simple
advertisement

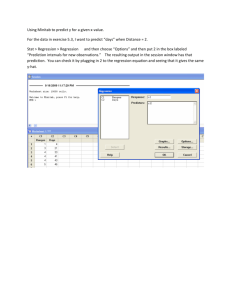
Simple linear regression Linear regression with one predictor variable What is simple linear regression? What is simple linear regression? • A way of evaluating the relationship between two continuous (quantitative) variables. • One variable is regarded as the predictor, explanatory, or independent variable (x). • Other variable is regarded as the response, outcome, or dependent variable (y). A deterministic (or functional) relationship 130 120 110 Fahrenheit 100 90 80 70 60 50 40 30 0 10 20 30 Celsius 40 50 Other deterministic relationships • Circumference = π×diameter • Hooke’s Law: Y = α + βX, where Y = amount of stretch in spring, and X = applied weight. • Ohm’s Law: I = V/r, where V = voltage applied, r = resistance, and I = current. • Boyle’s Law: For a constant temperature, P = α/V, where P = pressure, α = constant for each gas, and V = volume of gas. A statistical relationship Mortality (Deaths per 10 million) Skin cancer mortality versus State latitude 200 150 100 27 30 33 36 39 42 45 48 Latitude (at center of state) A relationship with some “trend”, but also with some “scatter.” Other statistical relationships • Height and weight • Alcohol consumed and blood alcohol content • Vital lung capacity and pack-years of smoking • Driving speed and gas mileage What is the best fitting line? Which is the “best fitting line”? 210 200 w = -331.2 + 7.1 h 190 weight 180 w = -266.5 + 6.1 h 170 160 150 140 130 120 110 62 66 70 height 74 Notation yi is the observed response for the ith experimental unit. xi is the predictor value for the ith experimental unit. ŷ i is the predicted response (or fitted value) for the ith experimental unit. Equation of best fitting line: yˆ i b0 b1 xi i xi yi 210 1 2 3 4 5 6 7 8 9 10 200 190 weight 180 170 w = -266.5 + 6.1 h 160 150 140 130 120 62 66 70 height 74 64 73 71 69 66 69 75 71 63 72 121 181 156 162 142 157 208 169 127 165 ŷ i 126.3 181.5 169.2 157.0 138.5 157.0 193.8 169.2 120.1 175.4 Prediction error (or residual error) In using ŷ i to predict the actual response y i we make a prediction error (or a residual error) of size ei yi yˆ i A line that fits the data well will be one for which the n prediction errors are as small as possible in some overall sense. The “least squares criterion” Equation of best fitting line: yˆ i b0 b1 xi Choose the values b0 and b1 that minimize the sum of the squared prediction errors. That is, find b0 and b1 that minimize: n Q yi yˆ i i 1 2 Which is the “best fitting line”? 210 200 w = -331.2 + 7.1 h 190 weight 180 w = -266.5 + 6.1 h 170 160 150 140 130 120 110 62 66 70 height 74 w = -331.2 + 7.1 h (dashed line) i xi yi ŷ i 1 2 3 4 5 6 7 8 9 10 64 73 71 69 66 69 75 71 63 72 121 181 156 162 142 157 208 169 127 165 123.2 187.1 172.9 158.7 137.4 158.7 201.3 172.9 116.1 180.0 yi yˆ i yi yˆ i 2 -2.2 -6.1 -16.9 3.3 4.6 -1.7 6.7 -3.9 10.9 -15.0 4.84 37.21 285.61 10.89 21.16 2.89 44.89 15.21 118.81 225.00 -----766.51 w = -266.5 + 6.1 h (solid line) i 1 2 3 4 5 6 7 8 9 10 xi 64 73 71 69 66 69 75 71 63 72 yi 121 181 156 162 142 157 208 169 127 165 ŷ i 126.271 181.509 169.234 156.959 138.546 156.959 193.784 169.234 120.133 175.371 yi yˆ i yi yˆ i 2 -5.3 -0.5 -13.2 5.0 3.5 0.0 14.2 -0.2 6.9 -10.4 28.09 0.25 174.24 25.00 12.25 0.00 201.64 0.04 47.61 108.16 -----597.28 The least squares regression line Using calculus, minimize (take derivative with respect to b0 and b1, set to 0, and solve for b0 and b1): n Q yi b0 b1 x i 2 i 1 and get the least squares estimates b0 and b1: n b1 x i 1 i n x yi y 2 x x i i 1 b0 y b1 x When is the slope b1 > 0? x 5.5 y 25 15 y 14.7 5 1 2 3 4 5 x 6 7 8 9 10 When is the slope b1 < 0? x 5.5 20 y 10 y 9 .2 0 1 2 3 4 5 x 6 7 8 9 10 Fitted line plot in Minitab Regression Plot weight = -266.534 + 6.13758 height S = 8.64137 R-Sq = 89.7 % R-Sq(adj) = 88.4 % 210 200 190 weight 180 170 160 150 140 130 120 65 70 height 75 Regression analysis in Minitab The regression equation is weight = - 267 + 6.14 height Predictor Constant height Coef -266.53 6.1376 S = 8.641 SE Coef 51.03 0.7353 R-Sq = 89.7% T -5.22 8.35 P 0.001 0.000 R-Sq(adj) = 88.4% Analysis of Variance Source DF Regression Residual Error Total 1 8 9 SS 5202.2 597.4 5799.6 MS 5202.2 74.7 F 69.67 P 0.000 What assumptions for the least squares regression line? • The relationship between the response y and the predictor x is linear. Prediction of future responses A common use of the estimated regression line. yˆ i , wt 267 6.14 xi ,ht Predict mean weight of 66"-inch tall people. yˆ i , wt 267 6.1466 138.24 Predict mean weight of 67"-inch tall people. yˆ i , wt 267 6.1467 144.38 What do the “estimated regression coefficients” b0 and b1 tell us? • We predict the mean weight to increase by 6.14 pounds for every additional one-inch increase in height. • It is not meaningful to have a height of 0 inches. That is, the scope of the model does not include x = 0. So, here the intercept b0 is not meaningful. What do the “estimated regression coefficients” b0 and b1 tell us? • We can expect the mean response to increase or decrease by b1 units for every unit increase in x. • If the “scope of the model” includes x = 0, then b0 is the predicted mean response when x = 0. Otherwise, b0 is not meaningful. The simple linear regression model College entrance test score What do b0 and b1 estimate? 22 Y E Y 0 1 x 18 14 10 Yi 0 1 x i 6 1 2 3 High school gpa 4 5 What do b0 and b1 estimate? College entrance test score 22 18 yˆ b0 b1 x 14 10 Y E Y 0 1 x 6 1 2 3 High school gpa 4 5 College entrance test score The simple linear regression model 22 Y E Y 0 1 x 18 14 10 Yi 0 1 x i 6 1 2 3 High school gpa 4 5 The simple linear regression model Source: Figure 1.6, Applied Linear Regression Models, 4th edition, by Kutner, Nachtsheim, and Neter. The simple linear regression model • The mean of the responses, E(Yi), is a linear function of the xi. • The errors, εi, and hence the responses Yi, are independent. • The errors, εi, and hence the responses Yi, are normally distributed. • The errors, εi, and hence the responses Yi, have equal variances (σ2) for all x values. College entrance test score What about (unknown) 22 2 σ? Y E Y 0 1 x 18 14 10 Yi 0 1 x i 6 1 2 3 4 5 High school gpa It quantifies how much the responses (y) vary around the (unknown) mean regression line E(Y) = β0 + β1x. Will this thermometer yield more precise future predictions …? Regression Plot fahrenheit = 17.0709 + 2.30583 celsius S = 21.7918 R-Sq = 70.6 % R-Sq(adj) = 66.4 % Fahrenheit 100 50 0 0 10 20 Celsius 30 40 … or this one? Regression Plot fahrenheit = 34.1233 + 1.61538 celsius S = 4.76923 R-Sq = 96.1 % R-Sq(adj) = 95.5 % 100 Fahrenheit 90 80 70 60 50 40 30 0 10 20 Celsius 30 40 Recall the “sample variance” The sample variance n Probability Density 0.025 0.020 s2 0.015 2 y y i i 1 n 1 0.010 0.005 0.000 52 68 84 100 IQ 116 132 148 estimates σ2, the variance of the one population. Estimating σ2 in regression setting The mean square error n MSE Source: Figure 1.6, Applied Linear Regression Models, 4th edition, by Kutner, Nachtsheim, and Neter. 2 ˆ y y i i i 1 n2 estimates σ2, the common variance of the many populations. Estimating σ2 from Minitab’s fitted line plot Regression Plot weight = -266.534 + 6.13758 height S = 8.64137 R-Sq = 89.7 % R-Sq(adj) = 88.4 % 210 200 190 weight 180 170 160 150 140 130 120 65 70 height 75 Estimating σ2 from Minitab’s regression analysis The regression equation is weight = - 267 + 6.14 height Predictor Constant height S = 8.641 Coef -266.53 6.1376 SE Coef 51.03 0.7353 R-Sq = 89.7% T -5.22 8.35 P 0.001 0.000 R-Sq(adj) = 88.4% Analysis of Variance Source DF Regression Residual Error Total 1 8 9 SS 5202.2 597.4 5799.6 MS 5202.2 74.7 F 69.67 P 0.000 Drawing conclusions about β0 and β1 Confidence intervals and hypothesis tests Relationship between state latitude and skin cancer mortality? # State 1 Alabama 2 Arizona 3 Arkansas 4 California 5 Colorado 49 Wyoming LAT 33.0 34.5 35.0 37.5 39.0 43.0 MORT 219 160 170 182 149 134 •Mortality rate of white males due to malignant skin melanoma from 1950-1959. •LAT = degrees (north) latitude of center of state •MORT = mortality rate due to malignant skin melanoma per 10 million people Relationship between state latitude and skin cancer mortality? Mortality (Deaths per 10 million) Skin cancer mortality versus State latitude yˆ 389.2 5.98 x 200 150 100 27 30 33 36 39 42 45 Latitude (at center of state) 48 (1-α)100% t-interval for slope parameter β1 Formula in words: Sample estimate ± (t-multiplier × standard error) Formula in notation: b1 t ,n2 2 MSE x x 2 i Hypothesis test for slope parameter 1 Null hypothesis H0: 1 = some number β Alternative hypothesis HA: 1 ≠ some number Test statistic t* b1 MSE 2 xi x b1 se b1 P-value = How likely is it that we’d get a test statistic t* as extreme as we did if the null hypothesis is true? The P-value is determined by referring to a t-distribution with n-2 degrees of freedom. Inference for slope parameter β1 in Minitab The regression equation is Mort = 389 - 5.98 Lat Predictor Constant Lat S = 19.12 Coef 389.19 -5.9776 SE Coef 23.81 0.5984 R-Sq = 68.0% T 16.34 -9.99 P 0.000 0.000 R-Sq(adj) = 67.3% Analysis of Variance Source Regression Residual Error Total DF 1 47 48 SS 36464 17173 53637 MS 36464 365 F 99.80 P 0.000 Factors affecting the length of the confidence interval for β1 b1 t ,n2 2 MSE x x 2 i • As the confidence level decreases, … • As MSE decreases, … • The more spread out the predictor values, … • As the sample size increases, … Does the estimated slope b1 vary more here …? y 25 Var b0 b1 15 5 1 2 3 4 5 x 6 7 8 9 10 N 5 5 StDev 0.385 0.0964 … or here? 30 20 y Var b0 b1 10 0 1 2 3 4 5 x 6 7 8 9 10 N 5 5 StDev 2.54 0.417 Does the estimated slope b1 vary more here with n = 4 …? 30 20 y Var b0 b1 10 0 1 2 3 4 5 x 6 7 8 9 10 N 5 5 StDev 2.54 0.417 … or here with n = 8? 20 y Var b0 b1 10 0 1 2 3 4 5 x 6 7 8 9 10 N 5 5 StDev 2.075 0.297 (1-α)100% t-interval for intercept parameter β0 Formula in words: Sample estimate ± (t-multiplier × standard error) Formula in notation: b0 t 2 ,n2 MSE 1 x2 n xi x 2 Hypothesis test for intercept parameter 0 Null hypothesis H0: 0 = some number Alternative hypothesis HA: 0 ≠ some number Test statistic b0 t* MSE 1 n x2 2 x x i b0 se b0 P-value = How likely is it that we’d get a test statistic t* as extreme as we did if the null hypothesis is true? The P-value is determined by referring to a t-distribution with n-2 degrees of freedom. Inference for intercept parameter β0 in Minitab The regression equation is Mort = 389 - 5.98 Lat Predictor Constant Lat S = 19.12 Coef 389.19 -5.9776 SE Coef 23.81 0.5984 R-Sq = 68.0% T 16.34 -9.99 P 0.000 0.000 R-Sq(adj) = 67.3% Analysis of Variance Source Regression Residual Error Total DF 1 47 48 SS 36464 17173 53637 MS 36464 365 F 99.80 P 0.000 What assumptions? • “LINE” • The intervals and tests depend on the assumption that the error terms (and thus the responses) follow a normal distribution. • Not a big deal if the error terms (and thus responses) are only approximately normal. • If you have a large sample, then the error terms can even deviate far from normality. Basic regression analysis output in Minitab • • • • • Select Stat. Select Regression. Select Regression … Specify Response (y) and Predictor (x). Click OK.