the effects of measurement error on the structural properties of the
advertisement

THE EFFECTS OF MEASUREMENT ERROR ON THE STRUCTURAL
PROPERTIES OF THE CITATION NETWORKS
Nuša Erman and Ljupčo Todorovski
University of Ljubljana, Faculty of Administration,
Gosarjeva 5, SI-1000 Ljubljana, Slovenia
{nusa.erman, ljupco.todorovski}@fu.uni-lj.si
ABSTRACT. Citation analysis takes at input a huge amount of bibliographical data that are often incomplete.
This leads to the introduction of several measurement errors in the citation network, which, in turn, influence the
results of citation network analysis. Such incompleteness of citation data most frequently derives from a number
of identified and well-known problems, which occur in sources of citation data: 1) the boundary specification
problem, 2) self-citations, 3) allocation of credit, 4) multiple authorship, 5) homographs, and 6) synonyms. Some
of these problems in sources of citation data can be abolished in the first stage of citation analysis, i.e., when
determining the study design and before collecting data, whereas others emerge when data is already collected.
The aim of this paper is to study and compare the effects of the above-mentioned sources of measurement errors
on the results of citation network analysis. More specifically, we first introduce different levels of
incompleteness into the collected data to get a number of artificial incomplete data sets and transform each of
them into citation network. We then perform comparative analysis of the values of the structural properties of the
citation network obtained from the original data with the corresponding values of the citation network obtained
from artificial incomplete data sets to check for the accuracy of the analysis results. Our study includes the
structural network properties of prestige measures.
Keywords: citation analysis, measurement error, imperfect data, prestige measures.
1. INTRODUCTION
In a broad sense, the term missing or incomplete data refers to imperfect information on the
phenomena under study, which consequently influence the further interpretation of the phenomena.
Accordingly, in the study of social phenomena it is important if not even essential to follow the
normative behavior and therefore also to strive to the prevention and remediation of imperfect data.
Imperfect data are present in every single field of science which deals with the manipulation of
gathered data, and the citation network analysis is no exception. It deals with the manipulation of huge
(practically unlimited) amount of data on academic publications, their authors and citations among
them. Such data are often incomplete and lead to several measurement errors which results in biased,
inaccurate and misleading results (McKnight et al. 2007).
The imperfect data problem in the field of network analysis has already been studied by several
authors. In their studies, authors usually refer to the data gathered by survey questionnaires. In this
sense, Costenbader and Valente (2003) study the impact of sampled networks, as compared to real
networks, on the stability of centrality measures. Their findings suggest that there exist high
correlation between the features of the real and the sampled networks. They conclude that, under
specific circumstances and conditions, the use of networks in which some of the data are missing is
relatively not problematic.
Further, Kossinets (2006) studies the impact of missing data using standard statistical approaches. He
focuses on the missing data which arise from different sources typical for data gathered by network
surveys: the boundary specification problem, non-response effects, and fixed-choice design. The main
aim of his work is to study the impact of missing survey data on the global characteristics of the
network. He shows that boundary specification problem mostly influence the estimates of networklevel statistics, in particular the assortativity coefficient and mean degree. In case of the fixed-choice
design, author finds that the impact of missing data is relatively low, but only up to a certain cut-off.
In contrast to the presented studies, authors also study the problem of imperfect data gathered from the
secondary data sources. In their studies, they usually focus on the effects of node removal, node
addition, edge removal, and edge addition on the centrality measures robustness. In this sense, Borgatti
and co-workers (2006) study the impact of network data accuracy on the measurement error. They find
that when the data accuracy decreases, the amount of error increases. But the decrease of data
accuracy can be predicted under the assumption that the decline is monotonically. Authors conclude
that the knowledge of the rates and types of errors enables to predict and establish error bounds in case
of centrality measures under study.
Similarly, Wang and his co-workers (2012) provide a re-classification of measurement error in
network data. More specifically, they study the impact of different measurement error scenarios on the
degree centrality, clustering coefficient, network constraint and eigenvector centrality. Their main
findings show that the sensitivity of centrality measures is higher in cases, when the clustering
coefficients attain higher values and when the degree distributions are more positively-skewed. They
conclude that the reliability of local measures declines more as compared to global measures, and that
the robustness of studied centrality measures is very similar in case of different measurement error
scenarios.
According to the brief presentation of related work, we can identify certain limitations of the above
mentioned studies. Firstly, a detailed studies on the effects of missing data in case of network analysis
focus on the data gathered by network surveys and the missingness which are typical for this type of
data. Secondly, although there exist studies on the impact of measurement error in case of data
gathered by secondary data sources, they study the simple node removal, node addition, edge removal,
and edge addition. Thus, they study measurement errors as random processes. Finally, the presented
studies limit their focus only on the undirected unweighted networks.
The aim of this paper is to overcome the identified limitations in two main directions. We first
introduce measurement errors to network data following the actual imperfect data scenarios, which can
be derived from issues concerning bibliometrics and especially citation analysis. In this sense, we
identify six sources of imperfect data: 1) the boundary specification problem, 2) self-citations, 3)
allocation of credit, 4) multiple authorship, 5) homographs, and 6) synonyms (Smith 1981; Lindsey
1980; Egghe et al. 2000). The second contribution of the present paper is that we apply the imperfect
data scenarios to citation network which enables to study the effects of measurement errors in case of
weighted directed network.
The rest of this paper is organized as follows. In Section 2, we introduce imperfect data scenarios,
present their impact on the change of citation network structural properties, and apply missing data
mechanisms to every imperfect data scenario. Section 3 present the data and the methodology used to
investigate effects of imperfect data on prestige measures. In Section 4, we provide the statistics and
graphical representation of the analysis results. Section 5 discusses the results and Section 6 draws
conclusions and outlines the directions for future research directions.
