Regression
advertisement

Applied Regression Analysis
BUSI 6220
Adapted from notes by:
Dr. K.N.Thompson, Dept. of Marketing, University of North Texas, 1999
Dr. S. Kulkarni, ITDS Dept., University of North Texas, 2004
Dr. N. Evangelopoulos, ITDS Dept., University of North Texas, 2012
Welcome to the UNT PhD in
Business Program! Get Socialized!
For a person to become a member of a scientific community typically involves not only the
cognitive or intellectual work required in a Ph.D. program, but also the socialization into the
ways of being a scientist in the given scientific discipline or specialty, where the socializing
typically begins with the Ph.D. student’s being a research assistant (i.e., apprentice) to a
senior professor, continues with experiences in gaining or not gaining acceptance at
conferences and journals, and eventually comes to include the tacit knowledge with which
the members of his or her particular scientific specialty are able, without conscious
deliberation, to know and agree that a particular instance of theoretical or empirical
research is valid and significant (or not). In his historical and sociological studies of natural
scientists, Kuhn (1996) has argued convincingly that a scientific theory does not exist
independently of the social forces of the particular scientific community that has developed,
championed, and refined it, but can be understood only in the social and historical context
of that particular scientific community.
Mårtensson and Lee, “Dialogical Action Research at
Omega Corporation,” MIS Quarterly Vol. 28 No. 3
(September 2004), pp. 507-536.
BusinessWeek report: Are you a top
performer?
In a confirmation of the proverbial
“Lies, Damn Lies and Statistics”1, the
question “Are you one of the top 10%
performers in your company?”
yielded some more surprising (or,
perhaps, not so surprising) results
Moral of the story: Cognitive biases
force people to lie, even to
themselves. Because of that, statistics
is often poorly understood by the
general public
1Attributed
to Benjamin Disraeli, British Prime
Minister, 1874-1880, popularized by Mark Twain
More quotations about Statistics
“Not everything
that can be counted
counts, and not
everything that
counts can be
counted”.-George
Gallup
“I’ve come loaded
with statistics, for
I’ve noticed that man
can’t prove anything
without statistics.”Mark Twain
“If we knew what it
was we were doing,
it would not be
called research,
would it”? -Albert
Einstein
Taken from The RESEARCH DIGEST Web site, http://researchexpert.wordpress.com/wise-words/
Statistics and the big facts of life
Statistics show that there
are more women in the
world than anything else.
Except insects.
Glenn Ford in
Gilda (1946)
© Columbia 1946
Statistics in National Security
Yes, well, I've worked out a few
statistics of my own. 15 billion
dollars in gold bullion weighs
10,500 tons. Sixty men would
take twelve days to load it onto
200 trucks.
Now, at the most, you're going
to have two hours before the
Army, Navy, Air Force, and
Marines move in and make
you put it back!…
Sean Connery in
Goldfinger (1964)
© United Artists 1964
How best decisions are made
We have no way of knowing
what lies ahead for us in the
future… All we can do is use
the information at hand to
make the best decision
possible!
Christopher Walken
in Wedding
Crashers (2005)
© WireImage 2003
Regression : A Definition
What is Regression Analysis?
