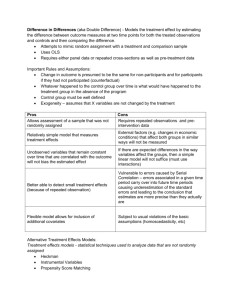
Financial Stability
advertisement

Structural modelling: Causality,
exogeneity and unit roots
Andrew P. Blake
CCBS/HKMA May 2004
What do we need to do
with our data?
• Estimate structural equations (i.e.
understand what’s happening now)
• Forecast (i.e. say something about what’s
likely to happen in the future)
• Conduct scenario analysis (i.e. perform
simulations) to inform policy
What do we need to know?
• Inter-relationships between variables
– Causality in the Granger sense
– Exogeneity
• Concepts
– Unit roots
• Spurious regression
• Role of pre-testing
• Appropriate single equation methods
0.08
0.04
0.00
-0.04
-0.08
94 95 96 97 98 99 00 01
X
Y
Inter-relationships between
variables
Period t
Period t+1
xt
xt+1
yt
yt+1
How best to estimate an
equation?
• Single equation structural model (estimated
by OLS)
• Single equation reduced form (IV/OLS)
• Structural system (estimated by TSLS,
3SLS or by a system method - SUR, FIML)
• Unrestricted VAR (OLS)
• VECM (FIML)
xt is autoregressive
Period t
Period t+1
xt
xt+1
yt
yt+1
xt has an autoregressive
representation
Period t
Period t+1
xt
xt+1
yt
yt+1
xt has an ARMA representation
xt yt t
}
yt yt 1 t
yt 1
1
x
t 1
Structural system
t 1
yt xt 1 t 1 t
so, xt xt 1 t t t 1 Reduced form
Granger Causality
Period t
Period t+1
xt
xt+1
yt
yt+1
Vector autoregressions (VARs)
Period t
Period t+1
xt
xt+1
yt
yt+1
Needs to be modelled to have
a structural interpretation
Granger causality
• If past values of y help to explain x, then y
Granger causes x
• Statistical concept
• A lack of Granger causality does not imply
no causal relationship
GC tested by an unrestricted VAR
xt a11 xt 1 a12 yt 1 b11 xt 2 b12 yt 2 ... t
yt a21 xt 1 a22 yt 1 b21 xt 2 b22 yt 2 ... t
• Definition of Granger Causality:
– y does not Granger cause x if a12=b12=...=0
– x does not Granger cause y if a21=b21=...=0
• NB. x and y could still affect each other in the
same period or via unmeasured common shocks to
the error terms.
Eviews Granger causality test result
Null Hypothesis
x does not Granger Cause y
y does not Granger Cause x
F-Statistic Probability
F1
F2
P1
P2
• The closer P1 is to zero, the less the likelihood of
accepting the null that x does not Granger cause y.
• (P1<0.10 : at least 90% confident that s1 Granger
causes s2).
• P1 should be less than 0.10 for us to be reasonably
confident that x Granger causes y.
Leading indicators
y is a leading indicator of x if
• y Granger causes x;
• x does not Granger cause y;
• and y is weakly exogenous.
73
.2
74
.2
75
.2
76
.2
77
.2
78
.2
79
.2
80
.2
81
.2
82
.2
83
.2
84
.2
85
.2
86
.2
87
.2
88
.2
89
.2
90
.2
91
.2
92
.2
93
.2
94
.2
95
.2
96
.2
97
.2
% on year earlier, smoothed, prices lagged 6
quarters
Long term trends of money and prices
in UK
30.0
25.0
20.0
15.0
10.0
5.0
0.0
Broad Money
Prices
Criticisms of Granger causality
• Granger causality can be assessed using an
unrestricted VAR - not tied to any particular
theory
• How would you explain to your governor
when it goes wrong?
• It depends on the choice of lags, data
frequency and variables in VAR
Exogeneity
• Engle et al. (1983)
– Separate parameters into two groups
– Those that matter, those that don’t
• These are endogenous and weakly
exogenous variables
• In practice a bit more complicated than that
Exogeneity (cont.)
• Correct assumptions of exogeneity simplify
modeling, reduce computational expense
and aid interpretation
• But incorrect assumptions may lead to
inefficient or inconsistent estimates and
misleading forecasts
Exogeneity (cont.)