2. IMPERFECT DATA SCENARIOS
The sources of imperfect data in case of citation analysis can occur in two points of data manipulation.
The first one is captured in the study design and includes the boundary specification problem, selfcitations, and allocation of credit. Other imperfect data scenarios emerge during the data gathering
process and originate from the errors introduced by citation data misrepresentations. They include
problems of multiple authorship, homographs, and synonyms.
2.1 The boundary specification problem
The boundary specification problem represents one of the key problems in the design of citation
network study. According to Laumann et al. (1989), the boundary specification problem refers to the
specification of inclusion rules, which cover the selection of network actors as well as the
determination of relation types among the selected actors. The determination of inclusion rules on the
actor level strongly depends on three main components, which include actors themselves, relations,
and activities. The actors' inclusion usually depends on specific characteristics or features of actors
which originate from two different approaches, namely, positional1 and reputational2 approach. In
practice, the combination of both approaches is generally used. In contrast, there exists another
approach concerning the inclusion of actors which is known as relational approach 3. Last but not least,
the inclusion of actors can also be defined according to the definition of the event or activity in which
the potential actors are included in. This approach is called the realistic approach (Laumann et al.
1989)
In citation analysis, maybe the most appropriate is the realistic approach. According to this approach,
actors place themselves on the specific scientific field in which they are active in. Furthermore, we
also have to consider the boundaries of individual scientific field which is usually far from an easy
task. Namely, according to Porter and Rafols (2009), the scientific fields are becoming more and more
intertwined and consequently form more and more interdisciplinary research fields.
2.2 Self-citations
The most general definition of self-citation refers to the citation which occurs in a specific document
and shares with this document one or more authors. Self-citations are said to be a natural, applicable
and informative phenomena since in most cases it refers to the cumulative work of self-citing author.
Despite this positivistic view, self-citations often represent a problem which significantly affects the
citation analysis results (Phelan 1999, MacRoberts and MacRoberts 1989).
For self-citations there has been argued that the impact of self-citations depends on the analysis level.
There exists evidence that on lower, individual levels of analysis self-citations can represent a serious
issue since the degree of self-citing significantly fluctuates among authors. Accordingly, authors (e.g.,
Phelan 1999; Aksenes 2003) suggest that in case of the analysis on the individual level it is better to
exclude the self-citations from the data. In contrast, the influence of self-citations at higher levels of
aggregations and longer time-periods decreases, and the inclusion or exclusion of the self-citations
from the data is not so defining.
1
Positional approach refers to the inclusion or membership of actors in formally constituted group (Laumann et
al. 1989).
2
Reputational approach involves an assessment of qualified informant, who determines the inclusion of actors
(Laumann et al. 1989).
3
According to the relational approach, the actors included in the network are reflected through the specific social
relations of a particular type (Laumann et al. 1989).
2.3 Allocation of credit
An important factor which derives from the problem of multiple authorship and which significantly
influences the imperfection of network data is the allocation of credit among co-authors. Namely,
single-authored and multiple-authored papers are equivalent in their impact which is why the credit in
multiple-authored papers should be allocated among the authors (Lindsey 1980).
There exist several schemes of allocating the credit among authors of the same paper. According to
Egghe et al. (2000), the allocation of credit can follow the first author counting, fractional counting,
proportional counting, pure geometric counting, and Noblesse oblige. The use of different enumerated
schemes leads to different relative results which do not capture the absolute truth about the relative
importance of co-authors of a specific documents. Accordingly, authors (e.g. Lindsey 1980) suggest
that in cases when the relative contribution of authors is unknown, the equal allocation of credit
(known as fractional schemes in the above categorization) is the most appropriate one to use. The
credit is thus allocated equally among the authors of a particular paper.
2.4 Multiple authorship
A problem of multiple authorship is presented as the situation when the citing document refers to the
multiple-authored paper but it specifies only the first author of the cited document. To overcome this
problem, authors propose different solutions. MacRoberts and MacRoberts (1989) argue that the most
useful and only eligible approach to the elimination of the multiple-authorship problem is the
verification of all references which are listed in the citing document.
2.5 Homographs and synonyms
As an important source of imperfect data in citation analysis represent homographs and synonyms.
Homographs occur when two or more authors in the citation database share their name and surname
and consequently emerge with the same initials. On the other hand, synonyms refer to the situation in
which the same author uses different names and/or surnames in different publications. Although the
problems of homographs and synonyms do not occur in a large number of cases, they represent a
serious issue, especially in case of citation analysis on individual level. Similarly as in the case of
multiple authorship, the most useful tool to avoid a large share of homographs and synonyms is
careful verification of possible problematic names of authors (Smith 1981; Phelan 1999).
2.6 The impact of imperfect data on the citation network structure
Imperfection of data, derived from the above mentioned sources, has a significant impact on the very
structure of citation networks. On one hand, imperfect data influence the global features of the
networks (e.g., the number of actors and/or the number of relations). On the other hand, the sources of
imperfect data can also influence the characteristics of networks at lower levels (e.g., the prestige
measures and/or cohesive subgroups identification).
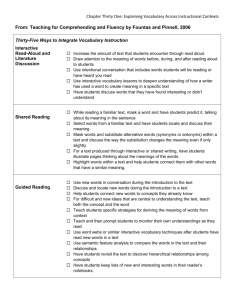
The presentation of the impact of different error scenarios on structural properties of the citation
network is presented in Figure 1.
When observing the changes in the network structure, according to different imperfect data scenarios,
we proceed from the real network which is presented in Figure 1 a). The real network consists of seven
authors, the lines represent the relation of citing, and the numbers attributed to the lines represent
citation weights.
