Simple Linear Regression
advertisement

18-1
4/9/2005 11:38 AM
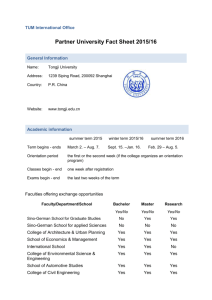
Principles of Biostatistics
Simple Linear Regression
PPT based on
Dr Chuanhua Yu and Wikipedia
Department of Epidemiology and Health Statistics,Tongji Medical College
http://statdtedm.6to23 (Dr. Chuanhua Yu)
4/9/2005 11:38 AM
18-2
Terminology
Moments, Skewness, Kurtosis
Analysis of variance
Response (dependent) variable
Explanatory (independent) variable
Linear regression model
Method of least squares
Normal equation
sum of squares, Error
sum of squares, Regression
sum of squares, Total
Coefficient of Determination
F-value P-value, t-test, F-test, p-test
Homoscedasticity
heteroscedasticity
Department of Epidemiology and Health Statistics,Tongji Medical College
ANOVA
SSE
SSR
SST
R2
http://statdtedm.6to23 (Dr. Chuanhua Yu)
18-3
4/9/2005 11:38 AM
Contents
• 18.0 Normal distribution and terms
• 18.1 An Example
•
•
•
•
•
•
•
•
•
18.2 The Simple Linear Regression Model
18.3 Estimation: The Method of Least Squares
18.4 Error Variance and the Standard Errors of Regression
Estimators
18.5 Confidence Intervals for the Regression Parameters
18.6 Hypothesis Tests about the Regression Relationship
18.7 How Good is the Regression?
18.8 Analysis of Variance Table and an F Test of the Regression
Model
18.9 Residual Analysis
18.10 Prediction Interval and Confidence Interval
Department of Epidemiology and Health Statistics,Tongji Medical College
http://statdtedm.6to23 (Dr. Chuanhua Yu)
18-4
4/9/2005 11:38 AM
Normal Distribution
The continuous probability density function of the normal distribution is the Gaussian
function
where σ > 0 is the standard deviation, the real parameter μ is the expected value, and
is the density function of the "standard" normal distribution: i.e., the normal distribution
with μ = 0 and σ = 1.
Department of Epidemiology and Health Statistics,Tongji Medical College
http://statdtedm.6to23 (Dr. Chuanhua Yu)
18-5
4/9/2005 11:38 AM
Normal Distribution
Department of Epidemiology and Health Statistics,Tongji Medical College
http://statdtedm.6to23 (Dr. Chuanhua Yu)
18-6
4/9/2005 11:38 AM
Moment About The Mean
The kth moment about the mean (or kth central moment) of a real-valued random
variable X is the quantity
μk = E[(X − E[X]) k],
where E is the expectation operator. For a continuous uni-variate probability
distribution with probability density function f(x), the moment about the mean μ is
The first moment about zero, if it exists, is the expectation of X, i.e. the mean of the
probability distribution of X, designated μ. In higher orders, the central moments are
more interesting than the moments about zero.
μ1 is 0.
μ2 is the variance, the positive square root of which is the standard deviation, σ.
μ3/σ3 is Skewness, often γ.
μ3/σ4 -3 is Kurtosis.
Department of Epidemiology and Health Statistics,Tongji Medical College
http://statdtedm.6to23 (Dr. Chuanhua Yu)
18-7
4/9/2005 11:38 AM
Skewness
Consider the distribution in the figure. The bars on the right side of the distribution
taper differently than the bars on the left side. These tapering sides are called tails (or
snakes), and they provide a visual means for determining which of the two kinds of
skewness a distribution has:
1.negative skew: The left tail is longer; the mass of the distribution is concentrated on
the right of the figure. The distribution is said to be left-skewed.
2.positive skew: The right tail is longer; the mass of the distribution is concentrated on
the left of the figure. The distribution is said to be right-skewed.
