Web Crawling
advertisement

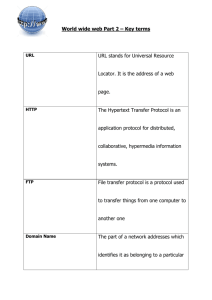
Web Crawling Next week • I am attending a meeting, Monday into Wednesday. I said I could go only if I can get back for class. • My flight is due in PHL at 5:22 pm. – That is really tight to be here by 6:15 – May we have a delayed start to class: 7:00? • If something bad happens and I will be later than that, I will let you know by e-mail or a post on blackboard. Web crawling – Why? • One form of gathering information. • We all know about information overload – Numbers are staggering – More is coming • The challenge of dealing with information, and data, will be with us for a long time. • There is more out there than we might immediately expect How much information is there? Soon most everything will be recorded and indexed Everything Recorded ! Most bytes will never be seen by humans. These require Data summarization, trend detection anomaly detection are key technologies algorithms, data and knowledge representation, and knowledge of the domain Yotta Zetta Exa All Books MultiMedia Peta All books (words) Tera A movie See also, Mike Lesk: How much information is there: http://www.lesk.com/mlesk/ksg97/ksg.html See Lyman & Varian: How much information http://www.sims.berkeley.edu/research/projects/how-much-info/ 24 Yecto, 21 zepto, 18 atto, 15 femto, 12 pico, 9 nano, 6 micro, 3 milli Slide source Jim Gray – Microsoft Research (modified) A Photo A Book Giga Mega Kilo Astronomy and Computing • The Large Synoptic Survey Telescope (LSST) Over 30 thousand gigabytes (30TB) of images will be generated every night during the decade-long LSST sky survey. LSST and Google share many of the same goals: organizing massive quantities of data and making it useful. http://lsst.org/lsst/google http://bits.blogs.nytimes.com/2012/04/16/daily-report-unanswered-questions-about-google/ Google and Information • From New York Times, April 16 2012 The Federal Communications Commission fined and censured Google for obstructing an inquiry into its Street View project, which had collected Internet communications from potentially millions of unknowing households as specially equipped cars drove slowly by. The data was a snapshot of what people were doing online at the moment the cars rolled by — e-mailing a lover, texting jokes to a buddy, balancing a checkbook, looking up an ailment. Google spent more than two years scooping up that information, from January 2008 to April 2010. "J. Trevor Hughes, president of the International Association of Privacy Professionals, said the Google case represented what happened when technical employees of technology companies made "innocent' decisions about collecting data that could infuriate consumers and in turn invite regulatory inquiry. "This is one of the most significant risks we see in the information age today," he said. "Project managers and software developers don't understand the sensitivity associated with data." Ocean Observatories NEPTUNE Canada ocean network is part of the Ocean Networks Canada (ONC) Observatory. Our network extends the Internet from the rocky coast to the deep abyss. We gather live data and video from instruments on the seafloor, making them freely available to the world, 24/7. http://www.neptunecanada.ca/ Live video from the seafloor, more than 2 KM deep OOI Data PolAll OOI data including data from OOI core sensors and all proposed sensors added by Principal Investigators, will be rapidly disseminated, open, and freely available (within constraints of national security). Rapidly disseminated implies that data will be made available as soon as technically feasible, but generally in near real-time, with latencies as small as seconds for the cabled components. In limited cases, individual PIs who have developed a data source that becomes part of the OOI network may request exclusive rights to the data for a period of no more than one year from the onset of the data stream. http://www.oceanobservatories.org/about/frequently-asked-questions/ Crawling – the how • Agenda for tonight –The web environment –An architecture for crawling –Issues of politeness –Some technical assistance First, What is Crawling A web crawler (aka a spider or a robot) is a program – Starts with one or more URL – the seed • Other URLs will be found in the pages pointed to by the seed URLs. They will be the starting point for further crawling – Uses the standard protocols for requesting a resource from a server • Requirements for respecting server policies • Politeness – Parses the resource obtained • Obtains additional URLs from the fetched page – Implements policies about duplicate content – Recognizes and eliminates duplicate or unwanted URLs – Adds found URLs to the queue and continues from the request to server step An exercise • Go to any URL you frequently use • If you used that as a starting point for a crawl, how many pages could you get to if your crawl depth is 3 – That is, you go to each link on the original page, each link pointed to by those first links, and then each link pointed to by the next set. • As always, work in groups of 2 or 3 • Report just the number of links found The Web Environment: Depth of the Web • A URL gives access to a web page. • That page may have links to other pages. • Some pages are generated only when information is provided through a form. – These pages cannot be discovered just by crawling. • The surface web is huge. • The deeper web is unfathomable. Anatomy of a URL • http://www.csc.villanova.edu/~cassel • That is a pointer to a web page. • Three parts – http – the protocol to use for retrieving the page • other protocols, such as ftp can be used instead – www.csc.villanova.edu -- the name of the domain • csc is a subdomain of the villanova domain – ~cassel • Abbreviation subdirectory html in the directory cassel at the machine associated with www.csc.villanova.edu • index.html is the default page to return if no other file is specified The major domain categories • Generic categories: – .net -- Originally restricted to major participants in maintaining the Internet. Now open. – .org -- Generally non profit organizations, including professional organizations such as acm.org – .com -- Commercial organizations such as amazon.com, etc. – .edu -- Restricted to higher education (post secondary) institutions. High schools and elementary schools are not allowed to use it. – .gov – Government organizations, such as nsf.gov – .mil – Military sites • Country Codes – – – – .us Example: http://www.dot.state.pa.us/ PA Dept of Transportation .it .uk Uses second level domains such as ac.uk or co.uk And other country designations. Who is .tv? Islands of Tuvalu • Newer ones: .biz, .name, etc. • All regulated by the Internet Assigned Numbers Authoriity (IANA) If not http:// then what? • Other protocols can be specified in the request to a server: – file:// local file on the current host – ftp:// use the ftp protocol to fetch the file – Etc. Domain categories • The domain categories serve to partition the universe of domain names. • Domain Name Servers (DNS) do lookup to translate a domain name to an IP address. • An IP address locates a particular machine and makes a communication path known. – Most common still: 32 bit IPv4 addresses – Newer: 128 bit IPv6 (note next slide) IPv6 note Accessible via IPv6 Total Percentage Web servers 453 1118 25.2% Mail servers 201 1118 11.1% DNS servers 1596 5815 27.4% Last Updated: Tue Apr 17 00:45:18 2012 UTC Source:http://www.mrp.net/IPv6_Survey.html Web servers • A server will typically have many programs running, several listening for network connections. – A port number (16 bits) identifies the specific process for the desired connection. – Default port for web connections: 80 – If other than 80, it must be specified in the URL Exercise: What is where? • Your project is running on a specific server at a specific port. • Can you find the exact “address” of your project? – Use nslookup from a unix prompt (msdos also?) – example nslookup monet.csc.villanova.edu returns Server: ns1.villanova.edu Address: 153.104.1.2 Name: monet.csc.villanova.edu Address: 153.104.202.173 Domain server Note, a local domain name server replied So the “phone number” of the apache server on monet is 153.104.202.173:80 Crawler features • A crawler must be – Robust: Survive spider traps. Websites that fool a spider into fetching large or limitless numbers of pages within the domain. • Some deliberate; some errors in site design – Polite: Crawlers can interfere with the normal operation of a web site. Servers have policies, both implicit and explicit, about the allowed frequency of visits by crawlers. Responsible crawlers obey these. Others become recognized and rejected outright. Ref: Manning Introduction to Information Retrieval Crawler features • A crawler should be – Distributed: able to execute on multiple systems – Scalable: The architecture should allow