Figure 1. Impact of different imperfect data scenarios - b) the boundary specification problem, c) selfcitations, d) allocation of credit, e) multiple authorship, f) homographs, and g) synonyms - on the
structural properties of the a) real network.
A1
a)
Real network
A4
0,5
1
0,5
A2
b)
c)
Imperfect network
Multiple authorship
1
0,5
A1
1
A1
g)
A4
1
A7
A6
0,5
0,5
1
1
A5
A4
1
A7
A6
1
0,5
1
A5
A4
0,5
0,5
1
1
1
A3
A31
0,5
A7
A6
0,5
0,5
0,5
1
0,5
A32
0,5
A31
1
1
1
A4
0,5
0,5
A6
0,5
A5
1
A3
A7
1
A32
0,5
1
A5
1
1
A2
0,5
1
1
A2
Imperfect network
Synonyms
A6
1
A3
1
0,5
A1
f)
1
1
A2
Imperfect network
Homographs
0,5
1
0,5
A2
e)
A4
1
A1
d)
A7
A5
A2
Imperfect network
Allocation of credit
1
A3
A2
Imperfect network
Self-citations
A5
1
A1
0,5
1
1
A3
A1
Imperfect network
The boundary specification problem
A6
0,5
1
1
A4
1
1
A5
A7
0,5
A6
1
0,5
A7
As it is shown in Figure 1 b), we introduce the boundary specification problem to the real network. We
assume that the paper written by the author A3 is published in a publication venue which is,
intentionally or unintentionally, missed from the data set. The author A3 is removed from the network
as well as his input and output links. The network therefore decomposes into two sections, where the
first section is represented by the authors A1 and A2, and the second section includes authors A5, A6,
and A7. Consequently, there can also be acknowledged the reduction of input and output degrees of
these authors.
By the application of self-citations, which is presented in Figure 1 c), we assume that the author A3 in
his references includes a publication written by himself. In this sense, the self-citation introduces a
loop in the network, which connects the author with himself. Consequently, the weighted input and
output degree of author A3 increase.
Allocation of credit is presented in Figure 1 d). In this case, instead of equal allocation of credit, which
is the case in real network, we introduce the normal or standard counting according to which every
author of the multi-authored paper is credited by the weight of 1. The result of the change in allocation
of credit is the increase in the values of weighted input and output degrees of authors which leads to
the overestimation of prestige measures at the individual level.
In case of multiple authorship problem (Figure 1 e)), we can ascertain the impact on the prosperity of
the network through the introduction of a higher number of authors as well as a higher number of
relations. As we assume in our example, the paper written by author A3 is in fact written by two
authors, i.e. A31 and A32. Consequently, the number of lines from authors A1 and A2 to authors A31 and
A32 duplicates and also influence the allocation of weights attributed to the lines. The same
consequences emerge in case of authors A5 and A4 and their linkage with authors A31 and A32.
The problem of homographs, presented in Figure 1 f) we assume that author A3 actually represents two
different authors with the same initials, A31 and A32. Therefore, authors A1 and A2 do not cite the same
author, but two different authors. Accordingly, the weights attributed to their links change.
Synonyms, which are presented in Figure 1 g), are introduced following the assumption that authors
A4 and A5 actually represent the same author which occurs in the database with two different initials.
Consequently, the links which are adjacent to author A5 are attributed to author A4 which influences
the relationship of the author to other authors. The change can also be observed both in case of
weighted input and weighted output degree of author A4.
2.7 Application of missing data mechanisms
As we have seen, the imperfect data normally result in missing or imperfect relations and/or actors in
the network. The main question accompanying the data imperfection is whether data are missing
systematically, and if so, whether the missing data is dependent on the very values of the observed
data (i.e., characteristics of actors and/or relations).
To get answer to these questions, in 1970s Rubin (1976) proposed the classification system of missing
data. Given the relation between the likelihood of the occurrence of missing values and data, he
defines three types or missing data mechanisms, namely: 1) Missing completely at random (MCAR),
2) Missing at random (MAR), and 3) Missing not at random (MNAR). The MCAR mechanism
assumes that the data is missing completely at random, so the probability of missing data on one
variable is not related to values of other variables as well as to the values of itself. The MAR
mechanism is more strict than the preceding one, since it assumes that data are missing at random but
the probability of missing data on one variable is dependent on the values of the variable itself. Here,
we are dealing with a systematic relationship between one or more measured variables and the
probability of missing data. According to MNAR mechanism, the occurrence of missing data has
unequal probability throughout the values of one variable. The missing data is related to the missing
data as well as the observed part of the data.
Following Rubin's classification of missing data mechanisms, we can categorize our measurement
error scenarios according to their probability of occurrence. Every source of imperfect data occurs
with a certain probability, which can on one hand be independent of the gathered data and on the other
hand derive in dependence to other observed and/or unobserved data. The application of missing data
mechanisms to issues of citation analysis, presented in previous subsections, is presented in Table 1.
Table 1. The application of missing data mechanisms to the measurement error scenarios
The boundary
specification problem
Selfcitations
Allocation of
credit
Multiple
authorship
Homographs
Synonyms
MCAR
MAR
MNAR
The incompleteness caused by the boundary specification problem can be categorized both, as MAR
and MNAR. In case of MAR, we are dealing with the example, when the publications, which are not
involved in the analysis and which represent key publications of the scientific field, are unavailable or
inaccessible. In case of MNAR, the data are incomplete because of other reasons, such as a subjective
specification of inclusion rules
The problem of self-citations influences the incompleteness of data according to MNAR mechanism.
