Note:158577.1 Subject: NLS_LANG Explained (How does Client
advertisement

Bookmark
Doc ID: Note:158577.1
Subject:NLS_LANG Explained (How
does Client-Server Character
Conversion Work?)
Type: BULLETIN
Status: PUBLISHED
Fixed font
Content
Type:
Creation
Date:
Last
Revision
Date:
Go to End
TEXT/PLAIN
24-SEP-2001
03-JUL-2003
Index of This Note:
------------------1.0 What is Oracle Globalization Support ?
1.1 What's the Purpose of This Document?
2.1 What is a Characterset or Code Page?
2.2 So Why Are There Different Charactersets?
2.3 What's the Difference Between 7 bit, 8 bit and Unicode
Charactersets?
3.1 Why Should I Convert?
3.2 A detailed example of a *wrong* nls setup to understand what's
going on.
3.3 How to see what's really stored in the database?
4.1 So What Should I Do?
4.1.1 Identify the characterset/codepage used by your clients.
4.1.2 Set the NLS_LANG on the client to the corresponding Oracle
characterset.
4.1.3 Create your database with a characterset that supports ALL
symbols used by
your various clients.
4.1.4 Set NLS_LANG on the server ALSO to the characterset used by the
OS
(terminal type) of the server.
4.2 How can I Check the Client's NLS_LANG Setting?
4.2.1 On Unix:
4.2.2 On Windows:
4.3 4.3 Where is the Character Conversion Done?
4.4 NLS_LANG default value and priority of NLS parameters:
5.1 My windows sqlplus is not showing all my extended characters.
5.2 I get an (inverted) question mark (¿ or ?) when selecting back
the just
inserted character.
5.3 What about sql*loader, import, export, my tool?
5.4 What about database links?
5.5 What about webclients (browsers) and webservers connecting to
Oracle?
5.6 What about Multiple Homes on Windows?
5.7 Is there an Oracle Unicode Client on Windows?
5.8 UTL_FILE is writing / reading incorrect characters.
5.9 Loading (XML) files as XMLtypes stores incorrect characters.
5.10 ODBC and NLS_LANG.
5.11 everything works except cut-and-paste from txt or word file to
sqlplus.
6.1 Things Not Covered in This Note:
6.2 Some Other Interesting Notes:
1.0 What is Oracle Globalization Support ?
------------------------------------------
Globalization support enables Oracle software to support different
languages and different national conventions in date and monetary
formatting.
It's also used to convert the charactersets of different clients
to the characterset of the database.
The name 'Globalization support' is the new name from Oracle9i
onwards
for 'National Language Support (NLS)'.
1.1 What's the Purpose of This Document?
----------------------------------------
To provide a basic understanding of what is going on if you set
NLS_LANG, how the conversion is done and how to set up a correct
configuration.
If you think or notice that you have problems with character
conversion
the please *do* go first of all through this note, so that you have
a good understanding what is a correct setup. If needed create a new
db and test.
If you understand this and then want to correct an existing
enviroment
go to:
[NOTE:225912.1] Changing the Database Character Set - an Overview
But *please* don't start changing you characterset without knowing
what you are
doing. And ALWAYS take a cold backup first.
If you have ANY doubt, test it on a backup of your enviroment.
2.1 What is a Characterset or Code Page?
----------------------------------------
A characterset is just an agreement on what numeric value a symbol
has.
A computer does not know ' A ' or ' ? ', it only knows the (binary)
numeric
value for that symbol, defined in the characterset used by its
Operating
System (OS) or in hardware (firmware) for terminals.
A computer can only manipulate numbers which is why there is a need
for
charactersets.
An example is 'ASCII', an old 7 bit characterset, 'ROMAN8' a 8 bit
characterset
on unix or 'UTF8' a multibyte characterset.
A code page is the name for the Windows/DOS encoding schemes,
for Oracle NLS you can consider it the same as a characterset.
You also have to distinguish between a FONT and a
characterset/codepage.
A font is used by the OS to convert a numeric value into a graphical
'print' on
screen.
The Windings Font on Windows is the best example of a font where an '
A ' is NOT
shown as an ' A ' on screen, but for the OS the numeric value
represents an ' A '.
So you don't SEE it as an ' A ', but for Windows it's an ' A ' and
will be saved (or
used) as an ' A '.
To better understand the above, just open MS Word, choose the
Windings Font,
type your name (you will see symbols) and save this as html, if you
open the html
file with Notepad you will see that in the <style> section the fonts
are declared
and lower in the <body> section you will find your name in plain text
but with
style='font-family:Wingdings' attribute. If you open it in Internet
Explorer or
Netscape, you will again see the Windings symbols. It's the
presentation that
changes, not the data itself.
It's also possible that you don't see with a particular font ALL the
symbols
defined in the codepage you are using, just because the creator of
the FONT did
not include a graphical representation for all the symbols in that
font.
That's why you get sometimes black squares on the screen if you
change fonts.
On Windows you can use the 'Character Map' tool to see all the
symbols defined
in a font (!font, not characterset!).
[NOTE:137127.1] for a more in-depth overview of this, highly
recommended!
Microsoft typography webpage:
http://www.microsoft.com/typography/default.asp
2.2 So Why Are There Different Charactersets?
---------------------------------------------
Two main reasons:
* Historically vendors have defined different 'sets' for their
hardware and
software, mainly because there were no official standards.
* New character sets have been defined to support new languages.
With an 8 bit characterset, you are limited in the number of
symbols you
can support so there are different sets for different written
languages.
2.3 What's the Difference Between 7 bit, 8 bit and Unicode
Charactersets?
------------------------------------------------------------------------
A 7 bit characterset only knows 128 symbols (2^7)
An 8 bit characterset knows 256 symbols (2^8)
Unicode (UTF8) is a multibyte characterset.
The latest version of the Unicode standard (3.1) defines 94,140
encoded characters.
Unicode has the capability to define over a million characters .
Oracle has several revisions of the Unicode standard implemented
during the
years:
AL24UTFFSS (unicode version 1.1) Introduced in V7 and now obselete.
UTF8 (unicode version 2.0) introduced in V8.
AL32UTF8 (unicode version 3.1) introduced in V9.
3.1 Why Should I Convert?
-------------------------
You can store data with the wrong setup, but that's up to you to take
the risk.
A common INCORRECT setup is storing 8 bit characters in a 7 bit
database.
This may render some tools or applications pretty useless at some
point,
not mentioning possible problems when upgrading Oracle.....
So a CORRECT NLS setup is really NEEDED.
3.2 A detailed example of a *wrong* nls setup to understand what's
going on:
--------------------------------------------------------------------------
You have created a database on your unix box with the US7ASCII
characterset.
Your Windows clients work with the MSWIN1252 characterset (regional
settings
-> western europe) and you, as dba, use the unix shell (ROMAN8) to
work
on the database. You set NLS_LANG to american_america.US7ASCII on the
clients
and the server.
(note: this is an INCORRECT setup to explain characterset conversion,
don't use it in your enviroment!)
a very important point:
When the client NLS_LANG characterset is set to the same value as the
database characterset, Oracle assumes that the data being sent or
received are
of the same encoding, so no conversions are performed. The data is
just stored
"as is", bit by bit....
Let's do something now:
You insert an ' é '(LATIN SMALL LETTER E WITH ACUTE ) into a table
ETEST
containing one column 'TEST' of the type 'char'.
As long as you insert into and select from the column on Windows NT
clients with
the MSWIN1252 characterset everything runs smoothly. No conversion is
done and
8 bits are inserted and read back, even if the characterset of the
database is
defined as 7 bits. This happens because a byte is 8 bit and Oracle is
ALWAYS
using 8 bits even with a 7 bit characterset. In a correct setup the
Most Significant Bit is just not used and only 7 bits are taken into
account.
