Concatenations
advertisement

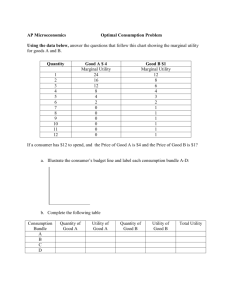
USpan: An Efficient Algorithm for
Mining High Utility Sequential Patterns
Authors: Junfu Yin, Zhigang Zheng, Longbing Cao
In: Proceedings of the 18th ACM SIGKDD international conference on
Knowledge discovery and data mining. ACM, 2012. p. 660-668.
Presenter:
0356069 江怡蕙
0356027 薛筑軒
Outline
•
•
•
•
•
•
Introduction
Related work
Problem Statement
USpan algorithm
Experiment
Conclusions & Discussions
2
Outline
• Introduction
•
•
•
•
•
• Background
• Definition
• Challenges
Related work
Problem Statement
USpan algorithm
Experiment
Conclusions & Discussions
3
Introduction
Sequential pattern mining has proven to be very
essential for handling order-based critical business
problems.
EX: structures and functions of molecular or DNA
sequences
4
Background
The selection of interesting sequences is generally
based on the frequency/support framework:
sequences of high frequency are treated as
significant. Under this framework, the downward
closure property (also known as Apriori property)
plays a fundamental role.
5
Definition
• Utility
• Internal utility = quantity ; External utility = quality
• High utility pattern mining
• Minimum utility
• The utility of <ea> in sequence 2 is {(6 × 1 + 1 × 2) ,
(6 × 1 + 2 × 2)} = {8, 10}
6
Definition
• The concept of sequence utility by considering the
quality and quantity associated with each item in a
sequence, and define the problem of mining high
utility sequential patterns;
• A complete lexicographic quantitative sequence
tree (LQS-tree) to construct utility-based
sequences; two concatenation mechanisms IConcatenation and S-Concatenation generate newly
concatenated sequences;
7
Definition
• Two pruning methods, width and depth pruning,
substantially reduce the search space in the LQStree;
• USpan traverses LQS-tree and outputs all the high
utility sequential patterns.
8
Outline
• Introduction
• Related work
•
•
•
•
• Utility Itemset/Pattern Mining
• Utility-based Sequential Pattern Mining
Problem Statement
USpan algorithm
Experiment
Conclusions & Discussions
9
Utility Itemset/Pattern Mining
• Mining high utility itemsets is much more challenging than
discovering frequent itemsets, because the fundamental
downward closure property in frequent itemset mining does
not hold in utility itemsets.
• The addition of ordering information in sequences makes it
fundamentally different and much more challenging than
mining utility itemsets
10
Utility-based Sequential Pattern Mining
• Mining frequent sequences many patterns being mined;
• Patterns with frequencies lower than minimum support are
filtered
11
Outline
•
•
•
•
•
•
Introduction
Related work
Problem Statement
USpan algorithm
Experiment
Conclusions & Discussions
12
Sequence Utility Framework
• I = {i1, i2, ..., in} a set of distinct items
• Each item ik ∈ I(1<= k<=n) is associated with a quality (or
external utility), denoted as p(ik)
• A quantitative item, or q-item, is an ordered pair (i, q),
where i ∈ I represents an item and q is a positive number
representing the quantity or internal utility
13
Sequence Utility Framework
• A quantitative itemset, or q-itemset, consists of more than
one q-item, which is denoted and defined as l = [(ij1, q1)(ij2,
q2)...(ijn, qn )]
• A quantitative sequence, or q-sequence, is an ordered list of
qitemsets, which is denoted and defined as s =< l1l2 ... lm>
• A q-sequence database S consists of sets of tuples <sid, s>
14
Sequence Utility Framework- Definitions
EX: (a, 4), [(a, 4)(e, 2)] and [(a, 4)(b, 1)(e, 2)] ⊆ [(a, 4)(b, 1)(e, 2)]
But [(a, 2)(e, 2)] or [(a, 4)(c, 1)] not contained in [(a, 4)(b, 1)(e, 2)]
<(b, 2)>, <[(b, 2)(e, 3)]>, <[(b, 2)][(e, 3)](a, 2)>
15
Sequence Utility Framework- Definitions
<(e, 5)[(c, 2)(f, 1)](b, 2)> is a 4-q-sequence with size
3.
<ea> is a 2-sequence with size 2.
16
Sequence Utility Framework- Definitions
17
Sequence Utility Framework- Definitions
18
Sequence Utility Framework- Definitions
t = <ea>
t’s utility in the s4 sequence in Table 2 is v(t, s4) = {u(<(e, 2)(a, 7)>), u(<(e, 2)
(a, 4)>)} = {16, 10}.
t’s utility in S is v(t) = {u(t, s2), u(t, s4),u(t, s5)} = {{8, 10}, {16, 10}, {15, 7}}
19
High Utility Sequential Pattern Mining
20
High Utility Sequential Pattern Mining
• Definition 10. (High Utility Sequential Pattern) Because a
sequence may have multiple utility values in the q-sequence
context, we choose the maximum utility as the sequence’s
utility.
Theof
maximum
a sequence=10
t is+denoted
The
utility
sequenceutility
ea is of
umax(<ea>)
16 + 15 =and
41.
as umax(t):
Ifdefined
the minimum
utility is ξ = 40, then sequence s = <ea> is a
high utility sequential pattern since umax(s) = 41 ≥ ξ
• Sequence t is a high utility sequential pattern if and only if
ξ user-specified minimum utility
21
Outline
•
•
•
•
Introduction
Related work
Problem Statement
USpan algorithm
•
•
•
•
•
Lexicographic Q-Sequence Tree
Concatenations
Width Pruning
Depth Pruning
USpan Algorithm
• Experiment
• Conclusions & Discussions
22
USpan Algorithm
• USpan is composed of
• a lexicographic q-sequence tree
• two concatenation mechanisms
• two pruning strategies
23
Lexicographic Q-Sequence Tree
• Adapt the concept of the Lexicographic Sequence Tree
• Suppose we have a k-sequence t, we call the operation of
appending a new item to the end of t to form (k+1)sequence concatenation.
• If the size of t does not change, we call the operation
I-Concatenation. Otherwise, if the size increases by one, we
call it S-Concatenation
• <ea>’s I-Concatenate and S-Concatenate with b result in
<e(ab)> and <eab>, respectively.
24
Lexicographic Q-Sequence Tree
• Assume two k-sequences ta and tb are concatenated from
sequence t, then ta < tb if
• i) ta is I-Concatenated from t, and tb is S-Concatenated from
t,
• ii) both ta and tb are I-Concatenated or S-Concatenated from
t, but the concatenated item in ta is alphabetically smaller
than that of tb.
• <(ab)> < <(ab)b>, <(abc)> < <(ab)b>, <(ab)c> < <(ab)d> and
<(ab)(de)> < <(ab)(df )>
25
Lexicographic Q-Sequence Tree
• Definition 11. (Lexicographic Q-sequence Tree) An
lexicographic q-sequence tree (LQS-Tree) T is a tree
structure satisfying the following rules:
• Each node in T is a sequence along with the utility of the
sequence, while the root is empty
• Any node’s child is either an I-Concatenated or Sconcatenated sequence node of the node itself
• All the children of any node in T are listed in an
incremental and alphabetical order
26
Lexicographic Q-Sequence Tree
• v(ea) = {{8, 10}, {16, 10}, {15, 7}} and umax(ea) = 41.
• “Can any <ea>’s child’s maximum utility be calculated by simply
adding the highest utility of the q-items after <ea> to
umax(ea)?” ---------------- no
27
Lexicographic Q-Sequence Tree
• Depth-first search
• How can we generate the node’s children’s utilities by
concatenating the corresponding items? Concatenations
• How can we avoid checking unpromising children? Width pruning
• When should USpan stop the search of deeper nodes?
Depth pruning
28
Concatenations
• Utility matrix
• (utility, remaining utility)
29
Concatenations
• Utility matrix
• (utility, remaining utility)
30
Concatenations
• Utility matrix
• (utility, remaining utility)
31
Concatenations: I-Concatenation
• I-Concatenation for the sequence 𝑏 in s4
• 𝑣( 𝑏𝑒 , 𝑠4 ) = { 10 + 2, 5 + 2 } = { 12, 7 }
32
Concatenations: S-Concatenation
• S-Concatenation for the sequence (𝑏𝑒) in s4
• Candidates: 𝑏𝑒 𝑎 , 𝑏𝑒 𝑏 , 𝑏𝑒 𝑑 , 𝑏𝑒 𝑒
• 𝑣( 𝑏𝑒 𝑎 , 𝑠4 ) = { 12 + 14, 12 + 8 } = { 26, 20 }
33
Concatenations
• To calculate the utilities of the children of a given
sequence (e.g. 𝑏𝑒 in s4)
• The positions of the last q-items of q-subsequences that
match the sequence (e.g. e1, e3)
• Pivot: e1 (the first place where 𝑏𝑒 ends)
• Ending q-items: e3 (other places where 𝑏𝑒 ends)
• The utility of a sequence (e.g. 12, 7)
• These values are stored in LQS-Tree.
34
Concatenations
35
Width Pruning
• Avoid constructing unpromising items into LQS-Tree
• Sequence-weighted utilization (SWU) of sequence t
𝑆𝑊𝑈 𝑡 =
𝑢(𝑠)
𝑠 ′ ~𝑡∧𝑠 ′ ⊆𝑠∧𝑠⊆𝑆
• 𝑆𝑊𝑈 𝑓 = 𝑢 𝑠1 = 24
• 𝑆𝑊𝑈 𝑒𝑎 = 𝑢 𝑠2 + 𝑢 𝑠4 + 𝑢 𝑠5 = 41 + 50 + 37
36
Width Pruning
• Sequence-weighted Downward Closure Property
(SDCP)
• Given an utility-based sequence database S, and two
sequences t1 and t2, where t2 contains t1, then
𝑆𝑊𝑈 𝑡2 ≤ 𝑆𝑊𝑈(𝑡1 )
• 𝑆𝑊𝑈 𝑒𝑎 = 𝑢 𝑠2 + 𝑢 𝑠4 + 𝑢 𝑠5 = 41 + 50 + 37
• 𝑆𝑊𝑈 𝑒 𝑎𝑏 = 𝑢 𝑠2 + 𝑢 𝑠4 + 𝑢 𝑠5 = 41 + 50 + 37
• 𝑆𝑊𝑈 𝑒 𝑎𝑑
= 𝑢 𝑠2 + 𝑢 𝑠4 = 41 + 50
• Item i is a promising item to t
• After concatenating i to t, for the new sequence t’
𝑆𝑊𝑈 𝑡 ′ ≥ 𝜉
37
Depth Pruning
• Stop USpan from going deeper in LQS-Tree
• Even if all the utilities of the remaining q-items are
counted into the utility of the sequence, the cumulative
utility still cannot satisfy 𝜉.
38
Depth Pruning
• Given a sequence t and S, the maximum utilities of
t and t’s offspring are no more than
(𝑢𝑟𝑒𝑠𝑡 𝑖, 𝑠 + 𝑢(𝑠′))
𝑖∈𝑠′ ∧𝑠′ ∼𝑡∧𝑠′ ⊆𝑠∧𝑠⊆𝑆
• i: the pivot in s of t
• urest: remaining utility at q-item i in q-sequence s
• E.g. 𝑡 = 𝑒𝑎
39
USpan Algorithm
// includes depth pruning strategy
// generate candidates
// width pruning strategy
// deal with I-Concatenation
// deal with S-Concatenation
40
Outline
•
•
•
•
•
Introduction
Related work
Problem Statement
USpan algorithm
Experiment
• Settings
• Results
• Conclusions & Discussions
41
Experimental Settings
• Data Sets
• DS1: C10 T2.5 S4 I2.5 DB10k N1k
• DS2: C8 T2.5 S6 I2.5 DB10k N10k
• The average number of elements in a sequence is 10 (8).
• The average number of items in an element is 2.5 (2.5).
• The average length of a maximal pattern consists of 4 (6)
elements and each element is composed of 2.5 (2.5) items
average.
• The data set contains 10k (10k) sequences.
• The number of items is 1k (10k).
42
Experimental Settings
• Data Sets
• DS3: online shopping transactions
• There are 811 distinct products, 350,241 transactions and
59,477 customers.
• The average number of elements in a sequence is 5.
• The max length of a customer’s sequence is 82.
• The most popular product has been ordered 2176 times.
• DS4: mobile communication transactions
• The dataset is a 100,000 mobile-call history.
• There are 67,420 customers in the dataset.
• The maximum length of a sequence is 152.
43
Experimental Results
– Execution Time & (#Patterns)
44
Experimental Results
– Execution Time & (#Patterns)
45
Experimental Results
– Distribution in Terms of Length
46
Experimental Results
– Distribution in Terms of Length
47
Experimental Results
– Pruning
48
Experimental Results
– Scalability
49
Experimental Results
– Utility vs Frequent
50
Outline
•
•
•
•
•
•
Introduction
Related work
Problem Statement
USpan algorithm
Experiment
Conclusions & Discussions
51
Conclusions
• Provide a systematic statement of a generic
framework for high utility sequential pattern
mining.
• Propose an efficient algorithm, Uspan
• I-Concatenation, S-Concatenation
• Width pruning, depth pruning
• USpan can efficiently identify high utility sequences
in large-scale data with low minimum utility.
52
Discussions
• Strongest part of this paper
• USpan grows tree by DFS and needs not to store the
whole LQS-Tree in memory.
• Two pruning strategies are proposed and work well in
their experiments.
• Only need to calculate the tables once at beginning.
• Weak points of this paper
• Each sequence needs a table to store it values and all
the tables are stored in memory.
• Each single tree node contains much information.
53
Discussions
• Possible improvement
• Design algorithms for even bigger datasets and better
pruning strategies.
• Shrink the number of tables or shrink the number of
elements in a table.
• Possible extension
• The metric of “utility”
• Items with positive and negative unit profits
• Time constraints (as in GSP)
• Possible Application
• Business decision-making
• Analysis of game records of experts
• But need to specify “item” and “utility” first
54
END
&
Thanks for your attention