Mid-term Presentation
advertisement

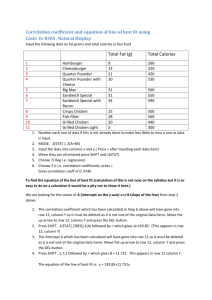
MATRIX MULTIPLY WITH DRYAD B649 Course Project Introduction Matrix Multiplication • Fundamental kernel algorithm used by many applications • Examples: Graph Theory, Physics, Electronics Scalability Issues: • Run on single machine: • Memory overhead increase in terms of N^2 • CPU overhead increase in terms of N^3 • Run on multiple machines: • Communication overhead increase in terms of N^2 memory overhead CPU overhead 1E+10 100000000 1000000 10000 100 0 500 1000 1500 Matrix Multiply Approaches Programming Mdoel Algorithm Customized Libraries User Implementation Sequential Naïve approach, tiles matrix multiply, Blas_dgemm Vendor supplied package (ie, Intel, AMD Blas), ATLAS Fortran, C, C++, C#, Java Shared memory parallelism Row Partition ATLAS Multi Threads, TPL, PLINQ, OpenMP Distributed memory parallelism Row Column Partition, Fox Algorithm ScalePack OpenMPI, Twister, Dryad Why DryadLINQ? • Dryad is a general purpose runtime that supports the processing of data intensive application in Windows • DryadLINQ is a high level programming language and compiler for Dryad • Applicability: • Dryad transparently deal with the parallelism, scheduling, fault. tolerance, messaging, and workload balancing issues. • SQL-like interface, based on .NET platform, easy to have code. • Performance: • Intelligent job execution engine, optimized execution plan. • Scale out for thousands of machines. Parallel Algorithms for Matrix Multiplication • MM algorithms can deal with matrices distributed on rectangular grids • No single algorithm always achieves best performance on different matrix and grid shapes. • MM Algorithms can be classified into categories according to the communication primitives • Row Partition • Row Column Partition • Fox Algorithm (BMR) – broadcast, multiply, roll up Row Partition • Heavy communication overhead • Large memory usage per node • The full Matrix B is copied to every node • The Matrix A row blocks are distributed to each node Pseudo Code sample: Partition matrix A by rows Broadcast matrix B Distributed matrix A row blocks Compute the matrix C row blocks Row Column Partition • Heavy communication overhead • Scheduling overhead for each iteration Column Block 1 Column Block 2 Column Block 3 ... Column Block n • Moderate memory usage 1 Row Block 1 Block (1,1) Block (1,2) Block (1,3) ... Block (1,n) 2 Row Block 2 Block (2,1) Block (2,2) Block (1,3) ... Block (2,n) 3 Row Block 3 Block (m,0) Block (m,1) Block (m,3) ... Block (m,n) … ... m Row Block m ... Block (m,n) B Matrix Pseudo Code sample: Partitioned matrix A by rows Partitioned matrix B by columns For each iteration i: broadcast matrix A row block i distributed matrix B column blocks compute matrix C row blocks Iterations A Matrix C Matrix ... Block (m,0) Block (m,1) Block (m,3) ... Node 1 Node 2 Node 3 Node n Fox Algorithm Stage One Stage Two Fox algorithm • Less communication overhead than other approach • Scale well for large matrices sizes Pseudo Code sample: Partitioned matrix A, B to blocks For each iteration i: 1) broadcast matrix A block (i%N, i%N) to row i 2) compute matrix C blocks add the to the previous result 3) roll-up matrix B block Performance Analysis on Fox algorithm Cache Size Turning Point Relative Parallel Efficiency • Cache Issue • Cache miss (size), pollution, confliction • Tiles matrix multiply • Memory Issue • Size (memory paging) • Bandwidth, latency OpenMPI/Threads/Cblas on 16 nodes 1.4 1.2 1 0.8 0.6 0.4 0.2 0 Grain Size Per Node 1node_8cores 16nodes_8cores • Absolute performance degrade as problem size increase for both cases • Single node performance worse than multiple nodes due to memory issue. 10^3Mflops 100 10 1 MPI/Threads/Cblas with Various Problem Sizes Multicore level parallelism • To use every core on a compute node for Dryad Job, the task must be programmed with multicore technology. (i.e. Task Parallel Library<TPL>, Thread, PLINQ) • For each thread, it will compute one row in matrix C or several rows in matrix C depends on the implementation. • By using TPL or PLINQ, the optimization for threads is implicit and easier to use. Timeline for term long project • Stage One • Familiar with HPC cluster • Sequential MM with C# • Multithreaded MM with C# • Performance comparison of above two approaches • Stage Two • Familiar with DryadLINQ Interface • Implement Row Partition algorithm with DryadLINQ • Performance study • Stage Three • Refinement experiments results • Report and presentation Backup slides Dryad Job Submission Client machine ToTable HPC Cluster DryadLINQ .NET program Query Expr Distributed query plan Invoke Query Vertex code JM foreach Output .Net Objects DryadTable (11) Results Input Tables Dryad Execution Output Tables Input: C# and LINQ data objects DryadLINQ distributed data objects. DryadLINQ translates LINQ programs into distributed Dryad computations: C# methods become code running on the vertices of a Dryad job. Output: DryadLINQ distributed data objects .Net objects Dryad Job Execution Flow Performance on one Node Performance on Multiple Node Analysis for three algorithms Performance for three algorithms • Test done on 16 nodes of Tempest, using one core per node. Performance for Multithreaded MM • Test done on one node of Tempest, 24 cores 25 20 Speed-up 15 10 5 TPL Thread PLINQ 0 2400 4800 7200 9600 12000 Scale of Square Matrix 14400 16800 19200