Homework #1:
advertisement

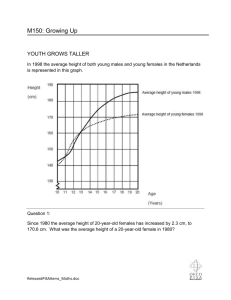
Psych 3101 Keller 1 3/19/16 Name:___________________________ Homework #2: Central Tendency and Variability. Due: 2/9/2012 Part 1: To be done in R: Question 1: A) Select one of the variables listed below from the fcq dataset and write a description of it. To load fcq into R, as well as lots of other datasets we’ll be using for this and other HWs, just type this into R: load(url("http://www.matthewckeller.com/Stats3101/Stat3101.Datase ts.RData")) Use the ls() command to view the available datasets, use ls(fcq) to view the variable names in the fcq dataset. Base your description on measures of the center (typical value) and examination of the histogram. Describe the shape of the distribution as well as a verbal description of its spread - whether most scores are close to the measure of central tendency (little spread) or whether scores tend to be far away from the measure of central tendency. B) When there are many observations, another useful plot in R is the estimated density function, which is really a smoothed histogram. For example, to obtain this plot for the course variable, you would use: plot(density(fcq$course)) Note the use of “$” to ‘grab’ the variable or column of the dataset that you are interested in. You can also control the number of bins in the histogram. Again with many observations, a greater number of categories or bins (or breaks) than the default number is appropriate. For example, try hist(fcq$course, breaks=30) Select one of the following variable from the fcq dataset and generate the density function and histogram: instructor – the average student rating of the instructor on 0 to 4 scale percentReturn – the percentage of enrolled students returning valid forms nEnrolled – the official size of the class avgGrade – the average grade received by students in the class percentA – the percentage of students in the class receiving grades of A percentD_F – the percentage of students in the class receiving D’s or F’s Psych 3101 Keller 2 3/19/16 NOTE: variable names in R are case-sensitive, so “avgGrade” is not the same as “avggrade.” Also, remember that each observation in this dataset corresponds to an entire class of students. There is no information about individual students in this dataset. To simplify typing, you can assign a new, shorter name to any variable. For example, to avoid having to type nEnrolled, you could first assign the name size as: size <- fcq$nEnrolled and then simply type size whenever you wanted to refer to nEnrolled. C) Write a summary describing the variable you chose above. Begin your paragraph with a sentence suggesting why we would be interested in this variable and end your paragraph with a no-number sentence stating some conclusion or overall summary. Question 2: In the survey you completed on the first day of class, you were asked how many times per day you check email. We’re interested in the following question: do lower division students (freshmen and sophomores) check email more than upper division students (junior and seniors)? A) Create and interpret two side-by-side boxplots to help figure out this question: boxplot(survey$email_check ~ survey$class_status) Describe what the two boxplots are telling you (i.e., describe the measures of central tendency and spread and whether these statistics are different between upper vs. lower division status). B) How sure are you that lower division students at CU check email more frequently? Is it likely that the two sample means or medians will be exactly the same, even if the population means are equal? Why or why not? C) What is the standard deviation of how often lower division students check their email? What is it for upper division students? Explain both of these numbers in plain English in a way that your grandma could understand. To do this in R for lower division students, do this: sd(survey$email_check[survey$class_status=="LOW"],na.rm=TRUE) Question 3: In this class, we will often ask you for a “four sentence summary of results.” (NOTE: the four sentence summary will be on all 4 tests you take in this class). The four sentence summary mirrors the four sections of an APA formatted paper, and is made up of the following: 1st sentence: The Introduction. State the problem, or what you are interested in looking at. 2nd sentence: The Method. How did you go about solving this problem? 