• A variable is exogenous if it can be taken as
given without losing information for the
purpose at hand
• This varies with the situation
• We do not want the independent variables to
be correlated with the regressors
• If they are, the estimates will be biased
Relationships between variables
Period t
Period t+1
xt
xt+1
yt
yt+1
• We do not want the black arrows
• We need to understand the red arrows
Both demand and supply shocks
14
12
P
10
8
6
4
2
0
0
1
2
3
4
5
6
Q
OLS is unable to identify either the demand or supply curve
Only supply shocks
14
12
P
10
8
6
4
2
0
0
1
2
3
4
5
Q
We can identify the demand schedule using OLS
6
Weak exogeneity
• Is y weakly exogenous with respect to x?
• Do values of current x affect current y?
• Are x and y both affected by a common
unmeasured third variable?
• Does the range of possible values for the
parameters in the process that determines x
affect the possible values of those that
determine y
Weak exogeneity: example 1
• Money demand function:
mt yt rt
• Would you estimate this as a single equation
using OLS?
• Very unlikely that money does not affect
real output or the nominal interest rate
Weak exogeneity: example 2
• Uncovered interest parity:
E t et 1 rt rt
*
• Tests of UIP have performed very poorly,
but ...
• No risk premia and monetary policy might
react to exchange rate changes
Interest rate
differentials
Exchange
rate change
Question: how would you test for exogeneity in UIP?
Weak exogeneity: example 3
• In UK consumption had been forecast using
single-equation ECM
• But relationship broke down in late 1980s
• Problem was that possibility that wealth
reactions to disequilibrium had been
ignored
Single Equation ECM
yt yt 1 xt xt 1 ...
Dynamic terms
... yt 1 xt 1
Long run
Vector ECMS
xt 1yt 11xt 1 12 yt 1 ... 1 ECM
yt 2 xt 21xt 1 22 yt 1 ... 2 ECM
Halfway between structural VARs and
unrestricted VARs
Strong exogeneity
• Necessary for forecasting
• Is y strongly exogenous to x?
– Is y weakly exogenous to x
– Does x Granger cause y?
• Need the answers to be yes and no
respectively
Strong exogeneity: example
First order VAR, ‘core’ and non-‘core’ inflation:
zt Azt-1 t , zt xt , yt '
Given a forecast of {yt} can we forecast {xt}?
• If y is not strongly exogenous to x, feedback
problems
Super exogeneity
Necessary for policy/scenario analysis. Is y super
exogenous to x?
• Is y weakly exogenous to x?
• Is the relationship between x and y invariant?
Need the answers to be yes to both
Invariance
• The process driving a variable does not
change in the face of shocks
• Linked to ‘deep parameters’
• Example: the Lucas critique
Testing for weak exogeneity:
orthogonality test
• Estimate a reduced form (marginal model)
for x, regress x on any exogenous variables
of the system
• Take residuals from this reduced form and
put them into the structural equation for y
• If they are significant then x is not weakly
exogenous with respect to the estimation of
c10
Testing for weak exogeneity with
respect to c(lr)
• Estimate a reduced form (marginal model) for x:
regress x on exogenous variables of system,
including lagged ECM term involving x and y
• Test if coefficient of ECM term is significant
• If it is, then x is not weakly exogenous with
respect to the estimation of long-run coeff, c(lr)
• Consequence is that estimate is inefficient
Stationarity
• Why should we test whether series are stationary?
• A non-stationary time series implies that shocks
never die out
• The mean, variance and higher moments depend
on time
• Standard statistics do not have standard
distributions
• Problem of spurious regression
Non-stationarity
• Start with the following expression
yt = + yt-1 + ut u, 2
• Substitute recursively:
yt = n + n yt-n + n-1jut-j
• The variable will be non-stationary if =
E(y)=t
Var(y) = Var(n-1ut-j - t) = t 2
• Displays time dependency
Non-stationarity (cont.)
• t is a stochastic trend
• The series drifts upwards or downwards
depending on sign of ; increases if positive
• Stationary series tend to return to its mean value
and fluctuate around it within a more-or-less
constant range
• Non-stationary series has a different mean at
different points in time and its variance increases
with the sample size
Non-stationarity (cont.)
•
•
•
•
•
•
Mean and variance increase with time
yt = n + n yt-n +n-1jut-j
If = then shocks never die out
If | |<1 as n, then y is like a finite MA
What do non-stationary series look like?
