table interpolation - SI-35-02
advertisement

COMPARISON OF POPULATION PROPORTIONS
Given X1~BIN(n1, p1) and X2~BIN(n2, p2)
Statistics : ˆ X 1 ˆ X 2
p1 ; p2
n1
n2
Are defined to be the sample proportions.
E ( pˆ1 pˆ 2 ) E ( pˆ1 ) E ( pˆ 2 )
p1 p2
Assume, that X1 and X2 are independent;
Var ( pˆ1 pˆ 2 ) Var ( pˆ1 ) Var ( pˆ 2 )
p1 (1 p1 ) p2 (1 p2 )
n1
n2
For sufficiently large n1 and n2 the standardized statistic :
( pˆ 1 pˆ 2 ) ( p1 p2 )
p1 (1 p1 ) p2 (1 p2 )
n1
n2
The (1-α)100% CI :
p1 (1 p1 ) p2 (1 p2 )
( pˆ1 pˆ 2 )
z 2
n1
n2
As p1 and p2 UNKNOWN, approximate (1-α)100% CI
for (p1-p2) :
( pˆ1 pˆ 2 ) z 2
pˆ1 (1 pˆ1 ) pˆ 2 (1 pˆ 2 )
n1
n2
In the testing situation,
Ho : p1 = p2 = p ( p unknown )
Versus
H1
p1 p2
RR : Z z
Test statistic : Z
p1 p2
RR : Z z
los test
ˆ1 p
ˆ2
p
p (1 p )
p (1 p )
n1
n2
p1 p2
RR : Z z 2
X1 X 2
ˆ:
The unknown common value of p is estimated byp
n1 n2
EXAMPLE
Members of the Department of statistics at Iowa State Union
collected the following data on grades in an introductory
business statistics course and an introductory engineering
statistics course.
Course
B.Stat
E.Stat
Vs
#Students
571
156
Ho : p1=p2
#A grades
82
25
; The proportion of A grades
in two courses is equal.
H1 : p1≠p2
pˆ 1
82
0,1436
571
pˆ 2
25
0,1603
156
82 25
0,1472
571 156
0,1436 0,1603
Z
0,1472(0,8528)( 1
1 )
571 156
pˆ
Z 0,52
The p-value is 2P(Z≤-0,52) = 0,6030
If α= 5% < p-value
Ho would not be rejected
Proportion of A’s does not differ significantly in the two
courses.
EXERCISE
An insurance company is thinking about offering discount on
its life insurance policies to non smokers. As part of its
analysis, it randomly select 200 men who are 50 years old and
asks them if they smoke at least one pack of cigarettes per day
and if they have ever suffered from heart diseases. The results
indicate that 20 out of 80 smokers and 15 out of 120 non
smokers suffer from heart disease. Can we conclude at the 5%
los that smokers have a higher incidence of heart disease than
non smokers ?
Solution:
DATA
berumur 50th
perokok
menderita penyakit JANTUNG
parameter : p1
berumur 50th
bukan perokok
menderita penyakit JANTUNG
parameter : p2
Jelas Data Qualitative
H o : p1 p2 0 vs H1 : p1 p2 0
Test statistic :
z
ˆ1 p
ˆ2)
(p
1
1
ˆ qˆ (
p
)
n1
n2
RR : z z z0, 05 1,645.
ztab
Sample proportion : pˆ 1 20 0,25
80
; pˆ 2 15 0,125
120
20 15
35
0,175
Pooled proportion estimate : pˆ
80 120 200
Value of the test statistic:
zcal zhit
z=
ˆ 1 -p
ˆ2
p
(0,25-0,125)
=
1 1
1
1
ˆˆ
pq(
+ ) 0,175(0,825)( +
)
n1 n2
80 120
zcal 2,28 ztab reject H o
Test statistic, is normally distributed
We can calculate p-value
p-value = P ( z 2,28) 0,0113 1,13%
Reject Ho
SOAL-SOAL
1.
Diberikan pmf dari variabel random X sbb:
x
0 1 2 3
p(x) 0 k k 3k2
Tentukan k sehingga memenuhi sifat dari pmf!
