Example
advertisement

WELCOME TO STT 231
• INSTRUCTOR: DR. Elijah E. DIKONG
• VISITING PROFESSOR
• CLASS WEBSITE:
– http://www.stt.msu.edu
1
EXTRA CREDIT NUMBER 1
RECOMMENDED READING
COURSEPACK PAGES 2 – 9
EXERCISES 2.9
Page 9
QUESTIONS 1, 3, 4, and 5
Due: Wednesday May 27, 2015
2
What Is Statistics?
Statistics: Two Different Meanings:
(a) IN PLURAL SENSE, STATISTICS MEANS A SET
OF OBSERVATIONS, USUALLY COLLECTED BY
MEASUREMENTS OR COUNTING, COLLECTIVELY
KNOWN AS DATA.
(b) IN SINGULAR SENSE, STATISITICS REFERS TO A
GROUP OF SCIENTIFIC METHODS USED TO
* collecting data
* interpreting and analyzing data
* making conclusions or inferences.
3
IN SUMMARY
• STATISTICS IS THE ART AND SCIENCE
OF DESIGNING STUDIES AND
ANALYZING THE DATA THAT THOSE
STUDIES PRODUCE. ITS ULTIMATE
GOAL IS TRANSLATING DATA INTO
KNOWLEDGE AND UNDERSTANDING
OF THE WORLD AROUND US. IN
SHORT, STATISTICS IS THE ART AND
SCIENCE OF LEARNING FROM DATA.
4
THREE MAIN ASPECTS OF STATISTICS
• DESIGN: PLANNING HOW TO OBTAIN DATA TO
ANSWER THE QUESTIONS OF INTEREST (DATA
COLLECTION)
• DESCRIPTION: EXPLORING AND SUMMARIZING
PATTERNS IN THE DATA (DATA ANALYSES)
• INFERENCE: MAKING DECISIONS AND PREDICTIONS
BASED ON THE DATA. TO INFER MEANS TO ARRIVE
AT A DECISION OR PREDICTION BY REASONING
FROM KNOWN EVIDENCE
5
TYPES OF STATISTICS
DESCRIPTIVE
STATISTICS
INFERENTIAL
STATISTICS
STATISTICAL PROCEDURES
1.UNDERSTANDING
3.PLANNING
5.CHECKING
4.EXECUTING
2.ANALYZING
6.REPORTING
6
DESCRIPTIVE STATISTICS
• DEFINED AS THOSE METHODS INVOLVING THE COLLECTION,
PRESENTATION, AND CHARACTERIZATION OF A SET OF
DATA IN ORDER TO DESCRIBE PROPERLY THE VARIOUS
FEATURES OF THAT SET OF DATA. TO ACHIEVE THESE,
STATISTICIANS USE TABLES – EITHER FREQUENCY OR
CONTIGENCY; BAR AND PIE CHARTS; STEM-AND-LEAF
DISPLAYS; BOX-AND-WHISKER PLOTS; PARETO DIAGRAMS;
HISTOGRAMS.
• ALSO DEFINED AS THAT BRANCH OF STATISTICS THAT
INVOLVES IN THE ORGANIZING, DISPLAYING, AND
DESCRIBING OF DATA.
• INFERENTIAL STATISTICS
IS THE BRANCH OF STATISTICS THAT INVOLVES DRAWING
CONCLUSIONS ABOUT A POPULATION BASED ON
INFORMATION CONTAINED IN A SAMPLE FROM THAT
POPULATION
7
SOME
RELEVANT
STATISTICAL
TERMINOLOGIES
8
POPULATION VERSUS SAMPLE
• A POPULATION IS THE TOTAL GROUP OF
INDIVIDUALS ABOUT WHOM YOU WANT TO
MAKE CONCLUSIONS.
• A POPULATION IS THE TOTAL OBJECTS
THAT ARE OF INTEREST IN A STATISTICAL
STUDY.
• EXAMPLE: ALL CURRENTLY REGISTERED
STUDENTS AT A PARTICULAR COLLEGE
FORM A POPULATION.
9
POPULATION VERSUS SAMPLE
• A SAMPLE IS A REPRESENTATIVE
SUBSET OF A POPULATION,
EXAMINED IN HOPE OF LEARNING
ABOUT THE POPULATION.
• ILLUSTRATION: POT OF CHICKEN
SOUP
10
EXAMPLE: IDENTIFY THE
POPULATION AND THE SAMPLE
• A QUESTION POSTED ON THE LYCOS WEBSITE IN THE USA
ON 18 JUNE 2000 ASKED VISITORS TO THE SITE TO SAY
WHETHER THEY THOUGHT MARIJUANA SHOULD BE
LEGALLY AVAILABLE FOR MEDICINAL PURPOSES.
• THE GALLUP POLL INTERVIEWED 1007 RANDOMLY
SELECTED U.S. ADULTS AGED 18 AND OLDER, MARCH 23 –
25, 2007. GALLUP REPORTS THAT WHEN ASKED IF EVER,
THE EFFECTS OF GLOBAL WARMING WILL BEGIN TO
HAPPEN, 60% OF THE RESPONDENTS SAID THE EFFECTS
HAD ALREADY BEGUN. ONLY 11% THOUGHT THAT THEY
WOULD NEVER HAPPEN.
11
PARAMETER VERSUS STATISTIC
• PARAMETER (POPULATION PARAMETER):
A PARAMETER IS A NUMERICAL SUMMARY
OF THE POPULATION.
• STATISTIC (SAMPLE STATISTIC) – A
STATISTIC IS A NUMERICAL SUMMARY OF
A SAMPLE TAKEN FROM THE POPULATION.
