Nonparametric Statistics
advertisement

Summer School in Statistics
for Astronomers VI
June 7-11, 2010
Robustness, Nonparametrics and
Some Inconvenient Truths
Tom Hettmansperger
Dept. of Statistics
Penn State University
t-tests and F-test
rank tests
Least squares
Robust methods
Nonparametrics
Some ideas we will explore:
Robustness
Nonparametric Bootstrap
Nonparametric Density Estimation
Nonparametric Rank Tests
Tests for (non-)Normality
The goal: To make you worry or at least think
critically about statistical analyses.
Abstract
Population Distribution, Model
Statistical
Inference
Probability and
Expectation
Real World Data
Research Hypothesis or Question in English
Measurement, Exp. Design, Data Collection
Statistical Model, Population Distribution
Translate Res. Hyp. or Quest. into a
statement in terms of the model parameters
Select a relevant statistic
Carry out statistical inference
Graphical displays
Model criticism
Sampling Distributions
P-values
Significance levels
Confidence coefficients
State Conclusions and Recommendations in English
Parameters in a population or model
Typical Values: mean, median, mode
Spread: variance (standard deviation), interquartile range (IQR)
Shape: probability density function (pdf), cumulative distribution function (cdf)
Outliers
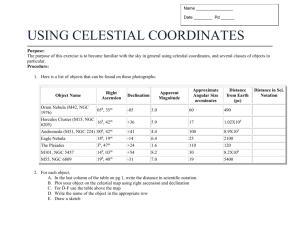
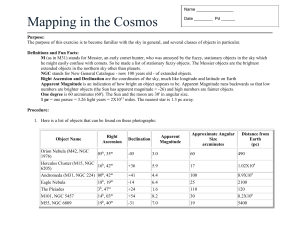
Research Question: How large are the luminosities in NGC 4382?
Measure of luminosity (data below)
Traditional model: normal distribution of luminosity
Translate Res. Q.: What is the mean luminosity of the population?
(Here we use the mean to represent the typical value.)
The relevant statistic is the sample mean.
Statistical Inference: 95% confidence interval for the mean
using a normal approximation to the sampling distribution of the mean.
S
X 2
n
NGC 4382 (n
26.215
26.687
26.790
= 59)
26.506
26.699
26.800
orig:
no:
24.000:
26.542
26.703
26.807
26.905 + .0524
26.917 + .0474
26.867 + .1094
26.551
26.553
26.607
26.612
26.727
26.740
26.747
26.765
... 27.161
27.169
27.179
26.674
26.779
Summary for NGC 4382
A nderson-Darling N ormality Test
26.2
26.4
26.6
26.8
27.0
27.2
A -S quared
P -V alue <
1.54
0.005
M ean
S tDev
V ariance
S kew ness
Kurtosis
N
26.905
0.201
0.040
-1.06045
1.08094
59
M inimum
1st Q uartile
M edian
3rd Q uartile
M aximum
26.215
26.765
26.974
27.042
27.179
95% C onfidence Interv al for M ean
26.853
26.957
95% C onfidence Interv al for M edian
26.915
27.010
95% C onfidence Interv al for S tDev
9 5 % C onfidence Inter vals
0.170
Mean
Median
26.850
26.875
26.900
26.925
26.950
26.975
27.000
0.246
Boxplot of NGC 4382 no, NGC 4382, NGC 4382_26, NGC 4382_25, ...
27.5
27.0
26.5
Data
26.0
25.5
25.0
24.5
24.0
NGC 4382_no NGC 4382_orig NGC 4382_26
NGC 4382_25
NGC 4382_24
Variable
NGC 4382_no
NGC 4382_orig
NGC 4382_26
NGC 4382_25
NGC 4382_24
Minimum
26.506
26.215
26.000
25.000
24.000
N
58
59
59
59
59
N*
0
0
0
0
0
Q1
26.776
26.765
26.765
26.765
26.765
Mean
26.917
26.905
26.901
26.884
26.867
Median
26.974
26.974
26.974
26.974
26.974
SE Mean
0.0237
0.0262
0.0280
0.0400
0.0547
Q3
27.046
27.042
27.042
27.042
27.042
StDev
0.181
0.201
0.215
0.307
0.420
First Inconvenient Truth:
Outliers can have arbitrarily large impact on the sample mean, sample
standard deviation, and sample variance.
