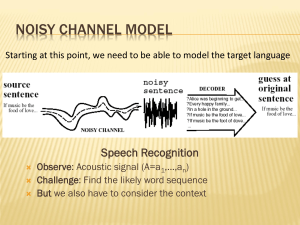
lecture2
advertisement

LING/C SC 581:
Advanced Computational Linguistics
Lecture Notes
Jan 20th
Today's Topics
• 1. LR(k) grammar contd. Homework 1
– (Due by midnight before next lecture: i.e. Tuesday
26th before midnight)
– One PDF file writeup: email to
sandiway@email.arizona.edu
• 2. N-gram models and Colorless green ideas
sleep furiously
Recap: dotted rule notation
• notation
– “dot” used to track the progress of a parse
through a phrase structure rule
– examples
• vp --> v . np
means we’ve seen v and are predicting an np
• np --> . dt nn
means we’re predicting a dt (followed by nn)
• vp --> vp pp.
means we’ve completed the RHS of a vp
Recap: Parse State
• state
– a set of dotted rules encodes the state of the parse
– set of dotted rules = name of the state
• kernel
• vp --> v . np
• vp --> v .
• completion (of predict NP)
• np --> . dt nn
• np --> . nnp
• np --> . np sbar
Recap: Shift and Reduce Actions
• two main actions
– Shift
• move a word from the input onto the stack
• Example:
– np --> .dt nn
– Reduce
• build a new constituent
• Example:
– np --> dt nn.
Recap: LR State Machine
• Built by advancing the dot over terminals and nonterminals
• Start state 0:
– SS --> . S $
– complete this state
• Shift action: LHS --> . POS …
1.
2.
move word with POS tag from input queue onto stack
goto new state indicated by the top of stack state x POS
• Reduce action: LHS --> RHS .
1.
2.
3.
pop |RHS| items off the stack
wrap [LHS ..RHS..] and put back onto the stack
goto new state indicated by the top of the stack state x LHS
LR State Machine Example
State 5
np np pp.
State 13
ss s $.
$
State 1
ss s .$
np
s
State 0
ss .s $
s .np vp
np .np pp
np .n
np .d n
State 4
s np .vp
np np .pp
vp .v np
vp .v
vp .vp pp
pp .p np
pp
vp
pp
p
State 6
pp p .np
np .np pp
np .n
np .d n
p
v
State 8
s np vp.
vp vp .pp
pp .p np
p
np
State 11
pp p np.
np np. pp
pp .p np
n
n
d
State 3
np n.
n
d
d
State 2
np d .n
n
pp
State 7
vp v .np
vp v .
np .np pp
np .n
np .d n
State 12
np d n.
p
np
State 9
vp vp pp.
pp
State 10
vp v np.
np np. pp
pp .p np
Prolog Code
• Files on webpage:
1.
2.
3.
4.
5.
grammar0.pl
lr0.pl
parse.pl
lr1.pl
parse1.pl
LR(k) in the Chomsky Hierarchy
• Definition: a grammar is said to be LR(k) for
some k = 0,1,2.. if the LR state machine for
that grammar is unambiguous
– i.e. are no conflicts, only one possible action…
RL = Regular
Languages
LR(0) RL
LR(1)
Context-Free Languages
LR(k) in the Chomsky Hierarchy
• If there is ambiguity, we can still use the LR
Machine with:
1. Pick one action, and use backtracking for
alternative actions, or
2. Run actions in parallel
grammar0.pl
1.
2.
rule(ss,[s,$]).
rule(s,[np,vp]).
3.
4.
5.
rule(np,[dt,nn]).
rule(np,[nnp]).
rule(np,[np,pp]).
6.
7.
8.
9.
rule(vp,[vbd,np]).
rule(vp,[vbz]).
rule(vp,[vp,pp]).
rule(pp,[in,np]).
10.
11.
12.
13.
14.
15.
lexicon(the,dt). lexicon(a,dt).
lexicon(man,nn). lexicon(boy,nn).
lexicon(limp,nn). lexicon(telescope,nn).
lexicon(john,nnp).
lexicon(saw,vbd). lexicon(runs,vbz).
lexicon(with,in).
grammar0.pl
1.
2.
3.
4.
5.
nonT(ss). nonT(s). nonT(np). nonT(vp). nonT(pp).
term(nnp). term(nn).
term(vbd). term(vbz).
term(in). term(dt).
term($).
6.
start(ss).
Some useful Prolog
• Primitives:
– tell(Filename)
– told
redirect output to Filename
close the file and stop redirecting
output
• Example:
– tell('machine.pl'),goal,told.
