Hypertext Transfer Protocol
advertisement

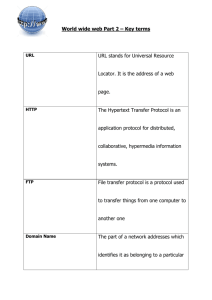
HTTP Hypertext Transport Protocol Hypertext Transfer Protocol (HTTP) Communications protocol Used to transfer or convey information on the World Wide Web Original purpose was to provide a way to publish and retrieve HTML hypertext pages Development of HTTP coordinated by: W3C (World Wide Web Consortium) IETF (Internet Engineering Task Force) Culminating in the publication of a series of RFCs Most notably RFC 2616 (June 1999) Defines HTTP/1.1 Version of HTTP in common use today Hypertext Transfer Protocol HTTP is a request/response protocol between clients and servers Client makes an HTTP request Referred to as the user agent Web browser, spider, or other end-user tool Server responds Called the origin server Stores or creates resources such as HTML files, images and programs In between the user agent and origin server may be several intermediaries Routers, proxies, gateways, tunnels, etc. Hypertext Transfer Protocol HTTP does not require the use of TCP/IP or its supporting layers Can be implemented on top of any other protocol on the Internet, or on other networks Only presumes a reliable transport Any protocol that provides such guarantees can be used Note: the rest of the lecture will implicitly assume TCP/IP Hypertext Transfer Protocol HTTP client initiates a request by establishing a Transmission Control Protocol (TCP) connection to a port on a host Port 80 by default HTTP server listening on that port waits for the client to send a request message Upon receiving the request, the server sends back: A status line E.g. "HTTP/1.1 200 OK“ A message of its own Body of which could be: The requested file An error message Some other information … Hypertext Transfer Protocol Resources to be accessed by HTTP are identified using: Uniform Resource Identifiers (URIs) Or, more specifically, URLs Using the http: or https: URI schemes URI/URL/URN SIDEBAR URI/URL/URN? Universal Resource Identifier (URI) String of characters used to identify a name or a resource on the Internet One can classify URIs as locators (URLs) names (URNs) —both— (rare) Uniform Resource Name (URN) Functions like an entity’s name Does not identify a specific entity Book’s ISBN functions as a URN ISBN: 978-0-07-154588-4 Linux Administration: A Beginner’s Guide 5th edition Uniform Resource Locator (URL) Resembles a person's street address Web addresses are URLs http://webpages.uncc.edu/~tkombol/index.htm Summary: URN defines an item's identity or label URL provides a method for finding a specific item Examples URN ISBN (International Standard Book Number) Uniquely identifies books Not a specific copy urn:isbn:0-486-27557-4 Unambiguously a specific edition of Shakespeare's play Romeo and Juliet ISAN (International Standard Audiovisual Number) Uniquely identifies films Root (base work), episode (for serial works), version urn:isan:0000-0000-9E59-0000-O-0000-0000-2 Identifies 2002 release of Spider-Man URL To gain access to this object and read the book, one needs its location: a URL address Typical URL for this book on a Unix-like operating system would be a file path: file:///home/username/RomeoAndJuliet.pdf Identifies the electronic book saved in a file on a local hard disk FTP URL template ftp://<user>:<password>@<host>:<port>/<url-path>;type=<typecode> URNs and URLs have complementary purposes BACK TO HTTP Request message Request message consists of the following: Request line What is needed to be done e.g. GET /images/logo.gif HTTP/1.1 Requests the file logo.gif from the /images directory Use HTTP 1.1 Headers Additional information to aid processing e.g. Accept-Language: en Empty line As many as needed Signals the end of the headers Message body Optional Request message Request line and headers must all end with CRLF Carriage return followed by a line feed ASCII Code 13 followed by ASCII Code 10 An empty line must consist of only CRLF and no other whitespace HTTP/1.1: all headers except Host are optional HTTP Methods HTTP defines eight methods Indicates the desired action to be performed on the identified resource Sometimes referred to as "verbs" Request Methods (the big 3) GET Requests the specified resource Most common method used on the Web today Data, e.g. parameters, (if any) sent as part of the URL Data (if present) is part of the URL Should not be used for operations that cause side-effects E.g. Changes the state of the server Using it for actions in web applications is a common misuse See 'safe methods' later POST Usually submits data to be processed by the identified resource Typically