display
advertisement

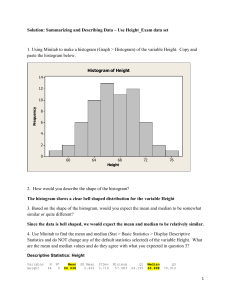
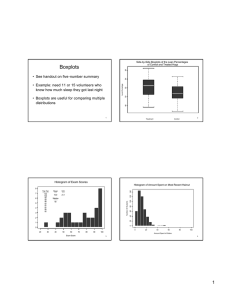
Summarizing and Describing Data – Use Height_Exam data set (11 Questions) 1. Using Minitab to make a histogram (Graph > Histogram) of the variable Height. Copy and paste the histogram below. 2. How would you describe the shape of the histogram? 3. Based on the shape of the histogram, would you expect the mean and median to be somewhat similar or quite different? 4. Use Minitab to find the mean and median (Stat > Basic Statistics > Display Descriptive Statistics and do NOT change any of the default statistics selected) of the variable Height. What are the mean and median values and do they agree with what you expected in question 3? 5. According to the Empirical Rule (also called the 68-95-99.7 Rule), for bell shaped data we would expect about 68% of all observations to fall within one standard deviation of the mean; about 95% to fall within two standard deviations of the mean; and about all (99.7%) to fall within three standard deviations of the mean. There are a total of 64 height values in the data set. Using the Standard Deviation (refer back to your Minitab output you produced for question 4) apply the Empirical Rule to the Height data by completing the table below [For simplicity, round the mean to nearest whole number and the SD to one decimal place. Also, you may want to copy/paste the Height data into Excel to sort. This will make counting the values within the range easier.]: Replace mean and SD with values 68% 95% 99.7% Compute the range (lower and upper values) from prior column The number of Height values we would expect to find in this range The actual number of Height values that fell in this range Mean ± SD Mean ± 2*SD Mean ± 3*SD 1 6. From question 4, what is the five number summary for the variable Height? Minimum: Q1: Median: Q3: Maximum: 7. As this summary relates to the variable Height, what is the interpretation of first and third quartile? 8. Do well does the Height data comply with these quartiles? That is, of total number of height values how many would we expect to fall at or below these quartiles compared to how many actually fell at or below these quartiles? Quartile First (Q1) Third (Q3) How many we expected How many we observed 9. Repeat this the histogram for the variable Exam. Copy and paste the histogram below and describe the shape and relationship between mean and median. 10. Now let’s apply the Empirical Rule to a data set that is not symmetrical. For the Exam data the mean is 88 with 11 as the standard deviation. Using this information, complete the following table. [For simplicity, round the mean and SD to one decimal place. Also, you may want to copy/paste the Exam data into Excel to sort. This will make counting the values within the range easier.]: Replace mean and SD with values 68% 95% 99.7% 88 ± 11 88 ± 2*11 88 ± 3*11 Compute the range (lower and upper values) from prior column The number of Height values we would expect to find in this range 68% of 32 = 95% of 32 = 99.7% of 32 = The actual number of Height values that fell in this range 11. Outliers and side-by-side boxplots. Outliers are "extreme observations" for a set of data, but how does one determine what is extreme? Boxplots help us in identifying such observations, and side-by-side boxplots are very useful when we want to display quantitative data across levels of a categorical variable, e.g. heights by gender. Create the side-by-side boxplots for Height by Gender. Click Graph > Boxplot > With Groups. Select Heights for the "Graph Variables" and 2 Gender for the "Categorical Variables" and click OK. Copy and paste your graph below and answer the following questions related to the graph. A. The '*' symbol in the Female boxplot represents an outlier. By placing your mouse over the this symbol in Minitab you can determine what the outlier value is and the data row in which it is located. What is the value and data row? B. How was this observation determined to be an outlier? To do this, read the online notes for "Finding Outliers Using IQR" and apply this technique to demonstrate why this observation would be considered an outlier [NOTE: after reading the online notes you can then place your mouse over the "box" part of the boxplot in Minitab to get the needed data]. C. In comparing the two boxplots, how would you describe the center and spread of the heights by gender? More specifically, which gender has the greater mean and median height, and what about spread, specifically the variance and standard deviation? 3