Could show made-up series (with and
without drift)
Difference vs trend stationarity
• Compare previous equation with
yt = a + b t + ut
E(y) = a + b t
var(y) = 2
• b t - deterministic trend
• But stationary around a trend
E(y - b t) = a
Difference vs trend stationarity (2)
• Compare two generated series
• Stationary around trend
• Difference stationary are non-constant
around a trend
• But can be difficult to tell apart
• Also difficult to tell series with AR
coefficients 1 and 0.95
Difference vs trend stationary
80
500
60
400
40
300
20
200
0
100
-20
0
00
10
20
30
40
50
X
60
70
Z
80
90
00
Difference vs trend stationarity
• Can you tell the difference?
xt = 1 + xt-1 + 0.6 ut
zt = 1 + 0.15 t + 0.8 et
• Can you tell the difference with a near-unit
root?
Unit root vs near-unit root
50
500
40
400
300
30
200
20
100
10
0
00
0
00
01
02
03
04
05
06
07
08
09
10
20
30
40
50
X
X
W
60
10
W
70
80
90
00
Testing for unit roots
• Dickey-Fuller test
• Write
yt = yt-1 + et
as
yt - yt-1 = (-1)yt-1 + et
Null: Coefficient on lagged value 0, vs < 0
Dickey-Fuller tests
•
•
•
•
Test akin to t-test but distributions not standard
Depends if series contains constant and/or trends
Must incorporate this into DF test
Augmented DF test - use lags of dependent
variable to remove serial correlation
• All of these must be checked against relevant DF
statistic
• But introducing extra variables reduces power
Unit versus near-unit roots
• Thus difficult to tell the difference between
two series over small samples
• Low power of ADF tests (sample of 400)
x: ADF statistic -0.77048 p-value 0.8258
w: ADF statistic -6.90130 p-value 0.0000
• Small sample (40 observations)
x: ADF statistic 0.39323 p-value 0.9804
w: ADF statistic -0.49216 p-value 0.8828
Stationarity in non-stationary
time series
• A variable is integrated of order d - I(d) - if
it musto be differenced d times for
stationarity
• The required number of differences depends
on the number of unit roots a series has
• For example, an I(1) variable needs to be
differenced once to achieve stationarity: it
has only one unit root
Spurious regressions
• Trends in data can lead to spurious
correlation between variables: there appears
to be meaningful relationships
• What is present are uncorrelated trends
• Time trend in a trend-stationary variable can
be removed by regressing variable on time
• Regression model then operates with
stationary series with constant means and
variances (standard t and F test inferences)
Spurious regressions
• Regressing a non-stationary variable on a
time trend generally does not yield a
stationary variable (it must be differenced)
i.e. taking trend away does not lead to
stationarity
• Using standard regression techniques with
non-stationary data can lead to the problem
of spurious regression involving invalid
inference based on usual t and F tests
Spurious regressions
• Consider the following DGP:
yt = yt-1 + ut u , 1
xt = xt-1 + et e , 1
• y and x are uncorrelated, but estimating
y t = a + b xt + v t
we find that we can reject b = 0.
• Why? Non-stationary data => v nonstationary gives problems with t and F stats
• Also find high R2 and low DW (G&N 1974)
Spurious Regressions
Dependent Variable: Y
Method: Least Squares
Date: 03/31/03 Time: 18:28
Sample: 1900:1 2003:4
Included observations: 416
Variable
X
R-squared
Adjusted R-squared
S.E. of regression
Sum squared resid
Log likelihood
Coefficient
Std. Error
t-Statistic
Prob.
0.964478
0.001112
867.6800
0.0000
0.997879
0.997879
5.543177
12751.63
-1302.206
Mean dependent var
S.D. dependent var
Akaike info criterion
Schwarz criterion
Durbin-Watson stat
202.9399
120.3730
6.265414
6.275103
0.023766
Spurious regression
• Why do we find significant coefficients?
• What will happen if we estimate a spurious
regression with the variables in first
differences?
• What ‘economic problem’ do we encounter
if we only use differenced variables in
economics?
• We lose information about the long-run
Spurious Regression
Dependent Variable: DY
Method: Least Squares
Date: 03/31/03 Time: 18:36
Sample(adjusted): 1900:2 2003:4
Included observations: 415 after adjusting endpoints
Variable
C
DX
R-squared
Adjusted R-squared
S.E. of regression
Sum squared resid
Log likelihood
Durbin-Watson stat
Coefficient
Std. Error
t-Statistic
Prob.