– means run goal and capture all output to a file called
machine.pl
lr0.pl
• Example:
lr0.pl
lr0.pl
action(State#, CStack, Input, ParseStack, CStack', Input',ParseStack')
parse.pl
lr0.pl
lr1.pl and parse1.pl
• Similar code for LR(1) – 1 symbol of lookahead
lr1.pl and parse1.pl
• Similar code for LR(1) – 1 symbol of lookahead
parse1.pl
Homework 1
• Question 1:
– How many states are built for the LR(0) and the
LR(1) machines?
Homework 1
• Question 2:
– Examine the action predicate built by LR(0)
– Assume there is no possible conflict between two
shift actions, e.g. shift dt or nnp
– Is grammar0.pl LR(0)? Explain.
• Question 3:
– Is grammar0.pl LR(1)? Explain.
Homework 1
• Question 4:
– run the sentence: John saw the boy with the
telescope
– on both LR(0) and LR(1) machines
– How many states are visited to parse both
sentences completely in the two machines?
– Is the LR(1) any more efficient than the LR(0)
machine?
Homework 1
• Question 5:
– run the sentence: John saw the boy with a limp
with the telescope
– on both LR(0) and LR(1) machines
– How many parses are obtained?
– How many states are visited to parse the sentence
completely in the two machines?
Homework 1
• Question 6:
– Compare these two states in the LR(1) machine:
Can we merge these two states?
Explain why or why not.
How could you test your answer?
Break …
Language Models and N-grams
• given a word sequence
– w1 w2 w3 ... wn
• chain rule
–
–
–
–
–
how to compute the probability of a sequence of words
p(w1 w2) = p(w1) p(w2|w1)
p(w1 w2 w3) = p(w1) p(w2|w1) p(w3|w1w2)
...
p(w1 w2 w3...wn) = p(w1) p(w2|w1) p(w3|w1w2)... p(wn|w1...wn-2 wn-1)
• note
– It’s not easy to collect (meaningful) statistics on p(wn|wn-1wn-2...w1) for all
possible word sequences
Language Models and N-grams
•
Given a word sequence
– w1 w2 w3 ... wn
•
Bigram approximation
–
–
–
–
just look at the previous word only (not all the proceedings words)
Markov Assumption: finite length history
1st order Markov Model
p(w1 w2 w3...wn) = p(w1) p(w2|w1) p(w3|w1w2) ...p(wn|w1...wn-3wn-2wn-1)
– p(w1 w2 w3...wn) p(w1) p(w2|w1) p(w3|w2)...p(wn|wn-1)
•
note
– p(wn|wn-1) is a lot easier to collect data for (and thus estimate well) than p(wn|w1...wn-2
wn-1)
Language Models and N-grams
• Trigram approximation
– 2nd order Markov Model
– just look at the preceding two words only
– p(w1 w2 w3 w4...wn) = p(w1) p(w2|w1) p(w3|w1w2) p(w4|w1w2w3)...p(wn|w1...wn3wn-2wn-1)
– p(w1 w2 w3...wn) p(w1) p(w2|w1) p(w3|w1w2)p(w4|w2w3)...p(wn |wn-2 wn-1)
• note
– p(wn|wn-2wn-1) is a lot easier to estimate well than p(wn|w1...wn-2 wn-1) but
harder than p(wn|wn-1 )
Language Models and N-grams
• estimating from corpora
– how to compute bigram probabilities
–
p(wn|wn-1) = f(wn-1wn)/f(wn-1w)
w is any word
–
Since f(wn-1w) = f(wn-1)
f(wn-1) = unigram frequency for wn-1
–
p(wn|wn-1) = f(wn-1wn)/f(wn-1)
relative frequency
• Note:
– The technique of estimating (true) probabilities using a relative
frequency measure over a training corpus is known as maximum
likelihood estimation (MLE)
Motivation for smoothing
• Smoothing: avoid zero probability estimates
• Consider
p(w1 w2 w3...wn) p(w1) p(w2|w1) p(w3|w2)...p(wn|wn-1)
• what happens when any individual probability component is
zero?
– Arithmetic multiplication law: 0×X = 0
– very brittle!