A very “robust” statistical methodology that
traditionally has used existing relationships
between variables to allow prediction of the values
of one variable from one or more others
Examples
Sales can be predicted using advertising expenditure
Performance on aptitude tests can be used to predict job
performance
GPA after first year in PhD program can be predicted
from GMAT score
On the news: Regression line helps
catch teachers who cheat
See course Web site, “school test erasure scandal”
A historical note: “Regression to
Mediocrity”
In the late 1800s, Sir Francis Galton
observed that heights of children of both
short and tall parents appeared to come
closer to the mean of the group:
extraordinary parents gave birth to more
“ordinary” children. Galton considered
this to be a “regression to mediocrity”
Today we understand that this effect is
due to the presence of other height
predictors: children with parents of
extraordinary height may be ordinary in
other height determinants, such as
nutrition
Functional Relationship
300
$ Sales
250
200
150
100
50
0
0
10
20
30
40
50
60
70
80
90 100 110 120 130 140
Units Sold
Y = 2X
Y is the dependent or criterion variable
X is the independent or predictor variable
Value of Y exactly predicted by X
No ‘error’ of prediction exists -- a perfect
relationship between X and Y
Y = GPA at end of first
year (response variable,
criterion variable,
dependent variable)
Statistical Relationship
4
X = Entrance exam score
(predictor variable,
independent variable,
explanatory variable)
3.5
Actual GPA
3
2.5
2
y = 0.8399x - 1.6996
R2 = 0.6538
1.5
1
Each ‘dot’ is a ‘case’ or
‘trial’
0.5
0
3.9 4.1 4.3 4.5 4.7 4.9 5.1 5.3 5.5 5.7 5.9 6.1 6.3 6.5
Entrance Test Score
Scatter diagram showing relationship between two variables, Score & GPA
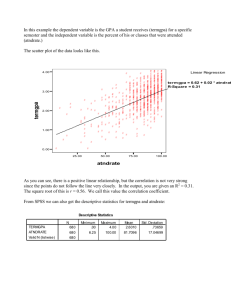
Y = -1.6996 + .8399X
X does not perfectly predict Y
Your GPA at the end of the first year cannot be exactly predicted by your score on
an entrance exam
Relationship between Score and GPA appears to be linear
Regression as a General Data
Analytic System
Ability to ‘partial’ out the effects of specific
predictor variables on the criterion in situations in
which predictors are not orthogonal to one another
Can establish the unique contributions of each predictor
to variance in the criterion
Allows identification of ‘spurious’ relationships
Study systems of causal relationships Y=f(C,D,E,
etc.)
Experimental & Non-experimental designs
Causal Modeling, Covariance Structure Modeling
(C&C pp. 1-10)
Regression as a General Data
Analytic System
Form of the data more than quantitative, interval
or ratio
Data can range from nominal to ratio
Nominally scaled predictors
• Traditionally assessed within the context of ANOVA,
ANCOVA (by “grouping” the Y values)
• Can be incorporated into regression models with the help of
dummy variables
Shape of relationship need not be linear
Predictors may be linear or non-linear
Transformations of non-linear data possible to produce
linearity required for the regression model
Curvilinear Relationship
22
d-s Score
20
18
16
14
12
10
0
1
2
3
4
5
6
Motivation
Scatter diagram showing relationship between two variables, Motivation & d-s
Score
Motivation (X) does not perfectly predict d-s Score (Y )
Relationship between Motivation and d-s Score appears to be curvilinear
Regression as a General Data
Analytic System
Investigate ‘conditional relationships’
Interactions between predictor variables or groups of
variables
Extends ANOVA, ANCOVA
• Not limited to interactions between nominally scaled variables
• Can assess interactions between predictors measured at
virtually any level
Extremely common in behavioral sciences….
Basic Regression Model
Population Regression
Function
Yi β 0 β 1 X i ε i
Yi= value of observed response on ith trial;
0 and 1 are parameters;
Regression Model is:
th
Xi = value of predictor on i trial ( a constant); • Simple
• Linear in parameters
i is a random error term
i = 1, …. n
• Linear in predictor variable
E{i }=0 (expected value of error terms is zero)
• First order
2 {i} = 2 (variance of error terms is constant)
{i, j} = 0 for all i, j; i j (error terms do not covary i.e. are not
correlated)
Each Yi consists of two parts: (1) a constant term predicted by the
regression equation; and, (2) a random error term unique to Yi . The
error term makes Yi a random variable.
Unexplained part: i
Observed value: Yi
Yi
E{Yi}
Explained part: Ŷi
Ŷi β0 β1 X i
1 = the change in the
mean of the probability
distribution for Y for
each unit increase in X.
Xi
0 = Y-intercept; the mean of the probability distribution for
Y when X = 0. Assumes scope of model includes X = 0.
Regression Function
E{Y} β 0 β 1 X
Yi
E{Yi}
The regression function
predicts the expected value of
Yi for a given Xi.
Values of Yi come from a
probability distribution with
mean of E{Yi } = 0 + 1Xi.
Xi
Example
GPA
3.10
2.30
3.00
1.90
2.50
3.70
3.40
2.60
2.80
1.60
2.00
2.90
2.30
3.20
1.80
1.40
2.00
3.80
2.20
1.50
Prediction of GPA at end of first year based on GMAT.
4.00
3.50
First Year GPA
Score
550
480
470
390
450
620
600
520
470
430
490
540
500
630
460
430
500
590
410
470
3.00
2.50
2.00
1.50
1.00
0.50
0.00
350
400
450
500
GMAT Score
550
600
650
E{GPA} = 3.34 when
GMAT =4.00
600
First Year GPA
3.34 3.50
3.00
2.50
2.00
1.50
1.00
0 = -1.6996.0.50
Value of
0.00
GPA assuming
that a
GMAT score of 0350
is
possible.
400
450
500
550
600
GMAT Score
E{Y } 1.6996 .0084 X
1 = .0084. GPA increases
by .0084 for each unit
increase in GMAT score.
650
Estimating the Regression Function
Regression Function specifies relationship
between predictor and response variables in a
population
Values of regression parameters (0 and 1) are
estimated from sample data drawn from the
population. Data are obtained via:
Observation
Experimentation
Survey
Method of Least Squares
Technique employed to produce estimates b0 and
b1 for 0 and 1, respectively.
Find those values of b0 and b1 that minimize the
sum of all squared error terms (i2)
n
Q (Yi 0 1 X i ) 2
i 1
The estimators of 0 and 1 are the values of b0
and b1 that minimize Q for a set of sample
observations.
Example
Assume from GPA example that:
b0 = -2.5
b1 = 0.01
GMAT
Xi
550
480
470
390
450
620
600
520
470
430
490
540
500
630
460
430
500
590
410
470
GPA
Yi
Predicted
GPA
Yi
Error
i2
3.10
2.30
3.00
1.90
2.50
3.70
3.40
2.60
2.80
1.60
2.00
2.90
2.30
3.20
1.80
1.40
2.00
3.80
2.20
1.50
3.00
2.30
2.20
1.40
2.00
3.70
3.50
2.70
2.20
1.80
2.40
2.90
2.50
3.80
2.10
1.80
2.50
3.40
1.60
2.20
0.10
0.00
0.80
0.50
0.50
0.00
-0.10
-0.10
0.60
-0.20
-0.40
0.00
-0.20
-0.60
-0.30
-0.40
-0.50
0.40
0.60
-0.70
0.0100
0.0000
0.6400
0.2500
0.2500
0.0000
0.0100
0.0100
0.3600
0.0400
0.1600
0.0000
0.0400
0.3600
0.0900
0.1600
0.2500
0.1600
0.3600
0.4900
i
Sum = 3.6400
n
Q (Yi 0 1 X i ) 2
i 1
n
Q (Yi b0 b1 X i ) 2
i 1
Q 3.64
4.00
3.50
3.00
GPA
2.50
2.00
1.50
1.00
0.50
0.00
350
400
450
500
550
600
650
GMAT
b0 = -2.5; b1 = .01. Q = 3.64.
Looks pretty good! Seems quite
reasonable, but…. are there other
values of b0 and b1 that provide
smaller Q’s for the sample data?
4.00
3.50
3.00
GPA
2.50
2.00
1.50
1.00
0.50
0.00
350
400
450
500
550
600
650
GMAT
b0 = -1.70; b1 = .0084 Q = 3.41.
Looks even better! This is the least
squares solution that minimizes Q.
No other values of b0 and b1 will
provide a smaller value of Q.
GMAT
Score
(Xi)
550
480
470
390
450
620
600
520
470
430
490
540
500
630
460
430
500
590
410
470
GPA
(Yi)
3.10
2.30
3.00
1.90
2.50
3.70
3.40
2.60
2.80
1.60
2.00
2.90
2.30
3.20
1.80
1.40
2.00
3.80
2.20
1.50
Predicted
GPA
(Y)
2.92
2.33
2.25
1.58
2.08
3.51
3.34
2.67
2.25
1.91
2.42
2.84
2.50
3.59
2.16
1.91
2.50
3.26
1.74
2.25
Error
Terms
0.18
-0.03
0.75
0.32
0.42
0.19
0.06
-0.07
0.55
-0.31
-0.42
0.06
-0.20
-0.39
-0.36
-0.51
-0.50
0.54
0.46
-0.75
Q=
Squared
Error
Terms
0.0324
0.0010
0.5655
0.1049
0.1764
0.0369
0.0036
0.0046
0.3047
0.0974
0.1730
0.0041
0.0400
0.1535
0.1325
0.2622
0.2500
0.2961
0.2079
0.5595
3.41
The solution that
minimizes Q:
b0 = -1.69955
b1 = 0.008399
Finding the Least Squares
Estimators
Numerical Search Procedures
Analytic Procedures
Numerical Search
Unconstrained Optimization Algorithms
Systematically search for values of b0 and b1 that
minimize Q for a given set of data
Spread sheet solution possible.
