What's New in Globalization
advertisement

Unicode in
2008Q3
Mark Davis, Vladimir Weinstein, Andy
Heninger
2
Standard SW Globalization
Data Handling
Date, Time, Number Formatting
Collation
Locales/Languages
Timezones & Calendars,…
General Internationalization
Using character properties instead of hard-coded lists
Separation of code from localizable data (≈resource bundles)
Avoiding string concatenation, dealing with truncation …
3
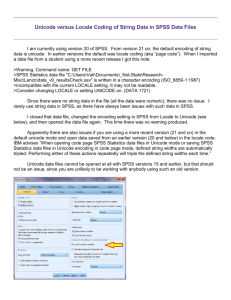
Where was the problem? (pause)
View
Server
Index
Data
DB
Upload
Server
dump
4
More places than you might think
❷
View
✔
Server
✔
1. Ensure Client App is Unicode
❹
Windows, don’t use ANSI
2. Prevent Encoding Mismatches
Index
Data
✔
Upload
✔
❶ ❺ ❷
✔
❸
Server
charset before web form params
❹
✔
3. Allow full Unicode identifiers
File names,…
4. Ensure Uniform Segmentation
Word ≠ [0-9a-zA-Z]+
DB
✔
5. Watch for hidden assumptions
❺
dump
Cp1252 corrupting bytes
6. Title requirement 3+ chars ok for
English, but not Chinese (狗)
5
Just a few extra challenges…
Massive amounts of data
Much web cruft to deal with
Very short release cycles
Many product × language/locale
pairs (next slide)
6
Locale × Product Versions
http://googleblog.blogspot.com/2008/07/hitting-40-languages.html
7
Translation
Professional Vendors, Contractors, Volunteers
8
Translation Strategies
Normal Translation Memory
Multiple, very short release cycles
Weeks, not months
Product Alternatives for new features
A. Delay release until completely translated
B. Disable new features until translated
C. Accept some English strings in new features
9
Unicode
Validation
NonUnicode
Converters
Int’l Strategy: Unicode Zone
Unicode Zone
10
Both forms of Unicode
UTF-8: C++, python
Mixture of char*, STL string, new robust class
UTF-8 is particularly good storage for the web (more later)
UTF-16: Java, Windows, Javascript, Mac
Libraries / Data
ICU, Joda Time, Internal libraries
Unicode Character Database, Unicode Locales (CLDR)
TZDB, ISO 4217 (currencies) – time sensitive
Update to new versions (eg Unicode 5.1) asap
11
Stable Identifiers
Unicode identifiers
Language/Locale, Script,
Region, Currency,
Timezone
based on BCP47, ISO
4217, TZDB
Required: unique, stable
CS = Czechoslovakia? Serbia
& Montenegro?
Serbia = CS? = RS? London is
in UK? GB?
Google Valid:
Canonical
US, iw
Noncanonical
SU, he
(deprecated / not preferred)
Google Disallowed*:
Private Use
XA
Unassigned
BB
Ill-Formed
B1
Variants i-tao, en-SCOUSE
12
User’s Locale / Language
Needed to improve quality
Locale = Language + (possibly) other info
Known if user is Signed In
Heuristics where not Signed In.
IP Address
Accept-Language
Country from Accept-Language
Domain,…
13
Normalizing Languages/Locales
Based on Unicode locale data (CLDR)
zh, und-CN, und-Hans,…
≃
zh
zh-TW, zh-Hant,…
≃
zh-TW
en, und-Latn, und-US,…
≃
en
en-GB, en-Latn-GB,…
≃
en-GB
he-IL, iw-IL, he-Hebr, he,… ≃
iw
14
Matching Languages/Locales
Input: User’s requested languages, our supported
languages
Output: “best” supported language
Need better match than truncation
A “distance” metric on normalized languages
Language, then script, then country
Plus special information:
hr vs bs, no vs nn, ro vs mo, tl vs fil
15
Web Cruft
Problems
Bad input: charset, language,…
Inaccurate detection
Difficulties in segmentation / morphology
These are non-trivial
Pages with conversion errors or unassigned (nonexistent) characters: ≈4%
Multiply that by billions and billions of pages…
16
You didn’t know there was going to
be a test…
How many pages are on the web?