Solusi: Ada dua sifat pmf, yaitu :
p ( x ) 0 x
p(x) 1
2
p
(
x
)
0
k
k
3
k
1
3k 2 2k 1 0
1
(3k 1)( k 1) 0 k , k 1
3
Untuk k 1 p(1) 1 0
p(2) 1 0
1
Dengan demikian k 1 tidak memenuhi. Selanjutnya untuk k
dapat diperiksa ternyata pada kondisi ini memenuhi sifat 3
pmf.
1
Jadi nilai k
3
In a public opinion survey, 60 out of a sample of 100 highincome voters and 40 out of a sample of 75 low-income
voters supported a decrease in sales tax.
(a) Can we conclude at the 5% los that the proportion of
voters favoring a sales tax decrease differs between high and
low-income voters?
(b) What is the p-value of this test?
(c) Estimate the difference in proportions, with 99%
confidence!
Solution:
vs
H o : ( p1 p2 ) 0
H1 : ( p1 p2 ) 0
RR : z 1,96
Test statistic : z
ˆ1 p
ˆ2)
(p
1
1
ˆ qˆ (
p
)
n1
n2
pˆ 1
pˆ
60
0,6
100
; pˆ 2
40
0,53
75
60 40 100
0,571
100 75 175
qˆ 1 pˆ 0,429
(0,60 0,53)
0,93
1
1
0,571(0,429)(
)
100 75
zcal
-1,96
0
1,96
(a) Conclusion : don not reject Ho
(b) p-value = 2P(z > 0,93) = 2(0,1762) = 0,3524.
(0,6)(0,4) (0,53)(0,47)
pˆ1qˆ1 pˆ 2 qˆ2
(c) ( pˆ pˆ ) z
(0,60 0,53) 2,575
1
2
2
n1
n2
0,07 0,195
100
75
The difference between the two-proportions is estimated to lie
between -0,125 and 0,265
TEST on MEANS WHEN THE OBSERVATIONS ARE PAIRED
TESTING THE PAIRED DIFFERENCES
Let (X1, Y1), (X2, Y2) … (Xn, Ym) be the n pairs, where (Xi, Yi)
denotes the systolic blood pressure of the i th subject before
and after the drug.
It is assumed that the differences D1, D2, …, Dn constitute
independent normally distributed RV such that:
EDi i and Var Di D2
H o : D o vs H1 : D o
D o
TEST STATISTIC:
T
SD n
1
Di and 2
2
S
(
D
D
)
D
i
D
n
1
n
Rejection criteria for testing hypotheses on means when the
observation are paired
Null hypothesis
H o : D o
Alternative hypothesis
Value test statistic under Ho
d o
t
sd
n
Rejection criteria
H1 : D o
Reject Ho when t t
or when t t1 2, n 1
H1 : D o
Reject Ho when t t1 , n 1
H1 : D o
Reject Ho when t
2, n 1
t ,n 1
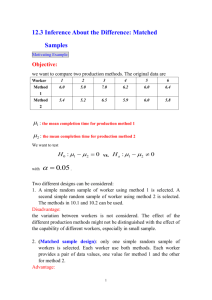
A paired difference experiment is conducted to compare the
starting salaries of male and female college graduates who find
jobs. Pairs are formed by choosing a male and female with the
same major and similar GRADE-POINT-AVERAGE. Suppose a
random sample of ten pairs is formed in this manner and
starting annual salary of each person is recorded. The result are
shown in table. Test to see whether there is evidence that the
mean starting salary, μ1 , for males exceeds the mean starting
salary, μ2, for female. Use α=0,05.
Pair
Male
Female
Difference (male-female)
1
$ 14.300
$13.800
$ 500
2
16.500
16.600
-100
3
15.400
14.800
600
4
13.500
13.500
0
5
18.500
17.600
900
6
12.800
13.000
-200
7
14.500
14.200
300
8
16.200
15.100
1.100
9
13.400
13.200
200
10
14.200
13.500
700
Solution: H o : D 0
vs
(1 2 0)
H1 : D 0
(1 2 0)
x o
Test statistic : t D
; xD d
s D nD
RR : reject Ho if : t > tα ;
d xD
D
i
t0.05,9=1,833
400
n
S D2 188.888,89 S D 434,61
T-distribution
with 9 dof
400
t
2,91
434,61 10
0 1,833
t
tcal falls in RR
Reject Ho at the
los=0,05
Starting salary for males
exceeds the starting salary for
females
Consider a classroom where the students are given a test before
they are taught the subject matter covered by the test. The
student’s score on this pre test are recorded as the first data set.