• even in a very large corpus, many possible n-grams over
vocabulary space will have zero frequency
– particularly so for larger n-grams
Language Models and N-grams
• Example:
wn
wn-1wn bigram
frequencies
wn-1
unigram
frequencies
bigram
probabilities
sparse matrix
zeros render probabilities
unusable
(we’ll need to add fudge
factors - i.e. do smoothing)
Smoothing and N-grams
• sparse dataset means zeros are a problem
– Zero probabilities are a problem
•
p(w1 w2 w3...wn) p(w1) p(w2|w1) p(w3|w2)...p(wn|wn-1) bigram model
• one zero and the whole product is zero
– Zero frequencies are a problem
•
p(wn|wn-1) = f(wn-1wn)/f(wn-1)
relative frequency
• bigram f(wn-1wn) doesn’t exist in dataset
• smoothing
– refers to ways of assigning zero probability n-grams a non-zero value
Smoothing and N-grams
•
Add-One Smoothing (4.5.1 Laplace Smoothing)
–
–
•
add 1 to all frequency counts
simple and no more zeros (but there are better methods)
must
rescale so
p(w) = f(w)/N
(before Add-One)
• N = size of corpus
that total
p(w) = (f(w)+1)/(N+V)
(with Add-One)
probability
f*(w) = (f(w)+1)*N/(N+V) (with Add-One)
mass stays
• V = number of distinct words in corpus
1 size caused by
• N/(N+V) normalization factor adjusting for the effective increase in the at
corpus
unigram
–
–
–
Add-One
•
bigram
–
–
–
p(wn|wn-1) = f(wn-1wn)/f(wn-1)
p(wn|wn-1) = (f(wn-1wn)+1)/(f(wn-1)+V)
f*(wn-1 wn) = (f(wn-1 wn)+1)* f(wn-1) /(f(wn-1)+V)
(before Add-One)
(after Add-One)
(after Add-One)
Smoothing and N-grams
•
Add-One Smoothing
–
•
bigram
–
–
•
Remarks:
perturbation problem
add 1 to all frequency counts
p(wn|wn-1) = (f(wn-1wn)+1)/(f(wn-1)+V)
(f(wn-1 wn)+1)* f(wn-1) /(f(wn-1)+V)
add-one causes large
changes in some
frequencies due to
relative size of V (1616)
frequencies
I
want
to
eat
Chinese
food
lunch
I want to eat Chinese food lunch
8 1087
0 13
0
0
0
3
0 786
0
6
8
6
3
0 10 860
3
0
12
0
0
2
0
19
2
52
2
0
0
0
0 120
1
19
0 17
0
0
0
0
4
0
0
0
0
1
0
I
want
to
eat
Chinese
food
lunch
I
6.12
1.72
2.67
0.37
0.35
9.65
1.11
want
740.05
0.43
0.67
0.37
0.12
0.48
0.22
to
0.68
337.76
7.35
1.10
0.12
8.68
0.22
= figure 6.4
eat
Chinese food lunch
9.52
0.68
0.68
0.68
0.43
3.00
3.86
3.00
575.41
2.67
0.67
8.69
0.37
7.35
1.10 19.47
0.12
0.12 14.09
0.23
0.48
0.48
0.48
0.48
0.22
0.22
0.44
0.22
want to: 786 338
= figure 6.8
Smoothing and N-grams
•
Add-One Smoothing
–
•
bigram
–
–
•
Remarks:
perturbation problem
add 1 to all frequency counts
p(wn|wn-1) = (f(wn-1wn)+1)/(f(wn-1)+V)
(f(wn-1 wn)+1)* f(wn-1) /(f(wn-1)+V)
similar changes in
probabilities
Probabilities
I
want
to
eat
Chinese
food
lunch
I
0.00233
0.00247
0.00092
0.00000
0.00939
0.01262
0.00871
want
0.31626
0.00000
0.00000
0.00000
0.00000
0.00000
0.00000
to
0.00000
0.64691
0.00307
0.00213
0.00000
0.01129
0.00000
eat
Chinese
0.00378 0.00000
0.00000 0.00494
0.26413 0.00092
0.00000 0.02026
0.00000 0.00000
0.00000 0.00000
0.00000 0.00000
food
0.00000
0.00658
0.00000
0.00213
0.56338
0.00000
0.00218
lunch
0.00000
0.00494
0.00369
0.05544
0.00469
0.00000
0.00000
I
want
to
eat
Chinese
food
lunch
I
0.00178
0.00141
0.00082
0.00039
0.00164
0.00641
0.00241
want
0.21532
0.00035
0.00021
0.00039
0.00055
0.00032
0.00048
to
0.00020
0.27799
0.00226
0.00117
0.00055
0.00577
0.00048
eat
Chinese
0.00277 0.00020
0.00035 0.00247
0.17672 0.00082
0.00039 0.00783
0.00055 0.00055
0.00032 0.00032
0.00048 0.00048
food
0.00020
0.00318
0.00021
0.00117
0.06616
0.00032
0.00096
lunch
0.00020
0.00247
0.00267
0.02075
0.00109
0.00032
0.00048
= figure 6.5
= figure 6.7
Smoothing and N-grams
• let’s illustrate the
problem
probability mass
f(wn-1wn)
– take the bigram case:
– wn-1wn
–
p(wn|wn-1) = f(wn-1wn)/f(wn-1)
f(wn-1)
– suppose there are cases
–
wn-1wzero1 that don’t occur in the
corpus
f(wn-1wzero1)=0
... zero
f(wn-1w
m)=0
Smoothing and N-grams
• add-one
–
“give everyone 1”
probability mass
f(wn-1wn)+1
f(wn-1)
f(wn-1w01)=1
...