from an HTML form Data is part of the body of the request On the server this may result in: Creation of a new resource Updating of existing resources Or both HEAD Asks for the response identical to the one that would correspond to a GET request, but without the response body Useful for retrieving meta-information written in response headers, without having to transport the entire content Request methods (the rest) PUT Uploads a representation of the specified resource DELETE Deletes the specified resource TRACE Echoes back the received request Allows a client to see what intermediate servers are adding or changing in the request OPTIONS Returns the HTTP methods that the server supports Can be used to check the functions available on a web server CONNECT Converts the request connection to a transparent TCP/IP tunnel Usually to facilitate SSL-encrypted communication (HTTPS) through an unencrypted HTTP proxy Request methods HTTP servers should implement the following methods: GET HEAD OPTIONS Whenever possible Note POST is not required Request methods Safe methods Some methods are defined as safe e.g. HEAD or GET Intended only for information retrieval Should not change the state of the server In other words, they should not have side effects Unsafe methods should be displayed to the user in a special way e.g. POST, PUT and DELETE Typically as buttons rather than links Make the user aware of possible obligations Such as a button that causes a financial transaction Request methods Safe methods Despite the required safety of GET requests they can cause changes on the server For example: Web server may use the retrieval through a simple hyperlink to initiate deletion of a domain database record Thus causing a change of the server's state as a sideeffect of a GET request This is discouraged, because it can cause problems for: Web caching Search engines Other automated agents Can make unintended changes on the server Another case is that a GET request may cause the server to create a cache space Request methods Idempotent methods and Web Applications Idempotent: HTTP RFC allows a user-agent, such as a browser, to assume that any idempotent request can be retried without informing the user Multiple identical requests should have the same effect as a single request GET, HEAD, PUT, DELETE OPTIONS and TRACE, being safe, are inherently idempotent Done to improve the user experience when connecting to unresponsive or heavily-loaded web servers However, note: Idempotence is not assured by the protocol or web server It is perfectly possible to write a web application in which (e.g.) a database insert or update is triggered by a GET request This would be a very normal example of what the spec refers to as "a change in server state" This misuse of GET can combine with the retry behavior above to produce erroneous transactions and used, as intended, for document retrieval only For this reason GET should be avoided for anything transactional HTTP versions HTTP has evolved into multiple, mostly backwards-compatible protocol versions RFC 2145 describes the use of HTTP version numbers Client’s initial request reports its version Server responds in the same or earlier version HTTP versions 0.9 HTTP/1.0 (May 1996) Deprecated Supports only one command, GET — which does not specify the HTTP version Does not support headers Since this version does not support POST, the client can't pass much information to the server This is the first protocol revision to specify its version in communications Still in wide use, especially by proxy servers HTTP/1.1 (June 1999) Current version; persistent connections enabled by default and works well with proxies Supports request pipelining Allows multiple requests to be sent at the same time Allows the server to prepare for the workload and potentially transfer the requested resources more quickly to the client HTTP/1.2 or HTTP/2 The initial 1995 working drafts were prepared by the W3C and submitted to the IETF an Extension Mechanism for HTTP proposed the Protocol Extension Protocol, abbreviated PEP PEP was originally intended to become a distinguishing feature of HTTP/1.2 In later PEP working drafts, however, the reference to HTTP/1.2 was removed HTTP/2 is now documented in RFC 7540 (2015) Status lines HTTP/1.0 and later Status Line: First line of the HTTP response Includes: The way the user agent handles the response primarily depends on: 1. 