additional machines to be added as needed – Efficient: Performance is a significant issue if crawling a large web – Useful: Quality standards should determine which pages to fetch – Fresh: Keep the results up-to-date by crawling pages repeatedly in some organized schedule – Extensible: Modular, well crafter architecture allows the crawler to expand to handle new formats, protocols, etc. Ref: Manning Introduction to Information Retrieval Scale • A one month crawl of a billion pages requires fetching several hundred pages per second • It is easy to lose sight of the numbers when dealing with data sources on the scale of the Web. – 30 days * 24 hours/day * 60 minutes/hour * 60 seconds/minute = 2,592,000 seconds – 1,000,000,000 pages/2,592,000 seconds = 385.8 pages/second • Note that those numbers assume that the crawling is continuous Ref: Manning Introduction to Information Retrieval Google Search See http://video.google.com/videoplay?docid=1243280683715323550&hl=en# Marissa Mayer of Google on how a search happens at Google. Web Operation • Basic Client Server model – The http protocol • HyperText Transfer Protocol – Few simple commands that allow communication between the server and an application requesting something from the server – usually a browser, but not always. – Server • The site where the content resides. • Most of the web is served up by Apache and its byproducts. – Client • The program requesting something from the server. • Browsers most often, but also web crawlers and other applications. HTTP: GET and POST • GET <path> HTTP/<version> – Requests that the server send the specific page at <path> back to the requestor. – The version number allows compatible communication – Server sends header and the requested file (page). – Additional requests can follow. • POST – Similar to a GET but allows additional information to be sent to the server. – Useful for purchases or page edits. HEAD • HEAD <path> HTTP/<version> • Useful for checking whether a previously fetched web page has changed. • The request results in header information, but not the page itself. • Response: – – – – Confirm http version compatibility Date: Server: Last-Modified: Full set of HTTP commands • • • • • • • • CONNECT Command DISCONNECT Command GET Command POST Command HEAD Command LOAD RESPONSE_INFO BODY Command LOAD RESPONSE_INFO HEADER Command SYNCHRONIZE REQUESTS Command Search • Search engines, whether general engines like Google or Yahoo, or special purpose search engines in an application, do not crawl the web looking for results after receiving a query. – That would take much too long and provide unacceptable performance • Search engines actually search a carefully constructed database with indices created for efficiently locating content Architecture of a Search Engine Ref: Manning Introduction to Information Retrieval Crawling in Context • So, we see that crawling is just one step in a complex process of acquiring information from the Web to use in any application. • Usually, we will want to sort through the information we found to get the most relevant part for our use. So, the example of a search engine is relevant. Making a request of a server • Browsers display pages by sending a request to a web server and receiving the coded page as a response. • Protocol: HTTP – http://abc.com/filea.html … means use the http protocol to communicate with the server at the location abc.com and fetch the file named filea.html – the html extension tells the browser to interpret the file contents as html code and 30 display it. Programming Language Help • Programming languages influence the kinds of problems that can be addressed easily. • Most languages can be used to solve a broad category of problems – but are more closely attuned to some kinds of problems • An example, – Python is very well suited to text analysis and has features useful in web crawling 31 Python module for web access urllib2 – Note – this is for Python 2.x, not Python 3 • Python 3 splits the urllib2 materials over several modules – import urllib2 – urllib2.urlopen(url [,data][, timeout]) • Establish a link with the server identified in the url and send either a GET or POST request to retrieve the page. • The optional data field provides data to send to the server as part of the request. If the data field is present, the HTTP request used is POST instead of GET – Use to fetch content that is behind a form, perhaps a login page – If used, the data must