Second Inconvenient Truth:
A single outlier can increase the width of the t-confidence interval
and inflate the margin of error for the sample mean. Inference can
be adversely affected.
It is bad for a small portion of the data to dictate
the results of a statistical analysis.
Third Very Inconvenient Truth:
The construction of a 95% confidence interval for the
population variance is very sensitive to the
shape of the underlying model distribution.
The standard interval computed in most statistical
packages assumes the model distribution is normal.
If this assumption is wrong, the resulting confidence
coefficient can vary significantly.
I am not aware of a stable 95% confidence interval
for the population variance.
The ever hopeful statisticians
Robustness: structural and distributional
Structural: We would like to have an estimator
and a test statistic that are not overly sensitive
to small portions of the data.
Influence or sensitivity curves: The rate of change
in a statistic as an outlier is varied.
Breakdown: The smallest fraction of the data that
must be altered to carry the statistic beyond any
preset bound.
We want bounded influence and high breakdown.
Distributional robustness:
We want a sampling distribution for the test
statistic that is not sensitive to changes or
misspecifications in the model or population
distribution.
This type of robustness provides stable
p-values for testing and stable confidence
coefficients for confidence intervals.
95% conf int for pop mean, x denotes the sample median
27.00
Median
26.95
Mean
Data
26.90
26.85
26.80
26.75
NGC 4382_no NGC 4382_orig NGC 4382_26
NGC 4382_25
NGC 4382_24
95% conf int for pop median, + denotes sample mean
27.025
27.000
Data
26.975
26.950
26.925
26.900
26.875
26.850
NGC 4382_no NGC 4382_orig NGC 4382_26
NGC 4382_25
NGC 4382_24
Message: The sample mean is not structurally robust;
whereas, the median is structurally robust.
It takes only one observation to move the sample mean
anywhere. It takes roughly 50% of the data to move the
median. (Breakdown)
SC( x) (n 1)[ˆn 1 ˆn ]
Sensitivity Curve:
SCmean(x) = x
SCmedian(x) = (n+1)x(r) if x < x(r)
(n+1)x
if x(r) < x < x(r+1)
(n+1)x(r+1) if x(r+1) < x
when n = 2r
Influence
Mean
Median
x
Mean has linear, unbounded influence.
Median has bounded influence.
Some good news: The sampling distribution of the
sample mean depends only mildly on the population
or model distribution. (A Central Limit Theorem effect)
Provided our data come from a model with finite
variance, for large sample size
[ X ]
n
S
has an approximate standard
normal distribution (mean 0 and variance 1).
This means that the sample mean enjoys distributional
robustness, at least approximately. We say that the
sample mean is asymptotically nonparametric.
More inconvenient truth: the sample variance is neither
structurally robust (unbounded sensitivity and breakdown
tending to 0), but also lacks distributional robustness.
Again, from the Central Limit Theorem:
Provided our data come from a model with finite
fourth moment, for large sample size
n[S 2 2 ]
has an approximate normal distribution
with mean 0 and variance:
4 ( 1), where
E ( X )4
4
is called the kurtosis
The kurtosis and is a measure of the tail weight of
a model distribution. It is independent of location and
scale and has value 3 for any normal model.
Assuming 95% confidence:
3
Approx true
Conf Coeff
.948
4.2
.877
5
.834
9
.674
Probability Plot of t5, Kurtosis = 9
Normal - 95% CI
99
Mean
StDev
N
AD
P-Value
95
90
0.08663
1.105
50
0.211
0.850
Percent
80
70
60
50
40
30
A very inconvenient truth:
A test for normality will also
mislead you!!