3rd sentence: The Results. What did you find? 4th sentence: The Discussion. What is your conclusion? Psych 3101 Keller 3 3/19/16 For example, let’s say we’re interested in whether female undergraduates check their email more frequently than male undergraduates. We could use our survey results to try to answer this in the following way: Example 4-sentence summary We are interested in whether females check their email more frequently on average than males do. To investigate this problem, we asked 71 females and 37 males enrolled in an undergraduate statistics class at the University of Colorado how many times they checked their emails per day. We found that females check their emails 5.6 times per day on average (SD=5.56) whereas males check their emails 3.8 times per day (SD=3.97). We conclude that female undergraduates do indeed appear to check their email more frequently, although we cannot say for certain if this difference arose by chance or not (exists only in this sample but not in the population). I used the following R syntax to find these results: males <- survey[survey$gender=="M",] #this gave me a dataset of all the males females <- survey[survey$gender=="F",] #this gave me a dataset of all the females mean(males$email_check, na.rm=TRUE) sd(males$email_check, na.rm=TRUE) mean(females$email_check, na.rm=TRUE) sd(females$email_check, na.rm=TRUE) Choose any dependent variable in the “survey” dataset you wish, and compare this dependent variable (its means and standard deviations) across two groups (males vs. females; employed vs. not, people with boy/girlfriends vs. not; people in fraternities/sororities vs. not; people from Colorado vs not; people who expect to get A’s vs. not, etc.). The dependent variable you choose should be a continuous or interval variable. The independent or quasi independent variable you choose should be nominal. A) Identify the independent or quasi-independent variable. B) Identify the dependent variable. C) What type of study are you conducting (e.g., an experiment?)? Can you make causal inferences that the independent variable caused a change in your dependent variable? Why or why not? D) Attach a boxplot to your HW comparing the two variables (as was done in 4A). Comment on what the boxplot shows you. E) Attach a histogram of the dependent variable to your HW. Comment on what the histogram shows you. To make a histogram in R: hist(x) #where x is your dependent variable Psych 3101 Keller 4 3/19/16 F) When R calculated the standard deviation of your dependent variable, did it divide by n or by n-1? Why? G) Trying writing up a four sentence summary of your findings (good practice for when you will do it on a test!). Part 2: To be done by hand: Question 1: For the following set of scores: 33 26 208 12 37 25 34 29 26 30 33 15 35 38 31 A) Draw a stem-and-leaf plot B) Compute the mean, median, and mode (show your work) C) What is the range? What is a disadvantage of the range statistic? D) What is the median, 1st quartile, 3rd quartile, and inter-quartile range? C) Which measure of central tendency do you think is best of this distribution? Why? Question 2: A sample of n = 5 scores has a mean of 10. One new score is added to the sample and the new mean is computed to be 11. What is the value of the score that was added to the sample? Show your work. Question 3: The median height in a sample is 70 inches. The (very tall) basketball player, Shaq O’Neil is part of this sample. A) Describe the likely shape of the distribution of heights. B) If there are 9 people in the sample, what percent of the sample has a height less than 70? C) Would you guess that the mean is greater than, equal to, or less than 70? Why? Psych 3101 Keller 5 3/19/16 D) If we remove Shaq from the sample and add in John Doe (who is 72 inches tall), what is the median of this new sample? Question 4: A) John (an imaginary friend of yours) says that Mark is a jerk. How sure are you that Mark is a jerk? What other possibilities might exist for why John said this other than that Mark really is a jerk? B) Now say that Jill, James, Julie, and Janice also said that Mark is a jerk. Does this change your subjective guess (i.e., your internal probability) that Mark really is a jerk? Why or why not? Try to explain this in a very specific (preferably mathematical) way. C) Now say that you found out that Jill, James, Julie, and Janice are all friends of John’s, and that you find out that John had been talking to the four of them about Mark before they told you that Mark is a jerk. Does this new information change your subjective guess about whether Mark is a jerk? Why or why not (again, try to be very specific)? Question 5: Explain in words what sums of squares, degrees of freedom, and variance are: Question 6: A) Let us say that somehow we know that the TRUE POPULATION MEAN of a set of numbers (that is, whatever you get for the sample mean is also the population mean). Given this information, write the formulas for the variance and the standard deviation of for the population: B) What is wrong with your answer above if we do not know the true population mean of the underlying distribution from which those numbers were drawn? Describe the issue in words and then write the correct formulas for the variance and the standard deviation of for the sample below: