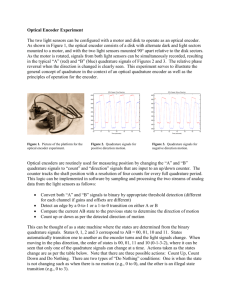
Quadrature Rules
advertisement

IFAC2011 Pre-Conference Tutorial
August 27-28, 2011, Milano
Integration Methods for Multidimensional
Probability Integrals
Abebe Geletu
abebe.geletu@tu-ilmenau.de
www.tu-ilmenau.de/simulation
Group of Simulation and Optimal Processes (SOP)
Institute for Automation and Systems Engineering
Technische Universität Ilmenau
Content
1. Introduction
2. One-dimensional probability integrals
3. Cubature rules for multidimensional
3.1. Full-grid cubature rules
3.2. Sparse-grid cubature rules
4. Application
5. Conclusions
6. Resources and References
1. Introduction
Task: to solve the optimization problem
(CCOPT) min E[f (u, )]
u
s.t.
Define:
Pr{g(u, ) 0}
umin u u max .
F(u) : E[f (u, )] f (u, )()d
G(u) : Pr{g(u, ) 0}
()d
g(u, ) 0
= 1( ,0] (g(u, ))()d =E[1( ,0] (g(u, ))].
Introduction …
The problem CCOPT is equivalently written as
(NLP) min F(u)
u
s.t.
G(u) 0
u min u u max .
Question: How to solve the problem NLP?
Use either gradient-based or gradient-free
optimization algorithms or a combination of both.
(A) Any optimization algorithm requires
• value of the objective function F(u)
• Value of the constraint function G(u)
for each given u .
Introduction …
The most difficult task in solving CCOPT is the evaluation
of the values of the chance constraint
G(u) Pr{g(u, ) 0}
for a given u .
Note that z g(u, ) is a random variable, since is
random.
If g(u, ) is non-linear w.r.t. it is difficult to determine
the distribution of the random variable z from that of .
Approach : back-projection through a montony relation
• Let be a 1D random variable with a known distribution.
• Let
Then
z
and
is a strictly increasing real valued function.
Pr a z b Pr 1 (a) 1 (b)
The latter is simpler to compute!!
Introduction …
In higher dimensions (experimentally or analytically) study the
equation
z g(u, )
and among 1 , 2 , , n find a j which has a strict monotony
relation with z ; so that z u j :
u
is either strictly increasing
decreasing j z
j
z or striclty
j u1 z .
u 0
()d j d,
0
1 ()d j d,
u 0
j z Pr g(u, ) 0 Pr j u1 0
j z Pr g(u, ) 0 Pr j
where 1 ,
, j1 , n 1 ,
1
u
, n
1
n 1
.
Introduction…
(B) Gradient-based algorithms further
require
• gradient of the objective function F(u) and
• Gradient of the constraints function G(u)
when these derivatives exist.
In both (A) and (B) values and gradient are
computed through evaluation of multidimensional
integrals of the form
Iu [f ]: f (u, )()d
Except in some special cases
• these integrals cannot be computed analytically
• integrals on higher dimensions are computationally
expensive
Introduction…
Numerical methods for evaluation of
multidimensional integrals.
Fast and efficient evaluation of probability integrals reduces
computational expenses in the overall optimization strategy for
CCOPT.
Since integration is done with respect to we drop the
parameterization with u and consider only
I[f]:]: ff(x)
(
)(x)dx
()d
I[f
for the sake of simplicity.
Introduction …
Methods for Multidimensional Integrals
Deterministic Methods
• Quadrature rules – for 1D integrals
• Full or Spars-grid cubature rules – for MD integrals
Sampling-based Methods
• Monte Carlo Methods
• Quasi-Monte Carlo methods
Deterministic integration rules for multidimensional integrals
(commonly called cubature rules) are usually constructed
from 1D quadrature rules.
2. Qudrature Rules
Given the 1D integral
where [a, b]
I[f ] f ()()d,
is a finite or an infinite interval
and () is a non-negative weight function.
The weight function corresponds to a probability density
function of a random variable on the set .
I[f ] represents expected value.
Weights and
integration
domains for
some standard
1D probability
integrals
,
[-1,1]
Distribution
2
Normal
1
Uniform
e
[-1,1]
(1 ) (1 )
0,
e
Beta
Exponential
Qudrature Rules …
Idea: to approximate the integral
I[f ] by a weighted sum
N
so that
Q[f ] w k f (k )
k 1
the approximation error E N [f ]
E N [f ]: I[f ] Q[f ]
is as small as possible;
the quadrature rule Q[] be capable of approximating 1D integrals
I[f ] for a large class of functions f .
Important issues: How to generate
quadrature nodes: 1 , 2 , , N
corresponding weights: w1 , w 2 , , w N and
the number N of function evaluations ?
Qudrature Rules …
The number N of nodes is a trade-off between accuracy and
efficiency. In general, the use of several nodes may not
reduce the approximation error!!
Methods for 1D integrals:
Newton-Cotes Formulas
- less accurate for probability integrals
Monte-Carlo and Quasi-Monte Carlo
- mainly used for multidimensional integrals
Gauss quadrature rules and Kronord/Patterson extenstions
- highly accurate and suitable for probability integrals
Clenshaw-Curtis quadrature rule
- suitable for probability integrals
Required property:
All the quadrature weights w1 , w 2 ,
, w N are non-negative.
Quadrature Rules …
Non-negative quadrature weights have advantages:
the use of non-negative weights reduces the danger of
numerical cancellations in Q[] ;
in stochastic optimization, if f , is convex w.r.t. u for each
fixed , then (u) :
(u) f (u, )()d
is convex and due to the non-negative of weights the
N
approximation
(u) w k f (u, k )
k 1
preserves the convexity.
Orthogonal Polynomials and Gauss
Quadrature Rules
Ref: Walter Gatushi : Orthogonal Polynomials
• For two functions
f
and
g
f ,g f g d
defines a scalar product w.r.t. on the set .
• A degree n polynomial p n and a degree m polynomial pm are orthogonal
on w.r.t. if
pn , pm pn pm d 0.
• Different pairs , lead to different sets of orthogonal polynomials.
Example: Sets of orthogonal polynomials for standard , pair:
2
• Hermit polynomials - () e , , .
• Jacobi polynomials - () (1 ) (1 ) , , 1;
1,1; etc.
Quadrature nodes 1 , 2 ,
, N and corresponding weights
w1 , w 2 , , w N are computed based on orthogonal polynomials with
respect to a given pair , .
Generation of orthogonal polynomials
Ref: Walter Gatushi : Orthogonal Polynomials
Given any pair , . Let
exist and finite. Then
(i)there is a unique set
0 and all moments
k
k
()d, k 0,1,
p0 1, p1 (), p2 (), of orthogonal polynomials
corresponding to , satisfying
pk , pm 0, for k m
(ii) the set of polynomials are uniquely determined by the three-term recurrence
relation using p0 () 1 and
pk 1 () a k 1 pk () bk pk 1 (), k 1, 2,
where
p1 () : 0 and
b k 1
a k 1 pk ,pk
1,
pk , pk
pk ,pk , k 0, 1, 2,
p k 1 , p k 1
for k 0
, for k 1, 2,
Computation of Gauss quadrature nodes and
weights
Ref: Golub, G.H., Welsch, J.H. Calculation of Gauss quadrature rules.
the computation of the coefficients a 0 ,a k ,bk ,k 0,1,2, of the
recurrence relation requires algorithms (commonly known as
Steleje’s procedures
see Gander & Karp for a stable algorithm.
For known recurrence coefficients a 0 ,a k ,bk ,k 0,1,2,
the N nodes
, w N of a Gauss
1 , 2 ,
, N and weights w1 , w 2 ,
quadrature rules are computed from the Jacobi matrix
a0
b1
JN
b1
a1
b2
b2
a N1
b N1
b N1
a N
Factorize J N V T V;
so that diag(1 , 2 ,
, N ) and V T V I N
Then,
k k , k 1,
w k e1T Ve k
,N
2
, k k 1,
where ek is the k-th unit vector in
, N;
N
.
, w N computed above
Note that: all the quadrature weights w1 , w 2 ,
are nonnegative
Gauss quadrature rules have non-negative weights.
, N all lie in the interior of .
the quadrature nodes 1 , 2 ,
Standard Gauss Quadrature Rules
Ref: Abramowitz, M. and Stegun, I. A. Handbook of Mathematical Functions with Furmulas, Graphs, and Mathematical Tables
There are software and lookup tables for standard quadrature nodes and
corresponding weights.
Table : Standard Gauss-quadrature rules
[1,1]
[1,1]
[1,1]
[0, )
(, )
1
Orthogonal
Polynomials
Quadrature Rule
1
Lgendre
Gauss-Legendre
Chebychev
Gauss-Chebychev
Jacobi
Gauss-Jacobi
Laguerr
Gauss-Laguerr
Hermite
Gauss-Hermite
1 2
(1 ) (1 ) ; , 1
e
e
2
NB: All 1D probability integrals corresponding to standard Gaussquadrature rules can be computed with non-negative quadrature weights.
Gauss Quadrature Rules – Exactness
An N-point Gauss quadrature rule computes all polynomials
with degree less or equal to 2N 1 exactly; i.e.
N
I pn pn ()()d Q pn w k pn (k ), n 1, 2,
pn
, 2N 1.
k 1
the quadrature rule has a degree of (polynomial) exactness
equal to 2N-1
a probability integrals with a polynomial integrand
can be computed exactly.
if the integrand is a general function f of the uncertain variable,
the approximation error E N f depends on the smoothness of the
function and the number N of integration nodes;
integration nodes and weights are generated independent of the
integrand;
quadrature rules with odd number N of nodes are usually more
preferred.
Example: Gauss-Hermite quadrature
Ref: Abramowitz, M. and Stegun, I. A. Handbook of Mathematical Functions with Furmulas, Graphs, and Mathematical Tables
Gauss-Hermite quadrature nodes and weights
k
±1.22474487139
wk
0.295408975151
3-Point GaussHermite quadrature
3
0
1.1816359006
Q3[f ] w k f ( k )
k 1
Polynomial exactness up
to degree 2 3 1 5
k
±2.651961356
wk
0.0009717812450
±1.673551628
0.05451558281
±0.8162878828
0.4256072526
0
0.8102646175
7-Point GaussHermite quadrature
7
Q7 [f ] w k f ( k )
k 1
Polynomial exactness up
to degree 2 7 1 13.
Example: Gauss-Hermite quadrature
Suppose
N(, ) to evaluate
where
1
()
e
2
2
( )2
2
Variable transformation :
E[f ]
f ()()d
.
x
2 x
2
and d 2 dx.
1
E[f ] f ()
e
2
( )2
2
1
x2
d
f ( 2x )e dx.
Example: Gauss-Hermite quadrature
Using quadrature nodes based on the weight function
(x) e
x2
we have
1 N
E[f ] Q N [f ]
w k f ( 2x k ).
k 1
For special case
f () 7 , =0.2, 1
1 3
7
E[f ] Q3[f ]
w
(
2x
0.2)
13.4467.
k
k
k 1
1 5
7
E[f ] Q5 [f ]
w
(
2x
0.2)
21.8467.
k
k
k 1
7
A 3-Point quadrature is not efficient to compute E .
Embedded quadrature rules
Ref: Trefethen: Is Gauss quadrature better than Clenshaw-Curtis?
(1)
(1)
(1)
Let N1 N 2 . If the set X 1 , 2 ,
subset of the set of nodes
, (1)
N1
X(2) 1(2) , (2)
2 ,
X(1) X(2)
the quadature rule is embedded.
of nodes for Q N1 is a
for
, (2)
N2
Q N;2 i.e.,
Clenshaw-Curtis Quadrature Rule on 1,1
Quadrature nodes
(k 1)
k cos
, k 1, 2,
N 1
, N; N 1.
All quadrature weights in Q N are positive;
have polynomial exactness equal to only N 1 (less than Gaussquadrature rules);
it is an embedded quadrature rule
Given Q N , construction of Q 2N 1 requires only N 1
additional points; values of f already computed for Q N
can be reused in Q 2 N 1
saves time.
Advantages of Embedded quadrature rules
Unfortunately, Gauss quadratture rules are not embedded.
Example: Gauss-Hermite quadrature
N
Nodes
1
0
2
-1,1
3
3, 0, 3
4
5
3 5, 3 6, 3 5, 3 6
5 15 , 5 15 , 0, 5 15 , 5 15
Some advantages of embedded rules:
nodes of lower degree quadrature can be used when constructing
higher degree quadratures;
provides easier error estimation for quadrature rule;
embeddedness is a highly desired property for the construction of
multidimensional cubature techniques, etc.
Kronord and Patterson Extensions
Ref: Laurie, D.P. Calculation of Gauss-Krnord quadrature rules.
Extend Gauss quadrature rules to make them embedded.
Kronord‘s Extension (Gauss-Krnord quadrature)
Given Gauss quadrature nodes 1 , 2 ,
two nodes add one new node:
1 (a, 1 ), 2 (1 , 2 ),
, N , between every
, N 1 ( N , b).
so that the new set of N N 1 nodes
1 , 1 , 1 , 2 , 2 ,
, N , N 1
embeds the former ones.
the new quadrature weights are w1 , w 2 ,
negative
, w 2 N 1 non-
Nodes of lower degree quadrature can be used in constructing higher degree
quadratures.
Degree of exactenss
3N 1, if N is even
3N 2, if N is odd.
Patterson’s Extensions
Ref: Patterson, T.N. L. The optimum addition of points to quadrature formula.
To existing Gauss quadrature nodes 1 , 2 ,
quadrature nodes
1 ,
, N add p new
, pso that the resulting rule has a
maximum degree of accuracy
2(p N) 1 N N 2p 1.
and the weights so that the new set of w1 , w 2 ,
are non-negative.
Hence,
, w N 2p 1
X N X Np .
In general,
pre-fixing integration nodes reduces degree of exactness;
construction of embedded Gauss quadrature rules is not a
trivial task. (see Laurie 1997)
Quadrature for non-standard integrals
Note that: transform integrals on non-standard intervals onto the
standard ones.
Examples of some possible transformations:
b
f ()()d
a
a
a
f ()()d
f ()()d
etc.
ba
1 f ()()d, using 1 2 ( a);
1
1
1 f ()()d, using a 1 ;
1
1
1 f ()()d, using a 1 ;
1
• transformation is done in such a way the resulting integral is
easier to compute;
• when possible to try to match the resulting weight function and
integration domain, so that available results can be easily used.
Quadrature for non-standard integrals
Example
1
Usinging a
we obtain
1
a
1 1 1 1
- f a
d.
