Windows Scalability:
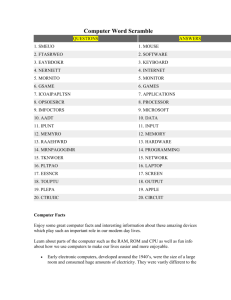
Technology
Terminology,
Trends
Jim Gray
Distinguished Engineer
Research
Microsoft Corporation
Outline
Progress: an overview
Scale-Up technology trends
Cpus, Memory, Disks, Networking
Scale-Out terminology:
clones, racks/packs, farms, geoplex
Progress
Other speakers in this track will tell you
Windows is #1
How they did it,
and how you too can do it.
Stepping back
Huge progress in last 5 years.
10x to 100x improvements
Now Windows has competitive high-end hardware
32xSMP, 64bit addressing, 30GBps bus bandwidth, …
Software has evolved (32x smp, 256GB ram, 10 TB DB)
In next 5 years,
expect 10x to 100x improvements
The Recurring Theme
Windows improved 50% to 500%,
Self Tuning
Tradeoffs
Buy memory locality & bandwidth with cpu (compress, pack, cluster)
Trade memory for IO (caches)
Speedups
Q: WHY?
A: Measure, Analyze, Improve
Introduce fast path for common case
Repack for smaller I-Cache footprint
Scalability
remove / improve locks
Cool hotspots cache / disk
Examine spins and timeouts
Affinity/Locality to improve caching
Measure
Analyze
Improve
Scaleable Systems
Scale UP
Scale UP: grow by
adding components
to a single system.
Scale Out: grow by
adding more systems.
Scale OUT
Outline
Progress: an overview
ScaleUp Nodes: technology trends
Cpus, Memory, Disks, Networking
ScaleOut terminology:
clones, racks/packs, farms, geoplex
What’s REALLY New –
Windows Scale Up
64 bit & TB size main memory
SMP on chip: everything’s smp
32… 256 SMP: locality/affinity matters
TB size disks
High-speed LANs
iSCSI and NAS competition
64 bit – Why bother?
1966 Moore’s law:
4x more RAM every 3 years.
1 bit of addressing every 18 months
36 years later: 236/3 = 24 more bits
Not exactly right, but…
32 bits not enough for servers
32 bits gives no headroom for clients
So, time is running out ( has run out )
Good news:
Itanium™ and Hammer™ are maturing
And so is the base software (OS, drivers, DB, Web,...)
Windows & SQL @ 256GB today!
Who needs 64-bit addressing?
You! Need 64-bit addressing!
640K ought to be enough for anybody.
Bill Gates, 1981
But that was 21 years ago
== 221/3 = 14 bits ago.
20 bits + 14 bits = 34 bits so..
16GB ought to be enough for anybody
Jim Gray, 2002
34 bits > 31 bits so…
34 bits == 64 bits
YOU need 64 bit addressing!
64 bit – why bother?
Memory intensive calculations:
You can trade memory for IO and processing
Example: Data Analysis & Clustering a JHU
in memory CPU time is
100000.0
~NlogN , N ~ 100M
Disk M chunks
10000.0
→ time ~ M2
1000.0
must run many times
100.0
Now running on
day
HP Itanium
10.0
Windows.Net Server 2003
SQL Server
1.0
decade
1
4
yea
r
32
256
CPU time (hrs)
Memory in GB
month
week
0
10
20
30
40
50
60
70
80
90
No of galaxies in Millions
Graph courtesy of Alex Szalay & Adrian Pope of Johns Hopkins University
100
Amdahl’s balanced System Laws
1 mips needs 4 MB ram and needs 20 IO/s
At 1 billion instructions per second
need 4 GB/cpu
need 50 disks/cpu!
4 GB
RAM
1 bips
cpu
64 cpus … 3,000 disks
50 disks
10,000 IOps
7.5 TB
The 5 Minute Rule – Trade
RAM for Disk Arms
If data re-referenced every 5 minutes
It is cheaper to cache it in ram
than to get it from disk
A disk access/second ~ 50$ or
~ 50MB for
1 second or
~ 50KB for 1,000 seconds.
