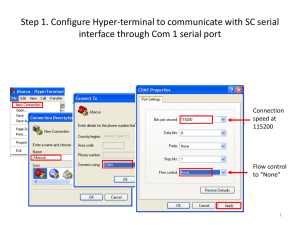
Task 4
advertisement

Introducing Normalization Having covered the rules by which you determine the relational nature of a database, we'll now cover the process of normalization used in designing relational systems. Normalization is a data modeling technique, the goal of which is to organize data elements in such a way that they're stored in one place and one place only (with the exception of foreign keys, which are shared). Data sets, or entities (in relational modeling vocabulary), are business concepts, and data elements, or attributes, are the business data. Every data element must belong to one and only one data set (with the exception of shared data values, called foreign keys), and every data set must own at least one data element. The lest to make sure you've done this correctly is often referred to as the process of, or testing for, normalization. If you've been diligent about creating atomic (single-meaning and nonconcatenated) data elements, then this process will be much simpler. Don't try to normalize a model before you've taken it to the greatest level of detail possible, having called out all its data elements separately and having understood each one well. Seven normal forms are widely accepted in the modeling community, sequenced in order of increasing data organization discipline. Note: A normal form is a slate of a relation that can be determined by applying simple rules regarding dependencies to that relation. Normal forms are designed to prevent update and delete anomalies, data redundancies, and inconsistencies. By the time you're testing for Domain Key Normal Form, you must have tested and organized the data elements to support the previous six normal forms and the universal properties of data records. These rules are cumulative, and Table 2-5 summarizes them. Table 2-5. Normal Forms 1-5. Boyce-Codd. and Domain Key Name Tests tor the Previous Normal Forms And ... Universal properties No duplicate members of the set. Record order unimportant |top to bottom). Attributes order unimportant (left to right). All attribute values are atomic. No single attribute is allowed to hold more than one value at one time. First Normal Form (1NF) The appropriateness of the primary key. Second Normal Form (2NF) The dependence of all attributes on all aspects of the primary key. Third Normal Form (3NF) The dependence of any attribute on any attribute other than the primary key. Boyce-Codd Normal Form Verifies that all data sets are identified and segregated. (BCNF) Fourth Normal Form (4NF) Verifies that all attributes are single valued for a member of the set. Fifth Normal Form (5NF) Verifies that if the constituent parts of a data set were divided, they couldn't be reconstructed. Domain Key Normal Form Verifies that all constraints are the logical consequence of (DKNF) the definition of the keys and the domains (data value rules). We'll cover only the first three normal forms in this chapter, as well as BCNF. This isn't because we don't think the others aren't interesting, but we're simply trying to reduce the complexity of normalization to make it more accessible here. On a more practical note, just getting to 3NF or BCNF is the goal of many project learns. Information support for control systems Lesson 4 / Student Page 1/7 Up until now, we've talked about data modeling with an emphasis on concepts, relationships, and data understanding rather than data element organization. Normalization is all about organizing data elements into a format where relational data integrity is maintained as strictly as possible. Logical data models should adhere to the normalization rules so that you can translate them into functioning Physical data models. However, as we mentioned earlier, in implementing Physical models you'll almost inevitably break some of the normalization rules to optimize the performance of the system. Universal Properties of Relations The universal properties of relations are the preconditions that must be in place prior to the lest for normal forms. They refer to that two-dimensional math form called a relation upon which relational design is based. There must be no duplicate instances (duplicate members of the set). Instances are unordered (top to bottom). Data elements are unordered (left to right). All data element values are atomic. No single column describing a single instance is allowed to hold multiple values at one time. These concepts underpin the way you define data sets and data elements. The identifying factor (primary key) must ensure that no duplicates exist. Not only that, but a primary key must be defined and the unique values must exist for a member to be added to the set. There must be at least enough data elements to make a member of the set unique. In addition, it shouldn't matter in what order the instances (members of the set) of a data set are created. The same goes for the order of the data elements. They end up being stored in some order, but it shouldn't matter what that order is (except for RDBMS needs). The sequence of the data elements is as independent as the sequence of the instances. Figure 2-5 illustrates that once the universal properties arc true (as supported by RDBMS and your analysis), you add layer upon layer of tests for potential anomalies in the data organization. Each subsequent test depends on the universal properties already being satisfied. Think of building on normal forms as analogous to painting a house. First you prepare the surface, then you seal the wood, then you add the primer, and