AP Statistics Section 4.2
Relationships Between Categorical
Variables
We will now describe relationships
between two or more categorical variables.
Some variables, such as race or sex are
categorical by nature. Other categorical
variables are created by grouping values of
a quantitative variable into classes. To
analyze categorical data, we use groups or
classes of individuals that fall into various
categories.
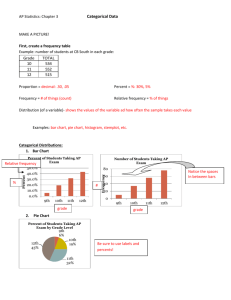
The table below presents Census Bureau data
describing the age and sex of college students.
two way table because it describes
This is a _____-_____
two categorical variables. (Age is categorical
here because the students are grouped into age
categories.) Age group is the ______
row variable
because each row in the table describes
students in one age group. Sex is the ________
column
variable because each column describes one
sex. The entries in the table are the counts of
students in each age-by-sex class.
Discrepancies may appear in
tabular data. For example, the sum
of entries in the “25 to 34” row is
_________________.
1,904 1,589 3, 493 The entry in
the total column is ______.
3 , 494 The
explanation is _________
rounding error.
To best grasp the information contained in
the table, first look at the distribution of
each variable separately. The distributions
of sex alone and age alone are called
__________________
marginal
distributions because they appear
at the right and bottom margins of the
two-way table. The distribution of a
categorical variable says how often each
outcome occurred. Usually it is
advantageous to look at percents as
opposed to counts.
Example 1: Determine the percent of
college students in each age group.
. 9 % 62.3% 21.0%
150
16639
15.8%
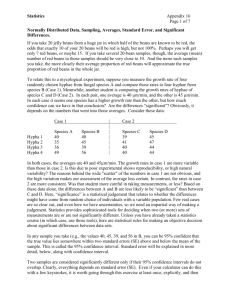
Each marginal distribution from a
two-way table is a distribution for a
single categorical variable. We
could use a pie graph or bar graph
to display such a distribution.
The marginal distributions of sex
and age do not tell us how the two
variables are related. How can we
describe the relationship between
age and sex of college students? To
describe relationships among
categorical variables, calculate
appropriate percents from the
counts given.
Example 2: Complete the tables below which give the
conditional distribution of sex, given age.
54.7% 45.3%
5668
10365
63.1% 36.9%
1660
2630
When we compare the percent of women in two age
groups we are comparing conditional distributions.
Comparing conditional distributions reveals the nature
of the association between the sex and age of college
students. Look at the bar graph at the right. The heights
do not differ greatly but women
are most common among the
35 or older age group.
__________
Example 3: Complete the tables below which give the
conditional distribution of age, given sex.
.01%
0.8%
60.8%
64.2%
20.4%
21.7%
17.8%
13.3%
Male students are more likely to be __________
18 24 years
old and quite a bit less likely to be _________.
15 17
CAUTION: No single graph (such as
a scatterplot) portrays the form of
the relationship between
categorical variables. No single
numerical measure (such as
correlation) summarizes the
strength of the association.
As is the case with quantitative
variables, the effects of lurking
variables can change or even
reverse relationships between two
categorical variables.
Example 4: Accident victims are sometimes taken by
helicopter from the accident scene to a hospital.
Helicopters save time. Do they also save lives?
Complete the table at the right.
32%
68%
24%
76%
Notice that a greater percentage of
helicopter patients died. How
discouraging.
But wait.
Here’s the data broken down by the seriousness of the
accident.
Complete the tables at the right.
48%
52%
60%
40%
16%
84%
20%
80%
Among serious accident victims, the
helicopter saves 52% compared with
40% for road transport. For less
serious accidents, 84% of those
transported by helicopter survive,
versus 80% of those transported by
road. Both groups have a higher
survival rate when transported by
helicopter.
The reason for the paradox in the
data is the helicopter carries
patients who are more likely to die.
The seriousness of the accident
lurking variable.
was the _______
An association or comparison that
holds for all of several groups can
reverse direction when the data
are combined to form a single
group. This reversal is called
_________
Simpson’s paradox.