Department of Epidemiology and Health Statistics,Tongji Medical College
http://statdtedm.6to23 (Dr. Chuanhua Yu)
18-8
4/9/2005 11:38 AM
Skewness
Skewness, the third standardized moment, is written as γ1 and defined as
where μ3 is the third moment about the mean and σ is the standard deviation.
For a sample of n values the sample skewness is
Department of Epidemiology and Health Statistics,Tongji Medical College
http://statdtedm.6to23 (Dr. Chuanhua Yu)
18-9
4/9/2005 11:38 AM
Kurtosis
Kurtosis is the degree of peakedness of a distribution. A normal distribution is a
mesokurtic distribution. A pure leptokurtic distribution has a higher peak than the
normal distribution and has heavier tails. A pure platykurtic distribution has a lower
peak than a normal distribution and lighter tails.
Department of Epidemiology and Health Statistics,Tongji Medical College
http://statdtedm.6to23 (Dr. Chuanhua Yu)
18-10
4/9/2005 11:38 AM
Kurtosis
The fourth standardized moment is defined as
where μ4 is the fourth moment about the mean and σ is the standard deviation.
For a sample of n values the sample kurtosis is
Department of Epidemiology and Health Statistics,Tongji Medical College
http://statdtedm.6to23 (Dr. Chuanhua Yu)
18-11
4/9/2005 11:38 AM
18.1 An example
Table18.1 IL-6 levels in brain and serum (pg/ml) of 10
patients with subarachnoid hemorrhage
Patient
i
1
2
3
4
5
6
7
8
9
10
Serum IL-6 (pg/ml)
x
22.4
51.6
58.1
25.1
65.9
79.7
75.3
32.4
96.4
85.7
Brain IL-6 (pg/ml)
y
134.0
167.0
132.3
80.2
100.0
139.1
187.2
97.2
192.3
199.4
Department of Epidemiology and Health Statistics,Tongji Medical College
http://statdtedm.6to23 (Dr. Chuanhua Yu)
4/9/2005 11:38 AM
18-12
Scatterplot
Larger (smaller) values of brain IL-6 tend
to be associated with larger (smaller) values
of serum IL-6 .
250
brain IL-6
This scatterplot locates pairs of
observations of serum IL-6 on the x-axis
and brain IL-6 on the y-axis. We notice
that:
200
150
100
50
0
20
40
60
80
serum IL-6
Figure18.1 Regression line between serum IL-6 and
brain IL-6
The scatter of points tends to be distributed around a positively sloped straight
line.
The pairs of values of serum IL-6 and brain IL-6 are not located exactly on a
straight line. The scatter plot reveals a more or less strong tendency rather than a
precise linear relationship. The line represents the nature of the relationship on
average.
Department of Epidemiology and Health Statistics,Tongji Medical College
http://statdtedm.6to23 (Dr. Chuanhua Yu)
100
18-13
4/9/2005 11:38 AM
Examples of Other Scatterplots
0
Y
Y
Y
0
0
0
0
X
X
X
Y
Y
Y
X
X
Department of Epidemiology and Health Statistics,Tongji Medical College
X
http://statdtedm.6to23 (Dr. Chuanhua Yu)
18-14
4/9/2005 11:38 AM
Model Building
The inexact nature of the
relationship between serum
and brain suggests that a
statistical model might be
useful in analyzing the
relationship.
A statistical model separates
the systematic component
of a relationship from the
random component.
Data
Statistical
model
Systematic
component
+
Random
errors
Department of Epidemiology and Health Statistics,Tongji Medical College
In ANOVA, the systematic
component is the variation
of means between samples
or treatments (SSTR) and
the random component is
the unexplained variation
(SSE).
In regression, the
systematic component is
the overall linear
relationship, and the
random component is the
variation around the line.
http://statdtedm.6to23 (Dr. Chuanhua Yu)
18-15
4/9/2005 11:38 AM
18.2 The Simple Linear Regression Model
The population simple linear regression model:
y= a + b x
Nonrandom or
Systematic
Component
+
or
my|x=a+b x
Random
Component
Where y is the dependent (response) variable, the variable we wish to
explain or predict; x is the independent (explanatory) variable, also called the
predictor variable; and is the error term, the only random component in the
model, and thus, the only source of randomness in y.
my|x is the mean of y when x is specified, all called the conditional mean of
Y.
a is the intercept of the systematic component of the regression relationship.
b is the slope of the systematic component.