For one reason or another you need to insert from the unix server.
When you select from tables where data is inserted by the Windows
clients
you get a ' Õ ' (LATIN CAPITAL LETTER O WITH TILDE) for the ' é '
instead of the ' é '.
If you insert ' é ' on the unix server and you select the row
inserted on the unix
at the Windows client you get an ' Å ' (LATIN CAPITAL LETTER A WITH
RING ABOVE)
back.
The thing is that you have INCORRECT data in the database.
You store the numeric value for ' é ' of the WIN1252 characterset in
the database
but you tell Oracle this is US7ASCII data, so Oracle is NOT
converting anything
and just stores the numeric value (again: Oracle thinks that the
client is giving
US7ASCII codes because the NLS_LANG is set to US7ASCII, and the
database
characterset is also US7ASCII -> no conversion done).
When you select the same column back on the unix server, oracle is
again
thinking that the value is correct (Oracle is thinking that the
terminal
understands US7ASCII) and passes the value to the unix terminal
without
any conversion.
Now the problem is that in the WIN1252 characterset the ' é' has the
hexadecimal
value 'E9' and in the Roman8 characterset the hexadecimal value for '
é ' is 'C5'.
Oracle just passes the value stored in the database ('E9') to the
unix terminal,
and the unix terminal thinks this is the letter ' Õ ' because in its
(Roman8)
characterset the hexadecimal value 'E9'is representing the letter ' Õ
'.
So instead of the ' é ' you get ' Õ ' on the unix terminal screen.
The inverse (the insert on the unix and the select on the Windows
client) is
just the same story, but you get other results.
The solution is creating database with a characterset that contains '
é '
(WE8MSWIN1252,WE8ISO89859P1, UTF-8, etc..) and setting the NLS_LANG
on client
to WE8MSWIN1252 and on the server to WE8ROMAN8.
If you then insert an ' é ' on both sides, you will get an
' é' back regardless of where you select them. Oracle knows then that
a
hexadecimal value of 'C5' inserted by the unix and a 'E9' from a
MSWIN1252
client are both ' é ' inserts ' é ' into the database (the code in
the database
depends on the characterset you have chosen).
The same problem appears if you add some Windows clients who are
using another
characterset and have an incorrect NLS_LANG set. You don't have to
switch
between unix, mainframe and Windows clients to run into this kind of
problem.
[NOTE:225938.1] Database Character Set Healthcheck
gives more info on how to check if you can change you database
characterset
without losing data, even if you have stored mswin1252 in an us7ascii
database
or so.
2 important remarks:
* The characterset defined with the NLS_LANG parameter does NOT
CHANGE
your client's characterset, it is used to let Oracle know what
characterset
you are USING on the client side, so Oracle can do the proper
conversion.
You cannot just set NLS_LANG to the characterset you WANT.
* Another myth is that if you don't set the NLS_LANG on the client
it uses the NLS_LANG of the server. This is also NOT true!
see the section "4.4 NLS_LANG default value" for this.
3.3 How to see what's really stored in the database?
---------------------------------------------------To find the real numeric value for a character stored in the
database is to use the dump command :
[NOTE:13854.1] Dump SQL Command for NLS Debugging
For a UTF8 database see also:
[NOTE:69518.1]
Determining the codepoint for UTF8 characters
4.1 So What Should I Do?
------------------------
To have a proper NLS environment you have to observe these steps:
4.1.1 Identify the characterset/codepage used by your clients.
--------------------------------------------------------------> contact your OS vendor (Microsoft, HP, Sun...) if you have
problems
with your OS configuration.
You may start with these sites and notes for your OS enviroment:
For Microsoft Windows platforms:
[NOTE:179133.1] The correct NLS_LANG in a Windows Environment
[NOTE:199926.1] How to change the ANSI Code Page (ACP) on Windows
http://www.microsoft.com/globaldev/reference/
(under the REFERENCE tab on the left of the page)
OEM = the command line codepage, ANSI = the gui codepage
For unix platforms, search your OS documenation for "LANG" and
"locale" as this
is differently implemented by each vendor.
For unix the characterset is also defined by the terminal
(emulation) used.
Generic FAQ for Unicode/UTF-8 on POSIX systems (Linux, Unix) by
Markus Kuhn
http://www.cl.cam.ac.uk/~mgk25/unicode.html
For Linux: (Li18NUX - Linux Internationalization Initiative)
http://www.li18nux.org
(Bruno Haible's Linux Unicode HOWTO)
ftp://ftp.ilog.fr/pub/Users/haible/utf8/Unicode-HOWTO.html
For Sun solaris: (Solaris 9 OE Globalization FAQ )
http://www.sun.com/developers/gadc/faq/sol9g11n.html
For Tru64: (section 4.2 of the System Administration Guide for
Tru64 UNIX Version 4.0F or higher)
http://www.tru64unix.compaq.com/docs/base_doc/DOCUMENTATION/V40F_HTML
/APS2RFTE/TITLE.HTM
For HP-UX: (hp-ux 9.x - 11i internationalization features white
paper)
http://docs.hp.com/hpux/pdf/5971-2270.pdf
For IBM AIX:(National Language Support Guide and Reference)
http://publib16.boulder.ibm.com/pseries/en_US/aixprggd/nlsgdrf/nlsgdr
f02.htm
For fujitsu-siemens (SINIX , Reliant UNIX and solaris on Siemens)
see:
http://manuals.fujitsu-siemens.com
For AS/400: (IBM publication National Language Support SC41-3101)
http://publib.boulder.ibm.com/cgibin/bookmgr/bookmgr.cmd/books/qbkawc00/CONTENTS?SHELF=&DT=19940609071
756
For the classic MacOS(v7-9) see:
http://developer.apple.com/techpubs/mac/Text/Text-30.html
http://developer.apple.com/techpubs/mac/Text/Text-516.html
Note that there are currently no supported versions for MacOS any
more.
For MacOS X:
http://developer.apple.com/techpubs/macosx/macosx.html
Note: 9i2 for MacOS X is no production release yet, just developer
release and so not yet
officially supported.
You can download it here:
http://technet.oracle.com/software/products/oracle9i/content.html
This might also be usefull:
http://www.macdevcenter.com/pub/a/mac/2003/01/03/oracle_part3.html?pa
ge=1
4.1.2 Set the NLS_LANG on the client to the corresponding Oracle
characterset.
-----------------------------------------------------------------------------
Use this note:
[NOTE:226492.1] Listing of Character Sets for 9.2, 9.0.1 and 8.1.7
including Language references
Or if you use windows clients:
[NOTE:179133.1] The correct NLS_LANG in a Windows Environment
*********************************************************************
****
It cannot be stressed enough that you need to set the NLS_LANG to
the characterset that your client is actually *using*.
Not to the characterset you *want* to use, if you need on your
client
another characterset (to display cyrillic or so) the you need to
see how
you can change the characterset of the client on OS level.
*********************************************************************
****
4.1.3 Create your database with a characterset that supports ALL
symbols used by
your various clients.
-------------------------------------------------------------------------------
Use locale builder (from 9i onwards) to view what characters are
defined:
[NOTE:223706.1] Using Locale Builder to view the definition of
character Sets
or use this note:
[NOTE:226492.1] Listing of Character Sets for 9.2, 9.0.1 and 8.1.7
including Language references
If you are thinking about using UTF8:
[NOTE:119119.1] UTF8 Database Character Set Implications
This select gives all the known charactersets for that release of
Oracle on that platform.
select unique VALUE from V$NLS_VALID_VALUES where PARAMETER
='CHARACTERSET';
You can create on Unix an database with a "Windows" characterset
like WE8MSWIN1252.
