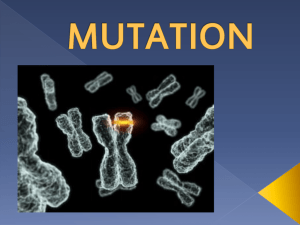
Lecture 4 what Genes are and What they do
advertisement

Lecture 3 what Genes are and What they do Part II Three Chapters 组别 第三讲:准备讨论内容(课堂 讨论时间5分左右) A P252-253: genetics and society C E P268:connection P269-26-70: Social and ethical issues P220:fast forwards H P202: genetics and society M P170-172: fast forwards S P191-192:1st part of chapter 7 D Chapter 6 DNA How the molecule of heredity carries, replicates, and recombines information • How investigators pinpointed DNA as the genetic material • The elegant Watson-Crick model of DNA structure • How DNA structure provides for the storage of genetic information • How DNA structure gives rise to the semiconservative model of molecular replication • How DNA structure promotes the recombination of genetic information • How investigators pinpointed DNA as the genetic material • The elegant Watson-Crick model of DNA structure • How DNA structure provides for the storage of genetic information • How DNA structure gives rise to the semiconservative model of molecular replication • How DNA structure promotes the recombination of genetic information The chemical composition of DNA Fig. 6.2 Chemical characterization localizes DNA in the chromosomes • 1869 – Friedrich Meischer extracted a weakly acidic, phosphorous rich material from nuclei of human white blood cells which he named nuclein Are genes composed of DNA or protein? • DNA – Only four different subunits make up DNA – Chromosomes contain less DNA than protein by weight • Protein – 20 different subunits – greater potential variety of combinations – Chromosomes contain more protein than DNA by weight Bacterial transformation implicates DNA as the substance of genes • 1928 – Frederick Griffith – experiments with smooth (S), virulent strain Streptococcus pneumoniae, and rough (R), nonvirulent strain – Bacterial transformation demonstrates transfer of genetic material • 1944 – Oswald Avery, Colin MacLeod, and MacIyn McCarty – determined that DNA is the transformation material Griffith experiment Fig. 6.3 Griffith experiment Fig. 6.3 b Avery, MacLeod, McCarty experiment Hershey and Chase experiments • 1952 – Alfred Hershey and Martha Chase provide convincing evidence that DNA is genetic material • Waring blender experiment using T2 bacteriophage and bacteria • Radioactive labels 32P for DNA and 35S for protein Hershey and Chase Waring blender experiment Fig. 6.5 a,b Hershey and Chase Waring blender experiment Fig. 6.5 c • How investigators pinpointed DNA as the genetic material • The elegant Watson-Crick model of DNA structure • How DNA structure provides for the storage of genetic information • How DNA structure gives rise to the semiconservative model of molecular replication • How DNA structure promotes the recombination of genetic information The Watson-Crick Model: DNA is a double helix • 1951 – James Watson learns about x-ray diffraction pattern projected by DNA • Knowledge of the chemical structure of nucleotides (deoxyribose sugar, phosphate, and nitrogenous base) • Erwin Chargaff’s experiments demonstrate that ratio of A and T are 1:1, and G and C are 1:1 • 1953 – James Watson and Francis crick propose their double helix model of DNA structure X-ray diffraction patterns produced by DNA fibers – Rosalind Franklin and Maurice Wilkins Fig. 6.6 Chargaff’s ratios Complementary base pairing by formation of hydrogen bonds explain Chargaff’s ratios Fig. 6.8 • DNA is double helix • Strands are antiparallele with a sugar-phosphate backbone on outside and pairs of bases in the middle • Two strands wrap around each other every 30 Angstroms, once every 10 base pairs • Two chains are held together by hydrogen bonds between A-T and G-C base pairs Fig. 6.9 • Stucturally, purines (A and G )pair best with pyrimadines (T and C) • Thus, A pairs with T and G pairs with C, also explaining Chargaff’s ratios Fig. 6.9 d Double helix may assume alternative forms Fig. 6.10 Some DNA molecules are circular instead of linear 1. 2. 3. 4. Some viruses carry single-stranded DNA Prokaryotes Mitochondria Chloroplasts Viruses 1. bacteriophages Some viruses carry RNA 1. e.g., AIDS • How investigators pinpointed DNA as the genetic material • The elegant Watson-Crick model of DNA structure • How DNA structure provides for the storage of genetic information • How DNA structure gives rise to the semiconservative model of molecular replication • How DNA structure promotes the recombination of genetic information Four requirements for DNA to be genetic material • Must carry information – Cracking the genetic code • Must replicate – DNA replication • Must allow for information to change – Mutation • Must govern the expression of the phenotype – Gene function Some viruses use