Each app has a memory “knee”
Up to the knee,
more memory helps a lot.
64 bit Reduces IO, saves disks
Large memory reduces IO
64-bit simplifies code
Processors can be faster (wider word)
Ram is cheap (4 GB ~ 1k$ to 20k$)
Can trade ram for disk IO
Three TPC Benchmarks:
GBs help a LOT!
Better response time.
even if cpu clock is slower
Example
Transactions Per
Second
100,000
75,000
tpcC
4x1Ghz Itanium2 vs
4x1.6Ghz IA32
40 extra GB
→ 60% extra throughput
50,000
25,000
4x1.6Ghz 4x1.6Ghz
IA32
IA32
8GB
32GB
4x1 Ghz
IA64
48GB
4x1.6Ghz IA32+8GB 4x1.6Ghz IA32+32GB
4x1Ghz Itanium2 +
48GB
0
AMD Hammer™ Coming Soon
AMD Hammer™ is 64bit capable
2003: millions of Hammer™ CPUs will ship
2004: most AMD CPUs will be 64bit
4GB ram is less than 1,000$ today
less than 500$ in 2004
Desktops (Hammer™)
and servers (Opteron™).
You do the math,…
Who will demand 64bit capable software?
A 1TB Main Memory
Amdahl’s law: 1mips/MB , now 1:5
so ~20 x 10 Ghz cpus need 1TB ram
1TB ram
~ 250k$ … 2m$ today
~ 25k$ … 200k$ in 5 years
128 million pages
Takes a LONG time to fill
Takes a LONG time to refill
Needs new algorithms
Needs parallel processing
Which leads us to…
The memory hierarchy
smp
numa
Hyper-Threading: SMP on chip
If cpu is always waiting for memory
Predict memory requests and prefetch
If cpu still always waiting for memory
Multi-program it (multiple hardware threads per cpu)
Hyper Threading: Everything is SMP
2 now more later
Also multiple cpus/chip
If your program is single threaded
done
You waste ½ the cpu and memory bandwidth
Eventually waste 80%
App builders need to plan for threads.
The Memory Hierarchy
Locality REALLY matters
CPU 2 G hz, RAM at 5 Mhz
RAM is no longer random access.
Organizing the code gives 3x (or more)
Organizing the data gives 3x (or more)
Level
Registers
L1
L2
L3
Near RAM
Far RAM
latency (clocks)
size
1
1 KB
2
32 KB
10
256 KB
30
4 MB
100
16 GB
300
64 GB
Remote RAM
Remote RAM
Other Cpus
RAM
Other Cpus
Other Cpus
Remote cache
Other Cpus
The Bus
L2 cache
Off chip
L1 cache
Dcache
Icache
registers
Arithmatic Logical Unit
Scaleup Systems
Non-Uniform Memory Architecture (NUMA)
Coherent but… remote memory is even slower
CPU
I/O
Mem
CPU
I/O
Mem
CPU
I/O
CPU
CPU
Mem Mem Mem
CPU
CPU
CPU
Service
Processor
Mem Mem Mem
Config DB
CPU
Service
Processor
CPU
CPU
Chipset
CPU
CPU
CPU
Slow local main memory
Slower remote main memory
Scaleup by adding cells
Chipset
Mem Mem Mem
Mem
Partition
manager
Chipset
Mem
I/O
All cells see a common memory
CPU
CPU
Chipset
Mem Mem Mem
System interconnect
Crossbar/Switch
Planning for 64 cpu, 1TB ram
Interconnect,
Service Processor,
Partition management
are vendor specific
Several vendors doing this
Itanium and Hammer
Changed Ratios Matter
If everything changes by 2x,
Then nothing changes.
So, it is the different rates that matter.