12
EXAMPLE
• ONE YEAR THE GENERAL SOCIAL SURVEY
(GSS) ASKED, “ABOUT HOW MANY GOOD
FRIENDS DO YOU HAVE?” OF THE 819
PEOPLE WHO RESPONDED, 6% REPORTED
HAVING ONLY 1 GOOD FRIEND. IDENTIFY
• (A) THE SAMPLE,
• (B) THE POPULATION, AND
• (C) THE STATISTIC REPORTED
(POPULATION PARAMETER OR SAMPLE
STATISTICS)
13
DATA: SYSTEMATICALLY RECORDED INFORMATION,
WHETHER NUMBERS OR LABELS, TOGETHER WITH
ITS CONTEXT
CONTEXT TELLS WHO, WHAT, WHEN, WHERE, HOW and
WHY IS BEING MEASURED.
CONTEXT
WHERE
PLACE
E.G.
CITY
WHAT
WH0
CHARACTERISTICS
RECORDED ABOUT
EACH INDIVIDUAL
(VARIABLES)
INDIVIDUALS ABOUT
WHOM DATA ARE
COLLECTED(PARTICIPANTS,
RESPONDENTS, SUBJECTS,
EXPERIMENTAL UNITS,
RECORDS, CASES
WHEN
TIME[DAYS,
YEARS,
ETC.]
WHY
PURPOSE
OF STUDY
HOW
METHOD OF
COLLECTING
DATA. E.G.
SURVEY
14
EXAMPLE
• BECAUSE OF THE DIFFICULTY OF
WEIGHING A BEAR IN THE WOODS,
RESEARCHERS CAUGHT AND MEASURED
54 BEARS, RECORDING THEIR WEIGHT,
NECK SIZE, LENGTH, AND SEX. THEY
HOPED TO FIND A WAY TO ESTIMATE THE
WEIGHT FROM THE OTHER, MORE EASILY
DETERMINED QUANTITIES. IDENTIFY THE
W’S.
15
Raw Data
• Raw data are for numbers and category labels
that have been collected but have not yet been
processed in any way.
• Example list of questions and raw data for a student:
16
Raw Data
• An observation is an individual entity in a study.
• Sample data are collected from a subset of a
larger population.
• Population data are collected when all
individuals in a population are measured.
• A statistic is a summary measure of sample
data.
• A parameter is a summary measure of
population data.
17
DATA TABLE – AN ARRANGEMENT OF DATA IN WHICH EACH
ROW REPRESENTS A CASE[AN INDIVIDUAL ABOUT WHOM OR WHICH
WE HAVE DATA] AND EACH COLUMN REPRESENTS A VARIABLE.
NAME
CATHY
AGE
(YR)
22
NEAREST
STUDIUM
CATALOG
NUMBER
TIME
(DAYS)
AREA
CODE
130
312
ALI
Y
7TY73
MASS
INTERNET
PURCHASE
ARTIST
SAM
24
18
305
LINCO
N
CKJ24
BOST
CHRIS
43
368
610
VET
Y
JKN23
FLORI
5
413
SPAR
Y
7O28Y
APRIL
LINDA
35
18
VARIABLES
DEFINITION: THE CHARACTERISTICS RECORDED ABOUT
EACH INDIVIDUAL (SUBJECT) ARE CALLED VARIABLES.
TYPES OF VARIABLES
CATEGORICAL
OR
(QUALITATIVE)
QUANTITATIVE
OR
(NUMERICAL)
19
Types of Variables
• Raw data from categorical variables consist
of group or category names that don’t
necessarily have a logical ordering.
Examples: eye color, country of residence.
• Categorical variables for which the categories
have a logical ordering are called ordinal
variables. Examples: highest educational
degree earned, tee shirt size (S, M, L, XL).
• Raw data from quantitative variables consist
of numerical values taken on each individual.
Examples: height, number of siblings.
20
TWO TYPES OF QUANTITATIVE
VARIABLES
• DISCRETE QUANTITATIVE VARIABLE: A
VARIABLE IS DISCRETE IF IT TAKES ITS
VALUE FROM A COUNTABLE SET OF
NUMBERS LIKE {0, 1, 2, 3, 4, … } OR FROM A
FINITE SET OF NUMBERS.
• CONTINUOUS QUANTITATIVE VARIABLE: A
VARIABLE IS CONTINUOUS IF IT TAKES ITS
POSSIBLE VALUES FROM AN INTERVAL OR
A CONTINUUM LIKE [2, 7], (- 5, 10), OR THE
ENTIRE NUMBER LINE, R.
21
MORE EXAMPLES: WHAT TYPE
OF VARIABLE?
• THE NUMBER OF INCOMING PEOPLE IN THE BANK
BETWEEN 12:00 NOON AND 1:00P.M. ON FRIDAY
• YOU ROLL TWO DICE AND RECORD WHETHER OR
NOT THE RESULTING VALUES ON THE TWO DICE
MATCHED.
• A WOMAN IS SELECTED AT RANDOM FROM A CITY.
YOU RECORD WHETHER OR NOT THE SELECTED
WOMAN HAS BREAST CANCER.
• THE AMOUNT OF RAINFALL FOR A SEASON IN A
CITY
22
QUANTITATIVE AND
QUALITATIVE(CATEGORICAL) DATA
• DATA COLLECTED FROM A
QUANTITATIVE VARIABLE IS CALLED
QUANTITATIVE DATA.
• EXAMPLES INCLUDE HEIGHT,
WEIGHT, OF STUDENTS. TIME TO
COMPLETE DIFFERENT TASKS.
