AP Statistics
advertisement

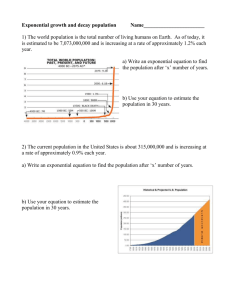
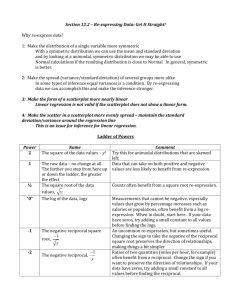
AP Statistics Chapter 10 Re-Expressing data: Get it Straight Objectives: • Re-expression of data • Ladder of powers Straight to the Point • We cannot use a linear model unless the relationship between the two variables is linear. Often re-expression (transformation) can save the day, straightening bent relationships so that we can fit and use a simple linear model. • Two simple ways to re-express data are with logarithms and reciprocals. • Re-expressions can be seen in everyday life— everybody does it. Straight to the Point • The relationship between fuel efficiency (in miles per gallon) and weight (in pounds) for late model cars looks fairly linear at first: Straight to the Point • A look at the residuals plot shows a problem: Straight to the Point • We can re-express fuel efficiency as gallons per hundred miles (a reciprocal) and eliminate the bend in the original scatterplot: Straight to the Point • A look at the residuals plot for the new model seems more reasonable: Goals of Re-expression • Goal 1: Make the distribution of a variable (as seen in its histogram, for example) more symmetric. It’s easier to summarize the center of a symmetric distribution, we can use the mean and standard deviation. If the distribution is unimodal also, we can analysis using the normal model. Here taking the log of the explanatory variable. Goals of Re-expression • Goal 2: Make the spread of several groups (as seen in side-by-side boxplots) more alike, even if their centers differ. Groups that share a common spread are easier to compare. Here taking the log makes the individual boxplots more symmetric and gives them spreads that are more nearly equal. Goals of Re-expression • Goal 3: Make the form of a scatterplot more nearly linear. Linear scatterplots are easier to model. By re-expressing to straighten the scatterplot relationship we can fit a linear model and use linear techniques to analysis. Here taking the log of the response variable. Goals of Re-expression • Goal 4: Make the scatter in a scatterplot spread out evenly rather than thickening at one end. Having an even scatter is a condition of many methods of Statistics, as we will see later. This is closely related to goal 2, but often comes along with goal 3, as seen below. When taking the log to straighten the data, it also evened out the spread. The Ladder of Powers • There is a family of simple re-expressions that move data toward our goals in a consistent way. This collection of re-expressions is called the Ladder of Powers. • The Ladder of Powers orders the effects that the re-expressions have on data. The Ladder of Powers Power Name Comment 2 Square of data values 1 Raw data ½ Square root of data values “0” Measurements that cannot be negative We’ll use logarithms here often benefit from a log re-expression. –1/2 –1 Reciprocal square root The reciprocal of the data Try with unimodal distributions that are skewed to the left. Data with positive and negative values and no bounds are less likely to benefit from re-expression. Counts often benefit from a square root re-expression. An uncommon re-expression, but sometimes useful. Ratios of two quantities (e.g., mph) often benefit from a reciprocal. The Ladder of Powers • The Ladder of Powers orders the effects that the re-expressions have on data. • How it works. If you try taking the square root of all the values in a variable and it helps, but not enough, then move further down the ladder to the log or reciprocal root. Those re-expressions will have a similar, but even stronger, effect on your data. If you go too far, you can always back up. Remember, when you take a negative power, the direction of the relationship will change. This is OK, you can always change the sign of the response variable if you want to keep the same direction. Plan B: Attack of the Logarithms • When none of the data values is zero or negative, logarithms can be a helpful ally in the search for a useful model. • Try taking the logs of both the x- and yvariable. • Then re-express the data using some combination of x or log(x) vs. y or log(y). Plan B: Attack of the Logarithms Multiple Benefits • We often choose a re-expression for one reason and then discover that it has helped other aspects of an analysis. • For example, a re-expression that makes a histogram more symmetric might also straighten a scatterplot or stabilize variance. Why Not Just Use a Curve? • If there’s a curve in the scatterplot, why not just fit a curve to the data? Why Not Just Use a Curve? • The mathematics and calculations for “curves of best fit” are considerably more difficult than “lines of best fit.” • Besides, straight lines are easy to understand. We know how to think about the slope and the yintercept. More Plan B: Modeling Nonlinear Data - Logarithms • Two specific types of nonlinear growth. 