Improving FAST
CPU speed
Memory & disk size
Network Bandwidth
Slowly changing
Speed of light
People costs
Memory bandwidth
WAN prices
What’s REALLY New
64 bit & TB size main memory
SMP on chip: everything’s smp
32… 256 SMP: locality/affinity matters
We are here
TB size disks
High-speed LANs
iSCSI and NAS competition
Disks are becoming tapes
Capacity:
150 IO/s 40 MBps
Bandwidth:
150 GB now,
300 GB this year,
1 TB by 2007
150 GB
40 MBps now
150 MBps by 2007
1 TB
200 IO/s 150 MBps
Read time
2 hours sequential, 2 days random now
4 hours sequential, 12 days random by 2007
Disks are becoming tapes
Consequences
Use most disk capacity for archiving
Copy on Write (COW) file system
in Windows.NET Server 2003
RAID10 saves arms, costs space (OK!).
Backup to disk
Pretend it is a 100GB disk + 1 TB disk
Keep hot 10% of data on fastest part of disk.
Keep cold 90% on colder part of disk
Organize computations to read/write
disks sequentially in large blocks.
Networking:
Great hardware & Software
WANs @ 5GBps (1 = 40 Gbps)
GbpsEthernet common (~100 MBps)
Offload gives ~2 hz/Byte
Will improve with RDMA & zero-copy
10 Gbps mainstream by 2004
Faster I/O
1 GB/s today (measured)
10 GB/s under development
SATA (serial ATA) 150MBps/device
Wiring is going serial
and getting FAST!
Gbps Ethernet and SATA
built into chips
Raid Controllers: inexpensive and fast.
1U storage bricks @ 2-10 TB
SAN or NAS
(iSCSI or CIFS/DAFS)
Enet
100MBps/link
NAS – SAN Horse Race
Storage Hardware
1k$/TB/y
Storage Management 10k$...300k$/TB/y
So as with Server Consolidation
Storage Consolidation
Two styles:
NAS (Network Attached Storage) File Server
SAN (System Area Network)
Disk Server
Windows supports both models.
We believe NAS is more manageable.
Windows is a great NAS server
What’s REALLY New –
Windows Scale Up
64 bit & TB size main memory
SMP on chip: everything’s smp
32… 256 SMP: locality/affinity matters
TB size disks
High-speed LANs
iSCSI and NAS competition
Take Aways / Call to Action
Threads: Plan for SMPs (threads)
32 cpu and (far) beyond….
Locality: Use affinity, cache, disk, …
64bit: Plan for VERY large memory
Sequential IO and Disk-as-tape
Plan for huge disks (with spare space)
Low-overhead networking:
LAN Converging on Ethernet, SATA, …?
Windows.Net Server 2003 and successors
will manage petabyte stores.
Outline
Progress: an overview
ScaleUp Nodes: technology trends
Cpus, Memory, Disks, Networking
ScaleOut terminology:
clones, racks/packs, farms, geoplex
Scaleable Systems
Scale UP
ScaleUP: grow by
adding components
to a single system.
ScaleOut: grow by
adding more systems.
Scale OUT
ScaleUP
and Scale OUT
Everyone does both. 1M$/slice
IBM S390?
Choice’s
Size of a brick
Clones or partitions
Size of a pack
Who’s software?
100 K$/slice
Sun E 10,000?
Wintel 8x++
10 K$/slice
Wintel 4x
scaleup and scaleout 1 K$/slice
both have a large
Wintel 1x
software component
Clones: Availability+Scalability
Some applications are
Read-mostly
Low consistency requirements
Modest storage requirement (less than 1TB)
Examples:
HTML web servers (IP sprayer/sieve + replication)
LDAP servers (replication via gossip)
Replicate app at all nodes (clones)
Load Balance:
Spray& Sieve: requests across nodes.
Route: requests across nodes.
Grow: adding clones
Fault tolerance: stop sending to that clone.
Two Clone Geometries
Shared-Nothing: exact replicas
Shared-Disk (state stored in server)
Shared Nothing Clones
Shared Disk Clones
If clones have any state: make it disposable.
Manage clones by reboot, failing that replace.
One person can manage thousands of clones.
Clone Requirements
Automatic replication (if they have any state)
Automatic request routing
Spray or sieve
Management:
Applications (and system software)
Data
Who is up?
Update management & propagation
Application monitoring.
Clones are very easy to manage:
Rule of thumb: 100’s of clones per admin.