• DATA COLLECTED FROM A
CATEGORICAL VARIABLE IS CALLED
CATEGORICAL DATA.
23
EXAMPLE
IN JUNE 2003 CONSUMER REPORTS PUBLISHED AN ARTICLE
ON SOME SPORT UTILITY VEHICLES THEY HAD TESTED
RECENTLY. THEY REPORTED SOME BASIC INFORMATION
ABOUT EACH OF THE VEHICLES AND THE RESULTS OF SOME
TESTS CONDUCTED BY THEIR STAFF. AMONG OTHER THINGS,
THE ARTICLE TOLD THE BRAND OF EACH VEHICLE, ITS PRICE,
AND WHETHER IT HAD A STANDARD OR AUTOMATIC
TRANSMISSION. THEY REPORTED THE VEHICLE’S FUEL
ECONOMY, ITS ACCELERATION(NUMBER OF SECONDS TO
GO FROM ZERO TO 60MPH), AND ITS BRAKING DISTANCE
TO STOP FROM 60MPH. THE ARTICLE ALSO RATED EACH
VEHICLE’S RELIABILITY BETTER THAN AVERAGE,
AVERAGE, WORSE, OR MUCH WORSE THAN AVERAGE.
IDENTIFY THE W’S. LIST THE VARIABLES. INDICATE WHETHER
EACH VARIABLE IS CATEGORICAL OR QUANTITATIVE. IF
THE VARIABLE IS QUANTITATIVE, TELL THE UNITS.
24
EXAMPLE
IN JUNE 2000, A HOMEOWNER IN TUSCOLA, ILLINOIS,
WANTED TO DETERMINE IF GENERIC FERTILIZER
AND WEED KILLER IS AS EFFECTIVE AS THE
MORE EXPENSIVE NAME BRAND PRODUCT.
AFTER THE SPRING RAINS AND EARLY SUMMER
WARMTH, HE COUNTED THE NUMBER OF WEEDS
AND DENSITY OF GRASS BLADES.
IDENTIFY WHO, WHERE, WHEN, AND WHY FOR THE
SITUATION DESCRIBED.
A. A HOMEOWNER; TUSCOLA, ILLINOIS, JUNE 2000,
COMPARE PRODUCTS.
B. TWO PATCHES OF LAWN; TUSCOLA, ILLINOIS;
JUNE 2001; COMPARE PRODUCTS.
C. TWO PATCHES OF LAWN; ARCOLA, ILLINOIS;
JUNE 2000; COMPARE PRODUCTS.
D. A HOMEOWNER; ARCOLA, ILLINOIS; JUNE 2000;
COMPARE PRODUCTS.
E. TWO PATCHES OF LAWN; TUSCOLA, ILLINOIS; 25
JUNE 2000; COMPARE PRODUCTS.
EXAMPLE
AN ADMINISTRATOR IN A SCHOOL DISTRICT WITH SEVERAL
FIFTH GRADE CLASSROOMS OF ESSENTIALLY THE SAME
SIZE COLLECT DATA ON THE VARIOUS CLASSES. AMONG
THE VARIABLES WERE THE NUMBER OF SINGLE PARENT
FAMILIES, AVERAGE FAMILY INCOME, STRUCTURE OF
SCHOOL(K-5, 5-8, K-8), NUMBER ELIGIBLE FOR
FREE/REDUCED LUNCH, MAJORITY BRING/BUY
LUNCH(YES/NO), AVERAGE DISTANCE TO SCHOOL, AND
NUMBER OF PARENTAL VISITS TO SCHOOL.
SELECT THE STATEMENT THAT CLASSIFIES THE VARIABLES
IN ORDER WITH Q REPRESENTING A QUANTITATIVE
VARIABLE AND C REPRESENTING A CATEGORICAL
VARIABLE.
(A)
(B)
(C)
(D)
(E)
C,Q,C,Q,C,Q,Q
Q,C,Q,C,Q,C,C
Q,Q,C,Q,C,Q,C,
C,C,Q,C,Q,C,C.
Q,Q,C,Q,C,Q,Q.
26
MEASURES OF CENTER OF
QUANTITATIVE DATA
• THE CENTER IS A VALUE THAT
ATTEMPTS THE IMPOSSIBLE BY
SUMMARIZING THE ENTIRE
DISTRIBUTION OR DATA SET WITH A
SINGLE NUMBER, A “TYPICAL”
VALUE. MEASURES OF CENTER
INCLUDE THE MEAN AND THE
MEDIAN.
27
DEFINITION
• MEAN: THE MEAN IS THE SUM OF THE
OBSERVATIONS DIVIDED BY THE
NUMBER OF OBSERVATIONS.
• MEDIAN: THE MEDIAN IS THE
MIDPOINT OF THE OBSERVATIONS
WHEN THEY ARE ORDERED FROM
THE SMALLEST TO THE LARGEST (OR
FROM THE LARGEST TO SMALLEST).
28
Measures of Central Location
The Mean
x
x
i
n
where xi means “add together all the
values”
The Median
If n is odd: M = middle of ordered values.
Count (n + 1)/2 down from top of ordered list.
If n is even: M = average of middle two ordered values.
Average values that are (n/2) and (n/2) + 1
down from top of ordered list.
29
EXAMPLE
• FIND THE MEAN AND MEDIAN OF THE
SET OF OBSERVATIONS: 7, 1, 5, 3, 4.
• FIND THE MEAN AND MEDIAN OF 4, 2,
8, 6.
30
Measures of Central Location Cont’d
• THE MODE OR SAMPLE MODE: is the
most frequent value in a data set.
