Gather-Scatter DRAM: Improving the Spatial Locality of Strided Access Patterns
advertisement

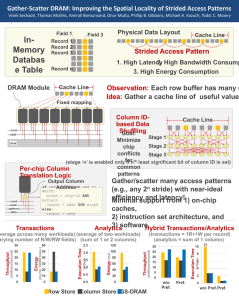
Gather-Scatter DRAM: Improving the Spatial Locality of Strided Access Patterns Vivek Seshadri, Thomas Mullins, Amirali Boroumand, Onur Mutlu, Phillip B. Gibbons, Michael A. Kozuch, Todd. C. Mowry Field 1 In-Memory Database Table Physical Data Layout Field 3 Record 1 Record 2 Record 3 Strided Access Pattern 1. High Latency 2. High Bandwidth Consumption 3. High Energy Consumption Record n Cache Line DRAM Module Cache Line Observation: Each row buffer has many useful values Idea: Gather a cache line of useful values in one read Fixed mapping Column ID-based Data Shuffling cmd addr Cache Line Goal: Minimize Stage 1 chip conflicts for common Stage 2 patterns Stage 3 data (stage ‘n’ is enabled only if nth least significant bit of column ID is set) Per-chip Column Translation Logic n Gather/scatter many access patterns (e.g., any 2 Output Column Address stride) with near-ideal efficiency and latency! if cmd == READ or cmd == WRITE: morph = chip-ID AND pattern output = addr XOR morph else: else output = addr cmd addr pattern data Minimal support from 1) on-chip caches, 2) instruction set architecture, and 3) software (average across many workloads) (varying number of R/W/RW fields) (average of two workloads) (sum of 1 or 2 columns) (transactions = 1R+1W per record) (analytics = sum of 1 column) 10 5 0 30 20 10 0 Row Store 2.0 100 25 1.5 1.0 80 60 40 20 15 10 0.5 20 5 0.0 0 0 Column Store GS-DRAM 10 Execution Time (mSec) 15 40 30 (millions/second) 20 120 Throughput 50 2.5 Energy (mJ) 25 (mJ for 10000 trans.) 60 Energy 30 Execution Time (mSec) Hybrid Transactions/Analytics (millions/second) Analytics Throughput Transactions 21 8 6 4 2 0 w/o Pref. Pref. w/o Pref. Pref.