6.1b - Power & Sampl..
advertisement

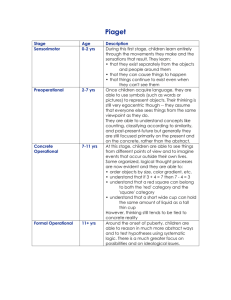
Power and Sample Size
• IF the null hypothesis H : μ = μ
0
•
•
•
0
is true,
“Null Distribution”
then we should expect a random sample
mean to lie in its “acceptance region” with
probability 1 – α, the “confidence level.”
That is,
P(Accept H0 | H0 is true) = 1 – α.
Therefore, we should expect a random
sample mean to lie in its “rejection region”
with probability α, the “significance level.”
That is,
P(Reject H0 | H0 is true) = α.
1
/2
/2
H0: = 0
“Type 1 Error”
Rejection
Region
Acceptance Region
for H0
Rejection
Region
μ0 + zα/2 (σ / n)
Power and Sample Size
“Null Distribution”
“Alternative Distribution”
• IF the null hypothesis H : μ = μ is false,
0
0
then the “power” to correctly reject it in
favor of a particular alternative HA: μ = μ1 is
1–
1
/2
/2
H0: = 0
Rejection
Region
Acceptance Region
for H0
P(Reject H0 | H0 is false) = 1 – .
Thus,
P(Accept H0 | H0 is false) = .
“Type 2 Error”
HA: μ = μ1
Rejection
Region
μ0 + zα/2 (σ / n)
μ1 – z (σ / n)
Set them equal to each other, and solve for n…
z /2 z
| 1 0 |
n
, where
2
Given:
• X ~ N(μ , σ ) Normally-distributed population random variable,
with unknown mean, but known standard deviation
• H0: μ = μ0
Null Hypothesis value
• HA: μ = μ1
Alternative Hypothesis specific value
•
significance level (or equivalently, confidence level 1 – )
• 1–
power (or equivalently, Type 2 error rate )
Then the minimum required sample size is:
N(0, 1)
z /2 z
| 1 0 |
n
,
where
2
1
z
Example: σ = 1.5 yrs, μ0 = 25.4 yrs, = .05 z.025 = 1.96
Suppose it is suspected that currently, μ1 = 26 yrs.
Want 90% power of correctly rejecting H0 in favor of HA, if it is false
1 – = .90 = .10 z.10 = 1.28
= |26 – 25.4| / 1.5 = 0.4
2
1.96 + 1.28
n
So… minimum sample size required is
65.61
0.4
n 66
Given:
• X ~ N(μ , σ ) Normally-distributed population random variable,
with unknown mean, but known standard deviation
• H0: μ = μ0
Null Hypothesis value
• HA: μ = μ1
Alternative Hypothesis specific value
•
significance level (or equivalently, confidence level 1 – )
• 1–
power (or equivalently, Type 2 error rate )
Then the minimum required sample size is:
N(0, 1)
z /2 z
| 1 0 |
n
,
where
2
1
z
Example: σ = 1.5 yrs, μ0 = 25.4 yrs, = .05 z.025 = 1.96
Suppose it is suspected that currently, μ1 = 26 yrs.
Want 95%
90% power of correctly rejecting H0 in favor of HA, if it is false
1.28
.90 = .05
.10 z.05
1 – = .95
.10 = 1.645
= |26 – 25.4| / 1.5 = 0.4
2 2
1.645
1.96 + 1.28
n
65.61
81.225
So… minimum sample size required is
0.4
0.4
n 82
66
Given:
• X ~ N(μ , σ ) Normally-distributed population random variable,
with unknown mean, but known standard deviation
• H0: μ = μ0
Null Hypothesis value
• HA: μ = μ1
Alternative Hypothesis specific value
•
significance level (or equivalently, confidence level 1 – )
• 1–
power (or equivalently, Type 2 error rate )
Then the minimum required sample size is:
N(0, 1)
z /2 z
| 1 0 |
n
,
where
2
1
Example: σ = 1.5 yrs, μ0 = 25.4 yrs, = .05 z.025 = 1.96
z
Suppose it is suspected that currently, μ1 = 25.7
26 yrs.
yrs.
Want 95% power of correctly rejecting H0 in favor of HA, if it is false
1 – = .95 = .05 z.05 = 1.645
= |25.7
|26 – –
25.4|
25.4|
/ 1.5
/ 1.5
==
0.4
0.2
2
1.96 + 1.645
81.225
324.9
So… minimum sample size required is n
0.4
0.2
n 325
82
Given:
• X ~ N(μ , σ ) Normally-distributed population random variable,
with unknown mean, but known standard deviation
• H0: μ = μ0
Null Hypothesis value
• HA: μ = μ1
Alternative Hypothesis specific value
•
significance level (or equivalently, confidence level 1 – )
• 1–
power (or equivalently, Type 2 error rate )
Then the minimum required sample size is:
N(0, 1)
z /2 z
| 1 0 |
n
,
where
2
Example: σ = 1.5 yrs, μ0 = 25.4 yrs, = .05 z.025 = 1.96
1
z
Suppose it is suspected that currently, μ1 = 25.7 yrs.
With n = 400, how much power exists to correctly reject H0 in favor of HA, if it is false?
Power = 1 – = P Z z /2 n
P Z 1.96 0.2 400
P Z 2.04 = 0.9793, i.e., 98%
Given:
• X ~ N(μ , σ ) Normally-distributed population random variable,
with unknown mean, but known standard deviation
• H0: μ = μ0
Null Hypothesis
• HA: μ ≠ μ0
Alternative Hypothesis (2-sided)
•
significance level (or equivalently, confidence level 1 – )
• n
sample size
From this, we obtain…
s
n
x1, x2,…, xn
But this introduces additional
variability from one sample to
another… PROBLEM!
“standard error” s.e.
(estimate)
x
s
sample mean
sample standard deviation
…with which to test the null hypothesis (via CI, AR, p-value).
In practice however, it is far more common that the
true population standard deviation σ is unknown.
So we must estimate it from the sample!
Recall that
s2
2
(
x
x
)
i
n 1
SS
df
Given:
• X ~ N(μ , σ ) Normally-distributed population random variable,
with unknown mean, but known standard deviation
• H0: μ = μ0
Null Hypothesis
• HA: μ ≠ μ0
Alternative Hypothesis (2-sided)
•
significance level (or equivalently, confidence level 1 – )
• n
sample size
From this, we obtain…
s
n
x1, x2,…, xn
“standard error” s.e.
(estimate)
x
s
But this introduces additional
variability from one sample to
another… PROBLEM!
sample mean
sample standard deviation
…with which to test the null hypothesis (via CI, AR, p-value).
SOLUTION: X follows a different sampling distribution from before.
… is actually a family of distributions, indexed
by the degrees of freedom, labeled tdf.
Z ~ N(0, 1)
t10
tt3
2
t1
William S. Gossett
(1876 - 1937)
As the sample size n gets large, tdf converges to the standard normal
distribution Z ~ N(0, 1). So the T-test is especially useful when n < 30.
… is actually a family of distributions, indexed
by the degrees of freedom, labeled tdf.
Z ~ N(0, 1)
t4
.025
William S. Gossett
(1876 - 1937)
1.96
As the sample size n gets large, tdf converges to the standard normal
distribution Z ~ N(0, 1). So the T-test is especially useful when n < 30.
Lecture Notes Appendix…
or…
qt(.025, 4, lower.tail = F)
[1] 2.776445
… is actually a family of distributions, indexed
by the degrees of freedom, labeled tdf.
Z ~ N(0, 1)
t4
.025
William S. Gossett
(1876 - 1937)
.025
1.96
2.776
Because any t-distribution has heavier tails than the Z-distribution,
it follows that for the same right-tailed area value, t-score > z-score.
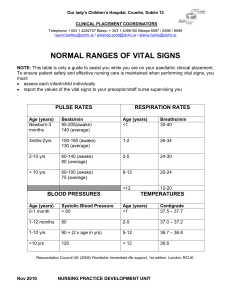
Given:
X = Age at first birth ~ N(μ , σ )
• H0: μ = 25.4 yrs Null Hypothesis
• HA: μ ≠ 25.4 yrs Alternative Hypothesis
Previously…
σ = 1.5 yrs, n = 400, x 25.6 yrs
statistically significant at = .05
Now suppose that σ is unknown, and n < 30.
Example: n = 16, x 25.9 yrs, s = 1.22 yrs
• standard error (estimate) =
• .025 critical value = t15, .025
s
1.22 yrs
0.305 yrs
16
n
Lecture Notes Appendix…
Given:
X = Age at first birth ~ N(μ , σ )
• H0: μ = 25.4 yrs Null Hypothesis
• HA: μ ≠ 25.4 yrs Alternative Hypothesis
Previously…
σ = 1.5 yrs, n = 400, x 25.6 yrs
statistically significant at = .05
Now suppose that σ is unknown, and n < 30.
Example: n = 16, x 25.9 yrs, s = 1.22 yrs
• standard error (estimate) =
s
1.22 yrs
0.305 yrs
16
n
• .025 critical value = t15, .025 = 2.131
95% Confidence Interval =
(25.9 – 0.65, 25.9 + 0.65) =
(25.25, 26.55) yrs
p-value = 2 P ( X 25.9)
2P(T15 1.639)
Test Statistic: T15
25.9 - 25.4
0.305
95% margin of error
= (2.131)(0.305 yrs)
= 0.65 yrs
Lecture Notes Appendix…
Given:
X = Age at first birth ~ N(μ , σ )
• H0: μ = 25.4 yrs Null Hypothesis
• HA: μ ≠ 25.4 yrs Alternative Hypothesis
Previously…
σ = 1.5 yrs, n = 400, x 25.6 yrs
statistically significant at = .05
Now suppose that σ is unknown, and n < 30.