RNA as the repository of genetic information Fig. 6.13 • How investigators pinpointed DNA as the genetic material • The elegant Watson-Crick model of DNA structure • How DNA structure provides for the storage of genetic information • How DNA structure gives rise to the semiconservative model of molecular replication • How DNA structure promotes the recombination of genetic information DNA replication: Copying genetic information for transmission to the next generation • Complementary base pairing produces semiconservative replication – Double helix unwinds – Each strand acts as template – Complementary base pairing ensures that T signals addition of A on new strand, and G signals addition of C – Two daughter helices produced after replication Fig. 6.14 Fig. 6.15 Meselson-Stahl experiments confirm semiconservative replication Fig. 6.16 The mechanism of DNA replication • Arthur Kornbuerg, a nobel prize winner and other biochemists deduced steps of replication – Initiation • Proteins bind to DNA and open up double helix • Prepare DNA for complementary base pairing – Elongation • Proteins connect the correct sequences of nucleotides into a continuous new strand of DNA Enzymes involved in replication • Pol III – produces new stands of complementary DNA • Pol I – fills in gaps between newly synthesized Okazaki segments • DNA helicase – unwinds double helix • Single-stranded binding proteins – keep helix open • Primase – creates RNA primers to initiate synthesis • Ligase – welds together Okazaki fragments Replication is bidirectional • Replication forks move in opposite directions • In linear chromosomes, telomeres ensure the maintenance and accurate replication of chromosome ends • In circular chromosomes, such as E. coli, there is only one origin of replication. • In circular chromosomes, unwinding and replication causes supercoiling, which may impede replication • Topoisomerase – enzyme that relaxes supercoils by nicking strands The bidirectional replication of a circular chromosome Fig. 6.18 Fig. 6.18 Cells must ensure accuracy of genetic information • Redunancy – Basis for repair of errors that occur during replication or during storage • Enzymes repair chemical damage to DNA • Errors during replication are rare • How investigators pinpointed DNA as the genetic material • The elegant Watson-Crick model of DNA structure • How DNA structure provides for the storage of genetic information • How DNA structure gives rise to the semiconservative model of molecular replication • How DNA structure promotes the recombination of genetic information Recombination reshuffles the information content of DNA • During recombination, DNA molecules break and rejoin • Meselson and Weigle - Experimental evidence from viral DNA and radioactive isotopes • Coinfected E. coli with light and heavy strains of virus after allowing time for recombination • Separated on a CsCl density gradient Meselson and Weigle demonstrate recombination occurs by breakage and rejoining of DNA Fig. 6.19 Heteroduplexes mark the spot of recombination • Products of recombination are always in exact register; not a single base pair is lost or gained • Two strands do not break and rejoin at the same location; often they are hundreds of base pairs apart • Region between break points is called heteroduplex Heteroduplex region Fig .6.20 In heterozygotes, mismatches within heteroduplexes must be repaired • Gene conversion – a deviation from expected 2:2 segregation of alleles due to mismatch repair. • Studied most extensively in yeast where tetrad analysis makes possible to follow products of meiosis Gene conversion in yeast Mismatch leads to 3:1 ratio of a:A. Ratio of B:b and C:c which lie outside of heteroduplex are both 2:2, as expected. Fig. 6.20 c Double stranded break model of meiotic recombination • Homologs physically break, exchange parts, and rejoin. • Breakage and repair create reciprocal products of recombination • Recombination events can occur anywhere along the DNA molecule • Precision in the exchange prevents mutations from occurring during the process • Gene conversion can give rise to unequal yield of two different alleles. 