1. Exponential function (form y = abx) 2. Power function (form y = axb) • Equations of both forms can be transformed into linear forms. • Can then use linear regression to model and analyze the transformed data. • Can also perform an inverse transformation to obtain a model of the original data. Transforming or Re-Expressing Exponential Data Linear vs. Exponential Growth • Linear Growth – A variable grows linearly over time if it adds a fixed increment in each equal time period. Arthmetic Sequence – common difference (yn-yn-1) • Exponential Growth – A variable grows exponentially if it is multiplied by a fixed number greater than 1 in each equal time period. Exponential decay occurs when the factor is less than 1. Geometric Sequence – common ratio (yn/yn-1) To Transform the exponential Function use its Inverse the Logarithmic Function • Properties of Logarithms Using Logarithms to Transform Data • Logarithms can be useful in straightening a scatterplot whose data values are greater than zero. • Remember, you cannot take the logarithm of a nonpositive number. • When you use transformed data to create a linear model, your regression equation is not in terms of (x,y) but in terms of the transformed variable(s) (log ŷ or log x). Logarithm Transformations Test for Exponential Functions • View the scatterplot, does it look exponential? • Calculate the common ratio between successive response values – yn/yn-1. Can only be used if the explanatory values (x) change in equal increments. Example: Testing for Exponential Association • Data View Scatterplot • Looks like it has a curved pattern, could possibly be an exponential relationship. Verify Exponential Association • Density (y) • r = yn/yn-1 Is there a common ratio? YES, r≈1.2 (mean r=1.16 and median r=1.19) 4.5 6.1 4.3 5.5 7.4 9.8 7.9 10.6 13.4 16.9 21.2 25.6 31.0 35.6 41.2 44.2 50.7 50.6 57.4 64.0 70.3 6.1/4.5 = 1.36 4.3/6.1 = .70 5.5/4.3 = 1.28 7.4/5.5 = 1.35 9.8/7.4 = 1.32 7.9/9.8 = .81 10.6/7.9 = 1.34 13.4/10.6 = 1.26 16.9/13.4 = 1.26 21.2/16.9 = 1.25 25.6/21.2 = 1.21 31.0/25.6 = 1.21 35.6/31.0 = 1.15 41.2/35.6 = 1.16 44.2/41.2 = 1.07 50.7/44.2 = 1.15 50.6/50.7 = 1.00 57.4/50.6 = 1.13 64.0/57.4 = 1.11 70.3/64.0 = 1.10 Your Turn: Is the following data exponential & if so, what is r? • Yes, it is exponential and r ≈ 1.45 Your Turn: Is the following data (Hours vs. Number) exponential & if so, what is r? • No, it is not exponential. Exponential Regression Procedure 1. Verify data is exponential. Graph scatterplot & calculate common ratio 2. Transform data to linear by taking the log of the response variable. 3. Calculate the LSRL for the transformed data; log ŷ =b0+b1x (linear model). Analyze using linear techniques, LSRL, r, r2, and residuals. 4. Find exponential model for the original data by inverse transformation of the LSRL, exponentiating both sides of the LSRL equation to base 10; ŷ = C • 10kx (exponential model). Example: Data Annual crude oil production from 1880 to 1970 • Year 1880 1890 1900 1910 1920 1930 1940 1950 1960 1970 • Mbbl 30 77 149 328 689 1,412 2,150 3,803 7,674 16,690 What to do: 1. Graph scatterplot. 2. Calculate common ratio. 3. Transform data to linear (take the log of y). 4. Calculate LSRL of transformed data & graph. 5. Analyze transformed data (r, r2, residual plot). 6. Perform inverse transformation (exponentiate LSRL to base 10). 7. Graph exponential model. Back to the Data Annual crude oil production from 1880 to 1970 • Year 1880 1890 1900 1910 1920 1930 1940 1950 1960 1970 • Mbbl 30 77 149 328 689 1,412 2,150 3,803 7,674 16,690 Models of Data • Data is exponential (scatterplot curved pattern and constant common ratio ≈ 2.1) • Linear model log ŷ=-53.7+.0294x • Exponential model ŷ=(10-53.7) • 10.0294x Use model on the calculate to make predictions, not the exponential model equation. Predict oil production for 1956. • 6564 Mbbl Predict oil production for 1992. • 75027 Mbbl – extrapolation, be careful. Your Turn: Exponential Regression Models of Data • Data is exponential (scatterplot curved pattern and constant common ratio ≈ 1.5) • Linear Model Log ŷ = -24.11 + .0157x • Exponential Model ŷ = (10-24.11) • (10.0157x) Your Turn: Age vs Height Models for Data • Data is exponential (scatterplot curved pattern and constant common ratio ≈ 1.04) • Linear Model Log ŷ = 1.89 + .0241x • Exponential Model ŷ = (101.89) • (10.0214x) • If comparing Height vs Weight, could a common ratio be calculated? NO, because the explanatory variable Height does not in crease in equal increments. Have to calculate different models and see which best fits the data. Transforming or Re-Expression Power Data Power Function Model • Power Function general form: y = axb • When we apply the log transformation to the response variable y in an exponential growth model, we produce a linear relationship. To produce a linear relationship from a power function model, we apply the log transformation to both variables (x & y). • Here is how it is done. Power function model: y = axb Take the log of both sides of the equation: log y = log (axb) Using the product and power properties of logs, this results in a linear relationship between log y and log x. log y = log a + log xb log y = log a + b log x The power b in the power function model becomes the slope of the straight line that links log y to log x. Inverse Transformation • Obtaining a power function model for the original data from the LSRL on the transformed data. • LSRL will have the form: log ŷ = a + b log x • Inverse transform the LSRL by exponentiating both sides of the equation to base 10. 10log ŷ = 10(a + b log x) ŷ = (10a)(10b log x) ŷ = (10a)(10log x)b ŷ = (10a)(xb) which is in the form y = C · xb • A Power Function (can not be done on the calulator, must be done by hand). Power Function Procedure 1. Graph scatterplot. 2. Determine it is a power function (ie. not exponential). 3. Transform data to linear (take the log of y & x). 4. Calculate LSRL of transformed data & graph. 5. Analyze transformed data (r, r2, residual plot). 6. Perform inverse transformation (exponentiate LSRL to base 10). 7. Graph power model. 8. Make predictions based on the power model. Example 1 • The table shows the temperature of an instrument measured as its distance from a heat source is varied. Find a suitable model for Dist. vs Temp. • LSRL: log(Temp.) = 4.84 - .255 log(Dist.) log ŷ = 4.84 - .255 log x • Power model: Temp. = (104.84)·(Dist.)-.255 ŷ = 104.84 · x-.255 Your Turn: • The owner of a Video Game Store records the business costs and revenue for different years with the results listed. Find the best model. • LSRL: log ŷ = 3.3 + .4 log x • Power model: ŷ = 103.3 · x.4 or ŷ = (1995)x.4 What Can Go Wrong? • Don’t expect your model to be perfect. • Don’t stray too far from the ladder. • Don’t choose a model based on R2 alone: What Can Go Wrong? • Beware of multiple modes. Re-expression cannot pull separate modes together. • Watch out for scatterplots that turn around. Re-expression can straighten many bent relationships, but not those that go up then down, or down then up. What Can Go Wrong? • Watch out for negative data values. It’s impossible to re-express negative values by any power that is not a whole number on the Ladder of Powers or to re-express values that are zero for negative powers. • Watch for data far from 1. Data values that are all very far from 1 may not be much affected by re-expression unless the range is very large. If all the data values are large (e.g., years), consider subtracting a constant to bring them back near 1. What have we learned? • When the conditions for regression are not met, a simple re-expression of the data may help. • A re-expression may make the: Distribution of a variable more symmetric. Spread across different groups more similar. Form of a scatterplot straighter. Scatter around the line in a scatterplot more consistent. What have we learned? • Taking logs is often a good, simple starting point. To search further, the Ladder of Powers or the log-log approach can help us find a good reexpression. • Our models won’t be perfect, but re-expression can lead us to a useful model.