Example: n = 16, x 25.9 yrs, s = 1.22 yrs
• standard error (estimate) =
s
1.22 yrs
0.305 yrs
16
n
• .025 critical value = t15, .025 = 2.131
95% Confidence Interval =
(25.9 – 0.65, 25.9 + 0.65) =
(25.25, 26.55) yrs
p-value = 2 P ( X 25.9)
2 P(T15 1.639)
= 2 (between .05 and .10)
= between .10 and .20.
95% margin of error
= (2.131)(0.305 yrs)
= 0.65 yrs
The 95% CI does contain the null value μ = 25.4.
The p-value is between .10 and .20, i.e., > .05.
(Note: The R command
2 * pt(1.639, 15, lower.tail = F)
gives the exact p-value as .122.)
Not statistically significant; small n gives low power!
Lecture Notes Appendix A3.3… (click for details on this section)
To summarize…
Assuming X ~ N(, σ),
σ) test H0: = 0 vs. HA: ≠ 0, at level α…
If the population variance 2 is known, then use it with the Z-distribution, for any n.
If the population variance 2 is unknown, then estimate it by the sample variance s 2,
and use:
• either T-distribution (more accurate), or the Z-distribution (easier), if n 30,
• T-distribution only, if n < 30.
ALSO SEE PAGE 6.1-28
Lecture Notes Appendix A3.3… (click for details on this section)
To summarize…
Assuming X ~ N(, σ),
σ) test H0: = 0 vs. HA: ≠ 0, at level α…
If the population variance 2 is known, then use it with the Z-distribution, for any n.
If the population variance 2 is unknown, then estimate it by the sample variance s 2,
and use:
• either T-distribution (more accurate), or the Z-distribution (easier), if n 30,
• T-distribution only, if n < 30.
ALSO SEE PAGE 6.1-28
Assuming X ~ N(, σ)
How do we check that this assumption is
reasonable, when all we have is a sample?
{ x1 , x2 , x3 ,…, x24 }
And what do we do if it’s not, or we can’t tell?
Z ~ N(0, 1)
IF our data approximates a bell
curve, then its quantiles should
“line up” with those of N(0, 1).
Assuming X ~ N(, σ)
How do we check that this assumption is
reasonable, when all we have is a sample?
{ x1 , x2 , x3 ,…, x24 }
And what do we do if it’s not, or we can’t tell?
Sample quantiles
Z ~ N(0, 1)
IF our data approximates a bell
curve, then its quantiles should
“line up” with those of N(0, 1).
• Q-Q plot
• Normal scores plot
• Normal probability plot
Assuming X ~ N(, σ)
How do we check that this assumption is
reasonable, when all we have is a sample?
And what do we do if it’s not, or we can’t tell?
IF our data approximates a bell
curve, then its quantiles should
“line up” with those of N(0, 1).
• Q-Q plot
• Normal scores plot
• Normal probability plot
qqnorm(mysample)
(R uses a slight variation
to generate quantiles…)
Assuming X ~ N(, σ)
How do we check that this assumption is
reasonable, when all we have is a sample?
And what do we do if it’s not, or we can’t tell?
IF our data approximates a bell
curve, then its quantiles should
“line up” with those of N(0, 1).
• Q-Q plot
• Normal scores plot
• Normal probability plot
qqnorm(mysample)
(R uses a slight variation
to generate quantiles…)
Formal statistical tests
exist; see notes.
Assuming X ~ N(, σ)
How do we check that this assumption is
reasonable, when all we have is a sample?
And what do we do if it’s not, or we can’t tell?
Use a mathematical “transformation” of the data (e.g., log, square root,…).
x = rchisq(1000, 15)
hist(x)
y = log(x)
hist(y)
X is said to be “log-normal.”
How do we check that this assumption is
reasonable, when all we have is a sample?
Assuming X ~ N(, σ)
And what do we do if it’s not, or we can’t tell?
Use a mathematical “transformation” of the data (e.g., log, square root,…).
qqnorm(x, pch = 19, cex = .5)
qqline(x)
qqnorm(y, pch = 19, cex = .5)
qqline(y)
Assuming X ~ N(, σ)
How do we check that this assumption is
reasonable, when all we have is a sample?
And what do we do if it’s not, or we can’t tell?
Use a mathematical “transformation” of the data (e.g., log, square root,…).
Use a “nonparametric test” (e.g., Sign Test, Wilcoxon Signed Rank Test).
= Mann-Whitney Test
• These tests make no assumptions on the underlying population distribution!
• Based on “ranks” of the ordered data; tedious by hand…
• Has less power than Z-test or T-test (when appropriate)… but not bad.
• In R, see ?wilcox.test for details….
SEE LECTURE NOTES, PAGE 6.1-28 FOR FLOWCHART OF METHODS
See…
http://pages.stat.wisc.edu/~ifischer/Intro_Stat/Lecture_Notes/6__Statistical_Inference/HYPOTHESIS_TESTING_SUMMARY.pdf