Next, the subject matter is presented to the class. After the
instruction is completed, the students are retested on the same
material. The scores on the second test, the post test, compose the
second data set. It is reasonable to expect that a student that
scored high on the pre test will also score high on the post
test(and vice versa). Inherently, a strong dependency exists
between the members of a pair of scores generated by each
individual.
Suppose that the scores in table, have been generated by 15
students under the conditions just described. How would you
decide whether the instruction had been effective?
A data set with paired scores
Student
Pre test
Post test
D
1
54
66
12
2
79
85
6
3
91
83
-8
4
75
88
13
5
68
93
25
6
43
40
-3
7
33
78
45
8
85
91
6
9
22
44
22
10
56
82
26
11
73
59
-14
12
63
81
18
13
29
64
35
14
75
83
8
15
87
81
-6
EX : Use the T statistic for the hypotheses
Ho : μ = 5
versus H1 : μ = 6
, which σ = 1
to compute :
a) β, if α = 0.05 and n = 16
b) α, if β = 0.025 and n = 16
c) n, if α = 0.05 and β = 0.025
Solution: Ho : μ = 5
vs H : μ = 6
1
μ = μo = 6
μ = μ1 > μo
Test Statistic : T ( X ) n
(a) P( X c 5) 0.05
X 5
c 5
P(
0.05
1
1
16
16
RR = { X > c}
P(T 4(c 5) 0.05
P(T t ) 0.05
t t15 1,753 , berarti
4(c 5) 1,753
c = 5.438
ˆ P(terima H o H1benar ) P( X c 6)
P(T 4(c 6) P(T 2.248)
Tidak ada dalam tabel t
JADI PAKAI INTERPOLASI
Umumnya, dipakai INTERPOLASI LINEAR
f ( x) a bx ; x1 x x2
x1 xo x2
f ( x2 ) f ( x1 )
f ( xo ) a bxo f ( x1 )
( xo x1 )
x2 x1
TABEL t
υ
1
2
3
.
.
.
15
0,10
0.05
0,20
0.10
One tail α
0.025 0.01
Two-tail α
0.05
0.02
1.341 1.753
2.131 2.602
2.248
0.005
0.001
0.01
0.002
f ( x2 ) f ( x1 )
f ( xo ) f ( x1 )
( xo x1 )
x2 x1
0.010 0.025
f ( xo ) 0.025
(0.117)
0.471
f ( xo ) 0.021
P(T 2.248) 0.021
(b) β = 0.025 ; n = 16
α=?
P( X c 6) 0.025
P(T 4(c 6) 0.025
P(T t ) 0.025
t 2.131
Jadi : 4(c-6) = -2,131
c = 5,467
P(tolak H o H obenar ) P( X c 5)
P(T 1.868 ) 0.042
TABLE INTERPOLATION
Suppose that it is desired to evaluate a function f(x) at a point xo ,
and that a table of values of f(x) is available for some, but not all,
values of x. In particular, the table may not give the value f(xo) but
may give values for f(x1) and f(x2) where x1< xo< x2 .
We can use the known values of f(x) for x = x1 , x2 to approximate the
value of f(xo) .
This process is known as INTERPOLATION. Perhaps the most
commonly used interpolation method is linear interpolation.
If f(x) is sufficiently smooth and not too curvilinear between x = x1
and x = x2 , calculus tells us that f(x) can be regarded as being nearly
linear over the interval [x1 , x2]
That is, f ( x) a bx ; x1 x x2
Solving the equations :
f ( x1 ) a bx1 ; f ( x2 ) a bx2
For a and b yields :
f ( x2 ) f ( x1 )
b
x2 x1
Hence :
f ( x2 ) f ( x1 )
a f ( x1 )
x
x
2
1
f ( x2 ) f ( x1 )
f ( xo ) a bxo f ( x1 )
( xo x1 )
x2 x1
f(x)
a+bx
f(x1)
f(xo)
f(x2)
x1
xo x2
1.