20
10
5
1
-3
-2
-1
0
1
t5
2
3
4
Some questions:
1. If statistical methodology based on sample means
and sample variances is non robust, what can we do?
Are you concerned about the last least squares analysis
you carried out? (t-tests and F-tests) If not, you should be!
2. What if we want to simply replace the mean by the
median as the typical value? The sample median is
robust, at least structurally. What about the distribution?
3. The mean and the t-test go together. What test goes
with the median?
We know that:
S
SE (mean)
, estimated by
n
n
How to find SE(median) and estimate it.
Two ways:
1. Nonparametric Bootstrap (computational)
2. Estimate the standard deviation of the
approximating normal distribution. (theoretical)
Nonparametric Bootstrap;
1. Draw a sample of size 59 from the original NGC4382
data. Sample with replacement.
2. Compute and store the sample median.
3. Repeat B times. (I generally take B = 4999)
4. The histogram of the B medians is an estimate of
sampling distribution of the sample median.
5. Compute the standard deviation of the B medians.
This is the approximate SE of the sample median.
Result for NGC4382: SE(median) = .028
(.027 w/o the outlier, .028 w outlier = 24)
Theoretical (Mathematical Statistics) Moderately Difficult
Let M denote the sample median. Provided the density (pdf)
of the model distribution is not 0 at the model median,
n[M ]
has an approximate normal distribution
with mean 0 and variance 1/[4f2()].
where f(x) is the density and is the model median.
In other words, SE(median) =
1
n 2 f ( )
and we must estimate the value of the density at the
population median.
Nonparametric density estimation:
Let f(x) denote a pdf. Based on a sample of size
n we wish to estimate f(x0) where x0 is given.
Define:
ˆf ( x ) 1 n 1 K x0 X i
0
n i 1 h h
Where K(t) is called the kernel and
2
2
K
(
t
)
dt
1
,
tK
(
t
)
dt
0
,
t
K
K (t )dt
Then a bit of calculation yields:
1 2
ˆ
E ( f ( x0 )) f ( x0 ) h f ( x0 ) K2 ...
2
And a bit more:
1
ˆ
V ( f ( x0 )
f ( x0 ) K 2 (t )dt ...
nh
And so we want:
h 0 and nh
The density estimate does not much depend on K(t), the
kernel. But it does depend strongly on h, the bandwidth.
1
1 2t2
e
We often choose a Gaussian (normal) kernel: K t )
2
Next we differentiate the integrated mean squared error and
set it equal to 0 to find the optimal bandwidth (indept of x0).
1/ 5
hopt
2
K
(
t
)
dt
n 1 / 5
2
[ f ( x)]2 dx
K
If we choose the Gaussian kernel and if f is normal then:
1 / 5
ˆ
hn (1.06 )n
where ˆ min S , .75IQR
Recall, SE(median) =
1
n 2 f ( )
For NGC4382: n = 59, M = 26.974
SE ( M )
1
.031, asy. approx
ˆ
59 2 f ( M )
Bootstrap result for NGC4382: SE(median) = .028
finite sample approx
Final note: both bootstrap and density estimate are robust.
The median and the sign test (for testing H0: = 0) are
related through the L1 norm.
D( ) | X i | [sgn( X i )]( X i )
d
D( ) S ( ) sgn( X i ) 2[# X i ] n
d
S ( ) # X i
n
with E[ S ( )]
2
To test H0: = 0 we use S+(0) # Xi > 0 which has a null
binomial sampling distribution with parameters n and .5.
This test is nonparametric and very robust.
Research Hypothesis: NGC4494 and NGC4382 differ
in luminosity.
Luminosity measurements (data)
NGC 4494 (m = 101)
26.146 26.167 26.173…26.632 26.641 26.643
NGC 4382 (n = 59)
26.215 26.506 26.542…27.161 27.169 27.179
Statistical Model Two normal populations with possibly
different means but with the same variance.
