course note #3
advertisement

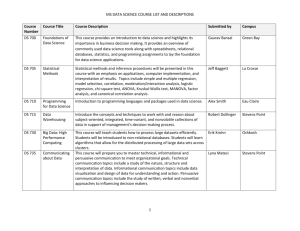
CSC 594 Topics in AI – Text Mining and Analytics Fall 2015/16 3. Word Association 1 What is Word Association? • Word association is a relation that exists between two words. • There are two types of relations: Paradigmatic and Syntagmatic. • Paradigmatic: A & B have paradigmatic relation if they can be substituted for each other (i.e., A & B are in the same class) – e.g. “cat” and “dog”; “Monday” and “Tuesday” • Syntagmatic: A & B have syntagmatic relation if they can be combined with each other (i.e., A & B are related semantically) – e.g. “cat” and “scratch”; “car” and “drive” • These two basic and complementary relations can be generalized to describe relations of any items in a language Coursera “Text Mining and Analytics”, ChengXiang Zhai 2 Why Mine Word Associations? • They are useful for improving accuracy of many NLP tasks – POS tagging, parsing, entity recognition, acronym expansion – Grammar learning • They are directly useful for many applications in text retrieval and mining – Text retrieval (e.g., use word associations to suggest a variation of a query) – Automatic construction of topic map for browsing: words as nodes and associations as edges – Compare and summarize opinions (e.g., what words are most strongly associated with “battery” in positive and negative reviews about iPhone 6, respectively?) Coursera “Text Mining and Analytics”, ChengXiang Zhai 3 Word Context Coursera “Text Mining and Analytics”, ChengXiang Zhai 4 Word Co-occurrence Coursera “Text Mining and Analytics”, ChengXiang Zhai 5 Mining Word Associations • Paradigmatic – Represent each word by its context – Compute context similarity – Words with high context similarity likely have paradigmatic relation • Syntagmatic – Count how many times two words occur together in a context (e.g., sentence or paragraph) – Compare their co-occurrences with their individual occurrences – Words with high co-occurrences but relatively low individual occurrences likely have syntagmatic relation • Paradigmatically related words tend to have syntagmatic relation with the same word joint discovery of the two relations • These ideas can be implemented in many different ways! Coursera “Text Mining and Analytics”, ChengXiang Zhai 6 Word Context as “Pseudo Document” Coursera “Text Mining and Analytics”, ChengXiang Zhai 7 Computing Similarity of Word Context Coursera “Text Mining and Analytics”, ChengXiang Zhai 8 Coursera “Text Mining and Analytics”, ChengXiang Zhai 9 Syntagmatic Relation – Word Collocation • Syntagmatic relation is word co-occurrence – called Collocation – If two words occur together in a context more often than chance, they are in the syntagmatic relation (i.e., related words). Coursera “Text Mining and Analytics”, ChengXiang Zhai 10 Word Probability • Word probability – how likely would a given word appear in a text/context? Coursera “Text Mining and Analytics”, ChengXiang Zhai 11 Binomial Distribution • Word (occurrence) probability is modeled by Binomial Distribution. Coursera “Text Mining and Analytics”, ChengXiang Zhai 12 Entropy as a Measure of Randomness • Entropy is a measure in Information Theory, and indicates purity or (un)even/skewed distribution -- a large entropy means the distribution is even/less skewed. • Entropy takes on a value [0, 1] (between 0 and 1 inclusive). • Entropy of a collection S with respect to the target attribute which takes on c number of values is calculated as: 𝑐 𝐸𝑛𝑡𝑟𝑜𝑝𝑦(𝑆) = −𝑝𝑖 ∙ log 2 𝑝𝑖 𝑖=1 • This is the average number of bits required to encode an instance in the dataset. • For a boolean classification, the entropy function yields: 𝐸𝑛𝑡𝑟𝑜𝑝𝑦(𝑋) = −p(X = 1) ∙ log 2 𝑃(𝑋 = 1) + p(X = 0) ∙ log 2 𝑃(𝑋 = 0) 13 Entropy for Word Probability Coursera “Text Mining and Analytics”, ChengXiang Zhai 14 Mutual Information (MI) as a Measure of Word Collocation • Mutual Information is a concept in probability theory, and indicates the two random variables' mutual dependence – or the reduction of entropy. • How much reduction in the entropy of X can we obtain by knowing Y? (where reduction give more predictability) 𝐼 𝑋; 𝑌 = 𝑦∈𝑌 𝑥∈𝑋 𝑝(𝑥, 𝑦) 𝑝(𝑥, 𝑦) ∙ log 𝑝(𝑥) ∙ 𝑝(𝑦) 𝑰 𝑿; 𝒀 = 𝑯 𝑿 − 𝑯 𝑿 𝒀 =𝑯 𝒀 −𝑯 𝒀 𝑿 15 Mutual Information (MI) and Word Collocation Coursera “Text Mining and Analytics”, ChengXiang Zhai 1616 Probabilities in MI Coursera “Text Mining and Analytics”, ChengXiang Zhai 1717 Estimation of Word Probability Coursera “Text Mining and Analytics”, ChengXiang Zhai 1818 Point-wise Mutual Information • Point-wise Mutual Information (PMI) is often used in place of MI. • PMI is a specific event of the two random variables. http://www.let.rug.nl/nerbonne/teach/rema-stats-meth-seminar/presentations/Suster-2011-MI-Coll.pdf 19 Other Word Collocation Measures • Likelihood Ratio (used in SAS Enterprise Miner) – • n is the number of documents that contain term B – • k is the number of documents containing both term A and term B – • p = k/n is the probability that term A occurs when term B occurs, assuming that they are independent of each other. Then the strength of association between the terms A and B, for a given r documents, is as follows (the inverse of the log likelihood of the probability of obtaining more successes than the k observed in a binomial distribution). 𝑆𝑡𝑟𝑒𝑛𝑔𝑡ℎ = log 𝑒 1 𝑃𝑟𝑜𝑏 𝑘 𝑛 𝑃𝑟𝑜𝑏𝑘 = 𝑟=𝑘 𝑛 𝑟 𝑝 (1 − 𝑝)(𝑛−𝑟) 𝑟 20 Conditional Counts: Concept Linking Centered term: a term that is chosen to investigate diabetes (63/63) +insulin (14/58) Concept linked term: a term that co-occurs with a centered term In this diagram, the centered term is diabetes, which occurred in 63 documents. The term insulin (and its stemmed variations) occurred in 58 documents, 14 of which also contained diabetes. The term diabetes occurs in 63 documents. continued... The term insulin and its variants occur in 58 documents, and 14 of those documents also contain the term diabetes. • Terms that are primary associates of insulin are secondary associates of diabetes.