2
1
2
1 (1 )
f ()d
This can be applied to a chance constraint as
p(u) Pr h(u) 0
h(u)
()d
1 1
1 1
p(u) - h(u)
d.
2
1
2
1 (1 )
The transformed integral can be computed using either Gauss-Legendre
or Gauss-Chebychev quadrature rule.
From Chance to Expected Value Constraint
Ref: Geletu et al: Monotony Analysis and Sparse-Grid Integration for nonlinear Chance Constrained Process Optimization
Example:
with
x (CA ,CB , rA , rB , R B ,T), u (Q, V, F), (CAi ,CBi ,Ti , k 0A , k 0B ) and
N(, 2 ).
Monotony relation CA R B
i
Pr R B R
min
B
Pr C
Ai
C
min
Ai
Cmin
Ai
u,x,
()d,
From Chance to Expected Value Constraint …
where
x CA , CB , rA , rB , R Bmin , T and 2 , 3 , 4 , 5 , 1 C Ai .
The inner integral
Cmin
Ai
u,x,
(1 , 2 , 3 , 4 , 5 )d1d2d4d5
can be transformed into
min
2z1
1 z1
f (u, x, ) : CAi u, x,
dz1
, 2 , 3 , 4 , 5
2
1
1 z1
(1 z1 )
1
using the change of variables
Pr R B R
min
B
Pr C
Ai
C
min
Ai
1 C
min
Ai
z1 1
u, x,
1 z1
= E f (u, x, ) .
f (u, x, )()d,
3. Multidimensional probability integrals
n
Problem: Given a (continuous) function f :
and a
non-negative weight function : n how to compute
the integral: I f f ()()d ?
In many practical applications the indefinite integral
I f
f ()()d
does not have analytic expression.
The domain of integration commonly has a product form
n
[a k , b k ] [a1 , b1 ] [a 2 , b 2 ]
k 1
[a n , b n ]
Multidimensional probability integrals …
Standard integration domains
Integration domain
Related probabilbility distribution
Uniform
[1,1]n
n
[1,1]
dis
Normal
(
, )-n unform
n
n
[0,1]
Drichlet
(, )n , Beta,
[0,1]
, [0, ) n
[0, ) n
Exponential, Gamma, Lognormal, Weibull
Note: Transform non-standard integrals into standard forms.
Example: Let
be a random variable w.r.t. the probability measure
such that d() ()d and
I f
f ()()d
n
| () 0 . Then
represents the expected value E f of f w.r.t. the probability
measure .
Multidimensional probability integrals …
Assumptions: (A1) The weight (probability density)
function (x) can be written as
n
, n ) k ( k ) product weight function;
() (1 , 2 ,
where k :
k 1
.
Assumption (A1) holds true if the 1 , 2 ,
, n are
independent random variables.
(A2) The domain of integration
1 2
Example:
() e
T
n ; where k , k 1,
n
e
k 1
and 1 2
2k
, with k ( k ) e
n (, ).
2k
, n.
Numerical method for multidimensional
Integrals
Two major approaches
Cubature Techniques (rules)
3.1. Full-Grid Integration Techniques
3.2. Sparse-Grid Integration Techniques
• Cubature techniques are constructed based on one
dimensional quadrature rules.
• One-dimensional interpolatory Gauss quadrature rules
(and their extensions) are found to be efficient, due to
their higher degree of accuracy.
Sampling based Techniques
will not be discusses here
(IIIA) Monte-Carlo (MC) Integration Techniques
(IIIB) Quasi-Monte-Carlo (QMC) Integration Techniques
• MC methods use randomly generated samples from .
• QMC methods use sequence of integration nodes from
lower discrepancy.
with
3.1. Full-Grid Cubature techniques
Suppose assumptions (A1) and (A2 ). Let for
Xk 1(k) , (k)
2 ,
w1(k) , w (k)
2 ,
, (k)
N k k
k 1, 2,
, n,
are quadrature nodes;
corresponding weights;
, w (k)
Nk
for the one-dimensional integral on
k
with the weight function
k .
A full-grid cubature rule to compute I[f]
Q f Q1(1) Q1(2)
N1 N 2
k1
k2
Nn
Q1(n) f
(2)
w (1)
w
k1
k2
(1)
(2)
w (n)
f
kn
k1
k2
(n)
kn
kn
is called full-grid tensor-product of one dimensional quadraturerules Q1(k) , k 1, , n; or product rule.
How good are full-grid cubature techniques?
Important questions:
How many grid-points are there in the full-grid cubature rule Q f ?
That is, the set
X X1 X 2
Xn
(2)
(1)
,
k1
k2 ,
(i)
, (n)
kn
k i Xi , k i 1,
, Ni ,i 1,
,n
Is it necessary to use all the grid points in X ? Is there redundancy in
the full-grid scheme?
What is the polynomial (or degree) of exactness of Q f ?
The number of grid-points (integration nodes) in Q f :
# X N1 N2
If
N1 N2
Nn .
Nn : N, then the number of grid points will be
# X Nn
exponential growth!!