Department of Epidemiology and Health Statistics,Tongji Medical College
http://statdtedm.6to23 (Dr. Chuanhua Yu)
18-16
4/9/2005 11:38 AM
Picturing the Simple Linear Regression Model
Y
Regression Plot
my|x=a + b x
y
Error:
} b = Slope
1
{
my|x= a+b x
Actual observed values of Y
(y) differ from the expected value
(my|x ) by an unexplained or
random error():
}
{
The simple linear regression
model posits an exact linear
relationship between the expected
or average value of Y, the
dependent variable Y, and X, the
independent or predictor variable:
a = Intercept
0
X
x
Department of Epidemiology and Health Statistics,Tongji Medical College
y = my|x +
= a+b x +
http://statdtedm.6to23 (Dr. Chuanhua Yu)
18-17
4/9/2005 11:38 AM
Assumptions of the Simple Linear
Regression Model
•
•
•
The relationship between X and
Y is a straight-Line (linear)
relationship.
The values of the independent
variable X are assumed fixed
(not random); the only
randomness in the values of Y
comes from the error term .
The errors are uncorrelated
(i.e. Independent) in
successive observations. The
errors are Normally
distributed with mean 0 and
variance 2(Equal variance).
That is: ~ N(0,2)
LINE assumptions of the Simple
Linear Regression Model
Y
my|x=a + b x
y
N(my|x, y|x2)
x
Department of Epidemiology and Health Statistics,Tongji Medical College
Identical normal
distributions of errors,
all centered on the
regression line.
X
http://statdtedm.6to23 (Dr. Chuanhua Yu)
18-18
4/9/2005 11:38 AM
18.3 Estimation: The Method of Least
Squares
Estimation of a simple linear regression relationship involves finding estimated
or predicted values of the intercept and slope of the linear regression line.
The estimated regression equation:
y= a+ bx + e
where a estimates the intercept of the population regression line, a ;
b estimates the slope
of the population regression line, b ;
and e stands for the observed errors ------- the residuals from fitting the
estimated regression line a+ bx to a set of n points.
The estimated regression line:
y$ = a + b x
where $ (y - hat) is the value of Y lying on the fitted regression line for a given
value of X.
ŷ
Department of Epidemiology and Health Statistics,Tongji Medical College
http://statdtedm.6to23 (Dr. Chuanhua Yu)
18-19
4/9/2005 11:38 AM
Fitting a Regression Line
Y
Y
Data
Three errors from the
least squares regression
line
X
X
Y
e
Three errors
from a fitted line
X
Department of Epidemiology and Health Statistics,Tongji Medical College
Errors from the least
squares regression
line are minimized
X
http://statdtedm.6to23 (Dr. Chuanhua Yu)
18-20
4/9/2005 11:38 AM
Errors in Regression
Y
.
yi
Error ei = yi yˆi
yˆi
yˆ = a bx
{
yˆ
the fitted regression line
the predicted value of Y for x
X
xi
Department of Epidemiology and Health Statistics,Tongji Medical College
http://statdtedm.6to23 (Dr. Chuanhua Yu)
18-21
4/9/2005 11:38 AM
Least Squares Regression
The sum of squared errors in regression is:
n
n
2
SSE = e i = (y i y$ i ) 2
SSE: sum of squared errors
i=1
i=1
The least squares regression line is that which minimizes the SSE
with respect to the estimates a and b.
a
SSE
Parabola function
Least squares a
Least squares b
Department of Epidemiology and Health Statistics,Tongji Medical College
b
http://statdtedm.6to23 (Dr. Chuanhua Yu)
18-22
4/9/2005 11:38 AM
Normal Equation
S is minimized when its gradient with respect to each parameter is equal to zero. The elements
of the gradient vector are the partial derivatives of S with respect to the parameters:
Since
, the derivatives are
Substitution of the expressions for the residuals and the derivatives into the gradient equations gives
Upon rearrangement, the normal equations
are obtained. The normal equations are written in matrix notation as
The solution of the normal equations yields the vector
of the optimal parameter values.