finally you apply two topcoats of paint. Similarly, in building data models it doesn't make sense to apply 3NF tests until INF and 2NFhave already been reflected in the design. Each normal form test represents a layering of data structure quality testing. Figure 2-5 shows the cumulation of forms. BCNF attributes are on depend on a key 3NF attributes depend on nothing but the key 2NF attributes depend on the whole key 1NF attributes depend on a key Universal relations Figure 2-5. Cumulation of forms So. you satisfy the generic universal relations by concentrating on the duplicate instances within each set. For example, in the set of Orders, Order 6497 isn't allowed to appear Information support for control systems Lesson 4 / Student Page 2/7 more than once. In a similar fashion, no data elements are allowed to represent multiple values at the same time. For example, you can't store the data values Spokane, Miami, and LA as a single City data element; each value must be stored as an individual data element. You can test this by getting sample data and combing through it. You have to resolve data issues such as this before you can finalize your logical design that a physical database can be built from. Why Check for Universal Relations? Unwanted or unmanaged duplicates create serious issues in physical data management. They cause the following problems: You have to worry about consistent and concurrent updates in all the places where the data is stored. You have to customize code for data retrieval issues when there may be possible inconsistent multiples of the same data element in the return set. You have to customize correct values in data generalizations, especially in math functions such as sums and averages. You have to parse and customize code for multiple values stored in one column. For example, if your bank account current balance is stored as several duplicated values in several different data stores in the bank's database, then there's a chance that, if the relevant integrity constraints are compromised in some way, your balance will be updated in only one location. All these values need to be updated in a synchronized fashion, or your latest salary payment may be missed! If these rules aren't followed, there's a chance of providing incorrect answers to simple data questions needed by the clients. The inability to provide correct answers lowers the value of the data. Having to be creative about getting correct answers because of these kinds of data storage issues increases the cost of managing the data. In practice, a lot of code randomly picks the first instance of a duplicate row just because there's no other way of filtering out duplicate records. There are also complicated blocks of code, involving complex query statements and coupled with IF...THEN...ELSE case statements, that are devised to custom parse through multiple values buried in one unstructured column in a table just to be able to access data and report correctly. Keeping all the instances unique and the data elements atomic provides a huge increase in data quality and performance (in part because you can now use indexes to access data). Let's say you're analyzing orders at a new car dealership. You learn that each customer places a separate order but that they can buy multiple cars on one order. A customer can place their order in person, over the phone, or via the Web page, and to finalize the order, one of the staff members must verify all the information. Having discovered these data elements, you test for the universal relation rules and use the results of those tests to reorganize the data into a preliminary normalized structure, as shown in Figure 2-6. Information support for control systems Lesson 4 / Student Page 3/7 Order Order number Order date Customer name Order Creation Method Name Verifying Employee Name Total Sales Amount Car Serial Number Car Color Names Car Make Model Year Notes Figure 2-6. Preliminary normalized structure of a car dealer Try 10 figure out what makes each sale unique so than you can determine the unique identifiers that are possible primary keys. In this case, you can come up with two options (candidate keys), namely, Order Number as a single unique piece of information or the coupling of two values, Customer Name plus Order Date. However, although it's improbable that a customer will make two orders on the same day. it isn't impossible, so you can't use Customer Name and Order Date in combination as a primary key. This leaves Order Number that can be used to uniquely identify each Order, and this data element moves into a position above the line to note it's the primary key, as shown in Figure 2-7. Now you've met the requirement for a unique method of recognizing the members of the set. Universal Relation Rules Order Order Order number Candidate Keys: Choose one Order number Order date Customer name Order Creation Method Name Verifying Employee Name Total Sales Amount Car Serial Number Car Color Names Car Make Model Year Notes Order date Customer name Order Creation Method Name Verifying Employee Name Total Sales Amount Car Serial Number Car Color Names Car Make Model Year Notes Data Role Change: Order Number is now the primary key Figure 2-7. Order Number is chosen as the primary identifier (primary key) Now look at the sequence of the orders. Can you still find one specific order if you shuffle the orders? Yes. Then it doesn't matter what order the data is in the table. That requirement is fine. Would it mailer if you reorganize the values for an order as long as you still knew they