Examples – full-grid Techniques
Example: For a 5-dimensional integral, a full-grid quadrature rule using
11-quadrature nodes in each dimension uses
# X N n 115 161051 cubature nodes.
• Q f requires large number of function evaluations even for
moderate dimensions;
• not efficient for problems of higher dimensions. In particular,
computationally expensive for stochastic optimization.
Example: Let f () cos
I f 2 cos
, () e
e
T
T
dx.
Q f Q1(1) Q1(2) f
7
7
k1
k2
(2)
(1)
(2)
w (1)
1.80818643195363.
k1 w k 2 f k1 k 2
7-Point 2D Full-grid nodes
Multidimensional polynomials and
exactness of cubature techniques
One measure of quality for a cubature rule is related with the largest
degree polynomial that it can integrate exactly.
For the variables 1 , 2 , , n a monomial of degree d in the
variables is an expression of the form
1 1
j
1
where
j1, j2 ,
1n
j
, jn
n
j
2
n
0
and j1 j2
jn d.
Example: For two variables 1 and 2
(a)the following are monomials of degree 3
1302 =13 , 12 12 , 1302 , 1 22 , 1032 =32
(b) all monomials in the two
variable of degree less equal to 3 are
degree
monomial
0
1
1
1 , 2
2
12 , 12 , 22
3
13 , 12 2 , 122 , 32
Multidimensional polynomials and
exactness of cubature techniques …
• The number of distinct monomials in n variables, degree less than
equal to d is equal to
n d n d !
n!d!
n
d
• A multidimensional polynomial p n (1 , 2 , , n ) of degree d in
the variables 1 , 2 , , n is a linear combination of monomials
of 1 , 2 , , n degree less or equal to d ; i.e.
p : span 1 1 1 j1 , j2 , , jn n0 , j1 j2 jn d
n d !
Hence, dim d
.
n
n!d!
Example:
(a)
32 =span 1, 1 , 2 , 12 , 12 , 22 , 12 2 , 1 22 , 13 , 32 .
d
n
d
n
j
1
j
2
j
n
(b)
a degree 2 polynomial: 21 2 2 51 22
a degree 3 polynomial:
1
1 2 3 21 33 .
3
Multidimensional polynomials and
exactness of cubature techniques …
Ref: Cools, R: Advances in multidimensional Integration.
A cubature rule Q f is said to be exact for a polynomial p dn if
1 2
n
That is,
pdn (1 ,
, n )()
w
N1 N 2
Nn
k1
kn
k2
(1)
k1
w (2)
k2
d
(1)
(2)
w (n)
p
kn
n
k1
k2
(n)
kn .
I pdn =Q pdn .
A cubature rule Q f is said to have a polynomial exactness (or
degree of accuracy) d if it is exact for all polynomials of degree
less than equal to d .
Multidimensional polynomials and
exactness of cubature techniques …
Ref: Cools, R: Advances in multidimensional Integration.
Theorem(Cools 2002). A cubature rule Q constructed as a
tensor-product of one-dimensional Gauss-quadrature rules:
Q Q1(1) Q1(2) Q1(n )
(k)
with degree of exactness of the quadrature rule Q1 equal to
2N k 1, k 1, , n; then the degree of exactness of Q is equal to
min 2N k 1.
1 k n
In particular, if N1 N 2 N n : N , then the degree of
exactness of Q will be equal to 2N 1.
Good Idea: Let f be an arbitrary function. For an accurate evaluation
of I f use a cubature rule with a higher degree of accuracy d . Iff
itself is a polynomial with degree less or equal to d , then
I f =Q f .
Multidimensional polynomials and
exactness of cubature techniques …
Fact: Higher accuracy in computing I f can be achieved by using a
cubature rule with higher degree of exactness.
Example: Consider a full-grid 2D cubaturer for the integral
I f 2 cos
Number of 1D quadrature
nodes
7
17
2
1
Cubature 2D
nodes
7 2 49
17 2 289
Almost equal result
from two full-grids
2
2
e
12 22
d1d 2 .
Q f
1.80818643195363
1.80818642926362
Redundancy in the full-grid integration
technique
Ref: Davis, P.J., Rabinowitz, P.: Methods of numerical integration.
The use 17 289 of Gauss-Hermite full-grid cubature nodes leads
to, too many function evaluations only with a little gain in accuracy.
• Redundancy in the full-grid cubature techniques.
n
• The use of N cubature nodes can lead the curse of dimensions.
2
Question: How many integration nodes are sufficient to obtain
a polynomial exactness d ?
Answer:
Theorem (Möller 1976, Mysovskikh 1968, Tchakaloff 1957) To attain a
polynomial exactness equal to d, the (optimal) required number of grid
points in Q[ ] has lower and upper bounds given by
N min
n d 2
n d
Required Number of Nodes
N max
n
n
N min - Known as Möller’s lower bound, while N max is Mysovskikh’s upper bound
(for unbounded ) or Tchakaloff upper bound (for bounded ).