Translation: H0: 4494 = 4382 vs. H0: 4494 4382
Select a statistic: The two sample t statistic
NGC 4494 (m = 101), NGC 4382 (n = 59)
t
X 4494 X 4382
2
2
(m 1) S 4494
(n 1) S 4382
1 1
)
mn2
m n
X 4494 X 4382
2
2
S 4494
S 4382
m
n
VERY STRANGE!
The two sided t-test with significanc level .05
rejects the null hyp when |t| > 2.
Recall that means and variances are not robust.
Table of true values of the significance level when
the assumed level is .05.
Ratio of variances
Ratio
of
sample
sizes
1/4
1/1
3/1
1/4
.01
.05
.15
1/1
.05
.05
.05
4/1
.18
.05
.01
Another inconvenient truth: the true significance level
can differ from .05 when some model assumptions fail.
An even more inconvenient truth:
These problems extend to analysis of variance
and regression.
Seek alternative tests and estimates.
We already have alternatives to the mean and t-test:
the robust median and sign test.
We next consider nonparametric rank tests and estimates
for comparing two samples. (Competes with the two
sample t-test and difference in sample means.)
X 1 ,..., X m a sample from F ( x)
Y1 ,..., Yn a sample from G ( y )
Generally suppose:
G ( y ) F ( y )
To test H0: 0 or to estimate we introduce
n(n 1)
S (0) #[Y j X i 0] R(Y j )
2
R (Y j ) is the rank of Yj in the combined data.
The robust estimate of is
ˆ median (Y X )
i, j
j
i
Provides the robustness
Provides the comparison
As opposed to
1
Y X
(Y j X i )
mn
which is not robust.
Research Hypothesis: NGC4494 and NGC4382 differ
in luminosity.
Luminosity measurements (data)
X: NGC 4494 (n = 101)
26.146 26.167 26.173…26.632 26.641 26.643
Y: NGC 4382 (n = 59)
26.215 26.506 26.542…27.161 27.169 27.179
Statistical Model Two normal populations with possibly
different medians but with the same scale.
Translation: H0: 0 vs. H0: 0
Mann-Whitney Test and CI: NGC 4494, NGC 4382
N Median
X: NGC 4494 101 26.659
Y: NGC 4382 59 26.974
Point estimate for Delta is 0.253
95.0 Percent CI for Delta is (0.182, 0.328)
Mann-Whitney test:
Test of Delta = 0 vs Delta not equal 0 is significant at
0.0000 (P-Value)
85% CI-Boxplot of NGC 4494, NGC 4382
27.2
27.0
Data
26.8
26.6
26.4
26.2
26.0
NGC 4494
NGC 4382
What to do about truncation.
1. See a statistician
2. Read the Johnson, Morrell, and Schick reference. and then
see a statistician.
Here is the problem: Suppose we want to estimate the difference in locations
between two populations: F(x) and G(y) = F(y – d).
But (with right truncation at a) the observations come from
F ( x)
for x a and 1 for x a
F (a)
F(y d)
Ga ( y )
for y a and 1 for y a
F (a d )
Fa ( x)
Suppose d > 0 and so we want to shift the X-sample to the right toward the
truncation point. As we shift the Xs, some will pass the truncation point and
will be eliminated from the data set. This changes the sample sizes and
requires adjustment when computing the corresponding MWW to see if
it is equal to its expectation. See the reference for details.
Comparison of NGC4382 and NGC 4494
Point estimate for d is .253
W = 6595.5 (sum of ranks of Ys)
S+ = 4825.5
m = 101 and n = 59
Computation of shift estimate with truncation
S+
E(S+)
.510
4750.5
4366.0
59
.360
4533.5
4248.0
83
59
.210
4372.0
4218.5
.323
81
59
.080
4224.5
4159.5
.333
81
59
-.020
4144.5
4159.5
.331
81
59
-.000
4161.5
4159.5
d
m
n
.253
88
59
.283
84
.303
d̂
Recall the two sample t-test is sensitive to the assumption
of equal variances.
The Mann-Whitney test is less sensitive to the assumption
of equal scale parameters.
The null distribution is nonparametric. It does not depend
on the common underlying model distribution.
It depends on the permutation principle: Under the null
hypothesis, all (m+n)! permutations of the data are
equally likely. This can be used to estimate the
p-value of the test: sample the permutations,
compute and store the MW statistics, then find the
proportion greater than the observed MW.
Here’s a bad idea:
Test the data for normality using, perhaps, the
Kolmogorov-Smirnov test.
If the test ‘accepts’ normality then use a t-test, and
if it rejects normality then use a rank test.
You can use the K-S test to reject normality.
The inconvenient truth is that it may accept many
possible models, some of which can be very
disruptive to the t-test and sample means.
Absolute Magnitude
Planetary Nebulae
Milky Way
Abs Mag (n = 81)
17.537 15.845 15.449 12.710 15.499 16.450 14.695 14.878
15.350 12.909 12.873 13.278 15.591 14.550 16.078 15.438
14.741 …
Dotplot of Abs Mag
-14.4
-13.2
-12.0
-10.8
-9.6
A bs Mag
-8.4
-7.2
-6.0
Probability Plot of Abs Mag
Normal - 95% CI
99.9
Mean
StDev
N
AD
P-Value
99
Percent
95
90
80
70
60
50
40
30
20
10
5
1
0.1
-17.5
-15.0
-12.5
-10.0
Abs Mag
-7.5
-5.0
-10.32
1.804
81
0.303
0.567
But don’t be too quick to “accept” normality:
Probability Plot of Abs Mag
3-Parameter Weibull - 95% CI
Percent
99.9
99
Shape
Scale
Thresh
N
AD
P-Value
90
80
70
60
50
40
30
20
10
5
3
2
1
0.1
1
10
Abs Mag - Threshold
2.680
5.027
-14.79
81
0.224
>0.500
Weibull Distributi on :
c( x t )c 1
xt c
f ( x)
exp{ (
) for x t and 0 otherwise
c
b
b
t threshold
b scale
c shape (2.68 in the example)
Null Hyp: Pop distribution, F(x) is normal
The Kolmogorov-Smirnov Statistic
D max | Fn ( x) F ( x) |
The Anderson-Darling Statistic
AD n ( Fn ( x) F ( x)) [ F ( x)(1 F ( x))] dF ( x)
2
1
A Strategy:
Use robust statistical methods whenever possible.
If you must use traditional methods (sample means,
t and F tests) then carry out a parallel analysis using
robust methods and compare the results. Start to
worry if they differ substantially.
Always explore your data with graphical displays.
Attach probability error statements whenever possible.
What more can we do robustly?
1. Multiple regression
2. Analysis of designed experiments (AOV)
3. Analysis of covariance
4. Multivariate analysis
There’s more:
The rank based methods are 95% efficient relative to the
least squares methods when the underlying model is
normal.
They may be much more efficient when the
underlying model has heavier tails than a normal distribution.
But time is up.
References:
1.
2.
3.
4.
5.
6.
7.
Hollander and Wolfe (1999) Nonpar Stat Methods
Sprent and Smeeton (2007) Applied Nonpar Stat
Methods
Kvam and Vidakovic (2007) Nonpar Stat with
Applications to Science and Engineering
Johnson, Morrell, and Schick (1992) Two-Sample
Nonparametric Estimation and Confidence Intervals
Under Truncation, Biometrics, 48, 1043-1056.
Hettmansperger and McKean (2010) Robust
Nonparametric Statistics, 2nd Ed.
Efron and Tibshirani (1993) An Introduction to the
bootstrap
Arnold Notes, Bendre Notes
Thank you for listening!