Indexing The World Wide Web: The Journey So Far
advertisement

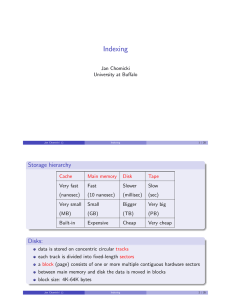
Author: Abhishek Das Google Inc., USA Ankit Jain Google Inc., USA Presented By: Anamika Mukherji 3/26/2013 Indexing The World Wide Web 1 Is Indexing Difficult? - Yes! Words not known beforehand Content available in different languages Variations in Grammar and Style No structure – riddled with colors, fonts, images, etc. Various byte-encoding schemes 3/26/2013 Indexing The World Wide Web 2 Answering The User’s Query Retrieval for a typical query Find terms in dictionary Start with the least frequent term since posting list will be the shortest. Fetch corresponding posting lists Intersect the lists on document identifiers to get relevant documents Rank and re-order the documents to present it to user. To get quality results as fast as possible, understanding of each usage is required Disk Space Disk Transfer Memory CPU Time Choice of data structure impacts CPU and storage Fixed-length array wasteful if posting lists kept in memory Singly linked list allows cheap insertions and updates Variable length array require less CPU time Linked list of fixed length arrays can be used for each term. Avoid pointers when storing the posting list in memory. 3/26/2013 Indexing The World Wide Web 3 Better Understanding of User Intent Check proximity of different terms Positional Index expands storage, slows down query processing . Phrase based Indexing – expensive, no accurate mechanism for identifying which phrase might be used. – Use a good phrase. 3/26/2013 Indexing The World Wide Web 4 Document vs. Term Based Partitioning 3/26/2013 Indexing The World Wide Web 5 Memory vs. Disk Storage 3/26/2013 Indexing The World Wide Web 6 Compressing The Index Advantages of compressed index Faster transfer of data from disk to memory Reduces disk seek time Compressions schemes Variable Encoding Bit-level Encoding Using gaps Original posting lists: the: ⟨1, 9⟩ ⟨2, 8⟩ ⟨3, 8⟩ ⟨4, 5⟩ ⟨5, 6⟩ ⟨6, 9⟩ to: ⟨1, 5⟩ ⟨3, 1⟩ ⟨4, 2⟩ ⟨5, 2⟩ ⟨6, 6⟩ john: ⟨2, 4⟩ ⟨4, 1⟩ ⟨6, 4⟩ With gaps: the: ⟨1, 9⟩ ⟨1, 8⟩ ⟨1, 8⟩ ⟨1, 5⟩ ⟨1, 6⟩ ⟨1, 9⟩ to: ⟨1, 5⟩ ⟨2, 1⟩ ⟨1, 2⟩ ⟨1, 2⟩ ⟨1, 6⟩ john: ⟨2, 4⟩ ⟨2, 1⟩ ⟨2, 4⟩ 3/26/2013 Indexing The World Wide Web 7 Variable Byte Encoding Uses an integral but adaptive number of bytes depending upon the gap size. First bit of each byte is a continuation bit. Remaining 7 bits in each byte are used to encode part of gap. To decode a byte: Read sequence of bytes till continuation bit flips. Extract and concatenate the 7-bit parts to get the magnitude of a gap. 3/26/2013 Indexing The World Wide Web 8 Bit Level Encoding Used when disk space is at premium. These codes adapt the length of the code on a finer grained bit level. Codeword is divided into 2 parts – prefix and suffix Prefix indicates the binary magnitude of the value and tells the decoder how many bits are there in the suffix part. Suffix indicates the value of the number within the corresponding binary range. Query processing is more time consuming. 3/26/2013 Indexing The World Wide Web 9 Ordering by Highest Impact First Example: (<doc id, term frequency>): ⟨12, 2⟩ ⟨17, 2⟩ ⟨29, 1⟩ ⟨32, 1⟩ ⟨40, 6⟩ ⟨78, 1⟩ ⟨101, 3⟩ ⟨106, 1⟩. When the list is reordered by term frequency, it gets transformed: ⟨40, 6⟩ ⟨101, 3⟩ ⟨12, 2⟩ ⟨17, 2⟩ ⟨29, 1⟩ ⟨32, 1⟩ ⟨78, 1⟩ ⟨106, 1⟩. The repeated frequency information can then be factored out into a prefix component with a counter that indicates how many documents there are with this same frequency value: ⟨6 : 1 : 40⟩ ⟨3 : 1 : 101⟩ ⟨2 : 2 : 12, 17⟩ ⟨1 : 4 : 29, 32, 78, 106⟩. Not storing the repeated frequencies gives a considerable saving. Finally, if differences of document identifiers are taken, we get the following: ⟨6 : 1 : 40⟩ ⟨3 : 1 : 101⟩ ⟨2 : 2 : 12, 5⟩ ⟨1 : 4 : 29, 3, 46, 28⟩. The document gaps within each equal-frequency segment of the list are now on average larger than when the document identifiers were sorted, thereby requiring more encoding bits/bytes. 3/26/2013 Indexing The World Wide Web 10 Managing Multiple Indices Multiples indices bucketed by rate of refreshing. The Large, rarely refreshing pages index The small, ever-refreshing pages index The dynamic real-time/news pages index Waterfall approach Pages discovered in one tier can be passed over the next over time. Invalidate older index and crawl file entries 3/26/2013 Indexing The World Wide Web 11 SCALING THE SYSTEM Web search engines use Distributed indexing algorithms for index construction Distributed File System In order to manage large amounts of data across large commodity clusters, a distributed file system that provides efficient remote file access, file transfers, and the ability to carry out concurrent independent operations while being extremely fault tolerant is essential. Map-Shuffle-Reduce Map: The master node chops up the problem into small chunks and assigns each chunk to a worker. The worker either processes the chunk of data with the mapper and returns the result to the master or further chops up the input data and assigns it hierarchically. Shuffle: Group key-value pair from mapper. Reduce: Take sub-answers and combine to create final output. 3/26/2013 Indexing The World Wide Web 12 FUTURE RESEARCH DIRECTIONS Real Time Data and Search – What can we do with each tweet? Create a Social Graph Extract and Index links Real-Time Related Topics Sentiment Analysis Social and Personalized Web Search Facebook, Twitter, etc. Facebook Users post a wealth of information Static – book, movie interest Dynamic – user locations, status updates, wall posts Learning user’s personal information can personalize search results Facebook impacting the world of search 3/26/2013 Opened data to third party service Search for 2 degrees of user Indexing The World Wide Web 13 Pros and Cons What I liked about it Delves into the history of Search Engines Talks about the Future Enhancement Explains how a search engine works What I didn’t like Skims through the surface without going deep. Includes very few examples which make understanding difficult. Compressing the Index section lacks structure which makes it difficult to understand. 3/26/2013 Indexing The World Wide Web 14