Efficient cubature rules
a - represents the largest integer less than or equal to a;
3.4 3.
Definition (Davis & Rabinowitz) A cubature rule Q[ ] is said
to be efficient (optimal) if it uses
integration nodes.
Neff
1 n d
n
n
d
a -represents the smallest integer greater or equal to a;
eg.
3.4 4.
n
Now it is obvious that N N max , for large n.
How many of cubature nodes?
For a 10-dimensiona integral we find the following values
d
Number of nodes
(d=2N-1)
3
Full-Grid
Nodes
N min
Neff
N max
2
11
72
286
1024
5
3
66
501
3003
59049
7
4
286
2431
19448
1048576
9
5
1001
9238
92378
9765625
11
6
3003
29393
352716
60466176
13
7
8008
81719
1144066
282475249
15
8
19448
204298
3268760
1073741824
For the computation of a 10–dimensional probability integral,
using the full-grid technique with a degree of precision d=7,
requires 1,048,576 function evaluations.
Unafforable in the conext of stochastic optimization.
Construction of Efficient Cubature Rules
Ref: Smolyak, S.:Quadrature and interpolation formulas for tensor products of certain classes of functions.
Remark: The Theorems of Möller, Mysovskikh or Tchakaloff are
non-constructive.
Question: How to construct cubature rules with minimal number of
nodes; i.e. number of nodes near or equal to Neff ? If not, rules with
number of nodes lying between the bounds N min and N max ?
The construction of cubature techniques with minimum
number of integration nodes and higher polynomial exactness
is still a hot research topic!! In fact, construction of cubature
rules is partly an art as well as a science (Cools 1997).
In 1963 Smolyak gave a scheme for construction of cubature
techniques with number of nodes between N min and N max .
Leading to a class of cubature rules known as
Smolyak’s tensor-product integration rules or sparsegrid integration techniques.
3.2. Sparse-grid integration techniques
f ()()dx
Recall the integral I f
with assumptions (A1) and (A2).
Assumption(A3): For the sake of simplicity, we assume
1 2
n and 1 2 n .
The random variables 1 , 2 , , n are independent and
identically distributed.
In general, assumption (A3) is not required. Sparse-grid cubature
rules can be constructed for independent but non-identically
distributed random variables i j ,i, j 1, , n.
However, correlated variables need to be de-correlated (or
transformed ) for construction a sparse-grid integration rule.
Now, according assumption (A3), consider the same quadrature
rules on each k using k , so drop the index k .
Sparse-grid integration techniques…
Assumption(A4): For each one dimensional cubature rule on
there is a sequence of sets X 1 ,X 2 ,
of quadrature nodes
X i ,i 1, 2,
with #X #X ,i 1, 2,
i
i 1
(i)
(i)
X
,
1
2 ,
The 1D quadrature rule with nodes i
N
, (i)
Ni
,
is
(i)
Q1(i) w (i)
f
ki 1
ki
for f1 :
.
k i 1
• If the quadrature nodes in assumption (A4) satisfy the property that,
X i Xi 1 ,i 1, 2,
(i)
Q
Then corresponding sequence of quadrature rules 1 ,i 1, 2,
nested or embedded quadrature rules.
• Such sequence of quadrature rules can be constructed based on
Curtis-Clenshaw, Krnord/Patterson extension rules, etc .
is called a
Construction of sparse-grid integration rules
Let
i (i1 ,i 2 ,
,i n )
be a multi-index such that
n
i i1 i 2
in .
Smolyak 1963 (also Wasilkowski & Woznikowski 1995 ):
(i)
A sparse-grid rule based on the sequence of quadrature rules Q1 ,i 1, 2,
for the approximation of the n-dimensional integral I f with a degree of
accuracy d is
Sn,d f
where
Q
1
d n 1 i d
(ii1 )
Q
Ni1 Ni2
(ii2 )
=
for
d i
k i1 k i2
d n.
Q
w
Nin
k in
k i1
n 1 (ii1 )
(ii2 )
Q Q
d i
(iin )
Q
(iin )
f
w ki
2
w ki f ki , ki ,
n
1
2
, ki ,
n
f ,
Sparse-grid integration rules - Examples
• For n=2 and d=7, the sparse grid technique takes the form
S2,7 f
1
7 i
7 2 1 i 7
2 1 (ii1 )
(ii2 )
f
Q Q
7 i
Q(1) Q(5) [f ] Q(2) Q(4) [f ] Q(3) Q(3) [f ]
Q(5) Q(1) [f ] Q(4) Q(2) [f ]
+Q
[f ] Q
[f ] Q
[f ].
+ Q(1) Q(6) [f ] Q(2) Q(5) [f ] Q(3) Q(4) [f ]
(6)
Q(1)
(5)
Q(2)
(4)
Q(3)
Observe that
2 1
1, for (i1 ,i 2 )
7 (i1 i 2 )
2
and 6 i i1 i 2 7.
Sparse-grid integration rules - Examples
For n=2 and d=7, the sparse-grids are spread as follows:
Fig: S2,7
with 29 grid-points.