EXERCISE
Let (X1, X2, …, Xn) be a random sample of a normal RV X with
mean μ and variance 100. Let :
Ho : μ = 50
vs
H1 : μ = 55
As a decision test, we use the rule to accept Ho if x 53, where
x is the value of sample mean.
a) find RR
b) find α and β for n = 16.
2. Let (X1, X2, …, Xn) be a random sample of a Bernoulli R.V X with
pmf:
x
1 x
p X ( x; p) p (1 p)
; x 0,1
1
≤2
where it is know that 0 < p
.
Let : Ho : p = 1 vs H1 : p = p1 ( 1 )
2
2
and n = 20. As a decision test, we use the rule to reject Ho if
n
x
i 1
i
6
(a) Find the power function γ(p) of the test.
(b) Find α
1
1
(c) Find β : (i) if p1 and (ii) p2
4
Solutions :
2. Ho : p =
1
2
X~BER(p)
a)
vs
10
H1 : p = p1 (
1
)
2
x
p X ( x) p (1 p)1 x ; x 0,1
( p) P(reject H o p)
20 k
1
20 k
p (1 p) ; 0 p
2
k 0 k
6
1
2
1
2
b) P (reject H o p ) ( )
20 1 k 1 20k
1
( ) ( ) ; 0 p
2
2
k 0 k 2
6
Table
α=0.058
c)
( p) P(accept H o H1 is true)
1 P(reject H o p1 )
6
20 1 k 3 20k
1
( ) 1 ( ) ( )
0,2142
4
4
k 0 k 4
6
20 1 k 9 20 k
1
( ) 1 ( ) ( )
0,0024
10
10
k 0 k 10
Let (X1, X2, …, Xn) be a random sample of a normal RV X with
mean μ and variance 100. Let :
Ho : μ = 50
vs
H1 : μ = 55
As a decision test, we use the rule to accept Ho if x c . Find
the value of c and sample size n such that α =0.025 and β =
0.05.
Solution :
R1 : {( x1 , x2 ,..., xn ) : x c}
P(tolak H o H o benar ) P( X c 50)
c 50
P( Z
) 0.025
10
n
P( Z z ) 0.025
n= 52
c = 52.718
P( Z z ) 0.975
c 50
(
) 0.975
10 n
c 50
(
) 1.96 (c 50) n 19.60
10 n
P(terima H o H1 benar ) P( X c 55)
c 55
c 55
P(
) 0.05 (
) 0.05
10 n
10 n
(c 55) n
1.645 (c 55) n 16.45
10
3.92 3.29
(c 55)3.92 (c 50)3.29
c 50 c 55
3.29c 215.60 3.29c 164.50
380.10
7.21c 380.10 c
7.21
38010
c
52,7184466
721
c 52.718
(c 50) n 19.60
19.60 19.600 19600
n
7.211
2.718 2.718
2718
n 51.998 52
Let (X1, X2, …, Xn) be a random sample of a normal RV X with
mean μ and variance 36. Let :
Ho : μ = 50
vs H1 : μ = 55
As a decision test, we use the rule to accept Ho if x 53 , where
x is the value of sample mean.
a) Find the expression for the critical region/rejection region R1
b) Find α and β for n = 16.
Solution :
a) R1 : {( x1 , x2 ,..., xn ) : x
1 n
53} dimana x xi
n i 1
P( X 53 50) P(Z 2)
1 (2) 1 0.9772 0.0228
P(terima H o H1 benar ) P( X 53 55)
P( Z 1.333) (1.333)
1 (1.333)
x1
1.330
0.9082
1.330
xo
1.333
?
x1 < xo < x2
x2
1.340
0.9099
1.340
0.9099 0.9082
f (1.333) 0.9082
(1.333 1.330)
1.340 1.330
0.0017
0.9082
(0.003)
0.0100
f (1.333) 0.9082 0.00051 0.90871
1 (1.333)
1 0.90870 0.0913
0.0913