• EXAMPLE: Find the mode of the following
data set: - 1, 0, 2, 0
• SOLUTION: The value 0 is most
frequently observed and therefore the
mode is 0
31
CHALLENGE QUESTION
• PROFESSOR DIKONG GAVE HIS FIRST
TEST TO HIS STT 200 STUDENTS. HIS
COLLEAGUE IS INTERESTED HOW HIS
STUDENTS PERFORMED IN THE TEST.
• HOW SHOULD PROFESSOR DIKONG
ANSWER IN ORDER TO GIVE HIS
COLLEAGUE A BETTER IDEA OF HOW
HIS STUDENTS PERFORMED IN THE
TEST?
32
Key Takeaway
• THE MEAN, THE MEDIAN, AND THE
MODE EACH ANSWER THE QUESTION
“WHERE IS THE CENTER OF THE
DATA SET?”
33
OUTLIERS
• OUTLIERS ARE UNUSUAL OR EXTREME VALUES
THAT DO NOT APPEAR TO BELONG WITH THE
REST OF THE DATA, THAT IS, AN OUTLIER IS A
DATA POINT THAT IS NOT CONSISTENT WITH THE
BULK OF THE DATA.
• SUCH STRAGGLERS STAND OFF AWAY FROM THE
BODY OF THE DISTRIBUTION OF DATA SET.
• OUTLIERS CAN AFFECT MANY STATISTICAL
ANALYSES, SO YOU SHOULD ALWAYS BE ALERT
FOR THEM.
34
ILLUSTRATION
• MSU SPARTANS
VERSUS
• UNIVERSITY OF MICHIGAN
WOLVORINES
35
The Influence of Outliers on the
Mean and Median
Larger influence on mean than median.
High outliers will increase the mean.
Low outliers will decrease the mean.
If ages at death are: 76, 78, 80, 82, and 84
then mean = median = 80 years.
If ages at death are: 46, 78, 80, 82, and 84
then median = 80 but mean = 74 years.
36
MEASURES OF SPREAD OF
QUANTITATIVE DATA
• A MEASURE OF SPREAD IS A
NUMERICAL SUMMARY OF HOW
TIGHTLY THE VALUES ARE
CLUSTERED AROUND THE CENTER.
• MEASURES OF SPREAD ARE:
– STANDARD DEVIATION
– INTERQUARTILE RANGE (IQR)
– RANGE
37
RANGE = (MAXIMUM OBSERVATION) –
(MINIMUM OBSERVATION)
• EXAMPLE: FIND THE RANGE OF THE
DATA SET: 45, 46, 49, 35, 76, 80, 89, 94,
37, 61, 62, 64, 68, 56, 57, 57, 71, 72
• MAXIMUM OBSERVATION = 94
• MINIMUM OBSERVATION = 35
• RANGE = MAX – MIN = 94 – 35 = 59
38
VARIANCE AND STANDARD
DEVIATION
• THE RANGE USES ONLY THE
LARGEST AND SMALLEST
OBSERVATIONS. THE MOST
POPULAR SUMMARY OF
SPREAD USES ALL THE DATA.
IT IS CALLED THE STANDARD
DEVIATION.
39
Steps in Calculating Standard Deviation
Step 1:
Calculate x, the sample mean.
Step 2:
For each observation, calculate the
difference between the data value
and the mean.
Step 3:
Square each difference in step 2.
Step 4:
Sum the squared differences in step
3, and then divide this sum by n – 1.
Step 5:
Take the square root of the value in
step 4.
40
COMPUTING THE MEASURES OF SPREAD –
VARIANCE AND STANDARD DEVIATION
n
VAR( X )
x
i
i 1
x
2
n 1
SD ( X ) VAR( X )
n
where x
x
i 1
i
n
41
ILLUSTRATION
• HERE ARE THE AGES FOR A SAMPLE OF N = 5
CHILDREN: 1, 3, 5, 7, 9. FIND THE STANDARD
DEVIATION FOR THIS DATA SET WITHOUT USING A
CALCULATOR.
42
FIND THE VARIANCE AND STANDARD DEVIATION OF
THE BATCH OF VALUES 4, 3, 10, 12, 8, 9, AND 3.
VALUES
DEVIATIONS
SQ. DEVIATIONS
4
4–7=-3
9
3
3–7=-4
16
10
10 – 7 = 3
9
12
12 – 7 = 5
25
8
8–7=1
1
9
9–7=2
4
3
3–7=-4
16
43
Example Cont’d
SUM OF SQUARED DEVIATION
n
xi x 80
2
i 1
80
80
VAR( X )
13.33
7 1 6
SD( X ) 13.33 3.65
44
EXAMPLE and Step 1
• Consider four pulse rates: 62, 68, 74, 76
62 68 74 76 280
x
70
4
4
45
Steps 2 and 3
46
Step 4
120
2
s
40
4 1
47
Step 5
s 40 6.3
48
Describing Spread With Standard
Deviation
Standard deviation measures variability by
summarizing how far individual data
values are from the mean.
Think of the standard deviation as roughly
the average distance values fall from
the mean.
49
INTERQUARTILE RANGE (IQR)
• WE SHALL CONSIDER THE FOLLOWING
DATA SET TO ILLUSTRATE INTERQUARTILE
RANGE (IQR)
DATA: 45, 46, 49, 35, 76, 80, 89, 94, 37, 61,
62, 64, 68, 56, 57, 57, 59, 71, 72.
SORTED DATA: 35, 37, 45, 46, 49, 56, 57,
57, 59, 61, 62, 64, 68, 71,
72, 76, 80, 89, 94.