Properties Sparse-grid integration Techniques
• The set of all nodes in the sparse-grid rule Sn,d is
X n,d :
d n 1 i d
X
i1
Xi 2
Xi n .
• If the underlying quadrature rules are nested (embedded), then
X n,d X n,d 1.
This helps to easily estimate approximation error.
• The number of integration nodes in sparse-grid technique is
2d d
estimated by
#X n,d
d!
n .
The number of nodes has a polynomial dependence on
the dimension of the integral;
Sparse-grid rules need few integration nodes as
compared to full-grid techniques
For higher dimensional integrals (very large n) using
lower degree of precision d reduces number of function
evaluations.
Full-Grid vs. Sparse-Grid for
n
1 n
T 2
d
k e
2 k 1
Fig. Number of grid-points per dimension
Full-Grid vs. Sparse-Grid for
n
Fig. Computation time
1 n
T 2
d
k e
2 k 1
Sparse-grid techniques - polynomial exactness
Heiss & Winschel 2006: If each quadrature rule Q (i) has a
degree of exactness equal to 2i 1 , then the sparse-grid rule
Sn ,d
has a degree of exactness equal to
2d 1.
The degree of accuracy of the underlying one-dimensional
quadrature rules can be preserved in a higher dimensional
sparse-grid cubature rule.
Note, however, that in high dimensions (for very large n)
computing integrals with a lower degree of accuracy d is
preferable, in lieu of the formula:
#X n,d
2d d
n .
d!
Sparse-Grid Technique – error estimation
The sparse-grid cubature approximation of Sn,d [f ] of the
integral I[f ] has a good error estimate if the function f
posses a smoothness property.
If the function f and its (mixed partial) derivatives up to
of order r are continuous on , then f is said to have
smoothness of order r.
Example: The function
f (1 , 2 ) 2
2
1
has a smoothness order
r 2 on
5
2
2
.
Sparse-Grid Technique – Error estimation
Ref: Wasilkowski , Wozniakowski:Explicit cost bounds of algorithms of multivariate tensor product problems.
Wasilkowski & Wozniakowski 1995: The error for the
approximation of I[f ] by Sn,d [f ] is given by
I Sn,d O N r (log N)(n 1)(r 1)
where N is the number of nodes used in Sn,d [f ] .
Observe that error estimation depends heavily on the factor
Nr .
Sparse-grid cubature rules are good approximation of
multidimensional integrals if the integrand has a higher
order of smoothness r..
For integrands of lower order of smoothness, a good
sparse-grid approximation requires a large number N of
integration nodes.
Some remark on fully-symmetric cubature
rules
We known that Gauss-Hermite quadrature rules are not embedded
(nested).
Kronord or Patterson like extension of these rules may also lead to
negative quadrature weights (see Delaportas & Wright 1991).
A sparse-grid cubature constructed from pure Gauss-Hermite or
its extension can be inefficient.
Instead cubature rules can be constructed based on the symmetry
n
n
properties of the set (, )
and weight function
() e
T
.
Some Remark on Fully-symmetric cubature
rules
A set
n is fully symmetric if
(1 , 2 , , n ) (i1 , i2 , , in )
for all possible permutation (i1 ,i 2 ,
Example: the sets
symmetric.
,i n ) of the indices (1, 2,
, n).
(, )n and [1,1]n are fully-
Observe that
1 1 1 1 1 1 1 1 1 1 1 1
, , , , , , , , , , , ,
2 3 3 2 2 3 3 2 2 3 3 2
1 1 1 1
2
,
,
,
[
1,1]
.
2 3 3 2
Some Remarks on fully-symmetric cubature
rules
A weight function () is (centrally) symmetric if
(1 , 2 ,
, n ) (i1 , i2 ,
for all possible permutation (i1 ,i 2 ,
, in )
,i n ) of the indices (1, 2,
Example: the weight function () e
T
, n).
and
() 1 1 1 1 1 2 1 2 , for , -1;
are symmetric.
Stroud 1971 gives a list of fully-symmetric cubature nodes
and weights. (see also Lu & Darmofal 2004).
Among all fully-symmetric cubature rules, the one given by Genz &
Keister 1996 is found to be highly efficient for the computation
of integrals with Gaussian weight functions. These are found to
be sparse-grid rules with few number of nodes (Henriches & Novak
2008)
Advantages and Disadvantages of Sparse-Grid
Integration Techniques
Advantages
The number of nodes have a polynomial (instead of
exponential) dependence on the dimension of the integral;
Sparse-grid rules need few integration nodes as compared to
full-grid techniques
reducing function evaluations for probability integrals
For higher dimensional integrals (very large n) using lower
degree of precision d reduces number of function evaluations.
Integrals of polynomial functions can be computed exactly.
Sparse-grid integration – advantages,
disadvantages
Disadvantages :
Even if the underlying quadrature rules have non-negative
weights the sparse-grid cubature rule S n ,d can have negative
weights
the sparse-grid approximation of E f (u, ) may not be
convex w.r.t. u even if f ( , ) is a convex function of u.