Department of Epidemiology and Health Statistics,Tongji Medical College
http://statdtedm.6to23 (Dr. Chuanhua Yu)
18-23
4/9/2005 11:38 AM
Normal Equation
Yˆ = XBˆ
n
n
Q = ei = yi yˆ i
i =1
U ~ N (0, )
Y = XB U
2
i =1
2
E = Y Yˆ = Y XBˆ
2
= ee = (Y XBˆ )(Y XBˆ )
Q = (Y Bˆ X )(Y XBˆ )
= ( Y Y Y XBˆ Bˆ X Y Bˆ X XBˆ )
= Y Y 2 Bˆ X Y Bˆ X XBˆ
Q
=0
ˆ
B
(Y XBˆ = Bˆ X Y ?
)
X Y X XBˆ = 0
1
Bˆ = X X X Y
ˆ
2
=
ee
n k 1
Department of Epidemiology and Health Statistics,Tongji Medical College
http://statdtedm.6to23 (Dr. Chuanhua Yu)
18-24
4/9/2005 11:38 AM
Sums of Squares, Cross Products, and
Least Squares Estimators
Sums of Squares and Cross Products:
lxx = ( x x ) 2 = x 2
lyy
x
2
n 2
y
2
2
= (y y ) = y
n
lxy = ( x x )( y y ) = xy
x ( y )
n
ŷ = a bx
Least squares re gression estimators:
lxy
=
b
lxx
a = y bx
ŷ = a bx
Department of Epidemiology and Health Statistics,Tongji Medical College
http://statdtedm.6to23 (Dr. Chuanhua Yu)
4/9/2005 11:38 AM
18-25
Example 18-1
Patient
1
4
8
2
3
5
7
6
10
9
Total
x
22.4
25.1
32.4
51.6
58.1
65.9
75.3
79.7
85.7
96.4
592.6
y
134.0
80.2
97.2
167.0
132.3
100.0
187.2
139.1
199.4
192.3
1428.7
x2
501.76
630.01
1049.76
2662.56
3375.61
4342.81
5670.09
6352.09
7344.49
9292.96
41222.14
y2
17956.0
6432.0
9447.8
27889.0
17503.3
10000.0
35043.8
19348.8
39760.4
36979.3
220360.5
x ×y
3001.60
2013.02
3149.28
8617.20
7686.63
6590.00
14096.16
11086.27
17088.58
18537.72
91866.46
lxx = x
2
x
2
n
y
592.62
= 41222.14
= 6104.66
10
2
1428.702
l yy = y
= 220360.47
= 16242.10
n
10
x y = 91866.46 592.6 1428.70 = 7201.70
lxy = xy
n
10
2
7201.70
b= =
= 1.18
l
6104.66
lxy
xx
regression equation:
yˆ = 72.96 1.18 x
a = y bx = 1428.7 (1.18) 592.6
10
10
= 72.96
Department of Epidemiology and Health Statistics,Tongji Medical College
http://statdtedm.6to23 (Dr. Chuanhua Yu)
18-26
4/9/2005 11:38 AM
New Normal Distributions
ˆB = ( X X )1 X Y
• Since each coefficient estimator is a linear combination of Y
(normal random variables), each bi (i = 0,1, ..., k) is normally
distributed.
• Notation:
b j ~ N (b j , 2c jj ), c jj is the jth row jth column element of (X' X) -1
in 2D special case,
c jj = 1/l xx
when j=0, in 2D special case
b0 = a ~ N (a , 2 ( x 2 ) / nlxx )
Department of Epidemiology and Health Statistics,Tongji Medical College
http://statdtedm.6to23 (Dr. Chuanhua Yu)
18-27
4/9/2005 11:38 AM
Total Variance and Error Variance
Y
2
(
y
y
)
Y
n 1
2
ˆ
(
y
y
)
n2
X
What you see when looking
at the total variation of Y.
X
What you see when looking
along the regression line at
the error variance of Y.
Department of Epidemiology and Health Statistics,Tongji Medical College
http://statdtedm.6to23 (Dr. Chuanhua Yu)
4/9/2005 11:38 AM
18-28
18.4 Error Variance and the Standard
Errors of Regression Estimators
Y
Degrees of Freedom in Regression :
df = (n-2) (n total observations less one degree of freedom
for each parameter estimated (a and b) )
lxy2
2
SSE = (y yˆ ) = l
yy
=l yy blxy
Square and sum all
regression errors to find
SSE.
lxx
An unbiased estimator of 2 ,denoted by s2 :
( y yˆ )
Error Variance: MSE= SSE =
n-2
n2
2
X
Example 18 -1:
SSE =l yy blxy
= 16242.10 (1.18)(7201.70)
= 7746.23
MSE =
SSE
n2
=
7746.23
= 968.28
8
Standard Error :
s = MSE = 968.28 = 31.12
Department of Epidemiology and Health Statistics,Tongji Medical College
http://statdtedm.6to23 (Dr. Chuanhua Yu)
18-29
4/9/2005 11:38 AM
Standard Errors of Estimates in Regression
The standard error of a (intercept) :
Example 18-1:
s
x
s =
2
sa =
where s =
s
lxx
x
n
2
a
1 x
=s
n lxx
s
lxx
n
lxx
41222.14
31.12
=
10
6104.66
= 0.398 64.204 = 25.570
MSE
The standard error of b (slope) :
sb =
2
sb =
s
lxx
31.12
=
6104.66
= 0.398
Department of Epidemiology and Health Statistics,Tongji Medical College
http://statdtedm.6to23 (Dr. Chuanhua Yu)
18-30
4/9/2005 11:38 AM
T distribution
Student's distribution arises when the population standard
deviation is unknown and has to be estimated from the data.
Department of Epidemiology and Health Statistics,Tongji Medical College
http://statdtedm.6to23 (Dr. Chuanhua Yu)
18-31
4/9/2005 11:38 AM
18.5 Confidence Intervals for the
Regression Parameters
Example 18-1
95% Confidence Intervals:
a
A 100(1-a ) % confidence interval for a :
a t
s
a / 2,n 2 a
A 100(1-a ) % confidence interval for b :
b t
s
a / 2, n 2 b
t0.05 / 2,102 sa
=72.961 (2.306) (25.570)
= 72.961 58.964
= [13.996,131.925]
b
t0.05 / 2,102 sb
=1.180 (2.306) (0.398)
= 1.180 0.918
= [0.261,2.098]
Department of Epidemiology and Health Statistics,Tongji Medical College
http://statdtedm.6to23 (Dr. Chuanhua Yu)
18-32
4/9/2005 11:38 AM
18.6 Hypothesis Tests about the
Regression Relationship
Constant Y
Y
Unsystematic Variation
Y
H0:b =0
Nonlinear Relationship
Y
H0:b =0
X
X
H0:b =0
X
A hypothesis test for the existence of a linear relationship between X and Y:
H0: b = 0
H1: b 0
Test statistic for the existence of a linear relationship between X and Y:
where
b
bb b
tb =
=
sb
sb
is the least - squares estimate of the regression slope and
sb is the standard error of b
When the null hypothesis is true, the statistic has a t distribution with n - 2 degrees of freedom.
Department of Epidemiology and Health Statistics,Tongji Medical College
http://statdtedm.6to23 (Dr. Chuanhua Yu)
18-33
4/9/2005 11:38 AM
T-test
A test of the null hypothesis that the means of two normally distributed
populations are equal. Given two data sets, each characterized by its mean,
standard deviation and number of data points, we can use some kind of t test to
determine whether the means are distinct, provided that the underlying
distributions can be assumed to be normal. All such tests are usually called
Student's t tests
t=
b jbj
b
~ t (n k )
j
Department of Epidemiology and Health Statistics,Tongji Medical College
http://statdtedm.6to23 (Dr. Chuanhua Yu)
18-34
4/9/2005 11:38 AM
T-test
Example 18-1:
H : b = 0, H : b 0
0
1
a = 0.05
b 1.180
=
= 2.962
sb 0.398
p value = 0.018 ( = 10 2 = 8)
tb =
t0.05 / 2, 8 = 2.306 2.962
H is rejected at the 5% level and we may
0
conclude that there is a relationship between
serum IL-6 and brain IL-6.
Department of Epidemiology and Health Statistics,Tongji Medical College
http://statdtedm.6to23 (Dr. Chuanhua Yu)
18-35
4/9/2005 11:38 AM
T test Table
Department of Epidemiology and Health Statistics,Tongji Medical College
http://statdtedm.6to23 (Dr. Chuanhua Yu)
4/9/2005 11:38 AM
18-36
18.7 How Good is the Regression?
The coefficient of determination, R2, is a descriptive measure of the strength of
the regression relationship, a measure how well the regression line fits the data.
( y y ) = ( y y$)
( y$ y )
Total = Unexplained
Explained
Deviation
Deviation
Deviation
(Error)
(Regression)
R2: coefficient of
determination
Y
.
Y
Unexplained Deviation
Y$
Explained Deviation
Y
}
{
2
2
( y y ) = ( y y$) ( y$ y )
SST
= SSE
+ SSR
Total Deviation
{
Rr22= =
X
SSR
SST
= 1
X
Department of Epidemiology and Health Statistics,Tongji Medical College
SSE
SST
2
Percentage of
total variation
explained by the
regression.
http://statdtedm.6to23 (Dr. Chuanhua Yu)
4/9/2005 11:38 AM
18-37
The Coefficient of Determination
Y
Y
Y
X
X
SST
R2=0
SSE
R2=0.50
X
SST
SSE SSR
R2=0.90
S
S
E
SST
SSR
Example 18 -1 :
SSR blxy 1.180 7201.70
R =
=
=
SST l yy
16242.10
2
= 0.5231 = 52.31%
brain IL-6
250
200
150
100
50
0
20
40
60
80
serum IL-6
Figure18.1 Regression line between serum IL-6 and
brain IL-6
Department of Epidemiology and Health Statistics,Tongji Medical College
http://statdtedm.6to23 (Dr. Chuanhua Yu)
100
18-38
4/9/2005 11:38 AM
Another Test
• Earlier in this section you saw how to perform a t-test to
compare a sample mean to an accepted value, or to
compare two sample means. In this section, you will see
how to use the F-test to compare two variances or standard
deviations.
• When using the F-test, you again require a hypothesis, but
this time, it is to compare standard deviations. That is, you
will test the null hypothesis H0: σ12 = σ22 against an
appropriate alternate hypothesis.
Department of Epidemiology and Health Statistics,Tongji Medical College
http://statdtedm.6to23 (Dr. Chuanhua Yu)
18-39
4/9/2005 11:38 AM
F-test
T test is used for every single parameter. If there are many dimensions, all
parameters are independent.
Too verify the combination of all the paramenters, we can use F-test.
H 0 : b 2 = b 3 = ... = b k = 0
H1 : b 2 , b 3 ,..., b k at least one non - zero
The formula for an F- test in multiple-comparison ANOVA problems is:
F = (between-group variability) / (within-group variability)
SSR /( k 1)
F=
~ F (k 1, n k )
SSE /( n k )
Department of Epidemiology and Health Statistics,Tongji Medical College
http://statdtedm.6to23 (Dr. Chuanhua Yu)
18-40
4/9/2005 11:38 AM
F test table
Department of Epidemiology and Health Statistics,Tongji Medical College
http://statdtedm.6to23 (Dr. Chuanhua Yu)
18-41
4/9/2005 11:38 AM
18.8 Analysis of Variance Table and an
F Test of the Regression Model
Source of
Variation
Sum of
Squares
Regression SSR
Degrees of
Freedom Mean Square F Ratio
(1)
MSR
Error
SSE
(n-2)
MSE
Total
SST
(n-1)
MST
MSR
MSE
Example 18-1
Source of
Variation
Sum of
Squares
Degrees of
Freedom Mean Square F Ratio p Value
Regression
8495.87
1
8495.87
Error
7746.23
8
968.28
Total
16242.10
9
Department of Epidemiology and Health Statistics,Tongji Medical College
8.77
0.0181
http://statdtedm.6to23 (Dr. Chuanhua Yu)
18-42
4/9/2005 11:38 AM
F-test T-test and R
1. In 2D case, F-test and T-test are same. It can be proved that f = t2
So in 2D case, either F or T test is enough. This is not true for more variables.
2. F-test and R have the same purpose to measure the whole regressions. They
nk
R
F=
,
are co-related as
k 1 1 R
3. F-test are better than R became it has better metric which has distributions
for hypothesis test.
2
2
Approach:
1.First F-test. If passed, continue.
2.T-test for every parameter, if some parameter can not pass, then we can
delete it can re-evaluate the regression.
3.Note we can delete only one parameters(which has least effect on regression)
at one time, until we get all the parameters with strong effect.
Department of Epidemiology and Health Statistics,Tongji Medical College
http://statdtedm.6to23 (Dr. Chuanhua Yu)
18-43
4/9/2005 11:38 AM
18.9 Residual Analysis
Residuals
Residuals
0
0
x or y$
x or y$
Homoscedasticity: Residuals appear completely
random. No indication of model inadequacy.
Residuals
Heteroscedasticity: Variance of residuals
changes when x changes.
Residuals
0
0
x or y$
Time
Residuals exhibit a linear trend with time.
Curved pattern in residuals resulting from
underlying nonlinear relationship.
Department of Epidemiology and Health Statistics,Tongji Medical College
http://statdtedm.6to23 (Dr. Chuanhua Yu)
18-44
4/9/2005 11:38 AM
Example 18-1: Using Computer-Excel
Residual Analysis. The plot shows the a curve relationship
between the residuals and the X-values (serum IL-6).
serum IL-6 Residual Plot
Residual(残差)
40
20
0
-20
0
20
40
60
80
100
120
-40
-60
serum IL-6
Department of Epidemiology and Health Statistics,Tongji Medical College
http://statdtedm.6to23 (Dr. Chuanhua Yu)
18-45
4/9/2005 11:38 AM
Prediction Interval
• samples from a normally distributed population.
• The mean and standard deviation of the population are unknown
except insofar as they can be estimated based on the sample. It is
desired to predict the next observation.
• Let n be the sample size; let μ and σ be respectively the unobservable
mean and standard deviation of the population. Let X1, ..., Xn, be the
sample; let Xn+1 be the future observation to be predicted. Let
• and
X ~ N ( X , Sn2 / n)
Department of Epidemiology and Health Statistics,Tongji Medical College
http://statdtedm.6to23 (Dr. Chuanhua Yu)
18-46
4/9/2005 11:38 AM
Prediction Interval
• Then it is fairly routine to show that
• It has a Student's t-distribution with n − 1 degrees of freedom.
Consequently we have
• where Tais the 100((1 + p)/2)th percentile of Student's t-distribution
with n − 1 degrees of freedom. Therefore the numbers
• are the endpoints of a 100p% prediction interval for Xn + 1.
Department of Epidemiology and Health Statistics,Tongji Medical College
http://statdtedm.6to23 (Dr. Chuanhua Yu)
18-47
4/9/2005 11:38 AM
18.10 Prediction Interval and Confidence Interval
• Point Prediction
– A single-valued estimate of Y for a given value of X
obtained by inserting the value of X in the estimated
regression equation.
• Prediction Interval
– For a value of Y given a value of X
•
•
Variation in regression line estimate
Variation of points around regression line
– For confidence interval of an average value of Y given
a value of X
•
Variation in regression line estimate
Department of Epidemiology and Health Statistics,Tongji Medical College
http://statdtedm.6to23 (Dr. Chuanhua Yu)
18-48
4/9/2005 11:38 AM
confidence interval of an average value of Y
given a value of X
2
(
X
X
)
1
Yˆ0 ~ N ( b 0 b 1 X 0 , 2 ( 0 2 ))
n
xi
Yˆ0 ( b 0 b 1 X 0 )
t=
~ t ( n 2)
S Yˆ
0
Yˆ t n 2,a / 2 SYˆ E (Y ) Yˆ t n 2,a / 2 SYˆ
where
1
SYˆ = S
n
X X
X X
2
0
n
i =1
2
i
Department of Epidemiology and Health Statistics,Tongji Medical College
http://statdtedm.6to23 (Dr. Chuanhua Yu)
18-49
4/9/2005 11:38 AM
Confidence Interval for the Average Value of Y
A 100(1-a ) % confidence interval for the mean value of Y:
1 ( x0 x ) 2
yˆ x0 ta / 2,n 2 s
n
lxx
Example 18 - 1 (x0 =75.3):
yˆ x0 = a bx0 = 72.96 1.18 75.3 = 161.79
1 (75.3 59.26) 2
161.79 2.306 31.12
10
6104.66
= 161.79 27.06 = [134.74,188.85]
Department of Epidemiology and Health Statistics,Tongji Medical College
http://statdtedm.6to23 (Dr. Chuanhua Yu)
18-50
4/9/2005 11:38 AM
Prediction Interval For a value of Y given a
value of X
Y0 ~ N ( b 0 b1 X 0 , 2 )
2
(
X
X
)
1
0
Yˆ0 Y 0 ~ N ( 0 , (1
))
2
n
xi
2
Yˆ0 Y0
t=
~ t ( n 2)
S Yˆ Y
0
0
Yˆ t n 2,a / 2 S Y Yˆ YP Yˆ t n 2,a / 2 S Y Yˆ
where
S Y Yˆ = S 1
1
n
X X
X X
2
0
n
i =1
2
i
Department of Epidemiology and Health Statistics,Tongji Medical College
http://statdtedm.6to23 (Dr. Chuanhua Yu)
18-51
4/9/2005 11:38 AM
Prediction Interval for a Value of Y
A 100(1-a ) % prediction interval for Y:
1 ( x0 x ) 2
yˆ x0 ta / 2, n 2 s 1
n
lxx
Example 18 - 1 (x0 =75.3):
yˆ x0 = a bx0 = 72.96 1.18 75.3 = 161.79
1 (75.3 59.26) 2
161.79 2.306 31.12 1
10
6104.66
= 161.79 76.69 = [85.11, 238.48]
Department of Epidemiology and Health Statistics,Tongji Medical College
http://statdtedm.6to23 (Dr. Chuanhua Yu)
18-52
4/9/2005 11:38 AM
Confidence Interval for the Average Value of Y and
Prediction Interval for the Individual Value of Y
300.0
brain IL-6
250.0
200.0
150.0
100.0
50.0
0.0
20
40
60
serum IL-6
Actual observations
upper of 95% CL for y
upper of 95% CL for mean
80
100
lower of 95% CL for y
lower of 95% CL for mean
Department of Epidemiology and Health Statistics,Tongji Medical College
http://statdtedm.6to23 (Dr. Chuanhua Yu)
18-53
4/9/2005 11:38 AM
Summary
1. Regression analysis is applied for prediction while
control effect of independent variable X.
2. The principle of least squares in solution of
regression parameters is to minimize the residual sum
of squares.
3. The coefficient of determination, R2, is a descriptive
measure of the strength of the regression relationship.
4. There are two confidence bands: one for mean
predictions and the other for individual prediction
values
5. Residual analysis is used to check goodness of fit for
models
Department of Epidemiology and Health Statistics,Tongji Medical College
http://statdtedm.6to23 (Dr. Chuanhua Yu)