What’s the most frequent character? Script? (next
slides) …
17
Most Web Data
18
Data in Different Scripts
19
Bad Source
Original page has corrupted data
Doubly-encoded UTF-8
Random illegal control codes, unassigned chars
Forms input data of unknown/wrong encoding
Mixtures of different charsets, from
Random pasting in non-Unicode enabled tools
Page composition (eg server-side includes), mixing charsets
Indic font encodings
20
Bad Server
Server mis-identifies the type or encoding of the
page in the HTTP protocol.
Example: JPEGs served up as text
Server overrides page with wrong charset
If you don’t do special detection, you get
random junk
Interpreting a JPEG as windows-1252:
not altogether productive…
21
Charset Tagging Trends
http://googleblog.blogspot.com/2008/05/moving-to-unicode-51.html
22
Encoding Detection
Pages are so often untagged & mis-tagged:
Bad codes
Both at HTTP and HTML levels
And what happens if they differ?
We have to heuristically detect
the “real” character encoding
{charset}
_charset
En
TW
…
Need to do better than the browser
In the browser, the user can adjust a bad guess
UTF-8 source is the safest, but still must be verified
23
Attacks!
Cross-site scripting (XSS)
Don’t treat ill-formed UTF-8 as space (or syntax)
<p id=abc�onMouseOver=evilDoers()…
Don’t swallow valid characters after ill-formed
…q="�>onMouseOver=…
Don’t allow UTF-7, UTF-16 as output encodings
Browsers often mis-detect, and allow XSS.
24
Spamming/Spoofing
IDNA Spoofing: “paypal.com”
Spamming: need to detect equivalences
http://spamsource.cn
http://spamsource.cn
http://bücher.de
http://xn--bcher-kva.de
http://b%C3%BCcher.de
fullwidth dot
25
Language Detection
Pages are so often untagged & mis-tagged:
Both at HTTP and HTML levels
So, we have to heuristically determine the
“real” language
Unfortunately, detecting language is
more complicated than encoding
Mixtures of languages on same page
Need to detect short strings, out of context, without
encoding
Needs to happen after entity expansion: &#xxx; → Y
Fortunately, misdetecting language is way less
problematic than encoding
Bad codes
en-securid
English
xl
Chinese
zs
us
eses
en-us.
"en-us "
es-es-ts
undefined
espa�ol
utf-8
26
Non-English Languages
27
Language Tags & Detection
28
If Lang Tags Normalized…
29
Tagged vs Detected
30
Bad HTML
It's easy to parse valid HTML correctly
But invalid HTML is not uncommon
We need to be as good at doing bad HTML as the
browsers are
That is, what the user sees in IE or Firefox is what
needs to be indexed
Illegal characters (controls) sneak in as character
entities: &#x1E;
31
Segmentation Challenges
Indexing & query: breaking text into words
→
ユニコードとは何か
ユニコード · とは · 何か
Problems if wrong:
Source segmented as: |AB|C|
User searches for
“BC”
Can segment/query multiple ways
not found
32
Thai Segmentation
คอมพิวเตอร์ จะ เกี่ยวข้อง กับ เรื่ อง ของ ตัวเลข
Before segmentation (2007-03):
After segmentation:
→
10 hits
300,000+ hits!
Spaces in query still make difference
คอมพิวเตอร์ จะเกี่ยวข้องกับเรื่ องของตัวเลข
acts as a complete phrase, equals:
“คอมพิวเตอร์ จะ เกี่ยวข้อง กับ เรื่ อง ของ ตัวเลข”
33
Morphology Challenges
Varies by language
Stopwords, phrases: a, the,…
Diacriticals: sasa → saša, sasha
Decompounding: Abiball → abiball OR abi ball
“Forms” of a word: go → gone, went, …
Synonyms: car shopping → auto shopping
…
34
Correcting User Typing
Users may be on keyboard without accents, or
expect transliteration
Types “Sasha” or “Sasa” or “Саша” for “Saša”
Misspellings
35
Character folding
Avoid spurious input
differences
“financial” (fi lig., PDF)
Normalize with:
NFC + subset of NFKC +
UCA + others
Suppress display
“➠”
Original
Term
1
2
3
4
5
6
Index
Term
➠
omit
SHY omit
صلى ﷹ
₩
₩
Can’t can't
fi
fi
SW Globalization
at
Mark Davis
37
Q&A
38
In Action
Indexing stores canonicalized originals
… Fishing … ro◌̂les
→
… fishing … rôles
Query expanded to variants
fish → fish|fishing
rôle → role|rôle|roles|rôles
Expansions may be language-dependent
39
Freeform Parsing