50% of gene conversions are associated with crossing over of adjacent chromosomal regions, and 50% of gene conversions are not associate with crossing over Double stranded break formation spoI protein breaks one chromatid on both strands Fig. 6.22 step 1 Resection 5’ end on each side of break are degraded to produce two 3’ single stranded tails Fig. 6.22 step 2 First strand invasion RecA binds 3’ tail and double helix allowing invasion and migration Fig. 6.22 step 3 Formation of Holliday junctions New DNA synthesis forms two X structures called Holliday junciions Fig. 6.22 step 4 Branch migration Both invading strands zip up and migrate while newly created heteroduplex molecules rewind behind. Fig. 6.22 step 5 The Holliday intermediate Interlocked nonsister chromatids disenguage. Two resolutions are possible Fig. 6.22 step 6 Alternative resolutions Endonuclease cuts Holliday intermediate Probability of crossover occurring Resolution of Holliday junction in same plan results in noncrossover chromatids. Resolution in different planes results in crossover. Fig. 6.22 step 8 Chapter 7 Anatomy and Function of a Gene Dissection through mutation 57 • What mutations are – How often mutations occur – What events cause mutations – How mutations affect survival and evolution • Mutations and gene structure – Experiments using mutations demonstrate a gene is a discrete region of DNA • Mutations and gene function – Genes encode proteins by directing assembly of amino acids • How do genotypes correlate with phenotypes? – Phenotype depends on structure and amount of protein – Mutations alter genes instructions for producing proteins structure and function, and consequently phenotype 58 • What mutations are – How often mutations occur – What events cause mutations – How mutations affect survival and evolution • Mutations and gene structure – Experiments using mutations demonstrate a gene is a discrete region of DNA • Mutations and gene function – Genes encode proteins by directing assembly of amino acids • How do genotypes correlate with phenotypes? – Phenotype depends on structure and amount of protein – Mutations alter genes instructions for producing proteins structure and function, and consequently phenotype 59 Mutations: Primary tools of genetic analysis • Mutations are heritable changes in base sequences that modify the information content of DNA – Forward mutation – changes wild-type to different allele – Reverse mutation – causes novel mutation to revert back to wild-type (reversion) 60 Classification of mutations by affect on DNA molecule • Substitution – base is replaced by one of the other three bases • Deletion – block of one or more DNA pairs is lost • Insertion – block of one or more DNA pairs is added • Inversion 180 rotation of piece of DNA • Reciprocal translocation – parts of nonhomologous chromosomes change places • Chromosomal rearrangements – affect many genes at one time 61 62 Spontaneous mutations influencing phenotype occur at a very low rate Mutation rates from wild-type to recessive alleles for five coat color genes63in mice Fig. 7.3 b General observations of mutation rates • Mutations affecting phenotype occur very rarely • Different genes mutate at different rates • Rate of forward mutation is almost always higher than rate of reverse mutation 64 Are mutations spontaneous or induced? • Most mutations are spontaneous. • Luria and Delbruck experiments - a simple way to tell is mutations are spontaneous or if they are induced by a mutagenic agent 65 Fig. 7.4 66 Chemical and Physical agents cause mutations • Hydrolysis of a purine base, A or G occurs 1000 times an hour in every cell 67 Deamination removes – NH2 group. Can change C to U, inducing a substitution to and A-T base pair after replication • X rays break the DNA backbone UV light produces thymine dimers Fig. 7.6 c, d 68 Oxydation from free radicals formed by irradiation damages individual bases Fig. 7.6 e 69 Repair enzymes fix errors created by mutation Excision repair enzymes release damaged regions of DNA. Repair is then completed by DNA polymerase and DNA ligase 70 Fig. 7.7a Mistakes during replication alter genetic information • Errors during replication are exceedingly rare, less than once in 109 base pairs • Proofreading enzymes correct errors made during replication – DNA polymerase has 3’ – 5’ exonuclease activity which recognizes mismatched bases and excises it – In bacteria, methyl-directed mismatch repair finds errors on newly synthesized strands and corrects them 71 DNA polymerase proofreading Fig. 7.8 72 Methyldirected mismatch repair Fig. 7.9 73 Unequal crossing over creates one homologous chromosome with a duplication and the other with a deletion 7.10 a 74 Transposable elements move around the genome and are not susceptible to excision or mismatch repair Fig. 7.10 e 75 Trinucleotide instability causes mutations • FMR-1 genes in unaffected people have fewer than 50 CGG repeats. • Unstable premutation alleles have between 50 and 200 repeats. • Disease causing alleles have > 200 CGG repeats. 