Partitions for Scalability
Clones are not appropriate for some apps.
State-full apps do not replicate well
high update rates do not replicate well
Examples
Email
Databases
Read/write file server…
Cache managers
chat
Partition state among servers
Partitioning:
must be transparent to client.
split & merge partitions online
Packs for Availability
Each partition may fail (independent of others)
Partitions migrate to new node via fail-over
Pack: the nodes supporting a partition
Fail-over in seconds
VMS Cluster, Tandem, SP2 HACMP,..
IBM Sysplex™
WinNT MSCS (wolfpack)
Partitions typically grow in packs.
ActiveActive: all nodes provide service
ActivePassive: hot standby is idle
Cluster-In-A-Box now commodity
Partitions and Packs
Partitions
Scalability
Packed Partitions
Scalability + Availability
Parts+Packs Requirements
Automatic partitioning (in dbms, mail, files,…)
Simple fail-over model
Location transparent
Partition split/merge
Grow without limits (100x10TB)
Application-centric request routing
Partition migration is transparent
MSCS-like model for services
Management:
Automatic partition management (split/merge)
Who is up?
Application monitoring.
GeoPlex: Farm Pairs
Two farms (or more)
State (your mailbox, bank account)
stored at both farms
Changes from one
sent to other
When one farm fails
other provides service
Masks
Hardware/Software faults
Operations tasks (reorganize, upgrade move)
Environmental faults (power fail, earthquake, fire)
Fail-Over & Load Balancing
Routes request to right farm
Farm
can be clone or partition
At farm, routes request to right
service
At service routes request to
Any
clone
Correct partition.
Routes around failures.
Availability
99999
well-managed nodes
Masks some hardware failures
well-managed packs & clones
Masks hardware failures,
Operations tasks (e.g. software upgrades)
Masks some software failures
well-managed GeoPlex
Masks site failures (power, network, fire, move,…)
Masks some operations failures
Cluster Scale Out Scenarios
The FARM: Clones and Packs of Partitions
Packed Partitions: Database Transparency
SQL Partition 3
Cloned
Packed
file
servers
SQL Partition 2
replication
Web File StoreA
Web File StoreB
Web
Clients
SQL
SQLPartition1
Database
SQL Temp State
Load Balance
Cloned
Front Ends
(firewall, sprayer,
web server)
Some Examples:
TerraServer:
Hotmail:
6 IIS clone front-ends (wlbs)
3-partition 4-pack backend: 3 active 1 passive
Partition by theme and geography (longitude)
1/3 sys admin
1,000 IIS clone HTTP login
3,400 IIS clone HTTP front door
+ 1,000 clones for ad rotator, in/out bound…
115 partition backend (partition by mailbox)
Cisco local director for load balancing
50 sys admin
Google: (Inktomi is similar but smaller)
700 clone spider
300 clone indexer
5-node geoplex (full replica)
1,000 clones/farm do search
100 clones/farm for http
10 sys admin
Summary
Geo
Plex
Terminology for scaleability
Farms of servers:
Farm
Clones:
identical
Scaleability
Partition
+ availability
Clone
Partitions:
Pack
Scaleability
Packs
Partition
Shared
Nothing
Shared
Disk
Shared
Nothing
availability via fail-over
GeoPlex for disaster tolerance.
ActiveActive
ActivePassive
Architectural Blueprint for Large eSites
http://msdn.microsoft.com/library/en-us/dndna/html/dnablueprint.asp
Scalability Terminology: Farms, Clones, Partitions, and Packs:
ftp://ftp.research.microsoft.com/pub/tr/tr-99-85.doc
Call to Action
Plan for 64 bit addressing everywhere
it is in your future.
Use threads
SMP is in your future
Carefully
avoid locks, use locality/affinity
Think of disks as tape:
Sequential vs random
Online archive
Windows now has ScaleUp and ScaleOut
Think in terms of Geoplexes and Farms
© 2002 Microsoft Corporation. All rights reserved.
This presentation is for informational purposes only. MICROSOFT MAKES NO WARRANTIES, EXPRESS OR IMPLIED, IN THIS SUMMARY.