Excel Example Using GMAT data
b0 = -25
b1 = 0.05
GMAT
Score
(Xi)
550
480
470
390
450
620
600
520
470
430
490
540
500
630
460
430
500
590
410
470
GPA
(Yi)
3.10
2.30
3.00
1.90
2.50
3.70
3.40
2.60
2.80
1.60
2.00
2.90
2.30
3.20
1.80
1.40
2.00
3.80
2.20
1.50
Predicted
GPA
(Y)
2.50
-1.00
-1.50
-5.50
-2.50
6.00
5.00
1.00
-1.50
-3.50
-0.50
2.00
0.00
6.50
-2.00
-3.50
0.00
4.50
-4.50
-1.50
Error
Terms
0.60
3.30
4.50
7.40
5.00
-2.30
-1.60
1.60
4.30
5.10
2.50
0.90
2.30
-3.30
3.80
4.90
2.00
-0.70
6.70
3.00
Q=
Squared
Error
Terms
0.3600
10.8900
20.2500
54.7600
25.0000
5.2900
2.5600
2.5600
18.4900
26.0100
6.2500
0.8100
5.2900
10.8900
14.4400
24.0100
4.0000
0.4900
44.8900
9.0000
286.24
Yˆi b0 b1 X i
e Y Yˆ
i
i
i
ei2 (Yi Yˆi )2
Run Excel Example
(First, verify
using
analytic procedure)
n
Q ε i2
i 1
Analytic Procedures
Direct solution for values of β0 and β1 (e.g., β0 =
b0 and β1 = b1) that minimize Q
Using calculus can find set of simultaneous
equations, the “normal equations”
Normal equations for b0 and b1 are:
Y nb b X
X Y b X b X
i
i i
0
0
1
i
i
1
2
i
Solving the normal equations (see HW1) we
obtain the values b0 and b1 that minimize Q:
b1
( X X )(Y Y )
(X X )
i
i
2
i
1
b0 Yi b1 X i Y b1 X
n
Example computations of b0 and
b1 Using GMAT data
Total
Mean
1
GMAT
Score
2
3
4
GPA
Xi
Yi
Xi X
Yi Y
550
480
470
390
450
620
600
520
470
430
490
540
500
630
460
430
500
590
410
470
10000
500
3.10
2.30
3.00
1.90
2.50
3.70
3.40
2.60
2.80
1.60
2.00
2.90
2.30
3.20
1.80
1.40
2.00
3.80
2.20
1.50
50
2.5
50.00
-20.00
-30.00
-110.00
-50.00
120.00
100.00
20.00
-30.00
-70.00
-10.00
40.00
0.00
130.00
-40.00
-70.00
0.00
90.00
-90.00
-30.00
0.60
-0.20
0.50
-0.60
0.00
1.20
0.90
0.10
0.30
-0.90
-0.50
0.40
-0.20
0.70
-0.70
-1.10
-0.50
1.30
-0.30
-1.00
5
6
( X i X )(Yi Y ) ( X i X ) 2
30.0000
4.0000
-15.0000
66.0000
0.0000
144.0000
90.0000
2.0000
-9.0000
63.0000
5.0000
16.0000
0.0000
91.0000
28.0000
77.0000
0.0000
117.0000
27.0000
30.0000
766
2500.00
400.00
900.00
12100.00
2500.00
14400.00
10000.00
400.00
900.00
4900.00
100.00
1600.00
0.00
16900.00
1600.00
4900.00
0.00
8100.00
8100.00
900.00
91200
7
(Yi Y ) 2
0.36
0.04
0.25
0.36
0.00
1.44
0.81
0.01
0.09
0.81
0.25
0.16
0.04
0.49
0.49
1.21
0.25
1.69
0.09
1.00
9.84
( X
i
X )(Yi Y ) 766
2
(
X
X
)
91,200
i
X 500
Y 2.5
b1
X X Y Y
766
.0084
91,200
X X
i
i
2
i
b0 Y b1 X 2.5 .0083(500) 1.70
Point Estimates of Mean
Response
Point estimates obtained from...
