Link to Word Version
advertisement

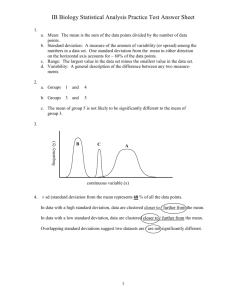
Variation Lab by Ray L. Winstead A major characteristic inherent in biological systems is the presence of VARIATION or differences that exist among individual organisms in their structures, functions, and behavior. As you have learned, or will learn, in the lecture part of the course, these differences are important in the process of evolution. The concept of variation will be illustrated in this lab by measuring some human characteristic and by examining the differences that exist within and between two different groups. The characteristic (e.g., height, length of a finger bone) and groupings (e.g., gender) may be chosen by your professor or by you, as directed by your lab professor. In biological research, observation values (i.e., numerical measurements or data points) are usually obtained to describe and give information about a particular characteristic within a group of subjects. Consider the following way to represent such measurements: Measurements Y1 Y2 Y3 . Y1 represents the first measurement, Y2 represents the . second measurement, Yi represents the generalized Yi "ith" measurement, and Yn represents the last . measurement, where n is the total number of . measurements in the group. Yn = Y n Whenever you have any group of measurements, especially a very large group, it is convenient and helpful to have an intuitive value denoting the "center" of the group. The common average or "mean" provides this handy, intuitive measure and is simply the sum of all the measurements divided by the number of measurements in the group (as illustrated above). Average = Mean = However, just knowing the average of the measurements is not enough information to have a good intuitive description of the characteristic. Information about the variation within the group, i.e., the spread of the measurements around the mean is also helpful and necessary. Consider the following two groups (Figure 1) where the averages are exactly the same in both groups but the spread of the measurements around the mean is very different. For each group the 12 tick marks along the horizontal axis indicate observation measurement values on some scale appropriate for the measurement. Figure 1 Note that the 12 values in the first group are clustered around the mean but, in general, are distributed farther away from the mean than in the second group. Note further that the 12 values in the second group are also clustered around the mean and are, in general, closer to the mean than in the first group. This shows that just having information about the mean is not enough information to have a clear understanding of the measurements of that characteristic. Consider another representation below (Figure 2) of the two groups, including further information about the distribution of measurement values in the two groups. The horizontal axis represents a scale of observation values as before, while the vertical axis represents the additional information of frequency, i.e., the number of observation values. The curved line represents the change in the number of observation values in the group as the actual value changes from a low value to a high value. Note that in both cases, as in many biological distributions, the curve approximates a "Normal" distribution with more values occurring in the center of the group near the mean and then becoming fewer in number away from the mean. Observation Values Figure 2 Consider the following two representations (Figure 3) of the difference between one individual observation measurement and the mean as a linear distance. In the first case the difference is represented on the horizontal axis, while in the second case the same distance is represented within the graph above the horizontal axis. In this way all the differences can be represented on the same graph and visualized more easily, without having to superimpose the different values all on top of each other on the horizontal axis. Figure 3 In Figure 4 below note that the lines representing the differences between the individual observations and the mean are, in general, longer in the first graph than the lines in the second graph. Figure 4 Here is where we can get a second index (the first being the mean) that will give us an intuitive idea of the characteristics of the measurements in the group. This second index will tell us, in general, how spread out the measurement values are away from the mean. Especially note intuitively from Figure 4 that if we simply take an AVERAGE OF THE DISTANCES representing differences between individual observation measurements and the mean that in the first case the average of the distances will be large and in the second case the average of the distances will be small. So, all we have to do is find the average of those distances for each group and that will give us our desired intuitive index of the spread of the observation values surrounding the mean for each group. If the index is small, it will mean that the values are close to the mean, however if the index is large, it will mean, in general, that the observation values are spread farther out from the mean (even though there are still more of them in the center of the distribution). In this way we can use the new index not only as a measure of variation within a group but also for comparative purposes among different groups. In particular, the second index we wish to construct is simply (a modified) average of the DIFFERENCES between the individual observations in a group and the group mean and is, therefore, an index of the VARIATION in that group. A large index indicates a large amount of variation (differences) within a group and a small index will indicate the existence of only small differences among the measurements. In this lab you will assess the variation WITHIN each group of measurements and also compare the variability BETWEEN two groups. The goal now is to calculate the index of the spread of the values around the mean, i.e., the average of the differences between individual observation measurements and the mean. First of all calculate the difference between each observation value and the mean: Measurements Difference Average = Mean = Y1 Y2 Y3 .. .. Yi .. .. Yn Y1 Y2 Y3 - = Y n (Y n Yi - Yn ) Taking the average of the differences above will apparently give us our desired index of the average of the differences and it first appears that we are finished. However, since some the values are greater than the mean, some of the differences will be positive values, while some of the differences will be negative values, since some of the values are less than the mean. This means that our original calculated average of the differences above will ALWAYS be equal to zero, given the inherent nature of the mean being in the