50
NOTATION
• INTERQUARTILE RANGE (IQR) = Q3 – Q1
Q3 = UPPER QUARTILE
= MEDIAN OF UPPER HALF OF ORDERED DATA
Q1 = LOWER QUARTILE
= MEDIAN OF LOWER HALF OF ORDERED DATA
NOTE: INCLUDE MEDIAN IN THE UPPER AND LOWER HALF OF
THE DATA IF THE DATA SET HAS ODD NUMBER OF
OBSERVATIONS OR DATA VALUES.
51
Quartiles
EXAMPLE: (odd number of observations, 19)
Median = 61
UPPER HALF
35 37 45 46 49 56 57 57 59 [61 62 64 68 71 72 76 80 89
94]
Q3 = (71 +72) / 2 = 71.5
LOWER HALF
[35 37 45 46 49 56 57 57 59 61] 62 64 68 71 72 76 80 89
94
Q1 = (49 + 56) / 2 = 52.5
IQR = 71.5 – 52.5 = 19
Note: Include the median in the calculation of both
quartiles IF n = ODD
52
Quartiles
EXAMPLE: (even number of observations, n = 18)
35 37 45 46 49 56 57 57 59 61 62 64 68 71 72 76 80 89
Median = (59+61)/2 = 60 DO NOT INCLUDE MEDIAN IN
THE LOWER AND UPPER HALF OF THE DATA.
UPPER HALF
35 37 45 46 49 56 57 57 59 [61 62 64 68 71 72 76 80 89 ]
Q3 = 71
LOWER HALF
[35 37 45 46 49 56 57 57 59 ] 62 64 68 71 72 76 80 89 94
Q1 = 49
IQR = 71 – 49 = 42
53
EXAMPLE
• 1. Here are costs of 10 electric smooth-top
ranges rated very good or excellent by
Consumers Reports in August 2002.
• 850
• 1000
•
•
•
•
900
750
1400
1250
1200
1050
1050
565
Find the following statistics by hand:
a) mean
b) median and quartiles
c) range and IQR
54
SOLUTION
• Step 1: Sort Data:
565
750
850
900
1000
1050
1050
1200
1250
1400
Mean = 1001.5
Median =1025
Q1=850
Q3=1200
Range = 835
IQR= 350
55
5 – NUMBER SUMMARY
•
THE 5-NUMBER SUMMARY OF A DISTRIBUTION REPORTS ITS
MEDIAN, QUARTILES, AND EXTREMES(MINIMUM AND MAXIMUM)
•
MAX = 94
•
Q3 = 71.5
•
MEDIAN = 61
•
Q1 = 52.5
•
MIN=35
OUTLIERS: DATA VALUES WHICH ARE BEYOND FENCES
IQR = Q3 – Q1 = 19
UPPER FENCE = Q3 + 1.5IQR = 71.5 + 1.5x19 = 100
LOWER FENCE = Q1 – 1.5IQR = 52.5 – 1.5x19 = 24
56
DISPLAYING QUANTITATIVE DATA
WHY DISPLAY DATA?
DATA TABLES DO NOT OFTEN HELP US
SEE (APPRECIATE) WHAT IS GOING ON. WE
NEED WAYS TO SHOW THE DATA SO THAT
WE CAN SEE
•
•
•
•
PATTERNS
RELATIONSHIPS
TRENDS
EXCEPTIONS.
57
BOXPLOTS
WHENEVER WE HAVE A 5-NUMBER SUMMARY OF A
(QUANTITATIVE) VARIABLE, WE CAN DISPLAY THE
INFORMATION IN A BOXPLOT.
• THE CENTER OF A BOXPLOT IS A BOX THAT SHOWS THE
MIDDLE HALF OF THE DATA, BETWEEN THE QUARTILES.
• THE HEIGHT OF THE BOX IS EQUAL TO THE IQR.
• IF THE MEDIAN IS ROUGHLY CENTERED BETWEEN THE
QUARTILES, THEN THE MIDDLE HALF OF THE DATA IS
ROUGHLY SYMMETRIC. IF IT IS NOT CENTERED, THE
DISTRIBUTION IS SKEWED.
• THE MAIN USE FOR BOXPLOTS IS TO COMPARE GROUPS.
58
How to Draw a Boxplot and Identify
Outliers
Step 1: Label either a vertical axis or a horizontal axis
with numbers from min to max of the data.
Step 2: Draw box with lower end at Q1 and upper end at Q3.
Step 3: Draw a line through the box at the median M.
Step 4: Calculate IQR = Q3 – Q1.
Step 5: Draw a line from Q1 end of box to smallest data value that
is not further than 1.5 IQR from Q1.
Draw a line from Q3 end of box to largest data value
that is not further than 1.5 IQR from Q3.
Step 6: Mark data points further than 1.5 IQR from either edge of
the box with an asterisk. Points represented
with asterisks are considered to be outliers.
59
Histogram (Minitab Commands)
• Open Minitab
• Click on Graph Histogram SimpleOk
• Click on C1Select
• Click on Labels Title (Write the title of
your histogram)
• Click Ok Click Ok
60
BOXPLOT OF THE PREVIOUS EXAMPLE
Boxplot of C1
100
90
80
C1
70
60
50
40
30
61
Boxplots: Picturing Location and Spread
for Group Comparisons
62
Boxplots: Picturing Location and Spread
for Group Comparisons
• Box covers the middle 50% of the data
• Line within box marks the median value
• Possible outliers are marked with
asterisk
• Apart from outliers, lines extending
from box reach to min and max values.
63
Comparing Groups
64
Comparing Groups
•
•
•
•
Q1: Which one has the larger median?
Q2: Which one has the larger IQR?
