Pricing Large Insureds
advertisement

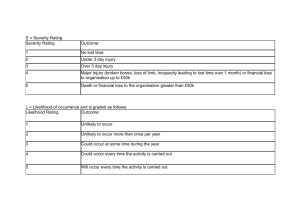
Pricing Large Insureds Stewart Gleason Ernst & Young LLP 2000 Seminar on Ratemaking Pricing Large Insureds • What is meant by “pricing large insureds”? – What is a “large insured”? – Can one always “price” a large insured just because it’s “large”? • What exactly is “industry” data and why do we need it? • Three examples with suggestions on where to find “industry” data “Pricing large insureds” could mean one of the following: • Developing a systematic approach to premium determination for a series of entities whose insurance programs are similar in structure. The approach allows the unique characteristics of a given entity to be incorporated into the analysis. • Developing ad hoc methodology for determination of the premium for a unique or unusual risk. This sounds rather like “individual risk rating”. Examples of some approaches that fall in this category are: • NCCI and ISO experience rating plans • NCCI and ISO retrospective rating plans • Customized retrospective rating procedures (e.g., determining the insurance charge from a risk specific aggregate loss distribution rather than a published table) • Experience rating models which require historical claim detail as an input (e.g., excess of loss reinsurance) • Traditional aggregate methods (i.e., incurred loss development) that use the insured’s experience exclusively • Highly detailed Monte Carlo simulation models Does “large” mean the same thing as “individual” in this situation? Where does “large” fit in? • This is best addressed by answering another question: What is a small insured? Let’s try this: “A small insured is one whose accumulated experience is valueless as a predictor of future experience. Its future loss costs cannot be analyzed without relying on the combined experience of a group of similar risks.” • Therefore, a large insured is… one whose accumulated experience is deemed sufficient to determine or significantly influence the cost of its own insurance. The predictive value of its experience is perceived to be high. • The words “deemed” and “perceived” are illuminating: deciding what is “large” is highly judgmental. Consider the following: • • • • • • An urban hospital system has hundreds of millions of dollars in property values but the property insurance cannot be rated on the system’s own experience. The same hospital system has $75,000,000 in medical malpractice losses annually; this exposure can be and is rated based entirely on the historical data. Exxon has commercial automobile liability exposure from company cars, vans and gasoline tank trucks. This involves lots of money but is so “predictable” they probably don’t even insure it (except for the high excess exposure). Exxon has monolithic exposure from environmental disasters (as in the Exxon Valdez). This is not only unpredictable, it’s almost uninsurable. The world abounds with insureds which at first glance are “large” but for which rating in isolation is essentially hopeless. The conclusion? – low frequency/high severity exposures (as in huge properties and extreme catastrophes) give rise to “small” risks! – high frequency/low severity exposures (as in medical malpractice!) give rise to “large” risks! On to the second question: what exactly is “industry” data? • By “blending in industry data”, we simply mean incorporating the experience of a larger body of insureds to which the entity in question belongs. • Take claim severity distributions, for example. The larger body of experience could be (concentrically): – – – – – insureds of the same class, territory and limit (company data) insureds of same territory (company data) insureds within the same state (company or bureau data) countrywide experience (company or bureau data) non-insurance sources, e.g. government databases • There is a hierarchy of sources. We want the best compromise between the effort required to assemble the “industry” data and its similarity to that of the insured. Example: Ad Hoc Methodology for a Unique Risk • Situation: a primary insurer issues a tail policy to an HMO that is reorganizing. – – – – – Insurer is a single state physicians & surgeons malpractice carrier Policy covers occurrences after 1/1/78 reported after 12/31/98 Policy has a $10 million per occurrence limit Insurer is seeking an 80% quota share Expected losses are somewhere between $15,000,000 and $20,000,000 • Three questions: – How many occurrences are left to be reported? – How many will close with a