The probability for the occurrence of self-citations does not depend on the observed data. Rather, they
are largely dependent on the individual author's interests. On the one hand, authors include selfcitations to expose the integration of the preliminary studies carried out by the same author. On the
other hand, self-citations occur due to the author's interest to emphasize his/her previous publications
in order to increase eventual citations by other authors.
The allocation of credit in multiple-authored papers depends on the number of co-authors of the
observed paper. The probability for the occurrence of incomplete data or false line weight depends on
the number of paper's authors. Accordingly, the allocation of credit is characterized as MAR.
Similar situation occurs in case of multiple authorship. Namely, the probability of imperfect data
depends on the number of authors. Higher probability for the imperfect data belongs to the papers
which are the result of collaborated work. Therefore, we categorize the multiple authorship as MAR.
The emergence of homographs significantly depends on the frequency according to which the names
and/or surnames of authors occur. In this sense, the probability for the occurrence of incomplete data
depends on the authors' names. More common names have higher probability for the occurrence of
homographs. Accordingly, we attribute the MNAR mechanism to the problem of homographs.
In contrast to homographs, synonyms occur as a function of the observed authors' names. Higher
number of names leads to greater probability for the incomplete data, since in case of authors with two
or more names the synonyms more frequently occur. In this sense, we classify synonyms as MAR.
3. DATA AND METHODOLOGY
In the continuation we first present the data used for further examination of the incomplete data effects
of incomplete on the citation analysis results. We also present the methodology used which includes
the prestige measures of interest and the process of introducing different error scenarios into data.
3.1 Dataset
To explore the effects of incomplete network data on the structural properties of the citation network,
we use the empirical dataset which has been studied in our past research (Erman and Todorovski 2009;
Erman and Todorovski 2011). We analyze the citation network built upon the papers published in the
field of e-government research. The dataset includes 675 papers published in the most prestigious egovernment related journal Government Information Quarterly (200 papers), as well as in the
proceedings of the international conference EGOV (314 papers), and the European conference ECEG
(161 papers) in the period between 2005 and 2009.
To avoid the mistakes induced by the sources of imperfect data caused by the study design, we
decided to remove most of these before the data collection, when preparing the parsers for the
automatic capture of data. To set the network boundaries, we decided to include the main publication
venues covering the work in the field of e-government research, as presented above. The publication
venues included in the dataset cover both, the papers prepared by the authors on the European as well
as on the international level. To avoid the bias of the results, we decided to exclude or ignore selfcitations which are consequently not included into the analysis. Finally, to give a proper amount of
credit to authors of multi-authored papers, we apply equal allocation of credit weighting scheme
according to which each author of the multi-authored paper receives a weight equal to 1/n, where n
represents the number of paper's authors. Since we mostly prevented the incompleteness introduced by
the study design, we limit our analysis to the effects of measurement errors caused by the data
collection procedure (i.e., multiple authorship, homographs, synonyms, and the combination of all).
Using the presented dataset, we build on the citation network in which nodes represent the authors and
arcs represent citation relations among the authors. We refer to this network as the real network. The
main characteristics of the generated citation network are presented in Table 2. As it is shown, the
author citation network includes 14,063 different authors and 48,449 arcs among which 88.2% have
weight different from one. The density of the network indicates that the observed citation network is
very sparse, in which only 0.02% of all possible arcs are present. Average degree almost equals the
value of seven which means that in average, the authors in e-government research field regularly cite
more than 6 other authors. But the low value of the network degree centralization indicates that in our
author citation network there is no clear separation between prestigious which were significantly more
frequently cited as other authors.
Table 2. Main characteristics of author citation network.
# nodes
# arcs
% arcs (w≠1)
Density
Average degree
Degree centralization
Author citation network
14,063
48,449
88.2
0.0002
6.8844
0.0294
3.2 Methods
Our objective is to observe the effects of measurement error introduced by different error scenarios on
the structural properties of the author citation network. Here we focus on the robustness of two
prestige measures – weighted input degree distribution and authority weights - which consider not
only mere arcs but also the weights assigned to these arcs. Since we are analyzing the citation network
in which we are mostly interested in the authors which are the most frequently cited, we restrict
ourselves to the analysis of input links.
3.2.1
Simulation procedure
The procedure which we follow in the present paper starts with a known or real network, built on the
previously presented data. In the real network, we compute the prestige measures (weighted input
degree and authority weights) for each individual author in the network. We then distort the network
to generate the incomplete network and again compute the prestige measures for each individual
author in the incomplete network.
According to this, for the real network we introduce exactly one of three types of imperfect data
sources as well as their combination in order to construct the imperfect networks. For each
measurement error scenarios, we apply four portions of errors to the real network: 0%, 5%, 10%, 20%,
and 50%. The simulations of incomplete data scenarios follow the next procedure:
1.
2.
3.
4.
5.
6.
7.
Consider a real network C;
Calculate the prestige measures for authors in C;
Identify lists of 1, 10, 20, and 50 most prestigious authors in C;
Apply an incomplete data scenario to C 100-times; generate the incomplete networks C1-C100;
Calculate the prestige measures for authors in C1-C100;
Identify lists of 1, 10, 20, and 50 most prestigious authors in C1-C100;
Compare the results gathered from C and C' - calculate the accuracy levels of the matching
between lists of the most prestigious authors in C and C1-C100;
8. Calculate the Spearman's rank correlation comparing the prestige measures of real network C and
average prestige measures of incomplete networks C1-C100.
In the continuation, we offer a detailed description of the seventh and the eighth step of the above
mentioned procedure.
