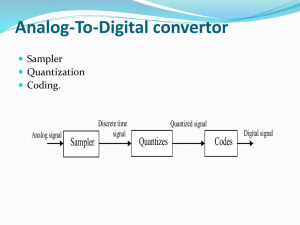
CBIR_quantization
advertisement

Special Topic on Image Retrieval
Measure Image Similarity by Local
Feature Matching
• Matching criteria (matlab demo)
– Distance criterion: Given a test feature from one image, the
normalized L2-distance from the nearest neighbor of a comparison
image is less than ϵ.
– Distance ratio criterion: Given a test feature from one image, the
distance ratio between the nearest and second nearest neighbors of a
comparison image is less than 0.80.
50
100
150
200
250
300
350
400
450
SIFT Matching by Threshold
The distribution of identified true matches and false matches
based on L2-distance thresholds.
Coefficient distributions of the top 20
dimensions in SIFT after PCA
Direct matching: the complexity issue
• Assume an image described by m=1000 descriptors (dimension d=128)
– N*m=1 billion descriptors to index
• Database representation in RAM
– 128 GB with 1 byte per dimension
• Search: m2* N * d elementary operations
– i.e., > 1014 " computationally not tractable
– The quadratic term m2: severely impacts the efficiency
Bag of Visual Words
• Text Words in Information Retrieval (IR)
–
–
Compactness
Descriptiveness
Bag-of-Word model
Of all the sensory impressions
proceeding to the brain, the visual
experiences are the dominant ones.
sensory,
brain,
Our perception
of the
world around
visual,
perception,
us is based essentially on the
retinal,
cortex,
messages
thatcerebral
reach the
brain from
eye,
cell,
optical
our eyes. For a long time it was
nerve,
imageimage was
thought that
the retinal
Wiesel
transmittedHubel,
point by
point to visual
centers in the brain; the cerebral
cortex was a movie screen, so to
speak, upon which the image in the
eye was projected.
Retrieve
China is forecasting a trade surplus of
$90bn (£51bn) to $100bn this year, a
threefold increase on 2004's $32bn.
China,Ministry
trade, said the
The Commerce
surplus,
surplus
would commerce,
be created by a
exports,
imports,
predicted 30% jump in US,
exports to
yuan,
bank, domestic,
$750bn,
compared
with a 18% rise in
increase,
importsforeign,
to $660bn.
The figures are
trade,
value
likely to further annoy the US, which
has long argued that China's exports
are unfairly helped by a deliberately
undervalued yuan.
Bag of Visual Words
• Could images be represented as Bag-of-Visual Words?
Bag of ‘visual words’
Image
?
CBIR based on BoVW
Query
Feature
Extraction
Vector
Quantization
Index
Lookup
On-line
……
Retrieval Results
Database
Feature
Extraction
Vector
Quantization
Image Index
Off-line
Codebook Training
8
Bag-of-visual-words
• The BOV representation
– First introduced for texture classification [Malik’99]
• “Video-Google paper” – Sivic and Zisserman, ICCV’2003
– Mimic a text retrieval system for image/video retrieval
– High retrieval efficiency and excellent recognition performance
• Key idea: n local descriptor describing the image -> 1 vector
– sparse vectors " efficient comparison
– inherits invariance of the local descriptors
• Problem: How to generate the visual word?
Bag-of-visual words
• The goal: “put the images into words”, namely visual words
– Input local descriptors are continuous
– Need to define what a “visual word is”
– Done by a quantizer q
– q is typically a k-means
•
is called a “visual dictionary”, of size k
– A local descriptor is assigned to its nearest neighbor
– Quantization is lossy: we can not get back to the original descriptor
– But much more compact: typically 2-4 bytes/descriptor
Popular Quantization Schemes
•
•
•
•
•
•
K-means
K-d tree
LSH
Product quantization
Scalar quantization
CSH
K-means Clustering
• Given a dataset x1 ,, x n
• Goal: Partition the dataset into K clusters denoted by μ1 ,, μ n
• Formulation:
arg min J
μ1 ,,μ n
r11,,rnk
N
K
n 1 k 1
• Solution:
– Fix μ k , and solve rnk
–
rnk x n μ k
2
Fix rnk , and solve μ k
rnk
: assignment of a
data to a cluster
1 if k arg min j x n μ j
r
: nk
otherwise
0
: μk
r x
r
n nk n
n nk
– Iterate above two steps until convergence
General Steps of K-means Algorithm
• General Steps:
– 1. Decide on a value for k.