Q3: Which one has the larger range?
Q4: What is your general comment?
Are U.S. cars less efficient?
65
HISTOGRAMS
A HISTOGRAM IS A SUMMARY GRAPH
SHOWING A COUNT OF THE DATA FALLING
IN VARIOUS RANGES OR CLASSES OR
GROUPS.
PURPOSE: TO GRAPHICALLY SUMMARIZE
AND DISPLAY THE DISTRIBUITION OF A
PROCESS DATA SET.
66
HISTOGRAM
• It is particularly useful when
there are a large number of
observations.
• The observations or data sets
for which we draw a histogram
are QUANTITATIVE variables.
67
Creating a Histogram
Step 1: Decide how many equally spaced (same width)
intervals to use for the horizontal axis. Between 6 and
15 intervals is a good number.
Step 2: Decide to use frequencies (count) or relative
frequencies (proportion) on the vertical axis.
Step 3: Draw equally spaced intervals on horizontal axis
covering entire range of the data. Determine frequency
or relative frequency of data values in each interval and
draw a bar with corresponding height. Decide rule to use
for values that fall on the border between two intervals.
68
69
Histograms
• Example : THE WEIGHTS OF 23
“THREE-POUND” BAGS OF APPLES
ARE GIVEN AS FOLLOWS:
• 3.26 3.62 3.39 3.12 3.53 3.30 3.10 3.26
3.19 3.22 3.14 3.39 3.31 3.49 3.41 3.02
3.17 3.20 3.12 3.42 3.36 3.21 3.26
• USE THESE DATA TO CONSTRUCT A
HISTOGRAM FOR THE WEIGHT DATA
70
GROUP FREQUENCY DISTRIBUTION FOR
WEIGHTS OF 3 LB APPLE BAGS WITH BIN = 0.1
BINS
FREQUENCY
2.95 TO 3.05
1
3.05 TO 3.15
4
3.15 TO 3.25
5
3.25 TO 3.35
5
3.35 TO 3.45
5
3.45 TO 3.55
2
3.55 TO 3.65
1
71
Histogram
Histogram of Weights of 3 lb Apple Bags
5
Frequency
4
3
2
1
0
3.0
3.1
3.2
3.3
C1
3.4
3.5
3.6
72
Histogram
EXAMPLE 2.
-4.50, -3.25, -1.75, -1.59, -1.44,
-1.22, -1.16, -0.88, -0.75, -0.72,
-0.69, -0.50, -0.50, -0.38, -0.28,
-0.22, -0.16, 0.03, 0.12, 0.34, 0.47,
0.62, 0.69, 0.75, 0.78, 0.81, 1.16,
1.47, 2.06, 2.22, 2.44, 3.28, 3.34,
4.12, 4.31, 5.62 , 5.85
73
FREQUENCY DISTRIBUTION OF CLASS DATA
CLASSES
-4.5 TO -3.5
-3.5 TO -2.5
FREQUENCY
1
1
-2.5 TO -1.5
-1.5 TO -0.5
-0.5 TO 0.5
2
7
10
0.5 TO 1.5
1.5 TO 2.5
2.5 TO 3.5
3.5 TO 4.5
7
3
2
2
4.5 TO 5.5
5.5 TO 6.5
2
74
Histogram
Histogram of class data
10
Frequency
8
6
4
2
0
-4
-2
0
2
4
6
C1
75
DESCRIBING THE DISTRIBUTION OF A QUANTITATIVE
VARIABLE FROM HISTOGRAMS
• WHEN YOU DESCRIBE THE DISTRIBUTION
OF A [QUANTITATIVE] VARIABLE, YOU
SHOULD ALWAYS TELL ABOUT FOUR
THINGS:
•
•
•
•
SHAPE
CENTER
SPREAD
UNUSUAL FEATURES OR OUTLIERS
76
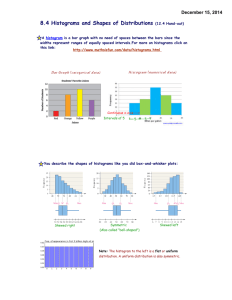
THE SHAPE OF A DISTRIBUTION
1. DOES THE HISTOGRAM HAVE A SINGLE,
CENTRAL HUMP OR SEVERAL SEPERATED
HUMPS? THESE HUMPS ARE CALLED
MODES.
A HISTOGRAM WITH ONE PEAK IS DUBBED
UNIMODAL; HISTOGRAMS WITH TWO PEAKS
ARE CALLED BIMODAL, AND THOSE WITH
THREE OR MORE PEAKS ARE CALLED
MULTIMODAL. A HISTOGRAM THAT DOESN’T
APPEAR TO HAVE ANY MODE AND IN WHICH
ALL THE BARS ARE APPROXIMATELY THE
SAME HEIGHT IS CALLED UNIFORM.
77
UNIMODAL, BIMODAL, MULTI-MODAL,
UNIFORM HISTOGRAMS
78
2. IS THE HISTOGRAM SYMMETRIC?
• CAN YOU FOLD THE HISTOGRAM ALONG A
VERTICAL LINE THROUGH THE MIDDLE AND HAVE
THE EDGES MATCH PRETTY CLOSELY, OR ARE
MORE OF THE VALUES ON ONE SIDE?
• THE (USUALLY) THINNER ENDS OF A DISTRIBUTION
ARE CALLED TAILS. IF ONE TAIL STRETCHES OUT
FARTHER THAN THE OTHER, THE HISTOGRAM IS
SAID TO BE SKEWED TO THE SIDE OF THE LONGER
TAIL.