3.2.2
Accuracy levels
For each pair of networks (the real one and one of the imperfect ones) we calculate the measures of
weighted input degrees as well as authority weights. We then apply the comparison according to four
accuracy measures, which are presented in Table 3. We first extract the most prominent author
according to weighted indegree and the most prominent author according to authority weights from the
real network. In addition we also eliminate the lists of ten, twenty, and fifty the most prominent
authors. Then we carry out a comparison of the prestige measures of the real network with the prestige
measures of the incomplete networks. In this respect, we also eliminate lists of one, ten, twenty, and
fifty the most prominent authors in each of the incomplete networks. Further we compare the lists
from incomplete networks with the lists from the real network. In this sense, we calculate the average
values of matching between the real prominent authors' lists and the incomplete authors' lists. The
result of the presented procedure are the average accuracy scores for both measures of prestige and all
measures of accuracy at all error levels of all measurement error scenarios.
Table 3. Measures of accuracy or robustness of prestige measures
Measure
Top 1
Description
Average proportion of times that the most prominent author in the real network is
also the most central one in the incomplete networks
Proportion of times that the ten most prominent authors in the real network are also
among the ten most prominent ones in the incomplete networks
Proportion of times that the twenty most prominent authors in the real network are
also among the twenty most prominent ones in the incomplete networks
Proportion of times that the fifty most prominent authors in the real network are also
among the fifty most prominent ones in the incomplete networks
Top 10
Top 20
Top 50
3.2.3
Spearman's rank correlation coefficient
Finally, we calculate Spearman's rank correlation coefficients between the prominence measures of the
real network and the average of prominence measures of the incomplete networks. For the selection of
Spearman's rho instead of Pearson's correlation we decided from the same reason as Wang et al.
(2012). Namely, Pearson's correlation might add noise to the results since it is very sensitive regarding
the linearity. Following the distribution of the prominence measures under study (see Figure 2), we
can claim that these measures are highly skewed (following a clear power-law distribution) which is
why the node ranking by a given prominence measure is the best choice.
Figure 2. Weighted input degree distribution of author citation network
100
10
1
Frequency
1000
10000
Weighted indegree distribution
1
2
5
10
20
Weighted indegree
50
100
4. THE EFFECTS OF MEASUREMENT ERROR ON THE PROMINENCE MEASURES
4.1 The effects of measurement error on weighted input degree measure
Table 4 presents average accuracy scores for weighted input degree measure and all measures of
accuracy at all error levels of all measurement error scenarios.
Table 4. Average accuracy scores for weighted input degree measure and all measures of accuracy
(Top 1, Top 10, Top 20 in Top 50) at all error levels (0%, 5%, 10%, 20%, and 50%) of all
measurement error scenarios (multiple authorship, homographs, synonyms, and the combination of all
the three)
% error
Multiple authorship
Top 1
0
5
10
20
50
Top 10
0
5
10
20
50
Top 20
0
5
10
20
50
Top 50
0
5
10
20
50
Weighted input degree
Homographs
Synonyms
Combination of all
1.000
1.000
1.000
1.000
1.000
1.000
1.000
1.000
1.000
1.000
1.000
1.000
1.000
1.000
1.000
1.000
1.000
1.000
1.000
1.000
1.000
1.000
1.000
1.000
1.000
1.000
0.995
0.892
0.801
0.611
1.000
0.976
0.921
0.775
0.489
1.000
0.996
0.965
0.874
0.731
1.000
1.000
1.000
1.000
1.000
1.000
1.000
0.981
0.768
1.000
0.991
0.954
0.872
0.542
1.000
1.000
0.996
0.985
0.886
1.000
1.000
1.000
1.000
1.000
1.000
0.990
0.977
0.942
0.802
1.000
0.994
0.980
0.961
0.792
1.000
0.995
0.988
0.967
0.921
As we can see, in case of multiple authorship as one of the measurement error scenarios, the accuracy
scores according to the proportion of error do not change. We can say that we note a perfect fit when
comparing the imperfect weighted degree measures with the real ones. This perfect fit can probably be
attributed to the fact that the papers written by the most prominent authors are a result of individual
work or work with lower number of authors.
We can witness the same situation in case of accuracy measure »Top 1«. The leading author maintains
its position in all the measurement error scenarios introduced and at all error levels. This is likely due
to the fact that in the real network as the most prominent author stands out as the author with a
significantly higher weighted input degree as compared to other authors in the network.
On the other hand, we ascertain considerable similarity in the behavior of accuracy scores with the
introduction of homographs, synonyms and combination of all three error scenarios. We can also say
that in the case of these three error scenarios, the weighted input degree measures behave virtually the
same.
In Figure 3, we present the scatter plots representing the average accuracy scores of the weighted input
degree measures as a function of error introduced by all four error scenarios.
Figure 3. Scatter plots of the weighted input degree accuracy as a function of error proportion (0%,
5%, 10%, 20%, and 50%) for all four measures of accuracy (Top 1, Top 10, Top 20, and Top 50).
Each line represents a different error scenario (multiple authorship, homographs, synonyms, and the
combination of all)
30
40
50
0
10
20
30
% data corrupted
Top 20
Top 50
40
50
10
20
30
% data corrupted
40
50
0.4
0.6
0.8
0
0.2
Multiple authorship
Homographs
Synonyms
Combination of all
Multiple authorship
Homographs
Synonyms
Combination of all
0.0
0.2
0.4
0.6
Accuracy level
0.8
1.0
% data corrupted
0.0
Accuracy level
0.6
0.8
20
1.0
10
Multiple authorship
Homographs
Synonyms
Combination of all
0.0
0.0
Multiple authorship
Homographs
Synonyms
Combination of all
0
0.4
0.2
Accuracy level
0.6
0.4
0.2
Accuracy level
0.8
1.0
Top 10
1.0
Top 1
0
10
20
30
40
50
% data corrupted
In case of accuracy measure »Top 10«, the upper horizontal line indicates, that the introduction of
multiple authorship again does not affect the accuracy of the calculated weighted input degree
measures in imperfect networks as compared to the real network. The list of the ten most prominent
authors therefore remains unchanged. But there are changes in case of the introduction of homographs,
synonyms and the combination of all. The curves indicating the individual error scenario have pretty
much the same shape. The accuracy of the results, obtained by the introduction of synonyms decreases
the most rapid which presumably indicates that the synonyms pose the highest problem to the
identification of the ten most prominent authors in the imperfect networks as compared to the real
network. The error scenarios of homographs and the combination of all also affect the accuracy levels
but not to such extent as the problem of synonyms. The situation stays much the same in case of
accuracy measure »Top 20« as well.