– 2. Initialize the k cluster centers (randomly, if necessary).
– 3. Decide the class memberships of the N objects by assigning them to
the nearest cluster center.
– 4. Re-estimate the k cluster centers, by assuming the memberships
found above are correct.
– 5. If none of the N objects changed membership in the last iteration, exit.
Otherwise goto 3.
Illustration of the K-means algorithm using
the re-scaled Old Faithful data set.
Plot of the cost function. The
algorithm has converged after
the third iterations
Large Vocabularies with Learned Quantizer
• Feature matching by quantization:
• Hierarchical k-means [Nister 06]
• Approximate k-means [Philbin 07]
– Based on approximate nearest neighbor search
– With parallel k-tree
Bag of Visual Words with Vocabulary Tree
Interest point detection and local feature extraction
Hierarchical Kmeans clustering
Visual Word
Get the final visual word Tree
Feature Space
Bag of Visual Words
•
Summarize entire image based on its distribution (histogram)
of word occurrences.
frequency
Visual Word Histogram
…..
Visual words codebook
Bag of Visual Words with Vocabulary Tree
IDF: inverse document frequency
TF: term frequency
nid : number of occurrences of word i in image d
nd : total number of words in the image d
ni : the number of occurrences of term i in the
whole database
N : the number of images in the whole database
Visual Word Histogram
Bag of Visual Words
Interest point detection and local feature extraction
Bag of Visual Words
Features are clustered to quantize the space into a discrete
number of visual words.
Bag of Visual Words
Given a new image, the neareast visual wod is identified for
each of its features.
Bag of Visual Words
A bag-of-visual-words histogram can be used to summarized
the entire image.
Image Indexing and Comparison based on
Visual Word Histogram Representation
• Image Indexing with visual word
– Representation of a sparse image-visual word matrix
– Store only those non-empty items
• Image distance measurement
Popular Quantization Schemes
•
•
•
•
•
•
K-means
K-d tree
LSH
Product quantization
Scalar quantization
CSH
KD-Tree (K-dimensional tree)
• Divide the feature space with binary tree
• Each non-leaf node corresponds to a cutting plane
• Feature points in each rectilinear space are similar to
each other
10
8
6
4
2
0
0
2
4
6
8
10
KD-Tree
• Binary tree with each node denoting a rectilinear region
• Each non-leaf node corresponds to a cutting plane
• The directions of the cutting planes alternate with depth
An Example
Popular Quantization Schemes
•
•
•
•
•
•
K-means
K-d tree
LSH
Product quantization
Scalar quantization
CSH
Locality-Sensitive Hashing
[Indyk, and Motwani 1998] [Datar et al. 2004]
101
0
1
Index by compact code
hash function
h(x) sgn(wT x b)
0
1
1
random
0
• hash code collision probability proportional to original similarity
l: # hash tables, K: hash bits per table
Courtesy: Shih-Fu Chang, 2012
Popular Quantization Schemes
•
•
•
•
•
•
K-means
K-d tree
LSH
Product quantization
Scalar quantization
CSH
Product Quantization (TPAMI’12)
• Basic idea
– Partition feature vector into m sub-vectors
– Quantize sub-vectors with m distinct quantizers
• Advantage
– Low complexity in quantization
– Extremely fine quantization of the feature space
Distance table
• Vector distance approximation
D
m
(x y )
2
i
i 1
i
k 1
|| u k (x) u k (y ) ||22
where ak qk u k (x) , bk qk u k (y )
m
|| ca c
k
k 1
bk ||22
m
d
k 1
d12
…
d1K
…
|| x y
||22
d11
ak bk
dK1
dKK
Product Quantization
Popular Quantization Schemes
•
•
•
•
•
•
K-means
K-d tree
LSH
Product quantization
Scalar quantization
CSH
Scalar Quantization
• SIFT distance distribution of true matches and
false matches from experimental study