Oracle is not depending on the OS for the DATABASE (national)
characterset.
The only restriction is that you cannot use EBCDIC charactersets
(like used on AS400 ea)
on ASCII based platforms (like used on Unix and Windows) (or
inverse) for the
database characterset.
select * from nls_database_parameters where parameter like
'%CHARACTERSET%';
gives the current database (national) characterset.
All charactersets that Oracle implements are based on industry
standards,
see these web sites for more info about the contents of an
characterset:
http://www.unicode.org/
http://www.iso.org/
http://www.microsoft.com/globaldev/reference/
(under the REFERENCE tab on the left of the page)
4.1.4 Set NLS_LANG on the server ALSO to the characterset used by the
OS
(terminal type) of the server.
-----------------------------------------------------------------------
in fact the same as sections 4.1.1 and 4.1.2 ...
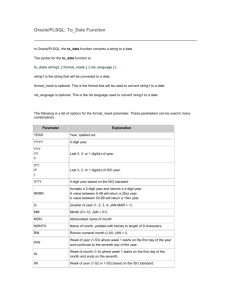
4.2 How can I Check the Client's NLS_LANG Setting?
--------------------------------------------------
To be 100% sure about the value used by the client, you can use these
methods
to get back the value of NLS_LANG:
4.2.1 On Unix:
--------------
sql>HOST ECHO $NLS_LANG
This returns the value of the parameter.
4.2.2 On Windows:
-----------------
On Windows NT you have two possible options, normally the NLS_LANG is
set in
the registry, but it can also be set in the environment, however this
is not
often done. The value in the environment takes precedence over the
value in
the registry and is used for ALL Oracle_Homes on the server(!).
Also note that any USER enviroment variable is taking precedence over
any SYSTEM enviroment variable (this is windows NT behaviour, nothing
to
do with Oracle) if set.
Please use the command line mode of sqlplus -> sqlplus.exe in a
command prompt.
To check if it's set in the environment:
sql>HOST ECHO %NLS_LANG%
If this reports just %NLS_LANG% back, the variable is not set in the
environment.
If it's set it reports something like
ENGLISH_UNITED KINGDOM.WE8ISO8859P1
If NLS_LANG is not set in the enviroment, check the value in the
registry:
sql>@.[%NLS_LANG%].
If you get something like:
unable to open file ".[ENGLISH_UNITED KINGDOM.WE8ISO8859P1]."
the "file name" between the '[]' is the value of the registry
parameter.
If you get this as result:
unable to open file ".[%NLS_LANG%]."
then the parameter NLS_LANG is also not set in the registry.
Note: the @.[%NLS_LANG%]. "trick" reports the NLS_LANG known by the
sqlplus
executable, it will not read the registry itself.
But then you are not sure if the variable is set in the enviroment or
in the
registry. That's the reason of checking with the host command first..
All other NLS parameters can be retrieved by a SELECT * FROM
NLS_SESSION_PARAMETERS;
See also [NOTE:241047.1] The Priority of NLS Parameters Explained.
note: SELECT USERENV ('language') FROM DUAL; gives the session's
<Language>_<territory>
but the DATABASE character set, so the characterset returned is
not
the client's complete NLS_LANG setting!
If you log a tar regarding an NLS issue please provide this
information:
[NOTE:226692.1] Finding out your NLS Setup.
4.3 Where is the Character Conversion Done?
-------------------------------------------
Normally the conversion is done at client side for performance
reasons.
This is true from Version 8.0.4 onwards.
If the database is using a characterset not known by the client
then the conversion is done at server side.
This is true from Version 8.1.6 onwards, if you are using pre-816
clients
please see:
[NOTE:70150.1] ALERT: Certain Character Sets Cause Client Code to
Fail
Note that there is a known problem with connecting with an V7 client
to an utf8 9.2
database. This will not fail with an error but any non-us7ascii
character will
be incorrectly stored.
There is no fix for this as this is an non-supported configuration.
4.4 NLS_LANG default value:
---------------------------
see
[NOTE:241047.1] The Priority of NLS Parameters Explained.
5.1 My windows sqlplus is not showing all my extended characters.
-----------------------------------------------------------------
You see black squares instead of the characters.
That's because sqlplusw.exe uses per default the Fixedsys font on
windows
and this font is not containing all characters, so it may have
problems
displaying some characters (the character is not defined in the font,
so windows cannot display it. note that the character is correctly
*stored* in the database)
To get around this see (from 8.1.7 onwards):
[NOTE:132453.1] How to Change the Displayed Font in SQL*Plus (GUI) on
WinNT.
Using 'Lucida Sans Unicode' should work for most cases.
Note that you don't need a "unicode" font, just a font that knows how
to
render all the characters you want to use, but with a unicode font
all chars
should be covered.
The same problem occurs with the dos version (sqlplus.exe), here
change
the properties of the dos box / cmd.exe / command prompt used.
Under the Font tab choose there Lucida Console.
As stated before you can see with the windows "Character Map" system
tool
what characters are known by a font.
5.2 I get an (inverted) question mark (? or ¿) when selecting back
the just
inserted character.
-------------------------------------------------------------------------This is most likly intended behavior, when your client send
characters to
the database and the character you are inserting is not *known* by
the
database characterset then Oracle stores a "replacement" character.
An example:
you have a arabian windows client (AR8MSWIN1256 codepage), so you set
your
NLS_LANG to ARABIC_BAHRAIN.AR8MSWIN1256 and you are connecting to an
database with an EE8MSWIN1250 database characterset.
Now, as long as you use ascii type characters or extended characters
like T
or é there is no problem, but if you insert an arabian character like
(ARABIC LETTER TEH , unicode code point 0x62b ) then you get an " ? "
because
Oracle cannot find a matching letter in the 1250 characterset.
" ? " is used in the microsoft/windows charactersets and " ¿ " in the
ISO
charactersets as replacement character.
It's also possible, but this less visible and not so common, that
Oracle is doing
a remapping to *another* character that resembles somwhat to the one
inserted:
a plain " e " for an
locale builder
" é " or so , but this you can check with
in the "Replacement Characters" tab for the characterset you are
using on
that database.
Of course, again, using an UTF8 database characterset solves all
this...
There is even a proposal to add Tolkiens Tengwar script to the
unicode
standard, not yet supported by Oracle ;-).
5.3 What about sql*loader, import, export, my tool?
---------------------------------------------------
Basicly it's always the same for any tool used to input data:
you have INPUT to a client:
* for sqlloader this is the txt/xls/html file you read.
* for import the dump file your read.
* for sqlplus is this you command line or GUI enviroment "driving"
your keyboard.
* for a Thick Jdbc (oci) driver the java program that calls it.
* for forms (windows runtime): [NOTE:105809.1] Character Set Support
for Developer Tools
* Web Forms 6i/9i is unicode enabled .
* etc
You have to set the character set part of the NLS_LANG to the
characterset of the INPUT telling Oracle what charterset you are
using
so the Oracle client can do the conversion.
For output, the same thing, if the tool you are using (like exp)
is capable of outputting the characterset wanted (!) you just
tell Oracle to convert it to that charset by setting the NLS_LANG
on the client.
5.4 What about database links?
------------------------------
The NLS_LANG on the server (or client) has no influence on
characterset
conversion trough a database link, Oracle will do the conversion
from the (national) characterset of the source database to the
(national) characterset of the target database (or inverse).