In case of accuracy measure »Top 50«, we again ascertain the unchanged situation after the
introduction of multiple authorship problem. But the situation, as compared to the other two accuracy
measures, changes in case of the introduction of synonyms. We can ascertain that synonyms are
almost identically harmful as the introduction of homographs, whereas the combination of all three
error scenarios affects the accuracy level only a bit.
To support these findings, in Figure 4 we present the Spearman's correlation coefficients as a function
of the proportion of data corrupted. All the correlation coefficients are statistically significant at level
0.01. In case of the introduction of multiple authorship we can ascertain that the weighted input degree
measure turns out to be the most robust. Correlation between the real weighted input degree measures
and the average of weighted input degree measures in incomplete networks at every error level equals
to 1.
0.6
0.4
0.2
Spearman s rank correlation
0.8
1.0
Figure 4. Spearman's rank correlation coefficients between the weighted input degree measures of the
real network and the incomplete networks according to different error levels (0%, 5%, 10%, 20%, and
50%) for all measurement error scenarios (multiple authorship, homographs, synonyms, and the
combination of all)
0.0
Multiple authorship
Homographs
Synonyms
Combination of all
0
10
20
30
40
50
% data corrupted
Weighted input degree measure turns out to be a little less robust in case of the introduction of
homographs and the combination of all error scenarios. The curves pass almost the same path at the
diagram. But the rank correlations between the real and incomplete network measures occupy values
of 0.77 or higher even in cases, when a half of the network data is corrupted either by homographs or
the combination of all three scenarios.
The correlation curves in cases of homographs, synonyms and the combination of all follow a similar
trend until the 20% of data is corrupted. In case when a half of data is corrupted, the correlation in case
of synonyms drops a bit which indicates the fact that the weighted input degree as a measure of
prestige is least robust in case of synonyms.
4.2 The effects of measurement error on authority weights measure
Table 5 presents average accuracy scores for authority weights measure and all measures of accuracy
at all error levels of all measurement error scenarios.
Table 5. Average accuracy scores for authority weights measure and all measures of accuracy (Top 1,
Top 10, Top 20 in Top 50) at all error levels (0%, 5%, 10%, 20%, and 50%) of all measurement error
scenarios (multiple authorship, homographs, synonyms, and the combination of all the three)
% error
Multiple authorship
Top 1
0
5
10
20
50
Top 10
0
5
10
20
50
Top 20
0
5
10
20
50
Top 50
0
5
10
20
50
Authority weights
Homographs
Synonyms
Combination of all
1.000
1.000
1.000
1.000
1.000
1.000
1.000
1.000
0.600
0.000
1.000
1.000
0.900
0.600
0.000
1.000
1.000
0.800
0.900
0.000
1.000
1.000
1.000
1.000
1.000
1.000
0.940
0.930
0.850
0.690
1.000
0.940
0.870
0.790
0.600
1.000
0.950
0.890
0.890
0.740
1.000
1.000
1.000
1.000
1.000
1.000
0.990
0.980
0.960
0.810
1.000
0.930
0.900
0.835
0.600
1.000
0.955
0.920
0.945
0.825
1.000
1.000
1.000
1.000
1.000
1.000
0.960
0.940
0.910
0.760
1.000
0.920
0.870
0.720
0.590
1.000
0.950
0.880
0.890
0.710
The situation in case of introduction the multiple authorship scenario is similar as when comparing
accuracy scores in case of weighted input degree measure. Namely, the accuracy scores according to
the proportion of error do not change and they indicate a perfect fit when comparing the imperfect
authority weights measures with the real ones.
In case of accuracy measure »Top 1«, we can ascertain a drop in accuracy levels in case of
homographs, synonyms, and combination of all. When a half of data is corrupted, the most prominent
author does not maintain his position of being the most prominent one. On the other hand, we
ascertain considerable fluctuation in the behavior of accuracy scores with the introduction of other
three error scenarios. We explain them according to the Figure 5.
In Figure 5, we present the scatter plots representing the average accuracy scores of the authority
weights measures as a function of error introduced by all four error scenarios.
Figure 5. Scatter plots of the authority weights measure accuracy as a function of error proportion
(0%, 5%, 10%, 20%, and 50%) for all four measures of accuracy (Top 1, Top 10, Top 20, and Top
50). Each line represents a different error scenario (multiple authorship, homographs, synonyms, and
the combination of all)
30
40
50
0
10
20
30
% data corrupted
Top 20
Top 50
40
50
10
20
30
% data corrupted
40
50
0.4
0.6
0.8
0
0.2
Multiple authorship
Homographs
Synonyms
Combination of all
Multiple authorship
Homographs
Synonyms
Combination of all
0.0
0.2
0.4
0.6
Accuracy level
0.8
1.0
% data corrupted
0.0
Accuracy level
0.6
0.8
20
1.0
10
Multiple authorship
Homographs
Synonyms
Combination of all
0.0
0.0
Multiple authorship
Homographs
Synonyms
Combination of all
0
0.4
0.2
Accuracy level
0.6
0.4
0.2
Accuracy level
0.8
1.0
Top 10
1.0
Top 1
0
10
20
30
40
50
% data corrupted
In case of accuracy measure “Top 1”, we can ascertain a huge drop in the accuracy scores in case of
homographs, synonyms, and the combination of all three – the accuracy drops down to zero. Hence,
the most prominent author drops out as being the most prominent one.