• A “SKEWED RIGHT” DISTRIBUTION IS ONE IN WHICH
THE TAIL IS ON THE RIGHT SIDE.
• A “SKEWED LEFT” DISTRIBUTION IS ONE IN WHICH
THE TAIL IS ON THE LEFT SIDE.
79
Skewed Right; Skewed Left
80
RIGHT-SKEWED HISTOGRAM
81
SYMMETRIC HISTOGRAM
82
BELL-SHAPED (SYMMETRIC)
HISTOGRAM
83
LEFT-SKEWED HISTOGRAM
84
3. DO ANY UNUSUAL FEATURES STICK
OUT?
• UNUSUAL FEATURES OR OUTLIERS ARE
EXTREME VALUES THAT DO NOT APPEAR
TO BELONG WITH THE REST OF THE DATA.
SUCH STRAGGLERS STAND OFF AWAY
FROM THE BODY OF THE DISTRIBUTION.
OUTLIERS CAN AFFECT MANY STATISTICAL
ANALYSES, SO YOU SHOULD ALWAYS BE
ALERT FOR THEM.
85
Illustration
86
Illustration of Possible Outliers
87
Illustration of a Possible
Outlier
88
Some Remarks
Symmetric: mean = median
Skewed Left: mean < median
Skewed Right: mean > median
89
EXAMPLE
90
More Remarks
• FOR SYMMETRIC DISTRIBUTIONS, REPORT THE
MEAN AS A MEASURE OF CENTER AND THE
STANDARD DEVIATION AS A MEASURE OF
SPREAD.
• FROM SKEWED DISTRIBUTIONS, REPORT THE
MEDIAN AS A MEASURE OF CENTER AND THE
INTERQUARTILE RANGE AS A MEASURE OF
SPREAD
91
EXAMPLE
92
STEM AND LEAF DISPLAY
• HISTOGRAMS PROVIDE AN EASY-TOUNDERSTAND SUMMARY OF THE
DISTRIBUTION OF A QUANTITATIVE
VARIABLE, BUT THEY DON’T SHOW THE
DATA VALUES THEMSELVES.
• A STEM AND LEAF DIAGRAM IS AN
EXPLORATORY DATA-ANALYSIS
TECHNIQUE THAT ALLOWS US TO GROUP
DATA WITHOUT LOSING THE ORIGINAL
DATA. WE USE THE LEADING DIGIT(S) AS
THE “STEM” AND THE TRAILING DIGIT(S)
AS THE “LEAVES,” SO THAT THE NUMBERS
THEMSELVES BECOME A GRAPH OF THE
93
DATA.
Creating Stem-and-Leaf Plots
Step 1: Determine stem values. The “stem”
contains all but the last of the displayed
digits of a number. Stems should define
equally spaced intervals.
Step 2: For each individual, attach a “leaf”
to the appropriate stem. A “leaf” is the last
of the displayed digits of a number. Often
leaves are ordered on each stem.
Note:
More than one way to define stems.
Can use split-stems or truncate/round
values first.
94
Stem-and-Leaf Plot
• STEM-AND-LEAF DISPLAYS CONTAIN ALL THE
INFORMATION FOUND IN A HISTOGRAM AND,
WHEN CAREFULLY DRAWN, SATISFY THE AREA
PRINCIPLE AND SHOW THE DISTRIBUTION. IN
ADDITION, STEM-AND-LEAF DISPLAYS PRESERVE
THE INDIVIDUAL DATA VALUES.
• UNLIKE A HISTOGRAM, STEM-AND-LEAF DISPLAYS
ALSO SHOW THE DIGITS IN THE BINS, SO THEY
CAN REVEAL UNEXPECTED PATTERNS IN THE
DATA.
95
EXAMPLE : CONSIDER THE SORTED
AND ROUNDED DATA BELOW.
-4.5, -3.3, -2.0, -1.8, -1.6, -1.4, -1.2, -0.9, -0.9, -0.8, -0.7, -0.7, -0.5, -0.5, -0.4,
-0.3, -0.2, -0.2, 0.0, 0.1, 0.3, 0.5, 0.6, 0.7, 0.8, 0.8, 0.8, 1.2, 1.5,
2.1, 2.2, 2.4, 3.3, 3.3, 4.1, 4.3, 5.6
STEM LEAVES
-4 5
-3 3
-2 0
-1 8642
-0 99877554322
0 013567888
1 25
2 124
3 33
4 13
5 6
96
EXAMPLE : USING THE WEIGHTS OF THE BAGS
OF APPLES GIVEN IN THE EXAMPLE OF SLIDE 68,
CONSTRUCT A STEM-AND-LEAF DIAGRAM.
STEM
3.0
3.1
3.2
3.3
3.4
3.5
3.6
LEAVES
2
209472
6621016
90916
912
3
2
THE WEIGHTS OF THE BAGS RANGE FROM 3.02 TO
3.62, SO CAN USE AS STEMS THE VALUES 3.0 – 3.6.
THE LEAVES ARE DETERMINED BY THE DIGIT
FOUND IN THE HUNDRED’S PLACE OF THE
ORIGINAL DATA.
97
DOTPLOTS
• A DOTPLOT GRAPHS A DOT FOR EACH
CASE AGAINST A SINGLE AXIS.
• IT IS LIKE A STEM-AND-LEAF DISPLAY, BUT
WITH DOTS INSTEAD OF DIGITS FOR ALL
THE LEAVES.
• SOME DOTPLOTS STRETCH OUT
HORIZONTALLY, WITH THE COUNTS ON
THE VERTICAL AXIS, LIKE A HISTOGRAM.
OTHERS RUN VERTICALLY, LIKE A STEMAND-LEAF DISPLAY.