(Convexity is vital in optimization. Convexity preserving sparsegrid techniques need further studies).
Sparse-grid integration techniques show poor performance or
may even provide wrong results if the integrand is discontinuous.
Also require intensive computation if the integrand has lower
order of smoothness.
In fact, for discontinuous integrands, Monte-Carlo or QuasiMonte-Carlo methods are highly preferable.
4. An application -exercise
Exercise: Suppose 1 , 2 , 3 are standard normal distributed
random variables.
max Pr u 1 u 3 0
u
2
2
2 2
subject to
0 u 2.
5. Conclusions
There is no single general technique for the numerical
computation of multidimensional integrals.
Stochastic optimization algorithms are highly dependent
on the evaluation of probability integrals. Efficient
techniques with a degree of accuracy in evaluating
integrals greatly reduce computation time.
Dimension-adaptive sparse-grid integration techniques
may provide better results.
Sparse-grid rules with positive weights are highly
demanding for probability integrals
Many fully- symmetric integration techniques use a few
nodes, but they are not computationally accurate.
Still there is a lot of work to be done!!
Resources
Resources for quadrature and sparse-grid integration techniques
Alan Genz :
http://www.math.wsu.edu/faculty/genz/software/software.html
Walter Gautschi:
http://www.cs.purdue.edu/archives/
John Burkardt :
http://people.sc.fsu.edu/~jburkardt/
Sparse Grid Interpolation Toolbox:
http://www.ians.uni-stuttgart.de/spinterp/
Quadrature on sparse grids:
http://sparse-grids.de/
References
A. Geletu, M. Klöppel, A. Hoffmann, P. Li, Monotony analysis and sparse-grid integration
for nonlinear chance constrained process optimization, Engineering Optimization, 2010.
Cools, R. Advances in multidimensional integration. J. Comput. Appl. Math.
149(2002) 1-12.
Davis, P. J.; Rabinowitz, P. Methods of numerical integration. Dover Publications, 2nd ed.,
2007.
Gander, M. J.; Karp, A. H. Stable computation of high order Gauss quadrature rules using
discretization for measures in radiation transfer. J. of Molecular Evolution, 53(4-5):47.
Gautschi, W. Orthogonal Polynomials: Computation and Approximation. Oxford University
Press, 2004.
Genez, A. Fully symmetric interpolatory rules for multiple integrals. SIAM J. Numer. Anal.,
23(1986), 1273 – 1283.
Genez, A.; Keister, B. D. Fully symmetric interpolatory rules for multiple integrals over
infinite regions with Gaussian weights. J. Comp. Appl. Math., 71(1996) 299 – 309.
Gerstner, T., Griebel, M. Numerical integration on sparse grids. Numerical Algorithms,
18(1998), 209 - 232.
G. H. Golub and J. H. Welsch, Calculation of Gauss Quadrature Rules, Math. Comp.,
23(1969), 221–230.
Heiss, F., Winschel, V. Esitimation with numerical integration on sparse grids. Münchner
Wirtschaftswissenschaftliche Beiträge(VWL), 2006-15.
References
Hinrichs, A.; Novak, E. Cubature formula for symmetric measures in high dimensions with
few points. Math. Comput. 76(2007) 1357 –1372.
Kronord, A. S. Nodes and weights of quadrature formulas. Consultants Bureau, New York,
1965.
Laurie, D. P. Calculation of Gauss-Kronord quadrature rules. Math. Comp. 66(1997) 1133 –
1145.
Lu, J.; Darmofal, D. L. Higher-dimensional integration with Gaussian weight for applications
in probabilistic design. SIAM J. Sci. Comput., 26(2004) 613 – 624.
Möller, H. M. Kubaturformeln mit minimaler Knotenzahl. Numer. Math. 25(1976) 185 – 200.
Mysovskikh, I. P. On the construction of cubature formulas with the smallest number of
nodes. Soviet Math. Dokl. 9(1968) 277 –280.
Patterson, T. N. L. The optimum addition of points to quadrature formulae. Math. Comp.
22(1968) 847 – 856. Errata: Math. Comp. 23(1969) 892.
Smolyak, S. A. Quadrature and interpolation formulas for tensor products of certain classes
of functions. Soviet Math. Dokl., 4(1963) 240 – 243.
Stroud, A. H. Approximate calculation of multiple integrals. Printc-Hall Inc., Englewood
Cliffs, N. J., 1971.
Trefethen, L. N. Is Gauss Better than Clenshaw-Curtis? SIAM Review 50(2008) 67 – 87.
Wasilkowski, G.W.; Woznikowski, H. Explicit cost bounds of algorithms for multivariate
tensor product problems. J. Complexity, 11(1995), 1 – 56.
References
Wendt, M., Li, P., Wozny, G. Nonlinear chance-constrained process optimization under
uncertainity. Ind. Eng. Chem. Res., 41(2002.), 3621 – 3629.
Many thanks for your attention !
Welcome to Ilmenau !