2. Numeric status code (such as "404") Textual reason phrase (such as "Not Found") the code the response headers Custom status codes can be used If the user agent encounters a code it does not recognize Can use the first digit of the code to determine the general class of the response Status lines Standard reason phrases are only recommendations Can be replaced with "local equivalents" at the web developer's discretion If the status code indicated a problem User agent might display the reason phrase to the user to provide further information about the nature of the problem Standard also allows the user agent to attempt to interpret the reason phrase This might be unwise since the standard explicitly specifies that: Status codes are machine-readable Reason phrases are human-readable Status Code Groups 1xx Informational 2xx Success 3xx Redirection 4xx Client Error 5xx Server Error 1xx Informational Request received, continuing process This class of status code indicates a provisional response Consists only of the Status-Line and optional headers Terminated by an empty line HTTP/1.0 did not define any 1xx status codes Servers MUST NOT send a 1xx response to an HTTP/1.0 client except under experimental conditions 1xx Informational 100 Continue The server has received the request headers The client should proceed to send the request body in the case of a request for which a body needs to be sent for example, a POST request If the request body is large, sending it to a server when a request has already been rejected based upon inappropriate headers is inefficient To have a server check if the request could be accepted based on the request's headers alone, a client must send Expect: 100-continue as a header in its initial request see RFC 2616 §14.20: Expect header) Check if a 100 Continue status code is received in response before Continuing or receive 417 Expectation Failed and not continue 101 Switching Protocols 102 Processing (WebDAV) 2xx Success The action was successfully: Received Understood Accepted This class of status code indicates that the client's request was successfully received, understood, and accepted 2xx Success 200 OK Standard response for successful HTTP requests. 201 Created Request has been fulfilled and resulted in a new resource being created 202 Accepted Request has been accepted for processing Request might or might not eventually be acted upon The processing has not been completed It might be disallowed when processing actually takes place 203 Non-Authoritative Information (since HTTP/1.1) 204 No Content 205 Reset Content 206 Partial Content Notice that a file has been partially downloaded. Used by tools like wget to enable resuming of interrupted downloads, or split a download into multiple simultaneous streams. 207 Multi-Status (WebDAV) The message body that follows is an XML message and can contain a number of separate response codes, depending on how many sub-requests were made. 3xx Redirection The client must take additional action to complete the request This class of status code indicates that further action needs to be taken by the user agent in order to fulfill the request The action required MAY be carried out by the user agent without interaction with the user if and only if the method used in the second request is GET or HEAD A user agent SHOULD NOT automatically redirect a request more than 5 times, since such redirections usually indicate an infinite loop 3xx Redirection (1of 2) 300 Multiple Choices Indicates multiple options for the URI that the client may follow. Can be used to present different format options for video, list files with different extensions, or word sense disambiguation. 301 Moved Permanently This and all future requests should be directed to the given URI. 302 Found Most popular redirect code, but also an example of industrial practice contradicting the standard. HTTP/1.0 specification (RFC 1945) required the client to perform a temporary redirect (the original describing phrase was "Moved Temporarily"), but popular browsers implemented it as a 303 See Other. Therefore, HTTP/1.1 added status codes 303 and 307 to disambiguate between the two behaviors. However, the majority of Web applications and frameworks still use the 302 status code as if it were the 303. 303 See Other (since HTTP/1.1) The response to the request can be found under another URI using a GET method. 3xx Redirection (2of 2) 304 Not Modified Indicates the request URL has not been modified since last requested. Typically, the HTTP client provides a header like the If-Modified-Since header to provide a time with which to compare Utilizing this saves bandwidth and reprocessing on both the server and client. 