middle of the group and the positive and negative differences ALWAYS canceling out each other. Having a zero as our index for all cases is not helpful! However, our original logic of calculating an average of the distances was correct, so now we need to calculate the average of the differences after first ignoring whether or not the difference is positive or negative, i.e., ignoring whether or not the value is either smaller than or larger than the mean. We are really only interested in the magnitude of the difference away from the mean, not which direction. The historical way of solving this problem was simply to take the absolute value of each difference (e.g, | + 5| = + 5 and | - 5| = + 5) and then to take the average of those resulting positive absolute values. That did in fact give the desired, useful index where a small average of the differences indicated that the values are close to the mean and a large average of the differences indicated that the observation values are spread farther out from the mean. However, as the field of statistics grew, more powerful, but complicated, procedures were introduced, and using this particular index for variation using absolute values proved to be very cumbersome. Therefore, an alternative solution to the "getting rid of the signs" problem was adopted that gives comparable results for a measure of the average difference, i.e., a measure of the spread of the values around the mean. Instead of taking the absolute value to get rid of the sign, each difference is squared, and the result is always positive. So, now we have: Measurements Difference Difference Squared Y1 Y1 (Y1 - )2 Y2 Y2 (Y2 - )2 Y3 Y3 (Y3 - )2 ... ... Yi Yi (Yi - )2 ... ... Yn Yn (Yn - )2 = Y (Y - ) (Y - )2 N n n Taking the average of the squared differences gives us (Y - )2 . n However, the average of the squared differences was not our original goal, but only the average of the differences (not squared). Therefore, in order to account for squaring each difference (to get rid of the sign), we now must take the square root of our calculated average of the squared differences. We have as our answer our desired index of the spread of the values around the mean as Average = Mean = Average Difference = . This index gives us the information we need as a measure of the spread of the values within a group around the mean, i.e., a measure of variation. If the index is small, it will mean that the values are close to the mean, however if the index is large, it will mean, in general, that the observation values are spread farther out from the mean. Another term for "difference" is "deviation," so the Average Difference may also be called the Average Deviation. Another term often used for "average" is "standard," so the Average Difference is more often called the "Standard Deviation." THE STANDARD DEVIATION IS JUST THE AVERAGE DIFFERENCE BETWEEN INDIVIDUAL OBSERVATION MEASUREMENTS AND THE MEAN. Note that the formula above for the standard deviation is not just a mysterious formula but a shorthand presentation of a logical way to achieve a meaningful measure of variation. The average of the squared differences is also a legitimate index of variation, since as the index goes up this also means that the spread of the values around the mean is greater. The average of the squared differences is usually called the "Variance." The calculation of the standard deviation above assumes that ALL of the subjects of interest within a group are available and have been measured. This is rarely the case. Most of the time in biological research only a small sample of a larger group of interest is actually measured. The assumption is then made that the sample accurately reflects the characteristics of the larger group. Any conclusions drawn from the sample are only as accurate as the accuracy of the sample representing the larger group. Although the equation above is accurate for calculating the standard deviation for an entire group, it is not an accurate representation of variation for the entire group if calculated from a smaller sample. Since the calculation above is "biased" (systematically distorted) when calculated from a sample, a correction factor is needed when estimating the true standard deviation of a larger group from a smaller sample. Mathematical statisticians have shown that instead of dividing by the number of cases n, dividing by n - 1 will provide a more accurate "unbiased" ESTIMATE of the true standard deviation when calculated from a sample from the larger group. Therefore, the following formula for standard deviation is the one most often used and the one we will use during this lab. Standard Deviation = . In this lab you will assess the variation WITHIN each group of measurements and also compare the variability BETWEEN two groups. Lab Procedure Unless otherwise instructed by your lab professor, follow the procedure below. Work in groups of three or four students at a lab table. Having half the class (e.g., students at three lab tables) acquire data for one group (e.g., men) and the other half of the class acquire data for the other group (e.g., women) works well. Leave the lab room and go out to the Oak Grove (or other nearby place on campus) to select twelve (12) subjects (students) to measure the chosen characteristic in each of the two groups of interest. Each table is responsible for acquiring four data points, so that the class will have a total of 24 measurements. Record the measurements for one group (e.g., men) in the first column (1) in Table 1 and record the information for the other group (e.g., women) in the first column of Table 2. (Numbers in parentheses refer to the steps outlined in the Tables.) It will be helpful to first list the 12 measurements in each group on the chalkboard before copying this information into the tables, so that everyone will be working with the same data in the same order. In this way finding errors in upcoming calculations will be easier. Note that the measurements are not all the same, but are different from each other, indicating variation in the measurements. The amount of this variation or variability within your sampled group can be measured, as well as the difference that may exist between the two groups. Next, add the measurements in each group together (2) and divide by the number of measurements you have (n = 12) to give you the average (3) of the measured characteristic for that group. Unless otherwise told by your lab professor, for steps (1) through (4) round off your values to one decimal place, e.g., 7.6, however for steps (5) through (8) round off to two decimal places, e.g., 1.21. After EVERY calculation always ask yourself the question: Does the answer make sense? For example, is the average of the measurements close to your intuitive guess of the middle of the recorded