76 Fig. B(1) Genetics and Society Trinucleotide repeat in people with fragile X syndrom Fig. A, B(2) Genetics and Society 77 Mutagens induce mutations • Mutagens can be used to increase mutation rates • H. J. Muller – first discovered that X rays increase mutation rate in fruitflies – Exposed male Drosophila to large doses of X rays – Mated males to females with balancer X chromosome (dominant Bar eyed mutation and multiple inversions) – Could assay more than 1000 genes at once on the X chromosome 78 Muller’s experiment Fig. 7.11 79 Mutagens increase mutation rate using different mechanisms Fig. 7.12a 80 81 82 Fig. 7.12 b Fig. 7.12 c 83 Consequences of mutations • Germ line mutations – passed on to next generation and affect the evolution of species • Somatic mutations – affect the survival of an individual – Cell cycle mutations may lead to cancer • Because of potential harmful affects of mutagens to individuals, tests have been developed to identify carcinogens 84 • What mutations are – How often mutations occur – What events cause mutations – How mutations affect survival and evolution • Mutations and gene structure – Experiments using mutations demonstrate a gene is a discrete region of DNA • Mutations and gene function – Genes encode proteins by directing assembly of amino acids • How do genotypes correlate with phenotypes? – Phenotype depends on structure and amount of protein – Mutations alter genes instructions for producing proteins structure and function, and consequently phenotype 85 What mutations tell us about gene structure • Complementation testing tells us whether two mutations are in the same or different genes • Benzer’s experiments demonstrate that a gene is a linear sequence of nucleotide pairs that mutate independently and recombine with each other • Some regions of chromosomes mutate at a higher rate than others – hot spots 86 Complementation testing Fig. 7.15 a 87 Fig. 7.15 b,c Five complementation groups (different genes) for eye color. Recombination mapping demonstrates distance between genes and alleles. 88 A gene is a linear sequence of nucleotide pairs • Seymore Benzer mid 1950s – 1960s – If a gene is a linear set of nucleotides, recombination between homologous chromosomes carrying different mutations within the same gene should generate wildtype – T4 phage as an experimental system • Can examine a large number of progeny to detect rare mutation events • Could allow only recombinant phage to proliferate while parental phages died 89 Benzer’s experimental procedure • Generated 1612 spontaneous point mutations and some deletions • Mapped location of deletions relative to one another using recombination • Found approximate location of individual point mutations by deletion mapping • Then performed recombination tests between all point mutations known to lie in the same small region of the chromosome • Result – fine structure map of the rII gene locus 90 How recombination within a gene could generate wild-type Fig. 7.16 91 • What mutations are – How often mutations occur – What events cause mutations – How mutations affect survival and evolution • Mutations and gene structure – Experiments using mutations demonstrate a gene is a discrete region of DNA • Mutations and gene function – Genes encode proteins by directing assembly of amino acids • How do genotypes correlate with phenotypes? – Phenotype depends on structure and amount of protein – Mutations alter genes instructions for producing proteins structure and function, and consequently phenotype 92 What mutations tell us about gene function • One gene, one enzyme hypothesis: a gene contains the information for producing a specific enzyme – Beadle and Tatum use auxotrophic and prototrophic strains of Neurospora to test hypothesis • Genes specify the identity and order of amino acids in a polypeptide chain • The sequence of amino acids in a protein determines its three-dimensional shape and function • Some proteins contain more than one polypeptide coded for by different genes 93 Beadle and Tatum – One gene, one enzyme • 1940s – isolated mutagen induced mutants that disrupted synthesis of arginine, an amino acid required for Neurospora growth – Auxotroph – needs supplement to grow on minimal media – Prototroph – wild-type that needs no supplement; can synthesize all required growth factors • Recombination analysis located mutations in four distinct regions of genome • Complementation tests showed each of four regions correlated with different complementation group (each was a different gene) 94 Fig. 7.20 a 95 Fig. 7.20 b 96 Interpretation of Beadle and Tatum experiments • Each gene controls the synthesis of an enzyme involved in catalyzing the conversion of an intermediate into arginine 97 Genes specify the identity and order of amino acids in a polypeptide chain • Proteins are linear polymers of amino acids linked by peptide bonds – 20 different amino acids are building blocks of proteins – NH2-CHR-COOH – carboxylic acid is acidic, amino group is basic – R is the side chain