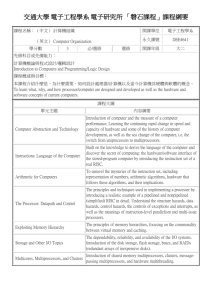
Chapter 7
Multicores,
Multiprocessors, and
Clusters
FIGURE 7.1 Hardware/software categorization and examples of application perspective on concurrency versus
hardware perspective on parallelism. Copyright © 2009 Elsevier, Inc. All rights reserved.
Chapter 7 — Multicores, Multiprocessors, and Clusters — 2
FIGURE 7.2 Classic organization of a shared memory multiprocessor. Copyright © 2009 Elsevier, Inc. All rights
reserved.
Chapter 7 — Multicores, Multiprocessors, and Clusters — 3
FIGURE 7.3 The last four levels of a reduction that sums results from each processor, from bottom to top. For all
processors whose number i is less than half, add the sum produced by processor number (i + half) to its sum. Copyright
© 2009 Elsevier, Inc. All rights reserved.
Chapter 7 — Multicores, Multiprocessors, and Clusters — 4
FIGURE 7.4 Classic organization of a multiprocessor with multiple private address spaces, traditionally called a
message-passing multiprocessor. Note that unlike the SMP in Figure 7.2, the interconnection network is not between
the caches and memory but is instead between processor-memory nodes. Copyright © 2009 Elsevier, Inc. All rights
reserved.
Chapter 7 — Multicores, Multiprocessors, and Clusters — 5
FIGURE 7.5 How four threads use the issue slots of a superscalar processor in different approaches. The four
threads at the top show how each would execute running alone on a standard superscalar processor without
multithreading support. The three examples at the bottom show how they would execute running together in three
multithreading options. The horizontal dimension represents the instruction issue capability in each clock cycle. The
vertical dimension represents a sequence of clock cycles. An empty (white) box indicates that the corresponding issue
slot is unused in that clock cycle. The shades of gray and color correspond to four different threads in the multithreading
processors. The additional pipe line start-up effects for coarse multithreading, which are not illustrated in this figure,
would lead to further loss in throughput for coarse multithreading. Copyright © 2009 Elsevier, Inc. All rights reserved.
Chapter 7 — Multicores, Multiprocessors, and Clusters — 6
FIGURE 7.6 Hardware categorization and examples based on number of instruction streams and data streams:
SISD, SIMD, MISD, and MIMD. Copyright © 2009 Elsevier, Inc. All rights reserved.
Chapter 7 — Multicores, Multiprocessors, and Clusters — 7
FIGURE 7.7 Comparing single core of a Sun UltraSPARC T2 (Niagara 2) to a single Tesla multiprocessor. The T2
core is a single processor and uses hardware-supported multithreading with eight threads. The Tesla multiprocessor
contains eight streaming processors and uses hardware-supported multithreading with 24 warps of 32 threads (eight
processors times four clock cycles). The T2 can switch every clock cycle, while the Tesla can switch only every two or
four clock cycles. One way to compare the two is that the T2 can only multithread the processor over time, while Tesla
can multithread over time and over space; that is, across the eight streaming processors as well as segments of four
clock cycles. Copyright © 2009 Elsevier, Inc. All rights reserved.
Chapter 7 — Multicores, Multiprocessors, and Clusters — 8
FIGURE 7.8 Hardware categorization of processor architectures and examples based on static versus dynamic
and ILP versus DLP. Copyright © 2009 Elsevier, Inc. All rights reserved.
Chapter 7 — Multicores, Multiprocessors, and Clusters — 9
FIGURE 7.9 Network topologies that have appeared in commercial parallel processors. The colored circles
represent switches and the black squares represent processor-memory nodes. Even though a switch has many links,
generally only one goes to the processor. The Boolean n-cube topology is an n-dimensional interconnect with 2n nodes,
requiring n links per switch (plus one for the processor) and thus n nearest-neighbor nodes. Frequently, these basic
topologies have been supplemented with extra arcs to improve performance and reliability. Copyright © 2009 Elsevier,
Inc. All rights reserved.