305 Use Proxy (since HTTP/1.1) Many HTTP clients (such as Mozilla [1] and Internet Explorer) don't correctly handle responses with this status code, primarily for security reasons 306 Switch Proxy No longer used. 307 Temporary Redirect (since HTTP/1.1) In this occasion, the request should be repeated with another URI, but future requests can still be directed to the original URI. In contrast to 303, the request method should not be changed when reissuing the original request. For instance, a POST request must be repeated using another POST request 4xx Client Error The request contains bad syntax or cannot be fulfilled The 4xx class of status code is intended for cases in which the client seems to have erred Except when responding to a HEAD request, the server SHOULD include an entity containing an explanation of the error situation, and whether it is a temporary or permanent condition These status codes are applicable to any request method User agents SHOULD display any included entity to the user 4xx Client Error 400 Bad Request 401 Unauthorized Original intention to be used as part of a digital cash or micropayment scheme Has not happened, and this code has never been used 403 Forbidden Similar to 403, when authentication is possible but has failed or not been provided 402 Payment Required The request contains bad syntax or cannot be fulfilled Request was a legal request, but the server is refusing to respond to it Unlike a 401 Unauthorized response, authenticating will make no difference 404 Not Found 405 Method Not Allowed Request made to a URL using a request method not supported by that URL Using GET on a form which requires data to be presented via POST Using PUT on a read-only resource 406 Not Acceptable 407 Proxy Authentication Required 408 Request Timeout 409 Conflict 4xx Client Error 410 Gone Indicates that the resource requested is no longer available and will not be available again Should be used when a resource has been intentionally removed In practice, a 404 Not Found is often issued instead 411 Length Required 412 Precondition Failed 413 Request Entity Too Large 414 Request-URI Too Long 415 Unsupported Media Type 416 Requested Range Not Satisfiable 417 Expectation Failed 4xx Client Error 422 Unprocessable Entity (WebDAV) Request was well-formed but was unable to be followed due to semantic errors 423 Locked (WebDAV) The resource that is being accessed is locked 424 Failed Dependency (WebDAV) The request failed due to failure of a previous request (e.g. a PROPPATCH). 425 Unordered Collection Defined in drafts of WebDav Advanced Collections Not present in "Web Distributed Authoring and Versioning (WebDAV) Ordered Collections Protocol" 426 Upgrade Required The client should switch to TLS/1.0 (use https) 449 Retry With A Microsoft extension: The request should be retried after doing the appropriate action. 4xx examples Directory listing allowed (no file referenced) http://ajklinux1.uncc.edu/grades/ Not found or Forbidden? http://webpages.uncc.edu/~tkombol http://webpages.uncc.edu/~tkombol/ITIS2110/fileabc.htm Works – has index.html (Apache default) 404 - fileabc.htm does not exist Should be 403 – ITIS2110 is a dir, listing not allowed http://ajklinux1.uncc.edu/dir1/ Real 403 File found http://ajklinux1.uncc.edu/grades/grades.htm File not found http://ajklinux1.uncc.edu/grades/gradex.htm 5xx Server Error The server failed to fulfill an normally valid request Response status codes beginning with the digit "5" indicate cases in which the server is aware that it has erred or is incapable of performing the request Except when responding to a HEAD request, the server SHOULD include an entity containing an explanation of the error situation, and whether it is a temporary or permanent condition User agents SHOULD display any included entity to the user These response codes are applicable to any request method 5xx Server Error 500 Internal Server Error 501 Not Implemented 502 Bad Gateway 503 Service Temporarily Unavailable 504 Gateway Timeout 505 HTTP Version Not Supported 506 Variant Also Negotiates 507 Insufficient Storage (WebDAV) 509 Bandwidth Limit Exceeded Not an official HTTP status code Still used by many servers 510 Not Extended (RFC 2774) Persistent connections HTTP/0.9 and 1.0: the connection is closed after a single request/response pair HTTP/1.1: a keep-alive-mechanism was introduced A connection could be reused for more than one request Such persistent connections reduce lag perceptibly The client does not need to re-negotiate the TCP connection after the first request has been sent Version 1.1 of the protocol also introduced: Chunked transfer encoding HTTP pipelining Main Allows content on persistent connections to be