that distinguishes each amino acid Fig. 7.21 a 98 R is the side group that distinguishes each amino acid Fig. 7.21 b 99 100 101 Fig. 7.21 b N terminus of a protein contains a free amino group C terminus of protein contains a free carboxylic acid group Fig. 7.21 c 102 Genes specify the amino acid sequence of a polypeptide – example, sickle cell anemia Mutant b chain of hemoglobin form aggregates that cause red blood cells to sickle 103 Fig. 7.22 a Sequence of amino acids determine a proteins primary, secondary, and tertiary structure 104 Fig. 7.23 Some proteins are multimeric, containing subunits composed of more than one polypeptide Fig. 7.24 105 How do genotypes and phenotypes correlate? • Alteration of amino acid composition of a protein • Alteration of the amount of normal protein produced • Changes in different amino acids at different positions have different effects – Proteins have active sites and sites involved in shape or structure 106 Dominance relations between alleles depend on the relation between protein function and phenotype • Alleles that produce nonfunctional proteins are usually recessive – Null mutations – prevent synthesis of protein or promote synthesis of protein incapable of carrying out any function – Hypomorphic mutations – produce much less of a protein or a protein with weak but detectable function; usually detectable only in homozygotes • Incomplete dominance – phenotype varies in proportion to amount of protein – Hypermorphic mutations – produces more protein or same amount of a more effective protein – Dominant negative – produces a subunit of a protein that blocks the activity of other subunits – Neomorphic mutations – generate a novel phenotype; example is ectopic expression where protein is produced outside of its normal place or time 107 Gene Expression The Flow of Genetic Information from DNA via RNA to Protein • The genetic code – How triplets of the four nucleotides unambiguously specify 20 amino acids, making it possible to translate information from a nucleotide chain to a sequence of amino acids • Transcription – How RNA polymerase, guided by base pairing, synthesizes a single-stranded mRNA copy of a gene’s DNA template • Translation – How base pairing between mRNA and tRNAs directs the assembly of a polypeptide on the ribosome • Significant differences in gene expression between prokaryotes and eukaryotes • How mutations affect gene information and expression • The genetic code – How triplets of the four nucleotides unambiguously specify 20 amino acids, making it possible to translate information from a nucleotide chain to a sequence of amino acids • Transcription – How RNA polymerase, guided by base pairing, synthesizes a single-stranded mRNA copy of a gene’s DNA template • Translation – How base pairing between mRNA and tRNAs directs the assembly of a polypeptide on the ribosome • Significant differences in gene expression between prokaryotes and eukaryotes • How mutations affect gene information and expression The triplet codon represents each amino acid • 20 amino acids encoded for by 4 nucleotides – By deduction: • 1 nucleotide/amino acid = 41 = 4 triplet combinations • 2 nucleotides/amino acid = 42 = triplet combinations • 3 nucleotides/amino acid = 43 = triplet combinations – Must be at least triplet combinations that code for amino acids The Genetic Code: 61 triplet codons represent 20 amino acids; 3 triplet codons signify stop Fig. 8.3 A gene’s nucleotide sequence is colinear the amino acid sequence of the encoded polypeptide • Charles Yanofsky – E. coli genes for a subunit of tyrptophan synthetase compared mutations within a gene to particular amino acid substitutions • Trp- mutants in trpA • Fine structure recombination map • Determined amino acid sequences of mutants Fig. 8.4 • A codon is composed of more than one nucleotide – Different point mutations may affect same amino acid – Codon contains more than one nucleotide • Each nucleotide is part of only a single codon – Each point mutation altered only one amino acid A codon is composed of three nucleotides and the starting point of each gene establishes a reading frame studies of frameshift mutations in bacteriophage T4 rIIB gene Fig. 8.5 • Most amino acids are specified by more than one codon • Phenotypic effect of frameshifts depends on if reading frame is restored Fig. 8.6 Cracking the code: biochemical manipulations revealed which codons represent which amino acids • The discovery of messenger RNAs, molecules for transporting genetic information – Protein synthesis takes place in cytoplasm deduced from radioactive tagging of amino acids • RNA, an intermediate molecule made in nucleus and transports DNA information to cytoplasm Synthetic mRNAs and in vitro translation determines which codons designate which amino acids • 1961 – Marshall Nirenberg and Heinrich Mathaei created mRNAs and translated to polypeptides in vitro • Polymononucleotides • Polydinucleotides • Polytrinucleotides • Polytetranucleotides • Read amino acid sequence and deduced codons Fig. 8.7 • Ambiguities resolved by Nirenberg and Philip Leder using trinucleotide mRNAs of known sequence to tRNAs charged with radioactive amino acid with ribosomes Fig. 8.8 • 5’ to 3’ direction of mRNA corresponds to N-terminal-toC-terminal direction of polypeptide – One strand of DNA is a template – The other is an RNA-like strand • Nonsense codons cause termination of a polypeptide chain – UAA (ocher), UAG (amber), and UGA (opal) Fig. 8.9 Summary • Codon consist of a triplet codon each of which specifies an amino acid – Code shows a 5’ to 3’ direction • Codons are nonoverlapping • Code includes three stop codons, UAA, UAG, and UGA that terminate translation • Code is degenerate • Fixed starting point establishes a reading frame – UAG in an initiation codon which specifies reading frame • 5’- 3’ direction of mRNA corresponds with N-terminus to Cterminus of polypeptide • Mutaiton modify message encoded in sequence – Frameshift mutaitons change reading frame – Missense mutations change codon of amino acid to another amino acid – Nonsense mutations change a codon for an amino acid to a stop codon Do living cells construct polypeptides according to same rules as in vitro experiments? Fig. 8.10 a • Studies of how mutations affect amino-acid composition of polypeptides encoded by a gene • Missense mutations induced by mutagens should be single nucleotide substitutions and conform to the code • Proflavin treatment generates trp- mutants • Further treatment generates trp+ revertants – Single base insertion (trp-) and a deletion causes reversion (trp+) Fig. 8.10 b Genetic code is almost universal but not quite • All living organisms use same basic genetic code – Translational systems can use mRNA from another organism to generate protein – Comparisons of DNA and protein sequence reveal perfect correspondence between codons and amino acids among all organisms • The genetic code – How triplets of the four nucleotides unambiguously specify 20 amino acids, making it possible to translate information from a nucleotide chain to a sequence of amino acids • Transcription – How RNA polymerase, guided by base pairing, synthesizes a single-stranded mRNA copy of a gene’s DNA template • Translation – How base pairing between mRNA and tRNAs directs the assembly of a polypeptide on the ribosome • Significant differences in gene expression between prokaryotes and eukaryotes • How mutations affect gene information and expression Transcription • RNA polymerase catalyzes transcription • Promoters signal RNA polymerase where to begin transcription • RNA polymerase adds nucleotides in 5’ to 3’ direction • Terminator sequences tell RNA when to stop transcription Initiation of transcription Fig. 8.11 a Elongation Fig. 8.11 b Termination Fig. 8.11 c Information flow Fig. 8.11 d Promoters of 10 different bacterial genes Fig. 8.12 In eukaryotes, RNA is processed after transcription • A 5’ methylated cap and a 3’ Poly-A tail are added • Structure of the methylated cap How Poly-A tail is added to 3’ end of mRNA Fig. 8.14 RNA splicing removes introns • Exons – sequences found in a gene’s DNA and mature mRNA (expressed regions) • Introns – sequences found in DNA but not in mRNA (intervening regions) • Some eukaryotic genes have many introns Dystrophin gene underlying Duchenne muscular dystrophy (DMD) is an extreme example of introns Fig. 8.15 How RNA processing splices out introns and adjoins adjacent exons Fig. 8.16 • Splicing is catalyzed by spliceosomes – Ribozymes – RNA molecules that act as enzymes – Ensures that all splicing reactions take place in concert Fig. 8.17 • Alternative splicing – Different mRNAs can be produced by same transcript – Rare transplicing events combine exons from different genes Fig. 8.18 • The genetic code – How triplets of the four nucleotides unambiguously specify 20 amino acids, making it possible to translate information from a nucleotide chain to a sequence of amino acids • Transcription – How RNA polymerase, guided by base pairing, synthesizes a single-stranded mRNA copy of a gene’s DNA template • Translation – How base pairing between mRNA and tRNAs directs the assembly of a polypeptide on the ribosome • Significant differences in gene expression between prokaryotes and eukaryotes • How mutations affect gene information and expression Translation • Transfer RNAs (tRNAs) mediate translation of mRNA codons to amino acids – tRNAs carry anticodon on one end • Three nucleotides complementary