Poster
advertisement

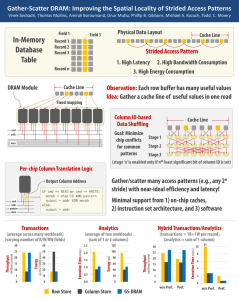
Gather-Scatter DRAM: Improving the Spatial Locality of Strided Access Patterns Vivek Seshadri, Thomas Mullins, Amirali Boroumand, Onur Mutlu, Phillip B. Gibbons, Michael A. Kozuch, Todd. C. Mowry Field 1 InMemory Databas e Table Physical Data Layout Field 3 Record 1 Record 2 Record 3 Strided Access Pattern 1. High Latency 2. High Bandwidth Consump 3. High Energy Consumption Record n DRAM Module Cache Line Cache Line Observation: Each row buffer has many u Idea: Gather a cache line of useful value Fixed mapping Column IDbased Data Shuffling Goal: cmd addr Stage 1 Minimize Stage 2 chip conflicts Stage 3 for th (stage ‘n’ is enabled only if n least significant bit of column ID is set) common Per-chip Column patterns Translation Logic Output Column if cmd Address == READ or cmd Gather/scatter many access patterns n (e.g., any 2 stride) with near-ideal efficiency and latency! Minimal support from 1) on-chip == WRITE: morph = chip-ID AND pattern output = addr XOR morph else: output = addr caches, 2) instruction set architecture, and 3) software Analytics Hybrid Transactions/Analytics verage across many workloads) (average of two workloads) arying number of R/W/RW fields) (sum of 1 or 2 columns) 5 0 20 10 0 2.0 100 1.5 1.0 0.5 0.0 80 60 40 20 10 30 Throughput 10 30 120 Energy (mJ) 15 40 2.5 (mSec) 20 50 Execution Time 25 (mJ for 10000 trans.) 60 Energy (millions/second) Throughput 30 (transactions = 1R+1W per record) (analytics = sum of 1 column) 0 Row Store Column Store GS-DRAM 25 20 15 10 5 0 w/o Pref. Pref. 21 8 (mSec) Transactions Execution Time cmd addr pattern data (millions/second) data Cache Line 6 4 2 0 w/o Pref.Pref.