Reliability slides
advertisement

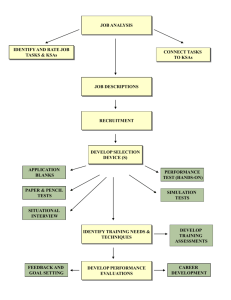
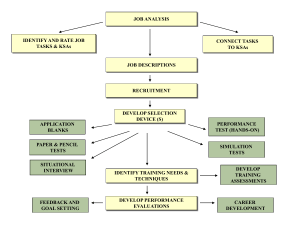
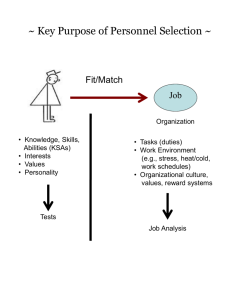
~ Reliability ~ Definition: The stability or consistency of a test Assumption: True score = obtained score +/- error Domain Sampling Model Item Domain Test ~ Identifying The Item Domain ~ [a.k.a. Where do the questions come from?] Test Item Domain • Specific, defined content area (e.g., course exam, training program) • Expert opinion, observation (e.g., professional literature) • Job analysis (identification of major job tasks, duties) Job Analysis Overview Task Identification KSA Identification Task 1 KSA 1 Task 2 KSA 2 Task 3 KSA 3 Task 4 KSA 4 Job (or Job Category) • Rate Tasks and KSAs • Connect KSAs to Tasks ~ Sample Task Rating Form ~ Frequency of use 5 = almost all of the time 4 = frequently 3 = occasionally 2 = seldom 1 = not performed at all 1 2 3 4 5 6 7 Importance of performing successfully Importance for new hire 5 = extremely important 4 = very important 3 = moderately important 2 = slightly important 1 = of no importance 5 = extremely important 4 = very important 3 = moderately important 2 = slightly important 1 = of no importance Distinguishes between superior & ad performance 5 = a great deal 4 = considerably 3 = moderately 2 = slightly 1 = not at all Damage if error occurs 5 = extreme damage 4 = considerable damage 3 = moderate damage 2 = very little damage 1 = virtually no damage ~ Sample KSA Rating Form ~ Importance for acceptable job performance 5 = extremely important 4 = very important 3 = moderately important 2 = slightly important 1 = of no importance A B C D E F G Importance for new hire 5 = extremely important 4 = very important 3 = moderately important 2 = slightly important 1 = of no importance Distinguishes between superior & adequate performance 5 = a great deal 4 = considerably 3 = moderately 2 = slightly 1 = not at all Sample Task -- KSA Matrix To what extent is each KSA needed when performing each job task? 5 = Extremely necessary, the job task cannot be performed without the KSA 4 = Very necessary, the KSA is very helpful when performing the job task 3 = Moderately necessary, the KSA is moderately helpful when performing the job task 2 = Slightly necessary, the KSA is slightly helpful when performing the job task 1 = Not necessary, the KSA is not used when performing the job task KSA Job Tasks 1 2 3 4 5 6 7 A B C D E F G H ~ Writing Test Items ~ • Write a lot of questions • Write more questions for the most critical KSAs • Consider the reading level of the test takers ~ Selecting Test Items ~ • Initial review by Subject Matter Experts (SMEs) • Connect items to KSAs • Assess difficulty of items relative to job requirements • Suggest revisions to items and answers Sample Item Rating Form Connect each item to a KSA or two Rate difficulty of each item (5point scale) relative to the level of KSA needed in the job) ~ Statistical Properties of Items ~ • Item Difficulty levels. Goal is to keep items of moderate difficulty (e.g., p values between .40 - .60) “p-value” is % of people getting each item correct -4 -3 -2 -1 Mean +1 +2 +3 +4 10 ~ KR-20 and Coefficient Alpha ~ [error due to item similarity] • KR-20 is used with scales that have right & wrong responses (e.g., achievement tests) • Alpha is used for scales that have a range of response options where there are no right or wrong responses (e.g., 7-point Likert-type scales) KR-20 % of people getting items correct; should be moderate (.40 - .60) Rtt = k k–1 pi (1 – pi) y 2 # of items variance of test scores variance of scores on each item Alpha = k 1 – i2 k–1 # of items y2 variance