to an mRNA codon – Structure of tRNA • Primary – nucleotide sequence • Secondary – short complementary sequences pair and make clover leaf shape • Teriary – folding into three dimensional space shape like an L – Base pairing between an mRNA codon and a tRNA anticodon directs amino acid incorporation into a growing polypeptide – Charged tRNA is covalently coupled to its amino acid Many tRNAs contain modified bases Fig. 8.19 a Secondary and tertiary structure Fig. 8.19 b Aminoacyl-tRNA syntetase catalyzes attachment of tRNAs to corresponding amino acid Fig. 8.20 Base pairing between mRNA codon and tRNA anticodon determines where incorporation of amino acid occurs Fig. 8.21 Wobble: Some tRNAs recognize more than one codon for amino acids they carry Fig. 8.22 Rhibosomes are site of polypeptide synthesis • Ribosomes are complex structures composed of RNA and protein Fig. 8.23 Mechanism of translation • Initiation sets stage for polypeptide synthesis – AUG start codon at 5’ end of mRNA – Formalmethionine (fMet) on initiation tRNA • First amino acid incorporated in bacteria • Elongation during which amino acids are added to growing polypeptide – Ribosomes move in 5’-3’ direction revealing codons – Addition of amino acids to C terminus – 2-15 amino acids per second • Termination which halts polypeptide synthesis – Nonsense codon recognized at 3’ end of reading frame – Release factor proteins and halt polypeptide synthesis Initiation of translation Fig. 8.24 a Elongation Fig. 8.24 b Termination of translation Fig. 8.24 c • Posttranslatio nal processing can modify polypeptide structure Fig. 8.25 • The genetic code – How triplets of the four nucleotides unambiguously specify 20 amino acids, making it possible to translate information from a nucleotide chain to a sequence of amino acids • Transcription – How RNA polymerase, guided by base pairing, synthesizes a single-stranded mRNA copy of a gene’s DNA template • Translation – How base pairing between mRNA and tRNAs directs the assembly of a polypeptide on the ribosome • Significant differences in gene expression between prokaryotes and eukaryotes • How mutations affect gene information and expression Significant differences in gene expression between prokaryotes and eukaryotes • Eukaryotes, nuclear membrane prevents coupling of transcription and translation • Prokaryotic messages are polycistronic – Contain information for multiple genes • Eukaryotes, small ribosomal subunit binds to 5’ methylated cap and migrates to AUG start codon – 5’ untranslated leader sequence – between 5’ cap and AUG start – Only a single polypeptide produced from each gene • Initiating tRNA in prokaryotes is fMet • Initiating tRNA in eukaryotes Met is unmodified A computerized analysis of gene expression in C. elegans: A comprehensive example • Computer programs search for possible exons by looking for strings of codons uninterrupted by nonsense codons • Look for splice donor and acceptor sites to identify introns • C. elegans genome contains roughly 19,000 genes – 15% encode worm’s genes or proteins Landmarks in a callogen gene of C. elegans and comparison of DNA and mRNA sequences Fig. 8.26 • The genetic code – How triplets of the four nucleotides unambiguously specify 20 amino acids, making it possible to translate information from a nucleotide chain to a sequence of amino acids • Transcription – How RNA polymerase, guided by base pairing, synthesizes a single-stranded mRNA copy of a gene’s DNA template • Translation – How base pairing between mRNA and tRNAs directs the assembly of a polypeptide on the ribosome • Significant differences in gene expression between prokaryotes and eukaryotes • How mutations affect gene information and expression • Mutations in a gene’s coding sequence can alter the gene product – Silent mutations do not alter amino acid specified – Missense mutations replace one amino acid with another – Nonsense mutations change an amino-acid-specifying codon to a stop codon – Frameshift mutations result from the insertion or deletion of nucleotides within the coding sequence • Mutations outside of the coding sequence can also alter gene expression – – – – Promoter sequences Termination signals Splice-acceptor and splice-donor sites Ribosome binding sites Fig. 8.27 c • Mutations in genes encoding the molecules that implement expression may affect transcription,l mRNA splicing, or translation – Usually lethal – Mutations in tRNA genes can suppress mutations in protein-coding genes • Nonsense supressor tRNAs • Nonsense suppression – (a) Nonsense mutation that causes incomplete nonfunctional polypeptide – (b) Nonsensesuppressing mutation causes addition of amino acid at stop codon allowing production of full length polypeptide Fig. 8.28