5.5 What about webclients (browsers) and webservers connecting to
Oracle?
------------------------------------------------------------------------
see [NOTE:229786.1]
NLS_LANG and webservers explained.
5.6 What about Multiple Homes on Windows?
-----------------------------------------
There is nothing special with NLS_LANG and the multiple homes on
Windows.
The parameter taken into account is the one specified in the
ORACLE_HOME
registry key used by the executable.
Again, if set in the environment, it takes precedence over the value
in
the registry and is used for ALL Oracle_Homes on the
server/client(!).
The NLS_LANG can be found in these registry keys:
HKEY_LOCAL_MACHINE\SOFTWARE\ORACLE
or
HKEY_LOCAL_MACHINE\SOFTWARE\ORACLE\HOMEx
See [NOTE:73963.1] Using multiple ORACLE HOMES on Windows platform
for more information
5.7 Is there an Oracle Unicode Client on Windows?
-------------------------------------------------
No, the gui of windows is not unicode, windows provide an API to the
unicode
layer of the OS (this is used by MS office 2000 / XP for example) but
Oracle
uses the "old" GUI API (like 99% of the windows programs).
IF you need to display unicode then you might want to use iSQL*PLUS
the browser based version of sqlplus..
See: [NOTE:231231.1] Quick setup of iSQL*Plus as unicode (UTF8)
client on windows.
5.8 UTL_FILE is writing / reading incorrect characters.
-------------------------------------------------------
See
[NOTE:227531.1] Character set conversion when using UTL_FILE
5.9 Loading (XML) files as XMLtypes stores incorrect characters.
----------------------------------------------------------------
See [NOTE:229291.1] XDB (xmltype) functionallity and NLS related
issues for 9.2
5.10 ODBC and NLS_LANG.
----------------------
See [NOTE:231953.1] ODBC and NLS Related Things to Know
5.11 everything works except cut-and-paste from txt or word file to
sqlplus:
---------------------------------------------------------------------------
See [NOTE:226558.1] An example inserting cyrillic data into a
database on west european windows.
for a live example en explenation what's happening when inserting
data from txt
or word files containing data in another code page than you are
normally using.
(that note uses cyrillic as example but you can easily use it for
other languages.)
6.1 Things Not Covered in This Note:
------------------------------------
NLS_SORT (see [NOTE:13978.1] and [NOTE:13882.1] for this)
NLS_TERRITORY, NLS_CURRENCY, and NLS_NUMERIC_CHARACTERS (see the
Globalization Manual)
NLS_DATE_FORMAT (see [NOTE:30557.1] for this)
The Euro (see [NOTE:68790.1] for this)
Export/import (see [NOTE:15095.1] for this)
6.2 Some Other Interesting Notes:
---------------------------------
[NOTE:60134.1]
NLS Frequently Asked Questions
[NOTE:152935.1] Alert: Warning of Change to Support of the EURO for
the 12 EMU Countries
[NOTE:226692.1] Finding out your NLS Setup.
[NOTE:241047.1] The Priority of NLS Parameters Explained.
[NOTE:132453.1] How to Change the Displayed Font in SQL*PLUS (GUI) on
WinNT
[NOTE:179133.1] The correct NLS_LANG in a Windows Environment
[NOTE:199926.1] How to change the ANSI Code Page (ACP) on Windows
[NOTE:231231.1] Quick setup of iSQL*Plus as unicode (UTF8) client on
windows.
[NOTE:69518.1]
Determining the codepoint for UTF8 characters
[NOTE:223706.1] Using Locale Builder to view the definition of
character sets
[NOTE:119119.1] UTF8 Database Character Set Implications
[NOTE:62107.1]
The National Character Set in Oracle8
[NOTE:225912.1] Changing the Database Character Set - an Overview
[NOTE:123670.1] Use Scanner Utility before Altering the Database
Character Set
[NOTE:225938.1] Database Character Set Healthcheck
[NOTE:66320.1] Changing the Database Character Set or the Database
National Character Set
[NOTE:137127.1] Character Sets, Code Pages, Fonts and the NLS_LANG
Value
[NOTE:13854.1]
Dump SQL Command for NLS Debugging
[NOTE:77442.1]
ORA_NLS (ORA_NLS32, ORA_NLS33) Environment Variables.
[NOTE:132090.1] How to get messages in your own language on MS
Windows platform?
[NOTE:115001.1] NLS_LANG Client Settings and JDBC Driver
[NOTE:131207.1] How to Set Unix Environment Variable
[NOTE:227531.1] Character set conversion when using UTL_FILE
[NOTE:229291.1] XDB ( xmltype ) functionallity and NLS related issues
for 9.2
[NOTE:231953.1] ODBC and NLS Related Things to Know
[NOTE:105809.1] Character Set Support for Developer Tools
additional information from Globalization Support:
http://otn.oracle.com/tech/globalization/content.html
and
http://otn.oracle.com/products/oracle8i/htdocs/faq_combined.htm
a Case study:
[NOTE:187739.1] NLS Setup in a Multilingual Database Environment
For further NLS / Globalization information you may start here:
[NOTE:150091.1] Globalization Technology (NLS) Library index
.
Bookmark
Doc ID: Note:231953.1
Fixed font
Content Type:
Go to End
TEXT/PLAIN
Subject:ODBC and NLS Related Things to
Know
Type: BULLETIN
Status: PUBLISHED
Creation Date:
Last Revision
Date:
10-MAR2003
19-MAR2003
PURPOSE
-------
Give a little overview of common NLS related cavevats with ODBC.
ODBC and NLS Related Things to Know:
------------------------------------
* From 8i drivers onwards it's NOT possible any more to
"disable" Characterset conversion by specifying for the NLS_LANG
the same characterset as the database characterset. There is now
ALWAYS a check to see if a codepoint is valid for that characterset.
Typically you will encounter problems if you upgrade an environment
that has NO NLS_LANG set on the client (or US7ASCII) and the database
was also US7ASCII. This *incorrect* setup allowed you to store characters
like éèç in an US7ASCII database, with the new 8i drivers this is not possible
any more. The solution is to correct your NLS setup as described in the notes:
[NOTE:158577.1] NLS_LANG Explained (How does Client-Server Character Conversion...
[NOTE:225912.1] Changing the Database Character Set - an Overview
and related...
* The NLS_LANG is for ODBC 8.1.7.2.0 and up now taken from the Oracle_Home
where the ODBC driver is installed, before ODBC 8.1.7.2.0 it was taken from
the default_home, even if this was NOT the home of that version
(so if you have a 734 and an 806 home on the same pc, then for the
806 ODBC the NLS_LANG of the 734 home is used, you can only have one ODBC
driver of this version installed...)
The ODBC installation now supports multiple Oracle homes.
Each installation of the ODBC driver will be uniquely identified by
the name of the Oracle home which it is installed under.
For example, if the name of the Oracle home is "OraHome81" the ODBC
driver will installed as "Oracle in OraHome81".
The Oracle ODBC driver use to always be installed as "Oracle ODBC Driver".
This list of installed ODBC drivers can be viewed from the ODBC Administrator
utility under the "Drivers" tab.
* A datasource configuration option to force SQLDescribeCol to return a
data type of SQL_WCHAR for SQL_CHAR columns, SQL_WVARCHAR for SQL_VARCHAR columns,
and SQL_WLONGVARCHAR for SQL_LONGVARCHAR columns has been added in ODBC 8.1.7.1.0
and up.
Enabling this option allows ADO applications to use Unicode.
ADO relies on the return value of SQLDescribeCol to determine how to bind the result
column.