0.989704
-0.005194
0.016085
0.012185
61.52980
-0.426235
0.0000
0.6702
0.000440
-0.001981
0.211922
18.54827
56.03014
1.752192
Mean dependent var
S.D. dependent var
Akaike info criterion
Schwarz criterion
F-statistic
Prob(F-statistic)
0.984475
0.211713
-0.260386
-0.240973
0.181676
0.670159
Cointegration (definition)
• In general, regressing two I(d) variables, d>0,
leads to the problem of spurious regression
• Assume two I(d) variables and estimate:
yt xt t
• If is a vector such that t is I(d-b) then we say
that y and x are co-integrated of order CI(d,b)
What is cointegration?
• If two (or more) series have an equilibrium
relationship in the long run even though the
series contain stochastic trends they move
together such that a (linear) combination of
them is stationary
• Cointegration resembles a long-run
equilibrium and differences from the
relationship are akin to disequilibrium
• Trivially, a stationary model must be
Modelling the short-run
• Are we ever in the long run?
• How do we model the short run?
• Problem of using only differenced data and
the loss of long-run information
• Assume yt xt t
• In steady state yt xt 0 has little
meaning for the long run
Modelling short run
• Assume
yt = xt + yt-1 + xt-1 + t, , 2
• If a LR relationship exists
yt = + xt
• We can write
yt = xt - (1- )(yt-1 - - xt-1 ) + t
• (1- ) is speed of adjustment
• Implications for the sign of ECM
Modelling the short-run
• There are some issues about the estimation
of
• Stock (1987) shows that OLS is fine, is
super-consistent; the estimator converges to
its true value at a faster rate when a series is
I(1) than when it is I(0)
• However, there is significant of bias in
small samples
Testing strategies
• Perron’s suggestion:
– start with regression with constant and trend
– proceed trying to reduce unnecessary paramaters
– if we fail to reject parameters continue testing until
we are able to reject the hypothesis of a unit root
• In the end we should use common sense and
economics
– If there should not be a unit root - probably a
break
Cointegration and single
equations
• When looking at single equations it is easy
to test for cointegration
– Engle and Granger two-step procedure
– Engle-Granger-Yoo three-step approach
• What if there is more than a single
cointerating relationship?
– Need a system approach
– VECMs
Modelling strategies
• Understand the data
– Do whatever tests necessary to be sure of using
appropriate models
• Understand the limitations of individual
methods
– By not taking limitations into account a rejection does
not necessarily imply that the hypothesis is false
• Use appropriate methods for different
problems
EXOGENEITY
•
Banerjee, A, D.F. Hendry and G.E. Mizon (1996) “The econometric analysis of economic policy”, Oxford Bulletin of
Economics and Statistics 58(4), 573-600
•
Ericsson, N.R. and J.S. Irons (eds) (1994) Testing Exogeneity. Advanced Texts in Econometrics. Oxford University
Press.
•
Lindé, J. (2001) “Testing for the Lucas Critique: A quantitative investigation”, American Economic Review 91(4),
986-1005.
•
Monfort, A and R. Rabemananjara (1990) “From a VAR model to a structural model, with an application to the wageprice spiral”, Journal of Applied Econometrics 5, 203-227
•
Urbain, J.P. (1995) “Partial versus full system modelling of cointegrated systems: An empirical illustration”,
Journal of Econometrics 69(1), 177-210.
•
Boswijk, P. and J.P. Urbain (1997) “Lagrange Multiplier tests for weak exogeneity: A synthesis”,
Econometric Reviews 16(1), 21-38.
•
Charezma, W.W and D.F. Deadman, (1997) New Directions in Econometric Practice, Edward Elgar, Second Edition.
•
Urbain, J.P. (1992) “On weak exogeneity in error correction models”, Oxford Bulletin of Economics and Statistics
54(2), 187-207.
MODELLING AND FORECASTING SHORT-TERM DATA
•
Jondeau, É., H. Le Bihan and F. Sédillot (1999) Modelling and Forecasting the French Consumer Price Index
Components, Banque de France Working paper 68.
•
Clements, M. P. and D.F. Hendry (1999) Forecasting non-stationary economic time series. MIT Press.
•
Bardsen, G and P.G. Fisher (1996) On the roles of economic theory and equilibria in estimating dynamic econometric
models-with an application to wages and prices in the United Kingdom, Essays in Honour of Ragnar Frisch.
VARS
•
Levtchenkova, S., A.R. Pagan and J.C. Robertson (1998) “Shocking stories”, Journal of Economic Surveys 12(5),
507-532.