Novel Approach- Scalar Quantization
• Basic Idea
– Scalar vs. Vector Quantization
simple, fast, data independent
– Map a SIFT feature to a binary signature (bits)
• Map function is independent of image collection
– The binary signature keeps the discriminative power
of SIFT feature
L2 distance
Hamming distance
Binary SIFT Signature
• General idea
Distance
preserving
SIFT descriptor
Binary Signature
(0, 25, 8, 2, . . ., 14, 5, 2)T
How to
select f(x)
Transformation
f(x)
(0, 1, 0, 0, . . ., 1, 0, 0) T
• Compact for storing in memory
• Efficient for comparison computing
Preferred Properties
• Simple and efficient
• Unsupervised to avoid overfiting to training data
• Well preserved feature distance
Scalar Quantization (MM’12)
• Each dimension is encoded with one bit
– Given a feature vector f ( f1 , f 2 ,, f d )T R d
– Quantize it to a bit vector b (b1, b2 , , bd )T
1 if f i fˆ
bi
0 if f i fˆ
(i 1,2,, d )
fˆ : the median value of vector f
Experimental Observation
Statistical study on 0.4 trillion feature pairs
0.2
1.4
average standard deviation
average L2 distane
1.2
1
0.8
0.6
0.4
0.15
0.1
0.05
0.2
0
0
10
20
30
40
50
60
Hamming distance
70
80
90
0
100
(a) Descriptor pair frequency vs. Hamming distance;
10
frequency of SIFT descriptor pair
2
x 10
0
10
20
30
40
50
60
Hamming distance
70
80
(c) Descriptor pair frequency vs. Hamming
distance;
0.5
0
0
20
40
60
Hamming distance
80
100
100
(b) The average standard deviation vs. Hamming
distance.
1.5
1
90
An Example of Matched Features
DF xor distance : 6 (f2D: 5, D: 6); L2 dis: 0.03
150
L2 distance : 0.03, Hamming distance : 4
magnitude
20
40
60
80
100
50
100
120
0
140
50
100
150
200
250
Observation
60
80
feature dimension
100
120
20
40
60
80
feature dimension
100
120
20
40
60
80
feature dimension
100
120
100
50
0
Implication:
1
XOR result
The differences between
bin magnitudes and a
predefined threshold are
stable for most bins.
40
150
magnitude
Share some common
patterns in magnitudes on
the 128 bins, e.g., the pairwise differences between
most of bins are similar
and stable.
20
300
0.5
0
Distribution of SIFT Median Value
• Distribution on 100 million SIFT features
6
7
x 10
frequency of SIFT feature
6
5
4
3
2
1
0
0
10
20
30
40
50
median value
60
70
80
Scalar Quantization
• Generalize Scalar Quantization
– Encode each dimension with multi-bits, e.g., 2 bits
– Trade-off between memory and accuracy
150
(1, 1)
(0, 0)
(1, 0)
magnitude
100
50
0
f2
0
20
f1
40
60
80
100
SIFT descriptor bin (sorted by magnitude)
120
A typical SIFT descriptor with bin magnitude sorted in descending order
Scalar Quantization
• Each dimension is encoded with one bit
– In practice, we quantize each dimension with 2 bits
• Considering memory and accuracy
(1, 1)
if f i
bi , bi 128 (1, 0) if fˆ1 f i
(0, 0)
if f i
fˆ2
fˆ2
fˆ1
(i 1,2,, d )
g 64 g 65 ˆ g 32 g 33
ˆ
, f2
where f1
2
2
( g1, g 2 ,, g128) is descendingly sorted from ( f1, f 2 ,, f128)
Visual Matching by Scalar Quantization
• Given SIFT f (1) from Image Iq and f (2) from image Id
• Perform scalar quantization:
f (1) b(1) ;
f (2) b(2)
• f (1) matches f (2), if Hamming distance
d(b(1), b(2)) < Threshold
DF xor distance : 22 (D: 14); L2 dis: 0.10
Real example:
256-bit SIFT binary
signature
Threshold = 24 bits
Binary SIFT Signature
– Given a SIFT descriptor f ( f1, f 2 ,, f d )T R d
– Transform it to a bit vector b (b1, b2 ,, bk d )T
• Each dimension is encoded with k bits, k ≤ log2d
Example:
d=8
1
1
1
1
0
0
0
0
0
0
0
0
1
0
0
1
1
0
0
0
0
0
0
0
Outline
• Motivation
• Our Approach
– Scalar Quantization
–Index structure
– Code Word Expansion
• Experiments
• Conclusions
• Demo
Indexing with Scalar Quantization
• Use inverted file indexing
• Take the top t bits of the SIFT binary signature as
“code word”.