Currently the Oracle ODBC driver would never return a data type of 'SQL_W' because
the database
does not support defining columns as type Unicode.
By default Force WCHAR Support is disabled.
Of course, you have to have an unicode database.
* The Oracle8 ODBC driver (ODBC 8.1.5.5.0 and up) now supports Unicode.
Unicode support is dependent on the Unicode features available through the
Oracle Call Interface (OCI). OCI 8.1.5 supports inputting Unicode data into
a database through SQLBindParameter and retrieving Unicode data from a database
through SQLBindCol or SQLGetData.
http://otn.oracle.com/docs/tech/windows/odbc/htdocs/817help/sqoraUnicode_Support.htm
* The installed CLIENT software is responsible for the characterset conversion,
so if you need support for the EURO symbol for example then you need to be shure
that the client version is supporting this.
Using a 806 odbc driver with an 805 client will NOT support euro symbol for example
as the 805 client NLS libraries have no support for EURO, use a 806 client here...
* See "How to write an ODBC Application to Support Unicode" on
http://technet.oracle.com/tech/globalization/content.html for some more info.
RELATED DOCUMENTS
-----------------
[NOTE:158577.1] NLS_LANG Explained (How does Client-Server Character Conversion
Work?)
[NOTE:179133.1] The correct NLS_LANG in a Windows Environment
[NOTE:225912.1] Changing the Database Character Set - an Overview
For further NLS / Globalization information you may start here:
[NOTE:150091.1] Globalization Technology (NLS) Library index
.
Bookmark
Doc ID: Note:179133.1
Subject:The correct NLS_LANG in a
Windows Environment
Type: BULLETIN
Status: PUBLISHED
Fixed font
Content
Type:
Creation
Date:
Last
Revision
Date:
Go to End
TEXT/PLAIN
07-MAR2002
13-JUN-2003
Content:
--------
1. Key concepts/terminology.
2. How to set up my NLS_LANG
3. The correct NLS_LANG for my Windows ANSI Code Page
4. The correct NLS_LANG for my DOS / Command Prompt OEM Code Page
5. How to check the NLS_LANG
6. List of common NLS_LANG to be set in Windows registry
7. List of common character sets to be used in a command prompt
8. How Windows uses Fonts to display the different charactersets
1. Key Concepts/terminology:
----------------------------
The intention of this note is to provide windows specific information
in addition of [NOTE:158577.1] NLS_LANG Explained (How does ClientServer
Character Conversion Work?).
Please read that note first to have an idea how NLS_LANG works.
1.1 Windows and Dos Code Pages:
-------------------------------
On Windows systems, the encoding scheme (=Characterset) is specified
by a Code Page.
Code Pages are defined to support specific languages or groups of
languages
which share common writing systems.
Usually, in non Chinese-Japanese-Korean environments, the Windows GUI
and
DOS command prompt do not use the same code page (!).
From Oracle point of view the terms Code Page and Characterset mean
the same.
1.2 Fonts:
----------
A font is a collection of glyphs (from "hieroglyphs") that share
common
appearances (typeface, character size). A font is used by the
operating system
to convert a numeric value into a graphical representation on screen.
A font does not necessarly contain a graphical representation for all
numeric
values defined in the code page you are using.
That's why you get sometimes black squares on the screen if you
change fonts and the new
that font has no representation for a certain symbol.
The Windows "Character Set Map" utility can be used to see which
glyphs are part
of a certain font.
On Windows 2000:
Start -> Programs -> Accessories -> System Tools -> Character Map
or
Start -> Run...
Type "charmap", and click "ok"
A font also implements a particular code page or set of code pages.
For example, the Arial font implements the code pages 1252, 1250,
1251, 1253,
1254, 1257.
For more in-depth info see point 8 in this note.
2. How to setup my NLS_LANG:
----------------------------
To specify the locale behaviour of your client Oracle software, you
have to set
your NLS_LANG parameter.
It sets the language, territory and also the character set of your
client.
For a short overview, it uses the following format:
NLS_LANG = LANGUAGE_TERRITORY.CHARACTERSET
where:
LANGUAGE specifies:
- language used for Oracle messages,
- day names and month names
TERRITORY specifies:
- monetary and numeric formats,
- territory and conventions for calculating week and day numbers
CHARACTERSET:
- controls the character set used by the client application
* or it matches your Windows code page
* or it set to UTF8 for an unicode application
The list of supported character sets,languages and territory
can also be found in the Oracle9i Globalization Support Guide,
Appendix A, Locale Data
Available online at the following URL:
http://otn.oracle.com/pls/db92/db92.docindex?remark=homepage
The NLS_LANG parameter is never inherited from the server.
Please also see: [NOTE:241047.1] The Priority of NLS Parameters
Explained.
2.1 In the Registry:
--------------------
On Windows systems, you should make sure that you have set an
NLS_LANG registry
subkey for each of your Oracle Homes:
You can easily modify this subkey with the Windows Registry Editor:
Start -> Run...
Type "regedit", and click "ok"
Edit the following registry entry:
HKEY_LOCAL_MACHINE\SOFTWARE\ORACLE\HOMExx\
where "xx" is the unique number identifying the Oracle home.
There you have an entry with as name NLS_LANG
When starting an Oracle tools, like sqlplusw, it will read the
content of
the oracle.key file located in the same directory to determine which
registry
tree will be used, therefore which NLS_LANG subkey will be used.
2.2 As a System or User Environment Variable, in System properties:
-------------------------------------------------------------------
Although the Registry is the primary repository for settings on
Windows, it is
not the only place where parameters can be set.
Even if not at all recommended, you can set the NLS_LANG as a System
or User
Environment Variable in the System properties.
This setting will be used for ALL Oracle homes.
To check and modify them:
Right-click the 'My Computer' icon -> 'Properties'
Select the 'Advanced' Tab -> Click on 'Environment Variables'
The 'User Variables' list contains the settings for the specific OS
user
currently logged on and the 'System variables' system-wide variables
for all users.
Since these environment variables take precedence of the parameters
already set
in your Registry, you should not set Oracle parameters at this
location unless you
have a very good reason.
Particularly note the "ORACLE_HOME" parameter that is set on unix but
NOT on windows.
2.3 As an Environment variable defined in the command prompt:
-------------------------------------------------------------
If you set the NLS_LANG as an environment variable in a Command
prompt,
be aware that it will overrite the current NLS_LANG setting in the
Registry
and also the System Properties.
In an MS-DOS command prompt, use the set command, for example:
C:\> set NLS_LANG=american_america.WE8PC850
3. The correct NLS_LANG for my Windows ANSI Code Page:
------------------------------------------------------
3.1 Determine your Windows ANSI code page:
------------------------------------------
The ACP (Ansi Code Page) is defined by the "default locale" setting
of windows,
so if you have a UK Windows 2000 client and you want to input
cyrillic (russian)
you need to change the ACP (by changing the "default locale") in
order to be
able to input russian.
see [NOTE:199926.1] How to change the ANSI Code Page (ACP) on
Windows.
You'll find its value in the registry:
Start -> Run...
Type "regedit", and click "ok"
Browse the following registry entry:
HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\Nls\CodePage\
There you have (all the way below) an entry with as name ACP
The value of ACP is your current GUI Codepage, see the table in
point 3.2
for the mapping to the oracle name.
Since there are many registry entries with very similar names, please
make sure that you are looking at the right place in the registry.
Again, if you need to change the "ACP" please see:
[NOTE:199926.1] How to change the ANSI Code Page (ACP) on Windows
Do NOT simply change it in the registry.