measurements? If not, then look for a possible error in your calculations. Since we are interested in differences as a measure of the variability among individuals, calculate the difference Y between each individual measurement Y (1) and the mean (3) and record these differences in column (4) of the Table. These differences are also called deviations from the mean. Note that some of these numbers are negative. Although our objective is to obtain an average of the differences we cannot just simply calculate this average in the usual way, because, recall, the sum of the differences will always be zero (because some of the measurements are less than the mean and some are more than the mean, i.e., because of the changes in sign). This would mean that the average of the differences would also always be zero, and therefore, this would be a totally useless index to compare different groups. To account for this fact and to get rid of the negative signs, the deviations are squared. Square each one of the deviations (4) and record these in the third column (5). Add the squared deviations (5) together to give you the entry for step (6). This sum of the squared deviations is sometimes referred to as simply the "sum of squares." The group of individuals we measured is a sample from a larger population (e.g., all students at IUP) and this sample is assumed to have basically the same characteristics as the larger population. In order to get the best estimate of the spread of values (i.e. the variation) around the mean of the larger population from our small sample, recall that mathematical statisticians have shown that the sum of the squared deviations must be divided by the number of observations minus one (n - 1), instead of just by the number of observations (n). (Dividing by n will indeed give us the average of the squared deviations for the sample, however we wish our estimate to be generalized to the larger group). For step (7) in the Table, divide the sum of the squared deviations (6) by n - 1 (i.e., divide by 11 in our case). This value is also a legitimate index of the variability in the group and is known as the variance. To complete the calculation of the standard deviation (8) take the square root of the calculated variance in step (7) and record this in the Table. The standard deviation will make more intuitive sense to you if you think of it as an average deviation or the average difference between the observed values and the mean of the sample. Either the standard deviation or the variance may be used as the index of the variability of the measured characteristic. Go through the same procedure with the measurements from the second group recorded in Table 2 to obtain the mean, variance, and standard deviation for the chosen characteristic for this second group. Using the information from the two samples, you will now be able to more formally compare the difference observed between the two groups. Certainly the means and variances that you have calculated from the two groups will vary some, however, the question really is whether or not the observed differences in the means and variances between the two groups are due to the chance sampling of unrepresentative individuals for that particular characteristic or, in fact, indicate a real difference between the two larger groups from which the smaller samples were drawn. Small observed differences could exist between the two smaller samples even if the true means of the two populations are the same. The standard statistical test called the "t test" will allow us to draw conclusions about a possible, real difference between the two larger populations using the means of the two small samples. Larger sample sizes would give us more accurate results about the characteristics of the larger population. In order to calculate the t test statistic, we first need to calculate the standard error of the estimate of differences. (The standard error is a standard deviation of an estimate, e.g. a mean). Information from both groups are used to calculate the needed standard error: When the sample sizes for both groups are 12, the value of n in the formula above is equal to 12, not 24. Using the information from both groups, calculate the standard error for our study: The t test statistic is the appropriate decision maker to decide if the means of the chosen characteristic in the two populations are indeed really different from each other. first group - second group t = ---------------------------------------S.E. Based on the information in the two samples you have, calculate the t test statistic to compare the means of the two groups: If the value of the calculated t above is greater than 2.07 or less than - 2.07, then our conclusion is that there is probably a real, "significant" difference between the means of the two larger groups from which the samples came. If the value of the calculated t falls between - 2.07 and + 2.07, then the observed difference between the two means is probably just due to chance sampling and there is probably not a real difference between the two groups. (This could also mean that our sample sizes are too small to pick up a possible real, but small, difference between the means of the two populations. The critical value of 2.07 is determined by the sample size of 12 in each of the two groups. Furthermore, the form of the t test above is appropriate for the conditions of this study, however more complex forms would be necessary under other conditions.) What is your conclusion about the difference in our case of the means of the chosen characteristic between the two groups? The t test determines whether or not there is a difference between the means of the two groups. The variance, however, is an index of variability WITHIN a group and this variability may be equal to or not equal to the variability within another group, regardless of whether or not their means are the same. To test whether or not the variability WITHIN the first group is different from the variability WITHIN the second group, compare the calculated variances of each group using the standard F test: Highest variance of the two groups F = --------------------------------------------Lowest variance of the two groups Calculate the F test statistic for the variances found in the two samples: If the value of the calculated F above is greater than 2.81, then our conclusion is that there is a real, significant difference between the variability found WITHIN each group with respect to the chosen characteristic. If the calculated value is less than 2.81, then the observed difference in the variances is probably due to chance sampling and there is probably no real difference between the two groups with respect to the variability around their respective means. Table 1 for one group: Table 2 for the second group: