ppt
advertisement

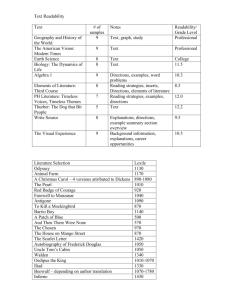
A characteristic of text documents..
“the sum total of all those elements within a given piece of
printed material that affect the success of a group of readers
have with it. The success is the extent to which they
understand it, read it at an optimal speed, and find it
interesting.” (Dale & Chall, 1949)
“ease of understanding or comprehension due to the style of
writing” (Klare, 1963)
Readability encompasses a number of areas…
Syntactic complexity of the text
▪ grammatical arrangement of words within a sentence,
(e.g. active / passive sentences have been shown to
affect readability)
▪ Simple/compound sentence/complex sentences
Organization of text
▪ discourse structure
▪ textual cohesion
Semantic complexity of the text
Improve literacy rate
Improving instruction delivery
Judging technical manuals
Matching text to appropriate grade level
And many more…
Assign score to text based on some textual
cues (e.g., average sentence length)
Readability formula
Over 200 formulas by 1980s (DuBay 2004)
Textual cues
▪ sentence length, percentage of familiar words, and word
length, syllables per word etc.
Testing validity: correlating predicted score to
reading comprehension score
Flesch Reading Ease score
Score = 206.835 – (1.015 × ASL) – (84.6 × ASW)
Score in [0 to 100]
ASL = average sentence length
ASW = average number of syllables per word
Dale-Chall Formula
Maintains a list of “easy words”.
Score = .1579PDW + .0496ASL + 3.6365
▪ PDW= Percentage of Difficult Words
FOG index
Lexile scale
Commonalities among formulae
Linear regression over some predictor variables
Traditional readability measures are robust
for large sample size (textbook and essays) as
compared to short and consize web
documents.
Web documents are generally noisy
Resource: Predicting Reading Difficulty With Statistical Language Models, Kevyn
Collins-Thompson and Jamie Callan
LM can encode more complex relationships
as compared to simple linear regression
model in traditional readability measures
A probabilistic distribution in all grade levels
Relative difficulty of words can be obtained
statistically as compared to hardcoded
approach in traditional measures
Earlier grade readers tend to use more
concrete words (e.g. red); later grade readers
use more abstract words (e.g., determine)
Same observations in web documents
Syntactic features are ignored
Word (semantic) feature based model
Formulated in a classification framework
For a given text passage 𝑇, predict the semantic
difficulty of 𝑇 relative to a specific grade level 𝐺𝑖
▪ Likelihood that the words of 𝑇 were generated from a
representative language model of 𝐺𝑖
words
Text
𝐿𝑀𝐺1
𝐿𝑀𝐺2
𝐺1 difficulty score
𝐺2 difficulty score
𝐿𝑀𝐺𝑛
𝐺𝑛 difficulty score
Word type 1
𝑤1
Word type 2
(𝑤2 )
𝑻
Token
𝐿𝑀 𝐺𝑖 = {𝑃 𝑤1 𝐺𝑖 , 𝑃 𝑤2 𝐺𝑖 , … , 𝑃(𝑤𝑘 |𝐺𝑖 )}
Word type k
(𝑤𝑘 )
“In a recent three-way election for a large country, candidate A
received 20% of the votes, candidate B received 30% of the
votes, and candidate C received 50% of the votes. If six voters
are selected randomly, what is the probability that there will be
exactly one supporter for candidate A, two supporters for
candidate B and three supporters for candidate C in the
sample?”
6!
𝑃 𝐴 = 1, 𝐵 = 2, 𝐶 = 3 =
0.21 0.32 0.53 = 0.135
1! 2! 3!
Multi-nomial Distribution
𝑛 independent trials
▪ Each of which leads to a success of exactly one of 𝑘
categories
▪ Each category has a given fixed success probability
▪ Probability mass function
𝑓 𝑥1 , 𝑥2 , … , 𝑥𝑘 ; 𝑛, 𝑝1 , 𝑝2 , … , 𝑝𝑘
= 𝑃 𝑋1 = 𝑥1 , 𝑋2 = 𝑥2 , … 𝑋𝑘 = 𝑥𝑘
𝑛!
=
𝑝1𝑥1 … 𝑝𝑘𝑥𝑘
𝑥1 ! … 𝑥𝑘 !
Unigram language model
Hypothetical author generates tokens of 𝑇as
follows:
Choosing a grade language model 𝐺𝑖 according to
prior probability distribution 𝑃(𝐺𝑖 )
▪ “I will write for grade level 4” [explicit]
Choosing a passage length |𝑇| according to
probability distribution 𝑃(|𝑇|)
▪ “I will write no more than 100 words” [Explicit/Implicit]
Sampling |𝑇| tokens from 𝐺𝑖 ’s multi-nomial word
distribution
▪ “I will pick up words with certain distribution” [Implicit]
We need to compute 𝑃 𝐺𝑖 𝑇 : Probability
that 𝑇 is generated from LM 𝐺𝑖
Bayes’ Theorem 𝑃 𝐺𝑖 𝑇 =
𝑃 𝐺𝑖 𝑃(𝑇|𝐺𝑖 )
𝑃(𝑇)
Compute 𝑃(𝑇|𝐺𝑖 )
▪ 𝑃 𝑐ℎ𝑜𝑜𝑠𝑖𝑛𝑔 𝑎 𝑡𝑒𝑥𝑡 𝑜𝑓 𝑙𝑒𝑛𝑔𝑡ℎ 𝑇 ×
𝑚𝑢𝑙𝑡𝑖𝑛𝑜𝑚𝑖𝑎𝑙 𝑑𝑖𝑠𝑡𝑟𝑖𝑏𝑢𝑡𝑖𝑜𝑛 𝑜𝑓 𝑢𝑛𝑖𝑔𝑟𝑎𝑚𝑠 𝑖𝑛 𝐺𝑖
▪ 𝑃 𝑇 𝐺𝑖 = 𝑃 𝑇
𝑇!
𝑃(𝑤|𝐺𝑖 )𝐶(𝑤)
𝑤∈𝑉
𝐶 𝑤 !
Classification model
arg max 𝑃(𝐺𝑖 |𝑇)
𝑖
𝑃(𝑤|𝐺𝑖 )𝐶(𝑤)
𝑃 𝐺𝑖 𝑃 𝑇 𝑇 ! 𝑤∈𝑉
𝐶 𝑤 !
= arg max
𝑖
𝑃(𝑇)
𝑃(𝑤|𝐺𝑖 )𝐶(𝑤)
= arg max 𝑃 𝐺𝑖 𝑃 𝑇 𝑇 !
𝑖
𝐶 𝑤 !
𝑤∈𝑉
Classification model
arg max log 𝑃(𝐺𝑖 |𝑇)
𝑖
=
arg max[
𝑖
𝑤∈𝑉 𝐶
𝑤 log 𝑃(𝑤|𝐺𝑖 ) −
𝑤∈𝑉 log 𝐶
log 𝑃 𝐺𝑖 + log 𝑃 𝑇 + log( 𝑇 !)]
𝑤 !+
Simplified assumptions
All grades are equally likely a priori
All passage lengths are equally likely
Simplified classification model
arg max log 𝑃(𝐺𝑖 |𝑇)
𝑖
= arg max[
𝑖
𝐶 𝑤 log 𝑃(𝑤|𝐺𝑖 ) −
𝑤∈𝑉
log 𝐶 𝑤 ! +
𝑤∈𝑉
log 𝑃 𝐺𝑖 + log 𝑃 𝑇 + log( 𝑇 !)]
Simplified classification model
arg max log 𝑃(𝐺𝑖 |𝑇) =
𝑖
arg max[
𝑖
𝑤∈𝑉 𝐶
𝑤 log 𝑃(𝑤|𝐺𝑖 )]
Example 1: Passage 𝑻 = "the red ball”
𝐿 𝐺1 𝑇 = 𝑙𝑜𝑔 0.0600 + 𝑙𝑜𝑔 0.0008 +
𝑙𝑜𝑔 0.00010 = −𝟖. 𝟑𝟏𝟗
𝐿 𝐺5 𝑇 =
log 0.0700 + log 0.0004 + log 0.00005 = −8.8 54
𝐿 𝐺12 𝑇 =
log 0.08 + log 0.0002 + log 0.00001 = −9.796
Example 2: Passage T “the red perimeter”
𝐿 𝐺1 𝑇 = −9.319
𝐿 𝐺5 𝑇 = −8.076
𝐿 𝐺12 𝑇 = −9.097
Example 2: Passage T “the perimeter was optimal”
𝐿 𝐺1 𝑇 = −12.523
𝐿 𝐺5 𝑇 = −11.678
𝐿 𝐺12 𝑇 = −11.097
What if a word does not belong to a language
model for a grade level
A 0 probability will be assigned
Redistribute a part of probability mass of known
words to rare and unseen words
Smooth individual grade-based language
model using Good-Turing smoothing
We have estimate of total probability mass of all
unseen words
We need to find each unseen word’s share of this
total probability mass
Uniform probability distribution?
Usage of discriminative words are clustered
towards grade levels.
Borrow probability mass from neighboring grade
classes
The type w occurs in one or more grade models
(which may or may not include 𝐺𝑖 )
𝑃 𝑤 𝐺𝑖 =
𝑘 𝛼𝑘 𝑃𝑘
𝑘 𝛼𝑘
▪ 𝑃𝑘 = 𝑃 𝑤 𝐺𝑘
▪ 𝛼𝑘 = 𝜙 𝑖, 𝑘, 𝜎 is a kernel distance function between i and
k.
▪ Gaussian Kernel
▪ 𝜙 𝑖, 𝑘, 𝜎 = exp −
𝑖−𝑘 2
𝜎2
𝒊
𝒌
Readability Score assigned documents
𝒑𝟏 , 𝒑𝟐 , … . , 𝒑𝒏
New
doc
Training
Regression Model:
𝑹 = 𝜷𝟎 + 𝜷𝟏 𝒑𝟏 + … . +𝜷𝒏 𝒑𝒏
Readability Score
Resource: Revisiting Readability: A Unified Framework for Predicting Text Quality, Emily
Pitler and Ani Nenkova
There are different predictor variables
indicating readability score
What is a the contribution of individual predictor
variable in readability score?
Testing methodology
Collect
Readability
Corpus
Extract
Predictor
Variable
Measure
<readability score,
predictor
variable>Correlation
Pearson product-moment correlation
coefficient (𝑟)
Captures relationship between two variables that
are linearly related (𝑌 = 𝛽0 + 𝛽1 𝑋).
𝑟=
(𝑋𝑖 −𝑋)(𝑌𝑖 −𝑌)
2
𝑋𝑖 −𝑋 2 (𝑌𝑖 −𝑌)
−1 ≤ 𝑟 ≤ +1
-Ve
+Ve
+Ve
-Ve
How statistically significant 𝑟 value is?
t-test for statistical significance
▪ Expressed through 𝒑-𝒗𝒂𝒍𝒖𝒆
▪ Computed through null hypothesis
the use of drug X to treat disease Y is no better than not using any
drug
▪ 𝒑-𝒗𝒂𝒍𝒖𝒆 of 0.001 signifies
▪ there is a 1 in 100 chance that we would have seen these observations
if the variables were unrelated.
▪ If 𝒑-𝒗𝒂𝒍𝒖𝒆 computed for a dataset is less than predefined
limit (say 𝑝 < 0.001), null hypothesis is rejected.
▪ Correlation is statistically significant
Methodology
Create a readability dataset
▪ “On a scale of 1 to 5, how well written is this text?”
Identify a group of predictor variables
Measure correlation between readability scores
and value of predictor variable
Decide on the effectiveness of predictor variables
based on correlation score and 𝑝-𝑣𝑎𝑙𝑢𝑒
Average Characters/Word
the average number of characters per word
Average Words/Sentence
average number of words per sentence
Max Words/Sentence
Maximum number of words per sentence
Text length
Limit on 𝑝-𝑣𝑎𝑙𝑢𝑒=0.05
Unigram model: probability of an article
𝐶(𝑤) , 𝑀
𝑤 𝑃(𝑤|𝑀)
is the background corpus
▪ Wall Street Journal and AP News corpus
Log-likelihood
𝑤𝐶
𝑤 log(𝑃(𝑤|𝑀))
This model will be biased towards shorter
articles
Why?