payment? – How much will each payment be? Ad Hoc Methodology for a Unique Risk (cont’d) • Claim count analysis HMO’s triangles are not robust enough to produce claim count development factors (but factors can be applied to the diagonal) – Primary insurer may use own data: count triangle for general practitioners and nonsurgical specialties only, all company, etc. – Reinsurer may use Schedule P claim count triangles (OneSource can produce state specific or countrywide aggregates) • Severity analysis – Risk’s own (closed) claims: not enough to fit, incomplete sample – Severity study of (subset of) insurer data: special study may already exist; can at least compare ultimate average severity – ISO Paretos: too long ($535,000 per CWI claim at $10M limit) – St. Paul lognormals: given by injury type, can be remixed Ad Hoc Methodology for a Unique Risk (cont’d) • Use your favorite method (simulation, Heckman-Meyers, etc.) to produce aggregate loss distribution – www.crimcalc.com is an interesting site • Problem: how do you get a severity distribution for late reporting claims only? – ISO now fits distributions to claims by lag; designing a model to make use of this is literally a research project – ad hoc: use distribution conditioned on claim being greater than $25,000 (this increases the expected value of indemnity from $281,000 to $367,000 per CWI claim) • Problem: how reliable are annual statement claim counts? Example: Somewhere Between Ad Hoc and Systematic • Situation: Insuring Exxon for oil spill cleanups (or an airline for aviation accidents or an auto manufacturer for recalls) • If Exxon doesn’t have enough data, who does? The “oil industry” in total: round up the cleanup cost for known spills and do your best to adjust them to future cost level • Extreme value theory provides a wealth of modeling tools to create a severity distribution from this “industry” data – Environment Canada has a database of 681 spills excluding anything less than 1,000 barrels - see www.etcentre.org) – XL Capital has large loss listings by industry at www.xl.bm – Lexis/Nexis case history databases have settlement data Between Ad Hoc and Systematic Procedures (cont’d) • The industry frequency is based simply on the number of events exceeding the threshold and the Poisson process assumptions. • Exxon’s frequency can be estimated by scaling based on barrels produced or transported, revenues, etc. – U.S. Department of Commerce (www.doc.gov) and Department of Energy (www.doe.gov) are useful links Between Ad Hoc and Systematic Procedures (cont’d) • Extreme Value Theory references – Gary Patrik and Farrokh Guiahi, 1998 Spring Meeting talk: http://www.casact.org/library/patrik.pdf (additional references here) – Alexander McNeil: ASTIN Bulletin paper, fitting software for SPlus/UNIX at http://www.math.ethz.ch/~mcneil/ – Xtremes software: http://www.xtremes.de – search the Euroweb: go to www.ethz.ch and use Eurospider search engine on “extreme value theory” • Recent CAS Announcement – Georgia State University Actuarial Summer School – “Modeling Extremal Events for Insurance and Finance” – http://www.actuary.gsu.edu/profeduc/summerschool.htm Example: A Systematic Procedure • Situation: Desire an experience rating model for physicians groups and clinics • Should produce a modification factor based on – expected cost by class, territory, limit, etc. – developed ultimate cost for insured – appropriate weight or credibility to average them • Determine ultimate losses for insured by applying backwards recursive factors to individual open claims – backwards recursive factors gotten from “industry” data – “industry” data means company data from a larger group of insureds (possibly all company) and bureau data but not annual statement data (depends too heavily on case reserving practices). A Systematic Procedure (cont’d) • Backwards recursive procedure is preferred because it allocates development to open claims only • This procedure can also be used to test SIR credits for same insureds against manual credits. – Develop individual claims and “layer” out; compare indicated loss elimination ratio to LER underlying manual credit • Problems: – Credibility: how to determine for modification procedure? – What is a statistically significant difference between observed and expected SIR credit? – Allocates average development to open claims when really some will CW/OP and others will go to limits – When limits are hit, an iterative procedure must be used to redistribute development in excess of policy limits