represented the Order Number, Customer Name, and so on? No, you could still find one specific order, and it would still mean the same thing. That requirement is OK. Information support for control systems Lesson 4 / Student Page 4/7 Next, you notice that Car Serial Number, Car Color Number, and Car Hake Model Year Note are noted as plurals. You look through the data and find that indeed there are several orders with two car purchases and one (out of the 100 examples you looked through) that has three cars. So you create separate data elements for the potential three car sales on the Order. This requires the structure changes shown in Figure 2-8. Now you need to carry out the same checks on the revised data structure. Does (his relation have a unique identifier? Are there any sequencing issues? Are there any multivalue data elements? The answer to this last question is of course "yes." which you probably spotted by reading the descriptive names. The Car Make Model Year Note data elements have been duplicated lo support car 1, 2, and 3. So. although they no longer have duplicated values for different cars, they contain an internal repealing group of make, model, and year. Since the process of normalization focuses on creating atomic data elements, leaving data elements such as this breaks the normalization rules. In the case of Logical modeling, you'll want to separate these concepts into distinctive data elements, as shown in Figure 2-9. Universal Relation Rules Order Does it matter what order the records are in? No Does it matter what order the columns are in? No Are there any multivalued attributes? Order number Order date Customer name Order Creation Method Name Verifying Employee Name Total Sales Amount Car Serial Number Car Color Names Car Make Model Year Notes Yes Data Storage Change: 1 Value = 1 Column Order Order number Order date Customer name Order Creation Method Name Verifying Employee Name Total Sales Amount Car 1 Serial Number Car 1 Color Names Car 1 Make Model Year Notes Car 2 Serial Number Car 2 Color Names Car 2 Make Model Year Notes Car 3 Serial Number Car 3 Color Names Car 3 Make Model Year Notes Figure 2-8. Continued tests resulting in a change for multivalues Information support for control systems Lesson 4 / Student Page 5/7 Universal Relation Rules Order Data Storage Change: 1 Value = 1 Column Order Order number Order number Order date Customer name Order Creation Method Name Verifying Employee Name Total Sales Amount Car 1 Serial Number Car 2 Serial Number Car 3 Serial Number Car 1 Color Names Car 2 Color Names Car 3 Color Names Car 1 Make Model Year Notes Car 2 Make Model Year Notes Car 3 Make Model Year Notes Order date Customer name Order Creation Method Name Verifying Employee Name Total Sales Amount Car 1 Serial Number Car 1 Color Names Car 1 Make Model Year Notes Car 2 Serial Number Car 2 Color Names Car 2 Make Model Year Notes Car 3 Serial Number Car 3 Color Names Car 3 Make Model Year Notes Yes Are there any multimeaning attributes? Figure 2-9. Continued tests resulting in a change for multivalues You must continue to review your data set design until you've met all the universal relation rules. Let's now look in a little more detail at the nature of the first four normal forms. First Normal Form (1NF) Having obeyed the demands of the universal relations, you can move onto 1NF Note: 1NF demands that every member of the set depends on the key; and no repeating groups are allowed. Here you're testing for any data element, or group of data elements, that seem to duplicate. For example, any data element that's numbered is probably a repeater. In the earlier car dealership example, you can see Car Serial Number 1, Car Serial Number 2, and Car Serial Number 3 and the corresponding Color data elements. Another way to recognize that data elements repeat is by looking for a distinctive grouping that's within a differentiating factor such as types or series numbers. You could find something such as Home Area Code and Home Phone Number, then Cell Area Code and Cell Phone Number, followed by Work Area Code and Work Phone Number, or just a simple Area Code l. Area Code 2, and Area Code 3. Repeating groups of data elements denote at least a one-to-many relationship to cover the multiplicity of their nature. What do you do with them? You recognize this case as a oneto-many relationship and break the data elements into a different data set (since they represent a new business concept).Then you change the data element names to show they occur only Information support for control systems Lesson 4 / Student Page 6/7 once. Finally, you have to apply the universal rules for the new data set and determine what the primary key for this new data set would be. In this case, each member of this set represents a sale of a car. You need both the Order Number and the Car Serial Number in the primary key. In many order systems this will be an order-to-order line structure, because the sales aren't for uniquely identifiable products (see Figure 2-10). Task 1. Answer the following questions: 1. 2. 3. 4. 5. What is normalization? When is a table in 1NF? When is a table in 2NF? When is a table in 3NF? When is a table in BCNF? Task 2. Create a databases listed below. You can use your databases represented on previous lessons 1. Create a database whose tables are at least in 2NF, showing the dependency diagrams for each table. 2. Create a database whose tables are at least in 3NF, showing the dependency diagrams for each table. Information support for control systems Lesson 4 / Student Page 7/7