Compensation
Linear regression with predictor variables as log-
likelihood and no of words in the article
Log likelihood, WSJ
article likelihood estimated from a language model from WSJ
Log likelihood, NEWS
article likelihood according to a unigram language model from NEWS
LL with length, WSJ
Linear regression of WSJ unigram and article length
LL with length, NEWS
Linear regression of NEWS unigram and article length
Average parse tree height
Average number of noun phrases per sentence
Average number of verb phrases per sentence
Average number of subordinate clauses per
sentence
Counting SBAR nodes in parse tree
Curious case of average verb phrases
No of verb phrases per sentence may increase the
text complexity
▪ average verb phrases should have a negative correlation
Let’s look at the following examples
It was late at night, but it was clear. The stars were
out and the moon was bright. (1)
It was late at night. It was clear. The stars were out.
The moon was bright. (2)
Aspects of well written discourse
Cohesive devices like pronouns, definite descriptions,
topic continuity
Number of pronouns per sentence
Number of definite articles per sentence
Average cosine similarity
Word overlap
Word overlap over nouns and pronouns
Entity based approach towards local
coherence
discourse coherence is achieved in view of the way
discourse entities are introduced and discussed
Some entities are more salient than others
▪ Salient entities are more likely to appear in prominent
syntactic positions (such as subject or object), and to be
introduced in a main clause.
▪ Centering theory models the continuity of discourse
Entity-Grid discourse representation
Each text is represented by an entity grid
▪ A two-dimensional array that captures the distribution
of entities across text sentences.
Optional Resource: Modeling Local Coherence: An Entity-Based Approach, Regina
Barzilay and Mirella Lapata
S => Entity appears in
subject phrase
O => Entity appears in
subject phrase
X => appears in any
other phrase
− => does no appear
If a noun phrase appears more than once in a sentence, we resort to
grammatical role based ranking [S>O>X]
-- Sentence 1: ‘Microsoft’ appears as subject (S) and rest (X) category
-- Mark entry for Microsoft as S
A local entity transition is a sequence
𝑆, 𝑂, 𝑋, − 𝑛
represents entity occurrences and their syntactic
roles in 𝑛 adjacent sentences
Each transition will have certain probability
given a grid.
𝑃 𝑆, −
=6
75
= 0.08
Text -> distribution defined over transition
types
Feature vector
Probability counts for a fixed set of transition types
Each grid rendering 𝑗 of document 𝑑𝑖
Φ 𝑥𝑖𝑗 = (𝑃1 𝑥𝑖𝑗 , 𝑃2 𝑥𝑖𝑗 , … , 𝑃𝑚 (𝑥𝑖𝑗 ))
▪ 𝑚 is the number of predefined transitions
▪ 𝑃𝑡 (𝑥𝑖𝑗 ) is the probability of transition 𝑡 in grid 𝑥𝑖𝑗
Sentence Ordering Task
determining an optimal sequence in which to
present a pre-selected set of information-bearing
items
▪ Concept-to-Text generation
▪ Multi-document summarization
Simpler task
▪ Rank alternative sentence ordering
▪ Which from pair of ordering (𝑑𝑜1 > 𝑑𝑜2 ) is better in terms of
coherence?
Training set
Ordered pairs of alternative rendering 𝑥𝑖𝑗 , 𝑥𝑖𝑘 of same
document 𝑑𝑖 .
▪ Where degree of coherence for 𝑥𝑖𝑗 is greater than that of 𝑥𝑖𝑘 .
Training objective
▪ To find parameter vector 𝒘
▪ To yield a ranking score function that minimizes number of violations of
pairwise rankings provided in training set
Modelling
▪ ∀ 𝑥𝑖𝑗 , 𝑥𝑖𝑘 ∈ 𝑟 ∗ : 𝑤. Φ 𝑥𝑖𝑗 > Φ(𝑥𝑖𝑘 )
▪ 𝑤. Φ 𝑥𝑖𝑗 − Φ 𝑥𝑖𝑘
>0
▪ Support Vector Machine Conctraint Optimization problem
Consider a document as a bag of discourse
relations
Language model defined over relations instead of
words
Probability of a document generated with 𝑛 number
of relation tokens and 𝑘 number of relation types
Log-likelihood of a document based on its discourse
relations
▪ log 𝑃 𝑛 + log 𝑛! +
𝑘
1 (𝑥𝑖
log 𝑝𝑖 − log(𝑥𝑖 !))
Increase in number of discourse relations in a
document will lower the log-likelihood
Number of relations in a document as feature
200+ readability measures and still counting
Are they really looking at deeper aspects of
language comprehension?
Are they tuned towards individual reading
abilities?
Is reader in the loop?
How do we comprehend sentences?
How do we store and access words?
How do we resolve ambiguities?