Секция Td. HSE PhD Seminar. Universalism and Relativism in the
advertisement

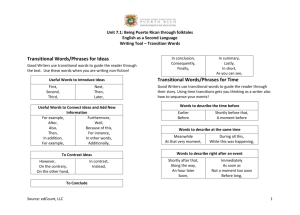
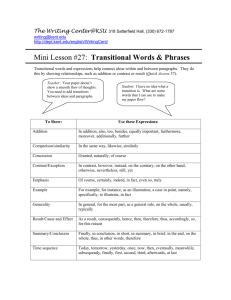
Секция Td. HSE PhD Seminar. Universalism and Relativism in the Philosophy of Language and Mind 10 апреля, пятница 10:00-11:30 Аудитория 240 М-20 Сеccия Td-09. Opening and Keynote Speech. Maria Polinsky (Harvard University, Professor, Department of Linguistics, Director of Undergraduate Studies (DUS), Head of "Polinsky Language Sciences Lab" (PI) Доклад М. Полинской Linguistics and cognitive sciences: In need of a partnership This talk addresses several basic principles of theoretical linguistics that are supported by experimental evidence. It also gives examples of the need for hierarchical representation of language in the modeling of cognitive phenomena. 12:00-13:30 Аудитория 226 М-20 Сеccия Td-10/2. Session V Председатель сессии: O. Lyashevskaya (HSE) I. Kuznetsov (HSE) Semantic Role Labeling for Russian language based on Russian FrameBank Илья Кузнецов (НИУ ВШЭ) Semantic Role Labeling for Russian language based on Russian FrameBank Semantic Role Labeling (SRL), often referred to as shallow semantic parsing, is one of the major research areas in today's natural language processing. The task can be described as follows: given an input sentence, that refers to some situation, find the participants of this situation in text and assign them semantically motivated labels, or roles. While major research effort has been put into developing SRL systems for English language, there have been only few works on Russian SRL, mostly due to the fact that Russian language lacks resources and training data for that task. In our work we present a supervised semantic role labeling system for Russian based on FrameBank, an actively developing Russian SRL resource analogous to FrameNet and PropBank. A. Shelya (University of Tartu, Estonia) Towards building a corpus of Soviet song poetry Артем Шеля (университет Тарту) К построению корпуса советской песенной поэзии Корпусная поэтика, использующая большие массивы размеченных текстов для решения литературоведческих задач разного уровня и сложности, позволяет изменить привычный масштаб зрения ученого. Вместо группы отдельных текстов, медленное чтение которых как правило санкционировано литературным каноном, можно собирать информацию в пределах целых текстовых полей, оперируя машинными и статистическими инструментами внутри корпуса. Такое "чтение издалека" (distant reading) особенно закономерно в тех случаях, когда исследователь сталкивается с массовой литературной продукцией эпохи: она одновременно ориентирована на воспроизведение типовых моделей и неограничена в объемах. Советская песенная лирика является таким относительно гомогенным и широким полем: вместо набора дискретных текстов, ее можно представить в виде единого корпуса и в этом масштабе наблюдать за семантическими тенденциями поля, его трансформациями и трансляцией внутри него "ключевых слов" эпохи и ее идеологических формул. Корпус советской песни, над которым ведется работа, строится исходя из двух основных принципов. С одной стороны, рассчитывается, что база данных, которая формируется изначально из текстов песен сталинской эпохи (~1930-1956 гг.), может послужить моделью для дальнейшего подключения корпусов текстов подобного типа. Целью является сводный корпус песенной лирики, доступный исследователям. С другой стороны, эта база данных строится для решения прикладных задач, связанных с песенной лирикой изучаемого периода, и дает возможность использовать расширенный инструментарий на размеченном корпусе текстов. В частности, с привлечением корпусной статистики, можно будет провести кластеризацию текстов и построить жанрово-тематическую классификацию, отказавшись от предзаданного языка традиционного жанрового описания. Моделирование, заимствованное, например, из популяционной генетики, открывает возможность описать на основе корпуса (в том случае, если его разметка действительно разветвленная) диахроническое измерение советской песни, внутренние трансформации и эволюцию этих изменений, которые в пределе можно будет представить в виде филогенетических деревьев. 15:00-16:30 Аудитория 226 М-20 Сеccия Td-11/2. Session VI Председатель сессии: A. Bonch-Osmolovskaya (HSE) D. Ryzhova (HSE) Distributional semantic models in lexical typology J. Hughes (Lancaster University, UK) The collocation hypothesis: Evidence from self-paced reading Jennifer Hughes (Lancaster University) The collocation hypothesis: Evidence from self-paced reading There is growing evidence to suggest that formulaic sequences are processed more quickly than non-formulaic sequences by native speakers of English (Conklin and Schmitt 2012:56). However, comparatively few studies have investigated the processing of formulaic sequences by learners of English (Wray 2002:144; Schmitt et al. 2004:55). These studies have either reported mixed results (Conklin and Schmitt 2012:45), or demonstrated a processing advantage only for fixed idioms or other highly restricted formulaic sequences (e.g. Conklin and Schmitt 2008:83; Underwood et al. 2004:160-161). In this paper, we present the results of a self-paced reading experiment which aimed to find out whether formulaic sequences are processed more quickly than non-formulaic sequences by 20 native speakers and 20 learners of English. However, instead of focusing on fixed idioms or other highly restricted formulaic sequences, we assume a broader conceptualisation of formulaic language by focusing on transitional probabilities, i.e. the probability of word Y being produced given that the previous word was X. The research questions are: (1) Do native speakers of English and learners of English process the nouns in adjectivenoun bigrams more quickly in bigrams that have a higher transitional probability compared to bigrams that have a lower transitional probability? (2) If learners of English are found to be sensitive to the transitional probabilities between words, is this sensitivity related to their English proficiency level and/or to their level of acculturation into the English-speaking community? (3) If there is a difference in reading time between the nouns in both conditions, is this difference in reading time sustained to the words that follow the noun? The transitional probabilities were calculated by dividing the number of times the bigram Xthen-Y occurs in the written section of the BNC by the number of times X occurs in the written section of the BNC altogether (McEnery and Hardie 2012:195). We extracted 10 adjective-noun bigrams with a higher transitional probability (median = 0.0175) and 10 with a lower transitional probability (median = 0.0009). The adjectives were the same in each condition; the nouns were different but were matched for frequency and length. The bigrams were then embedded into plausible sentences for use in the self-paced reading experiment. In order to answer research question 2, we asked the learners to complete an English proficiency test and an acculturation questionnaire. The questionnaire responses were then converted into an overall acculturation score for each learner. The results show that the bigrams with the higher transitional probabilities are processed significantly more quickly than the bigrams with the lower transitional probabilities by both the native speakers and the learners. Furthermore, the words following the bigrams with the higher transitional probabilities are often processed more quickly than the same words following the bigrams with the lower transitional probabilities. There is a significant interaction between the reading times and the proficiency level of the participants. However, no significant relationship was found between the reading times and the learners’ level of acculturation into the English-speaking community. In sum, these results therefore provide further confirmation for the psychological reality of formulaicity and collocation and their importance in language learning. 17:00-18:30 Аудитория 226 М-20 Сеccия Td-12/2. Session VII Председатель сессии: A. Bonch-Osmolovskaya (HSE) M. Kyuseva (HSE) Words with attributive/property meaning in Russian sign language: a cross-linguistic research