Additionally, the following URL provides a list of the default code
pages
for all Windows versions:
http://www.microsoft.com/globaldev/reference/
(under the REFERENCE tab on the left of the page)
OEM = the command line codepage, ANSI = the gui codepage
3.2 Find the correspondent Oracle client character set:
-------------------------------------------------------
Find the Oracle client character set in the table below based
on the ACP you found in point 3.1.
Note that there is only ONE CORRECT value for a given ACP
ANSI CodePage (ACP)
NLS_LANG)
Oracle Client character set (3rd part of
1250
EE8MSWIN1250
1251
CL8MSWIN1251
1252
WE8MSWIN1252
1253
EL8MSWIN1253
1254
TR8MSWIN1254
1255
IW8MSWIN1255
1256
AR8MSWIN1256
1257
BLT8MSWIN1257
1258
VN8MSWIN1258
874
TH8TISASCII
932
JA16SJIS
936
ZHS16GBK
949
KO16MSWIN949
950
ZHT16MSWIN950
others
UTF8
You can use UTF8 as Oracle client character set on Windows NT, 2000
and XP but
you will be limited to use only client programs that explicitly
support this
configuration.
This is because the user interface of Win32 is not UTF8, therefore
the client
programs have to perform explicit conversions between UTF8 (used on
Oracle
side) and UTF16 (used on Win32 side).
An example of such a program is Oracle Forms in version 5 and later
on NT 4.0.
[NOTE:105809.1] Character Set Support for Developer Tools
or iSQLplus (from 817 onwards).
see [NOTE:231231.1] Quick setup of iSQL*Plus as unicode (UTF8) client
on windows.
From the other side, programs relying on ANSI Win32 API, like
SQL*Plus,
older Oracle Forms , etc. cannot work with an NLS_LANG set to UTF8.
For Export / Import please see:
[NOTE:227332.1] NLS considerations in Import/Export
3.3 Set it in your Registry:
----------------------------
Use the Windows Registry Editor to set up the NLS_LANG in your Oracle
Home
with the value you have just find above.
Section 2.1 gives you more details on how to use the Registry Editor
for that
purpose.
4. The correct NLS_LANG for my DOS / Command Prompt OEM Code Page:
------------------------------------------------------------------
MS-DOS mode uses, with a few exceptions like CJK, a different code
page
(called OEM code page) than Windows GUI (ANSI code page).
Meaning that before using an Oracle command line tool such as
SQL*Plus
(sqlplus.exe/ plus80.exe / plus33.exe ) en svrmgrl in a command
prompt
then you need to MANUALLY SET the NLS_LANG parameter as an
environment
variable with the set DOS command BEFORE using the tool.
For Japanese, Korean, Simplified Chinese, and Traditional Chinese,
the MS-DOS OEM code page (CJK) is identical to the ANSI code page
meaning that,
in this particular case, there is no need to set the NLS_LANG
parameter in
MS-DOS mode.
In all other cases, you need to set it in order to overwrite the
NLS_LANG
registry key already matching the ANSI code page. The new "MS-DOS
dedicated"
NLS_LANG needs to match the MS-DOS OEM code page that could be
retrieved by
typing chcp in a Command Prompt:
C:\> chcp
Active code page: 437
C:\> set NLS_LANG=american_america.US8PC437
If the NLS_LANG parameter for the MS-DOS mode session is not set
appropriately,
error messages and data can be corrupted due to incorrect character
set
conversion.
Use the following list to find the Oracle character set that fits to
your MS-DOS
code page in use on your locale system:
MS-DOS code page
NLS_LANG)
Oracle Client character set (3rd part of
437
US8PC437
737
EL8PC737
850
WE8PC850
852
EE8PC852
857
TR8PC857
858
WE8PC858
861
IS8PC861
865
N8PC865
866
RU8PC866
For tools like sqlloader you need to set the NLS_LANG
to the characterset of the FILE you loading.
For Export / Import please see:
[NOTE:227332.1] NLS considerations in Import/Export
5. How to check the NLS_LANG:
-----------------------------
To check the NLS_LANG, you need to open a command prompt and to run
sqlplus
in command line mode.
First, check if it's set in the environment:
SQL> host echo %NLS_LANG%
If this reports just %NLS_LANG% back, the variable is not set in the
environment. If it's set it reports something like
ENGLISH_UNITED KINGDOM.WE8PC850
If NLS_LANG is not set in the enviroment, you should check the value
in the registry:
SQL> @.[%NLS_LANG%].
If you get something like:
unable to open file ".[ENGLISH_UNITED KINGDOM.WE8ISO8859P1]."
the "file name" between the '[]' is the value of the registry
parameter.
(This is NOT an error but just a "trick" to get the NLS_LANG value)
If you get this as result:
unable to open file ".[%NLS_LANG%]."
then the parameter NLS_LANG is also not set in the registry.
Note: the @.[%NLS_LANG%]. "trick" reports the NLS_LANG known by the
sqlplus
executable, it will not read the registry itself.
But then you are not sure if the variable is set in the enviroment or
in the
registry. That's the reason of checking with the host commando first.
6. List of common NLS_LANG's used in the Windows Registry:
----------------------------------------------------------
Operating System Locale
Arabic (U.A.E.)
EMIRATES.AR8MSWIN1256
NLS_LANG Value
ARABIC_UNITED ARAB
Bulgarian
BULGARIAN_BULGARIA.CL8MSWIN1251
Catalan
CATALAN_CATALONIA.WE8MSWIN1252
Chinese (PRC)
SIMPLIFIED CHINESE_CHINA.ZHS16GBK
Chinese (Taiwan)
CHINESE_TAIWAN.ZHT16MSWIN950
TRADITIONAL
Croatian
CROATIAN_CROATIA.EE8MSWIN1250
Czech
CZECH_CZECH REPUBLIC.EE8MSWIN1250
Danish
DANISH_DENMARK.WE8MSWIN1252
Dutch (Netherlands)
DUTCH_THE NETHERLANDS.WE8MSWIN1252
Dutch (belgium)
DUTCH_BELGIUM.WE8MSWIN1252
English (United Kingdom)
ENGLISH_UNITED KINGDOM.WE8MSWIN1252
English (United States)
AMERICAN_AMERICA.WE8MSWIN1252
Estonian
ESTONIAN_ESTONIA.BLT8MSWIN1257
Finnish
FINNISH_FINLAND.WE8MSWIN1252
French (Canada)
CANADIAN FRENCH_CANADA.WE8MSWIN1252
French (France)
FRENCH_FRANCE.WE8MSWIN1252
German (Germany)
GERMAN_GERMANY.WE8MSWIN1252
Greek
GREEK_GREECE.EL8MSWIN1253
Hebrew
HEBREW_ISRAEL.IW8MSWIN1255
Hungarian
HUNGARIAN_HUNGARY.EE8MSWIN1250
Icelandic
ICELANDIC_ICELAND.WE8MSWIN1252
Indonesian
INDONESIAN_INDONESIA.WE8MSWIN1252
Italian (Italy)
ITALIAN_ITALY.WE8MSWIN1252
Japanese
JAPANESE_JAPAN.JA16SJIS
Korean
KOREAN_KOREA.KO16MSWIN949
Latvian
LATVIAN_LATVIA.BLT8MSWIN1257
Lithuanian
LITHUANIAN_LITHUANIA.BLT8MSWIN1257
Norwegian
NORWEGIAN_NORWAY.WE8MSWIN1252
Polish
POLISH_POLAND.EE8MSWIN1250
Portuguese (Brazil)
BRAZILIAN
PORTUGUESE_BRAZIL.WE8MSWIN1252
Portuguese (Portugal)
PORTUGUESE_PORTUGAL.WE8MSWIN1252
Romanian
ROMANIAN_ROMANIA.EE8MSWIN1250
Russian
RUSSIAN_CIS.CL8MSWIN1251
Slovak
SLOVAK_SLOVAKIA.EE8MSWIN1250
Spanish (Spain)
SPANISH_SPAIN.WE8MSWIN1252
Swedish
SWEDISH_SWEDEN.WE8MSWIN1252
Thai
THAI_THAILAND.TH8TISASCII
Spanish (Mexico)
MEXICAN SPANISH_MEXICO.WE8MSWIN1252
Spanish (Venezuela)
LATIN AMERICAN
SPANISH_VENEZUELA.WE8MSWIN1252
Turkish
TURKISH_TURKEY.TR8MSWIN1254
Ukrainian
UKRAINIAN_UKRAINE.CL8MSWIN1251
Vietnamese
VIETNAMESE_VIETNAM.VN8MSWIN1258
7. List of common NLS_LANG's used in the Command Prompt (DOS box):
------------------------------------------------------------------
Operating System Locale
NLS_LANG)
Oracle Client character set (3rd part of
Arabic
AR8ASMO8X
Catalan
WE8PC850
Chinese (PRC)
ZHS16GBK
Chinese (Taiwan)
ZHT16MSWIN950
Czech
EE8PC852
Danish
WE8PC850
Dutch
WE8PC850
English (United Kingdom)
WE8PC850
English (United States)
US8PC437
Finnish
WE8PC850
French
WE8PC850
German
WE8PC850
Greek
EL8PC737
Hungarian
EE8PC852
Italian
WE8PC850
Japanese
JA16SJIS
Korean
KO16MSWIN949
Norwegian
WE8PC850
Polish
EE8PC852
Portuguese
WE8PC850
Romanian
EE8PC852
Russian
RU8PC866
Slovak
EE8PC852
Slovenian
EE8PC852
Spanish
WE8PC850
Swedish
WE8PC850
Turkish
TR8PC857
8. How Windows uses Fonts to display the different charactersets:
-----------------------------------------------------------------
We assume you have an UTF8 database with correctly stored UTF8
codepoints.
