ANOVA_between - Creative
advertisement

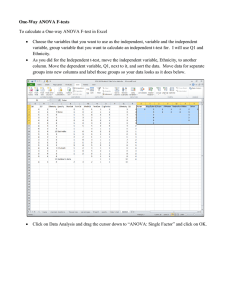
Chong Ho (Alex) Yu Illustrate the purpose, the concept, and the application of ANOVA between-subject design will NOT walk through the procedure of handcalculation; you will use a statistical software package to do your exercises. By the end of the lesson you will understand the meaning of the following concepts: • • • • • • One-way ANOVA vs. Two-way ANOVA Grouping factor and level Between-subject and within-subject Parametric assumptions Variance and F-ratio Confidence intervals and diamond plots Analysis of variance: a statistical procedure to compare the mean difference • Null hypothesis: all means are not significantly different from each other • Alternate: Some means are not equal There must be three or more groups. If there are two groups only, you can use a 2-independent-sample t-test. The independent variable is called the grouping factor. The group is called the level. In this example, there is one factor and three levels (Group 1-3). . There are two grouping factors. Unlike one-way ANOVA, in this design it is allowed to have fewer than three levels (groups) in each factor. In this example, there are two factors: A and B. In each factor, there are two levels: 1 and 2. Thus, it is called a 2X2 ANOVA between-subject design. In this lesson we focus on one-way ANOVA only, but you need to know why on some occasions there are only two groups in ANOVA. Between-subject: The subjects in each level (group) are not the same people (independent). Within-subject: The subjects in each level are the same people (correlated). They are measured at different points of time. In this lesson we will focus on the between-subject ANOVA only If we want to compare the means, why is it called Analysis of Variance, not Analysis of Mean? In the unreal world, the people in the same group have the same response to the treatment: • All people in Group 1 got 10. • All people in Group 2 got 11. • All people in Group 3 got 12. But in the real world, usually there is variability in each group (dispersion). We must take the variance into account while comparing the means. Independence: The responses to the treatment by the subjects in different groups are independent from each other. Normality: The sample data have a normal distribution. the variances of data in different groups are not significantly different from each other. Three different teaching formats (levels) are used in three different classes F = signal /noise(error) Between-group variance is the signal; we want to see whether there is a significant difference (variability) between the groups. Within-group variance is the noise or the error; it hinders us from seeing the between-group difference when the withingroup variances overlap. F = mean square between / mean square within MSB = Sum of square between / DF between MSW = Sum of square within/ DF within Effect size = eta square = SS effect (between) / SS total Mean square between and mean square error F ratio Probability (p value) The p value is smaller than .05 and therefore we reject the null hypothesis. Somewhere there is a difference. But, where is the difference? Which group can significantly outperform which? Many textbooks go into multiple comparison procedures or post hoc contrast at this point, but let’s try something else. • Grand sample mean: represented by a horizontal dot line • Group means: the horizontal line inside each diamond is the group means • Confidence intervals: The diamond is the CI for each group Download the dataset one_way.jmp from the Ch15 folder. Run a one-way ANOVA with this hypothesis: There is no significant difference between difference academic levels in test performance. Use level as the IV and score as the DV Use Test of unequal variances to check whether the group variances are equal. If OK, create a diamond plot. Is there any performance gap?