Demystifying the Regression Coefficient: Rethinking a complex tool
advertisement

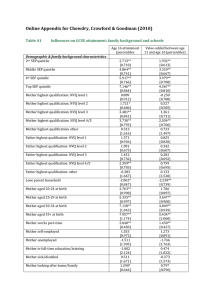
Jeffrey S. Napierala Prof. Glenn D. Deane Department of Sociology, SUNY Albany Prof. Donald J. Hernandez Department of Sociology, Hunter College & CUNY Graduate Center Research was supported by a Grant from the Annie E. Casey Foundation Please do not cite or distribute this research without consent from the Authors Outline The origins of this method An example using children's reading performance A “hybrid” approach Standard Errors Results Conclusions Origins The audience for policy research often has a diverse background in statistics. To accommodate those without any proficiency, the presentation must be simple and transparent. To satisfy those with advanced proficiency, current methods must be used. We want to have our cake and eat it too… Origins At one end of the spectrum: Sample means/proportions are simple and easy to understand …but may not clearly translate into effective policies… Towards the other end: A standard regression approach has obvious advantages, but results can be difficult to explain to general audiences. Origins Hernandez, Donald J. Double Jeopardy: How Third-Grade Reading Skills and Poverty Influence High School Graduation. Baltimore: Annie E. Casey Foundation An Example… Policy Question: How much would income transfers increase the percentage of (3rd Grade) students reading at the proficient level? Data: National Longitudinal Survey of Youth (NLSY) 4,060 children in 2369 families followed across about 30 years Dependent variable: Peabody Individual Achievement (PIAT) Reading Comprehension Test. Continuous variable ranging from 1-99. Methods: Weighted, linear GEE models with a correction for clustering within families. An Example: Model Specification Two models to highlight approach: 1. A “Base” model with just income and income squared predicting PIAT Reading Comprehension. 2. A “Full” model with controls for the 1) non-linear effect of mother’s education, 2) health insurance coverage, 3) whether a child attended head start or preschool, 4) the “quality” of their neighborhood, 5) race, 6) sex, and 7) year of interview. A “hybrid” Approach Let’s utilize the power of a regression, but keep the presentation as simple and flexible as possible. 1. Create a statistical model of the outcome. 2. “Simulate” new outcomes using the relevant parameters of the model. 3. Meaningfully summarize the distributions before and after the “simulation” using simple statistics/tabulations. 4. Compare the summary statistics/tabulations. A “hybrid” Approach: Standard Errors Using the common formula for the standard error of a proportion (with and without a Design Effect multiplier of 1.388). A Monte-Carlo approach to incorporate error from the sample regression and sample proportion. First, the effect(s) of covariates are added into the original score (the raw DV) by sampling from a normal distribution with a mean and s.d. from the regression. Rates (of reading proficiency) are computed then additional sampling error is introduced. After 5000 iterations, the S.E. of the distribution is computed from all the rates. A “hybrid” Approach: Standard Errors Also, to compare rates from the same group of children (before and after “simulations”) a “paired proportions” t-test is used (Altman 1997). Source: Altman, Douglas G. 1997. Practical Statistics for Medical Research. London: Chapman & Hall. Results… Predicted and Actual Values of PIAT Reading Score by Income 80 PIAT Reading Score 70 60 Sample Mean 50 40 "Base" Model 30 "Full" Model 20 10 $0 $2 $4 $6 $8 $10 Family Income in 10's of thousands $12 Results… 40000 35000 30000 25000 Sample Mean 20000 "Full" Model 15000 10000 5000 PIAT Scores 97.5 92.5 87.5 82.5 77.5 72.5 67.5 62.5 57.5 52.5 47.5 42.5 37.5 32.5 27.5 22.5 17.5 12.5 7.5 0 2.5 Number of Children (in 1,000's) Distribution of Low Income Children by PIAT Reading Score Results… Change in Number of Children (in 1,000's) Change in Distribution of Low Income Children by PIAT Reading Score after “Full” Model Simulation 20,000 15,000 10,000 5,000 0 -5,000 5 15 25 35 45 55 -10,000 -15,000 -20,000 -25,000 -30,000 PIAT Score 65 75 85 95 Results… Effect of Income on Reading Proficiency using Sample Means and Simulated Outcomes 50 Percent Reading Proficiently 45 40 35 30 25 20 15 10 1st Quintile 2nd Quintile 3rd Quintile 4th Quintile 5th Quintile 16.4 23.3 34.1 39.7 45.5 "Base" Model Simulation 23.4 30.0 36.6 42.7 "Full" Model Simulation 20.5 22.7 25.8 27.7 Sample Means Results… Standard Errors for Percent Reading Proficiently in 3rd Grade for Children in Poverty "Full" Model 1st Quintile 2nd Quintile 3rd Quintile 4th Quintile 5th Quintile Sample Percent 1.14 1.25 1.29 1.35 1.38 "Simulated" 1.15 1.27 1.31 1.40 1.40 Sample Percent w/ DEFT 1.58 1.73 1.80 1.88 1.92 "Simulated" w/ DEFT 1.58 1.75 1.82 1.89 1.91 Results… Difference Between Rates in "Full" Model Simulation Q2 - Q1 Q3-Q2 Q4-Q3 Q5-Q4 Difference 4.21 2.22 3.1 1.82 S.E. 0.62 0.45 0.54 0.41 S.E. w/ DEFT 0.86 0.63 0.74 0.57 Conclusions The “hybrid” approach has a few notable advantages over other methods… The independent effect of income on reading proficiency is much (much) less than might be expected from looking at bivariate or univariate results. We expect that about 4% (2.5-5.9; 95% C.I.) more kids in poverty would read proficiently if their families were given additional income to move them out of povery. Thank You! Email: jnapierala@albany.edu