f(wn-1w0m)=1
Smoothing and N-grams
• add-one
–
“give everyone 1”
probability mass
f(wn-1wn)+1
• redistribution of probability mass
– p(wn|wn-1) = (f(wn1wn)+1)/(f(wn-1)+V)
f(wn-1)
f(wn-1w01)=1
...
w0 )=1
f(wn-1
m
V = |{wi}|
Smoothing and N-grams
•
Good-Turing Discounting (4.5.2)
–
–
–
–
–
–
–
–
•
Nc = number of things (= n-grams) that occur c times in the corpus
N = total number of things seen
Formula: smoothed c for Nc given by c* = (c+1)Nc+1/Nc
Idea: use frequency of things seen once to estimate frequency of things we haven’t seen yet
estimate N0 in terms of N1…
and so on but if Nc =0, smooth that first using something like log(Nc)=a+b log(c)
Formula: P*(things with zero freq) = N1/N
smaller impact than Add-One
Textbook Example:
–
Fishing in lake with 8 species
•
–
Sample data (6 out of 8 species):
•
–
–
–
–
bass, carp, catfish, eel, perch, salmon, trout, whitefish
10 carp, 3 perch, 2 whitefish, 1 trout, 1 salmon, 1 eel
P(unseen new fish, i.e. bass or carp) = N1/N = 3/18 = 0.17
P(next fish=trout) = 1/18
• (but, we have reassigned probability mass, so need to recalculate this from the smoothing formula…)
revised count for trout: c*(trout) = 2*N2/N1=2(1/3)=0.67 (discounted from 1)
revised P(next fish=trout) = 0.67/18 = 0.037
Language Models and N-grams
• N-gram models
– data is easy to obtain
• any unlabeled corpus will do
– they’re technically easy to compute
• count frequencies and apply the smoothing formula
– but just how good are these n-gram language
models?
– and what can they show us about language?
Language Models and N-grams
approximating Shakespeare
–
–
•
generate random sentences using n-grams
Corpus: Complete Works of Shakespeare
Unigram (pick random, unconnected words)
•
Bigram
Language Models and N-grams
•
Approximating Shakespeare
–
–
•
generate random sentences using n-grams
Corpus: Complete Works of Shakespeare
Trigram
Remarks:
dataset size problem
training set is small
884,647 words
29,066 different words
29,0662 = 844,832,356
possible bigrams
•
Quadrigram
for the random sentence
generator, this means
very limited choices for
possible continuations,
which means program
can’t be very innovative
for higher n
Language Models and N-grams
• A limitation:
– produces ungrammatical sequences
• Treebank:
– potential to be a better language model
– Structural information:
• contains frequency information about syntactic rules
– we should be able to generate sequences that are
closer to “English”…
Language Models and N-grams
•
Aside: http://hemispheresmagazine.com/contests/2004/intro.htm
Language Models and N-grams
• N-gram models + smoothing
– one consequence of smoothing is that
– every possible concatentation or sequence of
words has a non-zero probability
Colorless green ideas
• examples
– (1) colorless green ideas sleep furiously
– (2) furiously sleep ideas green colorless
• Chomsky (1957):
– . . . It is fair to assume that neither sentence (1) nor (2) (nor
indeed any part of these sentences) has ever occurred in an
English discourse. Hence, in any statistical model for
grammaticalness, these sentences will be ruled out on
identical grounds as equally `remote' from English. Yet (1),
though nonsensical, is grammatical, while (2) is not.
• idea
– (1) is syntactically valid, (2) is word salad
• Statistical Experiment (Pereira 2002)
Colorless green ideas
• examples
– (1) colorless green ideas sleep furiously
– (2) furiously sleep ideas green colorless
• Statistical Experiment (Pereira 2002)
wi-1
wi
bigram language model
Interesting things to Google
• example
– colorless green ideas sleep furiously
• Second hit
Interesting things to Google
• example
– colorless green ideas sleep furiously
• first hit
– compositional semantics
–
–
–
–
–
a green idea is, according to well established usage of the word "green" is one that is an
idea that is new and untried.
again, a colorless idea is one without vividness, dull and unexciting.
so it follows that a colorless green idea is a new, untried idea that is without vividness,
dull and unexciting.
to sleep is, among other things, is to be in a state of dormancy or inactivity, or in a state
of unconsciousness.
to sleep furiously may seem a puzzling turn of phrase but one reflects that the mind in
sleep often indeed moves furiously with ideas and images flickering in and out.