• Store the remaining bits in the entry of indexed
features
• A toy example :
Code Word ID
CW (100)
10010101
Indexed feature list for image database
Indexed
Features
Image ID
……
(10101)
Unique “Code Word” Number
• Code word by 32 bit ->
232 in total ideally
8
10
amount of unique code words
7
10
6
10
5
10
4
10
16
18
20
22
24
bit number t
26
28
30
32
Stop Frequent Code Word
5
2
x 10
1000
visual word frequency
code word frequency
1.5
1
800
600
400
0.5
200
0
0
10
2
4
6
10
10
10
code word rank (sorted by frequency)
8
10
0
0
10
2
4
6
10
10
10
visual word rank (sorted by frequency)
(a)
(b)
Figure . Frequency of code words among one million images (a) before, and (b) after,
application of a stop list.
8
10
Code Word Expansion
• Scalar Quantization Error
– Flipping bits exist in code word
10010101
10110101
– If ignore those flipped bits, many candidate features will
be missed
• Degrade recall !!
– Solution: Expand code word to include flipped code words
• Enumerate all possible nearest neighbors within a predefined
Hamming distance
Code Word Expansion:
Quantization Error Reduction
Visual Word ID
2-bit flipping
Indexed feature list for image database
VW0 (000)
……
VW1 (001)
……
VW2 (010)
……
VW3 (011)
……
VW4 (100)
……
VW5 (101)
……
VW6 (110)
……
VW7 (111)
……
Analysis on Recall of Valid Features
01001…001010…1010111…110101…110001…101110
224 bits for in index list
32 bits for code word
Retrieved features as candidates:
All candidate features :
S {HamDis 32 2}
{HamDis 256 24}
S
recall
39 .8%
Popular Quantization Schemes
•
•
•
•
•
•
K-means
K-d tree
LSH
Product quantization
Scalar quantization
Cascaded Scalable Hashing
Cascaded Scalable Hashing (TMM’13)
SIFT: (12, 0, 1, 3, 45, 76, ……, 9, 21, 3, 1, 1, 0)
Keep high
precision
PCA
Keep high
recall
Binary Signature
Generation
Hashing
Hashing
>80% false
positive
>80% false
positive
…
Hashing
>80% false
positive
Binary Signature
Verification
SCH: Problem Formulation
• Nearest Neighbor (NN) by distance criterion
• Relax NN to approximate nearest neighbor:
• How to determine the threshold ti in each dimension?
– pi(x): probability density function in dimension i
– r i:
relative recall rate in dimension i, as
SCH: Problem Formulation (II)
• Relative recall rate in dimension i:
• Total recall rate by cascading c dimensions:
• To ensure high total recall, impose the constraint on
the recall rate of each dimensions:
• Then total recall:
Hashing in Single Dimension
• Feature matching criteria:
0.05
1
0.04
0.8
accumulated probability
probability density
Distance criterion: Given a test feature from one image, the normalized L2distance from the nearest neighbor of a comparison image is less than ϵ.
Distance ratio criterion: Given a test feature from one image, the distance
ratio between the nearest and second nearest neighbors of a comparison
image is less than 0.80.
0.03
0.02
0.01
0
0
20
40
60
80
absolute coefficient difference
100
0.6
0.4
0.2
0
0
20
40
60
80
absolute coefficient difference
100
Hashing in Single Dimension
• Scalar quantization/hashing in each dimension:
• Cascaded hashing across c dimensions:
– The SCH result can be further represented as a scalar key
– Each indexed feature is hashed to only one key
• Online query hashing:
– Each query feature is hashed to at most 2c keys
Binary Signature Generation
• For those bins in PSIFT after the top c dimensions,
• Feature matching verification
– Checking the hamming distance between binary signatures