Chapter 7 — Multicores, Multiprocessors, and Clusters — 10
FIGURE 7.10 Popular multistage network topologies for eight nodes. The switches in these drawings are simpler
than in earlier drawings because the links are unidirectional; data comes in at the bottom and exits out the right link. The
switch box in c can pass A to C and B to D or B to C and A to D. The crossbar uses n2 switches, where n is the number
of processors, while the Omega network uses 2n log2n of the large switch boxes, each of which is logically composed of
four of the smaller switches. In this case, the crossbar uses 64 switches versus 12 switch boxes, or 48 switches, in the
Omega network. The crossbar, how ever, can support any combination of messages between processors, while the
Omega network cannot. Copyright © 2009 Elsevier, Inc. All rights reserved.
Chapter 7 — Multicores, Multiprocessors, and Clusters — 11
FIGURE 7.11 Examples of parallel benchmarks. Copyright © 2009 Elsevier, Inc. All rights reserved.
Chapter 7 — Multicores, Multiprocessors, and Clusters — 12
FIGURE 7.12 Arithmetic intensity, specified as the number of fl oat-point operations to run the program divided
by the number of bytes accessed in main memory [Williams, Patterson, 2008]. Some kernels have an arithmetic
intensity that scales with problem size, such as Dense Matrix, but there are many kernels with arithmetic intensities
independent of problem size. For kernels in this former case, weak scaling can lead to different results, since it puts much
less demand on the memory system. Copyright © 2009 Elsevier, Inc. All rights reserved.
Chapter 7 — Multicores, Multiprocessors, and Clusters — 13
FIGURE 7.13 Roofline Model [Williams, Patterson, 2008]. This example has a peak floating-point performance of 16
GFLOPS/sec and a peak memory bandwidth of 16 GB/sec from the Stream benchmark. (Since stream is actually four
measurements, this line is the average of the four.) The dotted vertical line in color on the left represents Kernel 1, which
has an arithmetic intensity of 0.5 FLOPs/byte. It is limited by memory bandwidth to no more than 8 GFLOPS/sec on this
Opteron X2. The dotted vertical line to the right represents Kernel 2, which has an arithmetic intensity of 4 FLOPs/byte. It
is limited only computationally to 16 GFLOPS/s. (This data is based on the AMD Opteron X2 (Revision F) using dual
cores running at 2 GHz in a dual socket system.) Copyright © 2009 Elsevier, Inc. All rights reserved.
Chapter 7 — Multicores, Multiprocessors, and Clusters — 14
FIGURE 7.14 Roofline models of two generations of Opterons. The Opteron X2 roofline, which is the same as Figure
7.11, is in black, and the Opteron X4 roofline is in color. The bigger ridge point of Opteron X4 means that kernels that
where computationally bound on the Opteron X2 could be memory-performance bound on the Opteron X4. Copyright ©
2009 Elsevier, Inc. All rights reserved.
Chapter 7 — Multicores, Multiprocessors, and Clusters — 15
FIGURE 7.15 Roofline model with ceilings. The top graph shows the computational “ceilings” of 8 GFLOPs/sec if the
floating-point operation mix is imbalanced and 2 GFLOPs/sec if the optimizations to increase ILP and SIMD are also
missing. The bottom graph shows the memory bandwidth ceilings of 11 GB/sec without software prefetching and 4.8
GB/sec if memory affinity optimizations are also missing. Copyright © 2009 Elsevier, Inc. All rights reserved.
Chapter 7 — Multicores, Multiprocessors, and Clusters — 16
FIGURE 7.16 Roofline model with ceilings, overlapping areas shaded, and the two kernels from Figure 7.13.