of test scores RELIABILITY ANALYSIS - S C A L E (A L L) Mean Std Dev Cases Q1 Q2 Q3 Q4 Q5 Q6 Q7 Q8 Q9 Q10 Q11 Q12 Q13 Q14 .7167 .7583 .8167 .9333 .9583 .9000 .6333 .8750 .8000 .6167 .9750 .8083 .7583 .5083 .4525 .4299 .3886 .2505 .2007 .3013 .4839 .3321 .4017 .4882 .1568 .3953 .4299 .5020 120.0 120.0 120.0 120.0 120.0 120.0 120.0 120.0 120.0 120.0 120.0 120.0 120.0 120.0 Answers are scored as correct “1” or wrong “0.” So, the mean is the p value of the items (difficulty level or % or people getting each item correct) Easy items Acceptable items ~ Statistical Properties of Items (cont.) ~ Internal Consistency • Item correlations with each other. Goal is to select items that relate moderately to each other or “hang together” reasonably well (e.g., item x total score correlations of between .40 - .60, “alpha if item deleted” information) Overall alpha = .8374 ~ Standard Error of Measurement ~ [Error that exists in an individual’s test score] SEM = s 1 - r Reliability Standard Deviation Examples: = 10; r = .90 SEM = 3.16 = 10; r = .60 SEM = 6.32 Normal Curve 68% 95% 99% -4 -3 -2 -1 Mean +1 Actual z-score = 2.58 Actual z-score = 1.96 • 3.16 x 1.96 = 6.19 (95% confidence) • 3.16 x 2.58 = 8.15 (99% confidence) +2 +3 +4 ~ Other Standard Errors ~ Standard error of the mean: SX = s = standard deviation N = # observations or sample size S √N p = proportion Standard error of proportion: SEP = p (1 - p)/N N = sample size Standard error of difference in proportions: y = standard deviation of y Standard error of estimate (validity coefficient): y’ = y 2 1 - r xy (criterion) 2 r xy = correlation between x and y squared Possible problem with choosing test items based on their correlations with a criterion * * * * * * .20 .15 .10 * * * .05 * * ** * * * * * * .25 * * .30 * * * * * * .35 * * * * .40 * * Selection zone * Corr. .50 with .45 criteria * * * * * * * * .00 .00 .05 .10 .15 .20 .25 .30 .35 .40 Correlation of items with total test scores .45 .50 ~Test-retest method ~ Some Issues: • Length of time between test administrations if crucial (generally, the longer the interval, the lower the reliability) • Memory and learning effects • Stability of the construct being assessed • One-items measures ~ Parallel/Alternate Forms ~ [error due to test content and perhaps passage of time] Two types: 1) Immediate (back-to-back administrations) 2) Delayed (a time interval between administrations) Some Issues: • Need same number & type of items on each test • Item difficulty must be the same on each test • Variability of scores must be equivalent on each test ~ Split-half reliability ~ [error due to differences in item content between the halves of the test] • Typically, responses on odd versus even items are employed • Correlate total scores on odd items with the scores obtained on even items • Need to use the Spearman-Brown correction formula # of times the test is lengthened rttc = corrected r for the total test correlation between both parts of the test nr12 1 + (n – 1) r12 Person Odd Even 1 36 43 2 44 40 3 42 37 4 33 40 Example of Doubling a Test’s Length (test split into 2 halves) Rkk = 2 r12 1 + r12 If original correlation between 2 halves of a test (e.g., odd/even) is .80 then: (2)(.80)/(1 + .80) = .88 ~ Some Factors Affecting Reliability ~ 1) Number of items (the more questions, the higher the reliability) 2) Item difficulty (moderately difficult items lead to higher reliability, e.g., p-value of .40 to .60) 3) 3) Homogeneity/similarity of item content (e.g., item x total score correlation; the more homogeneity, the higher the reliability) 4) Scale format/number of response options (the more options, the higher the reliability)