ˆ
Y b0 b1 X
Yˆ is the estimate of E{Y}, the ‘mean response’,
when the level of the predictor is X.
b0 and b1 are estimates of 0 and 1, respectively
Yˆi
is the fitted value for the ith case (i.e. when X =
Xi)
GPA Example...
b0 = -1.70; b1 = .0084
Yˆi 1.70 .0084 X i
Yˆ600 1.70 .0084(600)
3.34
GMAT
Score
(Xi)
390
410
430
430
450
460
470
470
470
480
490
500
500
520
540
550
590
600
620
630
GPA
(Yi)
1.90
2.20
1.60
1.40
2.50
1.80
3.00
2.80
1.50
2.30
2.00
2.30
2.00
2.60
2.90
3.10
3.80
3.40
3.70
3.20
Predicted
GPA
(Y)
Yˆi
1.58
1.74
1.91
1.91
2.08
2.16
2.25
2.25
2.25
2.33
2.42
2.50
2.50
2.67
2.84
2.92
3.26
3.34
3.51
3.59
Note difference
between observed
value and fitted
values..
Yˆi b0 b1 X i
GMAT
Score
(Xi)
390
410
430
430
450
460
470
470
470
480
490
500
500
520
540
550
590
600
620
630
GPA
(Yi)
1.90
2.20
1.60
1.40
2.50
1.80
3.00
2.80
1.50
2.30
2.00
2.30
2.00
2.60
2.90
3.10
3.80
3.40
3.70
3.20
Predicted
GPA
ˆ
Y
(Y)
i
1.58
1.74
1.91
1.91
2.08
2.16
2.25
2.25
2.25
2.33
2.42
2.50
2.50
2.67
2.84
2.92
3.26
3.34
3.51
3.59
Error
Terms
0.32
0.46
-0.31
-0.51
0.42
-0.36
0.75
0.55
-0.75
-0.03
-0.42
-0.20
-0.50
-0.07
0.06
0.18
0.54
0.06
0.19
-0.39
Squared
Error
Terms
0.1049
0.2079
0.0974
0.2622
0.1764
0.1325
0.5655
0.3047
0.5595
0.0010
0.1730
0.0400
0.2500
0.0046
0.0041
0.0324
0.2961
0.0036
0.0369
0.1535
ei Yi Yˆi
ei2 (Yi Yˆi )2
Difference between ei and i
Y600 3.4
e600 3.4 3.34 .06
Yˆ600
Yˆ600 3.34
X600
ei (residual) is the known deviation between the observed value
and the fitted value
i (model error term) is the deviation between the observed value
and the unknown true regression line. ei is an estimate of i
Estimate of Error Terms
Variance:
2
Unbiased estimator of 2 is MSE
Mean Square Error
SSE
MSE
df
df=2 because had to
estimate 0 and 1 from
sample of size n. Thus,
only n-2 sources of
variability left to
estimate MSE
Error Sum of Squares or
Residual Sum of Squares
ˆ
Y
Y
i i
n2
e
2
2
i
n2
Degrees of Freedom
GPA Example...
e
MSE
2
i
3.4063
.189
n2
18
b
O
m
e
S
d
u
F
a
M
i
f
a
g
a
1
R
4
1
4
8
0
R
6
8
9
T
0
9
a
P
b
D
Maximum Likelihood Estimation
Requires functional form of probability distribution of
random error terms.
Provides estimates of required parameters that are most
consistent with the sample data.
In case of simple linear regression, the MLE estimators for
b0 and b1 are BLUE (=Best Linear Unbiased Estimators,
meaning that their expected values are equal to the true
parameter values β0 and β1).
The MLE estimator for 2 is biased but works out OK
when sample size is large.