The curves indicating accuracy measure »Top 10« show that the introduction of multiple authorship
again does not affect the accuracy of the calculated authority weights measures in imperfect networks
as compared to the real network. The list of the ten most prominent authors therefore remains
unchanged. But there are changes in case of the introduction of homographs, synonyms and the
combination of all. The curves indicating the individual error scenario have pretty much the same
shape. The accuracy of the results, obtained by the introduction of synonyms decreases the most rapid
which presumably indicates that the synonyms pose the highest problem to the identification of the ten
most prominent authors in the imperfect networks as compared to the real network. The error
scenarios of homographs and the combination of all also affect the accuracy levels but not to such
extent as the problem of synonyms.
The situation changes in case of accuracy measure »Top 20«. The introduction of multiple authorship
scenario does not affect the accuracy scores, so the lists of 20 most prominent authors in incomplete
networks coincide with the list in real network. In case of synonyms, the accuracy decreases most
rapidly and in case when 50% of data is corrupted the accuracy scores drop significantly. The accuracy
in case of homographs declines almost linearly. In case of the combination of all the three error
scenarios, we can ascertain linear drop in accuracy scores in cases when 5% and 10% of data is
corrupted, and then we witness the increase in accuracy scores when 20% of data is corrupted. After
that, the accuracy of imperfect measures as compared to the real ones again declines. The situation
stays much the same in case of accuracy measure »Top 50« as well. The only exception is the
introduction of synonyms which declines a bit more in case when 20% of data is corrupted.
In Figure 6 we present the Spearman's correlation coefficients as a function of the proportion of data
corrupted. All the correlation coefficients are statistically significant at level 0.01. In case of the
introduction of multiple authorship we can ascertain that the authority weights measure turns out to be
the most robust. Correlation between the real weighted input degree measures and the average of
weighted input degree measures in incomplete networks at every error level equals to 1.
0.6
0.4
0.2
Spearman s rank correlation
0.8
1.0
Figure 6. Spearman's rank correlation coefficients between the authority weights measures of the real
network and the incomplete networks according to different error levels (0%, 5%, 10%, 20%, and
50%) for all measurement error scenarios (multiple authorship, homographs, synonyms, and the
combination of all)
0.0
Multiple authorship
Homographs
Synonyms
Combination of all
0
10
20
30
40
50
% data corrupted
Authority weights measure turns out to be a little less robust in case of the introduction of homographs
and the correlation declines linearly. In case of the combination of all error scenarios, the correlation
most rapidly declines from 0% to 5% corrupted data and then again increases and then decreases
relatively linearly. The correlation curve in case of synonyms follow a linear trend as well. But the
correlations among the real and imperfect authority weights measures is lower than in cases of other
error scenarios. Regardless, the results show that the rank correlations between the real and incomplete
authority weights measures occupy values of 0.64 or higher even in cases, when a half of the network
data is corrupted either by homographs, synonyms, or the combination of all three scenarios.
5. DISCUSSION
According to our systematic examination of the effects of measurement error scenarios on the
structural properties of the citation network we can draw various important conclusions. One of the
key findings relates to the accuracy of the prominence measures under conditions of imperfect data. In
case when the multiple authorship scenario is introduced, we can ascertain no change in the accuracy
of the observed prominence measures. We suggest that this situation arises from the fact that the
papers written by the most prominent authors are a result of individual work or work with lower
number of authors. On the other hand, at least in the field of e-government research, we can also infer
that the most frequently cited papers are not written by a huge number of authors, but include only one
or a small number of authors.
For the other three error scenarios, we have seen that they behave virtually almost the same. In case of
weighted input degree measure, the accuracy scores drop as a function of increasing error level. The
most “destructive” error scenario is the introduction of synonyms which influences the accuracy scores
the most. But further on, we ascertain that the accuracy scores in case of synonyms decline slower
with the increasing bound of the observed top authors lists (in case of accuracy measure “Top 50”, the
accuracy scores in case of synonyms increase and reach the accuracy scores introduced by
homographs).
In case of the authority weights measure we have witnessed a slightly different situation. Although the
accuracy scores again drop as a function of increasing error level, in case of the combination of all
three error scenarios we can ascertain an increase in accuracy scores when 20% of data is corrupted.
Like in the case of the weighted input degree measure, also in the case of authority weights measure
synonyms occur as one of the most “destructive” error scenarios. And what is interesting, in this case
the accuracy level does not increase in case of the increasing bound of the observed top authors lists.
Regarding the robustness of the observed prominence measures we can say that in both cases, the
weighted degree measures and authority weights measure turn out to be the most robust in case of
multiple authorship scenario. The weighted degree measure is a little less robust when homographs
and combination of all scenarios are introduced. In case of authority weights, the robustness of the
measure according to these two scenarios is quite different, where the prominence measure is a little
more robust in case of homographs. For both, the authority weights and the weighted input degree
measures, the synonyms pose the biggest problem since in this case both measures become the least
robust.
Perhaps the most important finding of the present study is certainly the fact that the accuracy in cases
of homographs, synonyms, and the combination of all the error scenarios not only declines with
increasing error, but does so linearly, monotonically and therefore predictably. Thereby, we confirm
the findings of Borgatti et al. (2006) where they showed that in principle, if a researcher knows the
proportion and type of error, he can establish, at least partially, the error bounds on the measures
calculated from the observed data.