be encoded properly for including in an HTTP request. See http://www.w3.org/TR/html4/interact/forms.html#h-17.13.4.1 • timeout defines time in seconds to be used for blocking operations such as the connection attempt. If it is not provided, the system wide 32 default value is used. http://docs.python.org/library/urllib2.html URL fetch and use • urlopen returns a file-like object with methods: – Same as for files: read(), readline(), fileno(), close() – New for this class: • info() – returns meta information about the document at the URL • getcode() – returns the HTTP status code sent with the response (ex: 200, 404) • geturl() – returns the URL of the page, which may be different from the URL requested if the server 33 redirected the request URL info • info() provides the header information that http returns when the HEAD request is used. • ex: >>> print mypage.info() Date: Mon, 12 Sep 2011 14:23:44 GMT Server: Apache/1.3.27 (Unix) Last-Modified: Tue, 02 Sep 2008 21:12:03 GMT ETag: "2f0d4-215f-48bdac23" Accept-Ranges: bytes Content-Length: 8543 Connection: close Content-Type: text/html 34 URL status and code >>> print mypage.getcode() 200 >>> print mypage.geturl() http://www.csc.villanova.edu/~cassel/ 35 Python crawl example import urllib2 url = raw_input("Enter the URL of the page to fetch: ") try: linecount=0 You almost certainly have a page=urllib2.urlopen(url) python interpreter on your result = page.getcode() machine. Copy and paste this if result == 200: and run it. Give it any url you for line in page: want. Look at the results. print line linecount+=1 print "Page Information \n ", page.info() print "Result code = ", page.getcode() print "Page contains ",linecount," lines." except: print "\nBad URL: ", url, "Did you include http:// ?" file: url-fetch-try.py in pythonwork/classexamples Basic Crawl Architecture DNS WWW Doc FP’s robots filters URL set Content seen? URL filter Dup URL elim Parse Fetch URL Frontier 37 Ref: Manning Introduction to Information Retrieval Crawler Architecture • Modules: – The URL frontier (the queue of URLs still to be fetched, or fetched again) – A DNS resolution module (The translation from a URL to a web server to talk to) – A fetch module (use http to retrieve the page) – A parsing module to extract text and links from the page – A duplicate elimination module to recognize links already seen 38 Ref: Manning Introduction to Information Retrieval Crawling threads • With so much space to explore, so many pages to process, a crawler will often consist of many threads, each of which cycles through the same set of steps we just saw. There may be multiple threads on one processor or threads may be distributed over many nodes in a distributed system. 39 • Not optional. • Explicit Politeness – Specified by the web site owner – What portions of the site may be crawled and what portions may not be crawled • robots.txt file • Implicit – If no restrictions are specified, still restrict how often you hit a single site. – You may have many URLs from the same site. Too much traffic can interfere with the site’s operation. Crawler hits are much faster than ordinary traffic – could overtax the server. (Constitutes a denial of service attack) Good web crawlers do not fetch multiple pages from the same server at one time. 40 Robots.txt Protocol nearly as old as the web See www.rototstxt.org/robotstxt.html File: URL/robots.txt • Contains the access restrictions – Example: All robots (spiders/crawlers) User-agent: * Disallow: /yoursite/temp/ Robot named searchengine only User-agent: searchengine Disallow: Nothing disallowed Source: www.robotstxt.org/wc/norobots.html 41 Another example User-agent: * Disallow: /cgi-bin/ Disallow: /tmp/ Disallow: /~joe/ 42 Processing robots.txt • First line: – User-agent – identifies to whom the instruction applies. * = everyone; otherwise, specific crawler name – Disallow: or Allow: provides path to exclude or include in robot access. • Once the robots.txt file is fetched from a site, it does not have to be fetched every time you return to the site. – Just takes time, and uses up hits on the server – Cache the robots.txt file for repeated reference 43 Robots <META> tag • robots.txt provides information about access to a directory. • A given file may have an html meta tag that directs robot behavior • A responsible crawler will check for that tag and obey its direction. • Ex: – <META NAME=“ROBOTS” CONTENT = “INDEX, NOFOLLOW”> – OPTIONS: INDEX, NOINDEX, FOLLOW, NOFOLLOW 44 See http://www.w3.org/TR/html401/appendix/notes.html#h-B.4.1.2 and http://www.robotstxt.org/meta.html Crawling • Pick a URL from the frontier • Fetch the document at the URL • Parse the URL Which one? – Extract links from it to other docs (URLs) • Check if URL has content already seen – If not, add to indices • For each extracted URL E.g., only crawl .edu, obey robots.txt, etc. – Ensure it passes certain URL filter tests – Check if it is already in the frontier (duplicate URL elimination) 45 Ref: Manning Introduction to Information Retrieval Recall: Basic Crawl Architecture DNS WWW Doc FP’s robots filters URL set Content seen? URL filter Dup URL elim Parse Fetch URL Frontier 46 Ref: Manning Introduction to Information Retrieval DNS – Domain Name Server • Internet service to resolve URLs into IP addresses • Distributed servers, some significant latency possible • OS implementations – DNS lookup is blocking – only one outstanding request at a time. • Solutions – DNS caching – Batch DNS resolver – collects requests and sends them out together 47 Ref: Manning Introduction to Information Retrieval Parsing • Fetched page contains – Embedded links to more pages – Actual content for use in the application • Extract the links – Relative link? Expand (normalize) – Seen before? Discard – New? • Meet criteria? Append to URL frontier • Does not meet criteria? Discard • Examine content 48 Content • Seen before? –How to tell? • Finger Print, Shingles –Documents identical, or similar –If already in the index, do not process it again 49 Ref: Manning Introduction to Information Retrieval Distributed crawler • For big crawls, – Many processes, each doing part of the job • Possibly on different nodes • Geographically distributed – How to distribute • Give each node a set of hosts to crawl • Use a hashing function to partition the set of hosts – How do these nodes communicate? • Need to have a common index 50 Ref: Manning Introduction to Information Retrieval Communication between nodes The output of the URL filter at each node is sent to the Duplicate URL Eliminator at all nodes DNS Doc FP’s robots filters To other hosts URL set WWW Parse Fetch Content seen? URL Frontier Ref: Manning Introduction to Information Retrieval URL filter Host splitter Dup URL elim From other hosts 51 URL Frontier • Two requirements – Politeness: do not go too often to the same site – Freshness: keep pages up to date • News sites, for example, change frequently • Conflicts – The two requirements may be directly in conflict with each other. • Complication – Fetching URLs embedded in a page will yield many URLs located on the same server. Delay fetching those. 52 Ref: Manning Introduction to Information Retrieval Some tools • WebSphinx – Visualize a crawl – Do some extraction of content from crawled pages • See http://www.cs.cmu.edu/~rcm/websphinx/ • and http://sourceforge.net/projects/websphinx/ • Short demonstration, if possible; screen shots as backup WebSphinx • Do a simple crawl: – Crawl: the subtree – Starting URLs: • Pick a favorite spot. Don’t all use the same one (Politeness) – – – – Action: none Press Start Watch the pattern of links emerging When crawl stops, click on the statistics tab. • • • • How many threads? How many links tested? , links in queue? How many pages visited? Pages/second? Note memory use 54 Advanced WebSphinx • Default is depth-first crawl • Now do an advanced crawl: – Advanced • Change Depth First to Breadth First • Compare statistics • Why is Breadth First memory intensive – Still in Advanced, choose Pages tab • Action: Highlight, choose color • URL *new* 55 Just in case … Crawl site: http://www.acm.org 56 From acm crawl of “new” 57 Using WebSphinx to capture • Action: extract • HTML tag expression: <img> • as HTML to <file name> – give the file name the extension html as this does not happen automatically – click the button with … to show where to save the file • on Pages: All Pages • Start • Example results: acm-images.html 58 What comes next • After crawling – A collection of materials – Possibly hundreds of thousands or more – How to find what you want when you want it • Now we have a traditional Information Retrieval problem – Build an index – Search – Evaluate for precision and recall • Major source: Manning, Christopher, et al. Introduction to Information Retrieval. version available at http://nlp.stanford.edu/IR-book/ • Many other web sites as cited in the slides