On Windows there are two kinds of tools / applications:
1)A fully Unicode enabled applications which accepts Unicode
codepoints and
which can render them. It's the application that needs to deal with
the Unicode,
Windows provides the unicode API but the GUI system itself is NOT
Unicode
"by nature".
A fully Unicode application can only show one glyph for a given
Unicode
code point. So there is NO confusion possible here, this application
will need
to use a full unicode font. If you have a full unicode application,
then you
need to set the NLS_LANG to UTF8.
Note that there are currently NOT many applications like this and if
it's not
explicitly mentioned by the vendor it's most likely an ANSI
application (see
below). So DON'T set the NLS_LANG to UTF8 if you are not sure!
The only Unicode capable client that is included in the database is
iSQLPLus.
See [NOTE:231231.1] Quick setup of iSQL*Plus as unicode client on
windows.
for a guide on how to setup this.
2) An standard ANSI application (like sqlplusw.exe) cannot use
Unicode
code points. So the Unicode code point stored in the database needs
to be
CONVERTED to a ANSI code point. This is done by setting NLS_LANG (as
described
in further on in this note and in [NOTE:158577.1].
This allows oracle to map the unicode point to the characterset of
the client,
(and here comes the tricky part)but this is NOT the same as a font.
If you want to display Arabic for example then you need to set the
Windows
characterset to Arabic. That way Windows knows what are valid
codepoints and
can use the FONT engine to DISPLAY the codepoints (this results in
glyphs).
Windows passes the codepoint and the "page" to the rendering engine.
This "page" defines the glyphs for the codepoints for a certain
characterset/codepage.
Because there are only 256 possible positions for a ANSI application,
and one
font contains normally glyphs for different languages this "page" is
used to
select from a FONT that has (for example) all the glyphs for
Cyrillic, Arabic
and West-European the "page" for arabian.
So lets say you have a Arabic setup that works, you change manually
the "Page"
of a FONT and ask to display the glyph for ANSI codepoint XX. Now 1
of 2 things
can happen:
1) There is a character defined on that position for the CHARACTERSET
of that
"Page", so the creator of the font has forseen a glyph and this is
displayed
(but this is NOT the character expected or wanted as its stored as a
different
character in the database!).
2) There is NO character defined on that position for the
CHARACTERSET of that
"Page" so the creator of the font has NOT forseen a glyph and you get
"garbage"
or black squares (normally you should see a black square but a ? or ?
are also
possible, this depends on the error handling defined in the FONT).
The above is also possible if you have an non-Unicode characterset
for the
database.
For more information see also:
[NOTE:137127.1] Character Sets, Code Pages, Fonts and the NLS_LANG
Value
Related Documents:
==================
[NOTE:158577.1] NLS_LANG Explained (How does Client-Server Character
Conversion Work?)
[NOTE:137127.1] Character Sets, Code Pages, Fonts and the NLS_LANG
Value
<Note.199926.1> How to change the ANSI Code Page (ACP) on Windows NT
4.0 and Windows 2000
[NOTE:226558.1] An example inserting cyrillic data into a database on
west european windows.
[NOTE:223706.1] Using Locale Builder to view the definition of
character sets
[NOTE:132453.1] How to Change the Displayed Font in SQL*PLUS (GUI) on
WinNT
[NOTE:231231.1] Quick setup of iSQL*Plus as unicode (UTF8) client on
windows.
[NOTE:165259.1] How to set NLS Variables for different Applications
using the same ORACLE_HOME
- Oracle8i Installation Guide for Windows NT, Part Number A85302-01
Appendix D - National Language Support
http://otn.oracle.com/documentation/oracle8i.html
- Oracle9i Database Installation Guide for Windows, Part Number
A90162-01
Appendix E - Globalization Support
http://otn.oracle.com/documentation/oracle9i.html
- Microsoft web site:
http://www.microsoft.com/globaldev/reference/oslocversion.mspx
provides a list of the default code pages for all Windows versions.
For further NLS / Globalization information you may start here:
[NOTE:150091.1] Globalization Technology (NLS) Library index
.
Bookmark
Doc ID: Note:225912.1
Subject:Changing the Database
Character Set - an Overview
Type: BULLETIN
Status: PUBLISHED
Fixed font
Content
Type:
Creation
Date:
Last
Revision
Date:
Go to End
TEXT/PLAIN
14-JAN-2003
06-JUN-2003
Introduction
============
This article aims to give an overview of possibilities to change
the database
character set and points to notes that are specific to the methods
described
here. If you use this note as a guide you're sure to find the
correct
information for your particular circumstances.
Please make sure that you have a good understanding of how oracle
deals with
character set conversion before going ahead with this, start with
going trough
the following note before changing the character set of you
database:
[NOTE:158577.1] NLS_LANG Explained (How does Client-Server
Character Conversion Work?)
Impact of changing the database character set
=============================================
Changing the database character set can have a lot of consequences
that should
be understood before starting with it. The character set of a
database defines
how characters are stored in the database and therefore you are
limited to
storing just the characters defined in that character set. If you
change
character sets there is a possibility that characters that you
currently use
are not defined in the new character set and therefore you could
'corrupt'
your data. The following note gives a good way of viewing the
characters that
are defined in a character set:
[NOTE:223706.1] Using Locale Builder to view the definition of
character sets.