98
Creating a Dotplot
• Draw a number line (horizontal axis)
to cover range from smallest to largest
data value.
• For each observation, place a dot
above the number line located at the
observation’s data value.
• When multiple observations with the
same value, dots are stacked vertically
99
Example
THE DATA BELOW GIVE THE NUMBER OF
HURRICANE THAT HAPPENED EACH
YEAR FROM 1944 THROUGH 2000 AS
REPORTED BY SCIENCE MAGAZINE.
• 3,2,1,2,4,3,7,2,3,3,2,5,2,2,4,2,2,6,0,
2,5,1,3,1,0,3,2,1,0,1,2,3,2,1,2,2,2,3,
1,1,1,3,0,1,3,2,1,2,1,1,0,5,6,1,3,5,3
100
Frequency Table of Hurricanes
# OF HURRICANES/YEAR
FREQUENCY OR COUNT
0
4
1
14
2
17
3
12
4
2
5
4
6
2
7
1
101
Dot Plot For Hurricane Data
Dot plot for hurrican data
0
1
2
3
4
5
6
7
C6
102
DESCRIPTION OF THE DISTRIBUTION
• EACH DOT REPRESENTS A YEAR IN WHICH
THERE WERE THAT MANY HURRICANES.
• THE DISTRIBUTION OF THE NUMBER OF
HURRICANES PER YEAR IS UNIMODAL
• SKEWED TO THE RIGHT
• WITH CENTER AROUND 2 HURRICANES
PER YEAR.
• THE NUMBER OF HURRICANES PER YEAR
RANGES FROM 0 TO 7.
• THERE ARE NO OUTLIERS.
103
Right Handspan of College
Students
104
Right Handspan of College
Students
• Majority of females had handspans
between 19 and 21 cm,
and many males had handspans
between 21.5 and 23 cm.
• Two females with unusually small
handspans.
105
Interpreting Histograms, Stem-plots,
and Dot-plots
106
Comparing Histograms and Boxplots
107
DISPLAYING CATEGORICAL
DATA
• THE BAR CHART
• THE PIE CHART
108
EXAMPLE: CONSIDER THE TITANIC
• WHO: THE 2201 PEOPLE ON THE TITANIC;
• WHAT (VARIABLES):
–
–
–
–
–
–
SURVIVAL STATUS (DEAD OR ALIVE);
TICKET CLASS (FIRST, SECOND, THIRD, CREW);
GENDER (MALE OR FEMALE);
WHEN APRIL 14, 1912;
WHERE NORTH ATLANTIC;
HOW A VARIETY OF SOURCES AND INTERNET
SITES;
– WHY HISTORICAL INTEREST.
109
ONE VARIABLE ANALYSIS
WHO: THE 2201 PEOPLE ON THE TITANIC
WHAT: TICKET CLASS DISTRIBUTION
FREQUENCY TABLE: A
FREQUENCY TABLE LISTS
THE CATEGORIES IN A
CATEGORICAL VARIABLE
AND GIVES THE COUNT OR
PERCENTAGE OF
OBSERVATIONS OF EACH
CATEGORY.
CLASS
COUNT
OR
FREQU
ENCY
% OR
RELATI
VE
FREQU
ENCY
FIRST
325
285
706
14.766
12.949
32.076
885
2201
40.209
100
SECOND
THIRD
CREW
TOTAL
110
DISTRIBUTION OF A VARIABLE
* GIVES THE POSSIBLE VALUES OF THE VARIABLE, AND
* THE RELATIVE FREQUENCY OF EACH VALUE.
GRAPHICAL DISPLAY OF A DISTRIBUTION OF CATEGORICAL
DATA
BAR CHART
(A BAR CHART DISPLAYS THE
DISTRIBUTION OF A CATEGORICAL VARIABLE, SHOWING THE
COUNTS FOR EACH CATEGORY
NEXT TO EACH OTHER FOR
EASY COMPARISON.)
PIE CHART
PIE CHARTS SHOW THE
WHOLE GROUP OF CASES
AS A CIRCLE. THEY SLICE
THE CIRCLE INTO PIECES
WHOSE SIZE IS PROPORTIONAL TO THE FRACTION
OF THE WHOLE IN EACH
CATEGORY.
111
BAR CHART OF THE PEOPLE(WHO) ON THE
TITANIC WITH TICKET CLASS DISTRIBUTION(WHAT)
900
800
700
600
500
400
300
200
100
0
FIRST
SECOND
THIRD
CREW
112
PIE CHART OF PEOPLE ON THE TITANIC(WHO)
WITH TICKET CLASS DISTRIBUTION(WHAT)
15%
40%
13%
FIRST
SECOND
THIRD
CREW
32%
113
THE AREA PRINCIPLE: THE AREA OCCUPIED BY A
PART OF THE GRAPH SHOULD CORRESPOND TO
THE MAGNITUDE OF THE VALUE IT REPRESENTS.
TIPS
• FIRST RULE OF DATA ANALYSIS IS ‘MAKE A
PICTURE.’
• BEFORE YOU MAKE A BAR CHART OR A PIE
CHART, ALWAYS CHECK THE CATEGORICAL DATA
CONDITION. THE DATA ARE COUNTS OR
PERCENTAGES OF INDIVIDUALS IN CATEGORIES.
• IF YOU WANT TO MAKE A RELATIVE FREQUENCY
BAR CHART OR PIE CHART, YOU’LL NEED TO
ALSO MAKE SURE THAT THE CATEGORIES DON’T
OVERLAP, SO NO INDIVIDUAL IS COUNTED TWICE.
114