6. CONCLUSION
In the present paper we have argued to overcome the limitations of the existing incomplete network
data studies in two main directions. Firstly, we have introduced the actual measurement error scenarios
which have been derived from the real situations regarding the issues of bibliometric and especially
citation network analysis. In this sense, the cases of the boundary specification problem, self-citations,
allocation of credit, multiple authorship, homographs, and synonyms have been defined. We have then
applied different missing data mechanisms to all of the observed measurement error scenarios. In this
way, we have introduced measurement errors not as random processes but rather as random with the
constraints or not random. We have decided to check for the effects of these scenarios in the real
citation network composed of the papers published in the e-government research field. We have not
changed the structure of the citation network, so we have executed the analysis on the real weighted
directed citation network.
We have eliminated the first three measurement error scenarios when we have planned a study design
so the examination of the effects of these three error scenarios has not been the case in this paper. The
elimination of these has been described in the section about dataset description.
The other three measurement error scenarios have been examined according to two prominence
measures – weighted input degree and authority weights – since they represent the measures, which in
addition to considering citation links among the authors, also consider the weights attached to the
citation links. We examined the effects of measurement error scenarios on the structural properties of
these two measures. The results are discussed in the previous section.
However, we are aware of some of the limitations of our study. The first limitation is its focus only on
weighted directed network, although other types of networks exist, e.g. weighted undirected networks.
In the present paper we have focused on the citation networks, where nodes correspond to authors and
links correspond to citations. Our data set allows for the establishment and analysis of other types of
networks on different aggregation levels (papers, publication venues, as well as institutions, countries,
etc.).
For future research, we plan to expand our study of the effects of imperfect data in network analysis
firstly by the examination of these effects in case of co-authorship networks, i.e. weighted undirected
network. Then we plan to extend the scope to other aggregation levels, such as the citation network
among different publication venues. We expect that in the latter case the prominence measures will be
more robust, since it has been shown (e.g., Wang et al. 2012) that the effects of imperfect data at the
individual levels (e.g., individual authors) are much less robust as in cases of higher aggregation
levels. Our future work will also cover different network imputation network in order to fill in the
incomplete network data.
Last but not least, we also plan to check the effects of the other three error scenarios (i.e., the boundary
specification problem, self-citations, and allocation of credit). Firstly, we will remove one publication
venue at the time and check for the accuracy and robustness of the prestige measures in citation
network analysis. Secondly, we will examine the impact of self-citations so that we will not remove
them from the data. And finally, we will compare the results of different allocation schemes and try to
determine the most appropriate one.
Acknowledgements. This material is based in part upon work supported by the Slovenian Research
Agency through the funds for training and financing young researchers.
REFERENCES
Aksenes, Dag W. (2003). A macro study of self-citation. Scientometrics, 56(2), 235 – 246.
Borgatti, Stephen P, Kathleen M. Carley and David Krackhardt (2006). On the robustness of centrality
measures under conditions of imperfect data. Social Networks, 28(2), 124 – 136.
Costenbader, Elizabeth and Thomas W. Valente (2003). The stability of centrality measures when
networks are sampled. Social Networks, 25(4), 283 – 307.
Egghe, Leo, Ronald Rousseau and Guido van Hooydonk (2000). Methods for Accrediting Publications
to Authors or Countries: Consequences for Evaluation Studies. Journal of the American Society for
Information Science, 51(2), 145 – 157.
Erman, Nuša and Ljupčo Todorovski (2009). Mapping the e-Government Research with Social
Network Analysis. In Maria A. Wimmer, Hans J. Scholl, Marijn Janssen and Roland Traunmueller
(Eds.), EGOV 2009, LNCS 5693, 13 – 25.
Erman, Nuša and Ljupčo Todorovski (2011). Collaborative Network Analysis of Two e-Government
Conferences: Are We Building a Community? Electronic Journal of e-Government, 9(2), 141 – 151.
Kossinets, Gueorgi (2006). Effects of missing data in social networks. Social Networks, 28(3), 247 –
268.
Laumann, Edward O., Peter V. Marsden and David Prensky (1989). The Boundary Specification
Problem in Network Analysis. In Linton C. Freeman, Douglas R. White and A. Kimball Romney
(Eds.), Research Methods in Social Network Analysis (61 – 87), Virginia: George Mason University
Press.
Lindsey, Duncan (1980). Production and Citation Measures in the Sociology of Science: The Problem
of Multiple Authorship. Social Studies in Science, 10(2), 145 – 162.
MacRoberts, Michael H. and Barbara R. MacRoberts (1989). Problems of Citation Analysis: A
Critical Review. Journal of the American Society for Information Science, 40(5), 342 – 349.
McKnight, Patrick E., Katherine M. McKnight, Souraya Sidani and Aurelio José Figuerdo (2007).
Missing Data: A Gentle Introduction. New York: The Guilford Press.
Phelan, T.J. (1999). A compendium of issues for citation analysis. Scientometrics, 45(1), 117 – 136.
Porter, Alan L. and Ismael Rafols (2009). Is science becoming more interdisciplinary? Measuring and
mapping six research fields over time. Scientometrics, 81(3), 719 – 745.
Rubin, Donald B. (1976). Inference and missing data. Biometrica, 63(3), 581 – 592.
Smith, Linda C. (1981). Citation Analysis. Library Trends, 20(1), 83 – 106.
Wang, Dan J., Xiaolin Shi, Daniel A. McFarland and Jure Leskovec (2012). Measurement error in
network data: A re-classification. Social Networks, 34(4), 396 – 409.