streamed, rather than buffered Allows clients to send some types of requests before the previous response has been received, further reducing lag article: HTTP persistent connections HTTP session state HTTP is stateless Can pose problems for Web developers and applications The advantage of a stateless protocol is that hosts do not need to retain information about users between requests Forces use of alternative methods for maintaining users' state e.g. a host would like to customize content for a user who has visited before One common method for solving this problem involves the use of sending and requesting cookies Other methods include Server side sessions Hidden variables When current page is a form URL encoded parameters Such as /index.php?userid=3 Resume 2/29 HTTPS SECURE HTTP Secure HTTP Two methods of establishing a secure HTTP connection: HTTPS URI scheme HTTP 1.1 Upgrade header Introduced by RFC 2817 Browser support for the Upgrade header is nearly non-existent HTTPS URI scheme is the dominant method of establishing a secure HTTP connection Secure HTTP HTTPS URI scheme URI scheme syntactically identical to the http: scheme used for normal HTTP connections Signals the browser to use an added encryption layer of SSL/TLS to protect the traffic SSL – Secure Sockets Layer TLS – Transport Layer Security Main SSL is especially suited for HTTP since it can provide some protection even if only one side of the communication is authenticated In the case of HTTP transactions over the Internet, typically, only the server side is authenticated article: https Secure HTTP HTTP 1.1 Upgrade header HTTP 1.1 introduced support for the Upgrade header. In the exchange Client begins by making a clear-text request Later upgraded to TLS Either the client or the server may request (or demand) that the connection be upgraded The most common usage is a clear-text request by the client followed by a server demand to upgrade the connection, which looks like this: Client: GET /encrypted-area HTTP/1.1 Host: www.example.com Server: HTTP/1.1 426 Upgrade Required Upgrade: TLS/1.0, HTTP/1.1 Connection: Upgrade The server returns a 426 status-code because 400 level codes indicate a client failure Correctly alerts legacy clients that the failure was client-related Secure HTTP Benefits of using this method for establishing a secure connection are: Removes messy and problematic redirection and URL rewriting on the server side Allows virtual hosting (single IP, multiple domain-names) of secured websites Reduces user confusion by providing a single way to access a particular resource A weakness with this method is: Requirement for secure HTTP cannot be specified in the URI In practice, the (untrusted) server will thus be responsible for enabling secure HTTP, not the (trusted) client EXAMPLE Sample Following is a sample conversation between an HTTP client and an HTTP server running on www.example.com, port 80 Sample Client Request Client request (browser) url entered: http://www.example.com/index.html Generated the following http request: GET /index.html HTTP/1.1 Host: www.example.com <CRLF> GET followed by a blank line Request ends with a double newline Carriage return followed by a line feed The "Host" header Distinguishes between various DNS names sharing a single IP address Allows name-based virtual hosting Optional in HTTP/1.0, mandatory in HTTP/1.1 Sample Server Response HTTP/1.1 200 OK Date: Mon, 23 May 2005 22:38:34 GMT Server: Apache/1.3.27 (Unix) (Red-Hat/Linux) Last-Modified: Wed, 08 Jan 2003 23:11:55 GMT Etag: "3f80f-1b6-3e1cb03b" Accept-Ranges: bytes Content-Length: 438 Connection: close Content-Type: text/html; charset=UTF-8 Server response ETag (entity tag) Webserver publishes its ability to respond to requests for certain byte ranges of the document by setting the header Accept-Ranges: bytes Specifies the Internet media type of the data conveyed by the http message Content-Length indicates its length in bytes. Used to determine if the URL cached is identical to the requested URL on the server. Content-Type Followed by a blank line and text of the requested page Useful if the connection was interrupted before the data was completely transferred to the client Connection: close Webserver will close the TCP connection immediately after the transfer of this package. Which code response range indicates a server error? A. 1xx B. 2xx C. 3xx D. 4xx E. 5xx Has 30 second countdown 0% 5x x 0% 4x x 0% 3x x 0% 2x x 1x x 0% 30 Which code response indicates success: A. 101 B. 200 C. 302 D. 403 E. 404 F. 503 Has 30 second countdown 0% 50 3 0% 40 4 0% 40 3 0% 30 2 0% 20 0 10 1 0% 30