Kernels whose arithmetic intensity land in the blue trapezoid on the right should focus on computation optimizations, and
kernels whose arithmetic intensity land in the gray triangle in the lower left should focus on memory bandwidth
optimizations. Those that land in the blue-gray parallelogram in the middle need to worry about both. As Kernel 1 falls in
the parallelogram in the middle, try optimizing ILP and SIMD, memory affinity, and software prefetching. Kernel 2 falls in
the trapezoid on the right, so try optimizing ILP and SIMD and the balance of floating-point operations. Copyright © 2009
Elsevier, Inc. All rights reserved.
Chapter 7 — Multicores, Multiprocessors, and Clusters — 17
FIGURE 7.17 Four recent multiprocessors, each using two sockets for the processors. Starting from the upper left
hand corner, the computers are: (a) Intel Xeon e5345 (Clovertown), (b) AMD Opteron X4 2356 (Barcelona), (c) Sun
UltraSPARC T2 5140 (Niagara 2), and (d) IBM Cell QS20. Note that the Intel Xeon e5345 (Clovertown) has a separate
north bridge chip not found in the other microprocessors. Copyright © 2009 Elsevier, Inc. All rights reserved.
Chapter 7 — Multicores, Multiprocessors, and Clusters — 18
FIGURE 7.18 Characteristics of the four recent multicores. Although the Xeon e5345 and Opteron X4 have the same
speed DRAMs, the Stream benchmark shows a higher practical memory bandwidth due to the inefficiencies of the front
side bus on the Xeon e5345. Copyright © 2009 Elsevier, Inc. All rights reserved.
Chapter 7 — Multicores, Multiprocessors, and Clusters — 19
FIGURE 7.19 Roofline model for multicore multiprocessors in Figure 7.15. The ceilings are the same as in Figure
7.13. Starting from the upper left hand corner, the computers are: (a) Intel Xeon e5345 (Clovertown), (b) AMD Opteron X4
2356 (Barcelona), (c) Sun UltraSPARC T2 5140 (Niagara 2), and (d) IBM Cell QS20. Note the ridge points for the four
microprocessors intersect the X-axis at the arithmetic intensities of 6, 4, 1/3, and 3/4, respectively. The dashed vertical
lines are for the two kernels of this section and the stars mark the performance achieved for these kernels after all the
optimizations. SpMV is the pair of dashed vertical lines on the left. It has two lines because its arithmetic intensity
improved from 0.166 to 0.255 based on register blocking optimizations. LBHMD is the dashed vertical lines on the right. It
has a pair of lines in (a) and (b) because a cache optimization skips filling the cache block on a miss when the processor
would write new data into the entire block. That optimization increases the arithmetic intensity from 0.70 to 1.07. It’s a
single line in (c) at 0.70 because UltraSPARC T2 does not offer the cache optimization. It is a single line at 1.07 in (d)
because Cell has local store loaded by DMA, so the program doesn’t fetch unnecessary data as do caches. Copyright ©
2009 Elsevier, Inc. All rights reserved.
Chapter 7 — Multicores, Multiprocessors, and Clusters — 20
FIGURE 7.20 Performance of SpMV on the four multicores. Copyright © 2009 Elsevier, Inc. Allrights reserved.
Chapter 7 — Multicores, Multiprocessors, and Clusters — 21
FIGURE 7.21 Performance of LBMHD on the four multicores. Copyright © 2009 Elsevier, Inc. All rights reserved.
Chapter 7 — Multicores, Multiprocessors, and Clusters — 22
FIGURE 7.22 Base versus fully optimized performance of the four cores on the two kernels. Note the high fraction
of fully optimized performance delivered by the Sun UltraSPARC T2 (Niagara 2). There is no base performance column
for the IBM Cell because there is no way to port the code to the SPEs without caches. While you could run the code on
the Power core, it has an order of magnitude lower performance than the SPES, so we ignore it in this fi gure. Copyright
© 2009 Elsevier, Inc. All rights reserved.
Chapter 7 — Multicores, Multiprocessors, and Clusters — 23