You can check what what code points are physically stored in your
database at
this moment by using the dump command , see these notes for more
details:
[NOTE:13854.1] Dump SQL Command for NLS Debugging
[NOTE:69518.1] Determining the code point for UTF8 characters
Using "Oracle Applications"
===========================
If you use Oracle Applications the basic task of running the
character set
scanner explained in this note are the same, so please continue to
read this
note to get a full understanding of the migration options. However
there are
some additional considerations so please see the following note for
a complete
overview of changing the character set in an Applications Database:
[NOTE:124721.1] Migrating an Applications Installation to a New
Character Set
Preparation
===========
The first step in the process of changing the database character
set is running
the character set scanner (csscan) to check how the data will cope
with the
character set change. Using this you will find the data that can
not be stored
in the new character set. This can be either due to the fact that
the new
character set does not describe the characters you currently store,
or it can
be due to size restrictions. The following note explains how to use
the
character set scanner and gives some examples:
[NOTE:123670.1] Use Scanner Utility before Altering the Database
Character Set
The character set scanner reports the status of each table as one
of these 3:
CHANGELESS - the data would be stored in exactly the same way in
the new
character set.
CONVERTIBLE - the data can be stored using the new character set
without
problems but different code points are used so it needs to be
converted.
EXCEPTIONAL - These are the tables/rows with problems that need to
be tackled
before going ahead with the conversion
When you've changed the data in the original database and csscan
only reports
tables to be CHANGELESS or CONVERTIBLE it's time to move on to
changing
the database character set.
Important warning:
When using the Character set scanner you could find out that your
data is
stored completely incorrectly. For example you might have stored
Arabic data
in a WE8ISO8859P1 database (due to incorrect NLS_LANG settings on
the client).
This is typicaly showed as EXCEPTIONAL data found.
In that case please see the following note, which explains how to
recover from
these problems: [NOTE:225938.1] Database Character Set Healthcheck
Once the data is stored correctly you then have to start over and
go through
the steps of this note again to change the character set.
For example you might have a database that currently has the
US7ASCII character
set and you might want to change it to AL32UTF8. You might come to
the
conclusion that you actually have WE8MSWIN1252 codes (the character
set of
Western Windows) stored in your current US7ASCII database. You then
need to
first follow the mentioned [NOTE:225938.1] to change the database
to the
correct character set. After that you can restart with this note to
move from
there to the desired character set.
Changing the database character set
===================================
After having asserted the data is not going to give us problems by
using csscan
we now come to the real work of changing the character set. Since
Oracle 8.0
there are 2 ways to do this:
The simplest way is to use the "ALTER DATABASE CHARACTER SET"
command but that
is not always possible. Something that will always work is to
export the
current database, then create a new database with the new character
set and
import the data into that database. Sometimes a combination of the
2 methods
can be used. We will describe the methods further:
1. using the ALTER DATABASE CHARACTER SET command
------------------------------------------------This command was introduced in Oracle8. The statement does not
actually convert
any characters in the database. It simply updates all the places in
the
database where the character set information is stored. That means
that you
can only use this statement if the new character set is a superset
of the old
character set. We make the distinction between a binary -or TRUEsuperset and
a 'normal' superset. For example lets take character set A and B.
Character set
A is a binary superset of character set B if A describes exactly
the same
characters and used the same codepoint for those characters as B
does. On top
of that it probably also has some more characters characters at
codepoints that
are left free by character set B - otherwise they would be 100% the
same set.
If this is the case then csscan would have flagged up a CHANGELESS
conversion
in the csscan output and this method will work fine.
It is also possible for a character set to contain the same (and
more)
characters as another character set but store those characters at
different
code points. Although this is still a logical superset it is not a
binary
superset. Csscan would flag those characters up as CONVERTIBLE and
we need
another method of changing the character set. An example of this is
(AL32)UTF8,
which is a Unicode character set. It easily contains all the
characters of, for
example WE8ISO8859P15. However, it defines a lot of those
characters at
different code points. Therefore UTF8 is not classed as a binary
superset of
WE8ISO8859P15. The following note gives an overview of all the
superset/subset
combinations that exists:
[NOTE:119164.1] Changing Database Character Set - Valid Superset
Definitions
So, if you indeed are changing to a superset and csscan showed all
your data
as CHANGELESS you can use the ALTER DATABASE CHARACTER SET command.
See the
following note for a detailed description of how to do this:
[NOTE:66320.1] Changing the Database Character Set or the Database
National Character Set
2. Using export/import
---------------------A method that will always work is using export/import. You use this
method if
the csscan has marked your data CONVERTIBLE. Be aware that using
this method
you will not receive an error when you move to an incompatible
character set
(using method 1 you will get errors in that case). If characters
show up as
"EXCEPTIONAL" in the csscan output you can still press ahead with
export/import.
Characters that do not exist in the new character set are then
replaced by a
so-called replacement character. It is not advisable to rely on
this, it is a
better to make the choices yourself by changing data that shows up
as
EXCEPTIONAL before the export.
Also rows are flagged in csscan because the data in the new
database will be
expanded and will not fit in the allocated storage space. If you
press ahead
with the exp/imp they will simply receive a error om import (ORA1401) and will
not be imported.
When you change character sets through export/import you could
potentially go
through 3 different conversions. This is explained (among other
things) in the
following note:
[NOTE:15095.1] Export/Import and NLS Considerations
We obviously want to keep the number of conversions down to just 1
instead of 3
because there is less chance of problems that way. The easiest way
to achieve
that is to keep the export character set (the setting in NLS_LANG
when the
export is done) and the import session character set (the setting
in NLS_LANG
when the import is done) the same as the character set in the
original
database. That means that no conversion takes place on export and
no conversion
takes place inside the import session. The only conversion that
takes place is
from the import session (which by that point still has the original
data) to
the new database.
So, if you only have CONVERTIBLE and CHANGELESS data then:
1) Export the source database with the NLS_LANG set to the
character set of the
source (OLD) database.
( select * from nls_database_parameters where parameter =
'NLS_CHARACTERSET'; )
2) Create a NEW database with the NEW database characterset you
want to use.
3) Import the export file with the NLS_LANG set to the character
set of the
source (OLD) database.
4) The character set conversion will be done at the moment that the
import
executable inserts the data into the new database.
5) Backup the new database.
3. Using a combination of ALTER DATABASE CHARACTER SET and
export/import
----------------------------------------------------------------------In some cases you might find that csscan tells you that most of
your data is
CHANGELESS but only one (or a small number) of your tables is
CONVERTABLE.
In that case you would still have to use export/import. If the size
of the
database is particularly large and using export/import will cause
too much
down time you could follow this method:
a) Export the data from the tables that come out as CONVERTABLE.
b) Truncate or drop those tables.
c) Now you have a database with only CHANGELESS data. Because the
character set
is not classed as a subset of the new character set you cannot use
the normal
form of the ALTER DATABASE CHARACTER SET command. The command
usually simply
checks if the new character set is a superset of the old character
set, it does
not check the actual data. In order to force the change please
contact Oracle
Support. Provide them with the output of csscan showing all data is
classed as
CHANGELESS and they will then assist you in forcing the character
set change.
d) Now that the character set has changed we can simply import the
data
exported in step (a). The import will convert that data so that it
gets stored
in the correct way for this character set.
After changing the database character set
=========================================
Remember that changing the database character set only changes the
way
characters are stored on the database. This should NOT have any
effect on the
clients and you should not have to change the NLS_LANG for example.
The
NLS_LANG on the clients should simply reflect the setup of that
machine.
For more general information on setting up NLS_LANG and how clientserver
conversion works please see the following notes:
[NOTE:179133.1] The correct NLS_LANG in a Windows Environment
[NOTE:158577.1] NLS_LANG Explained (How does Client-Server
Character Conversion Work?)
Further reading
===============
For further NLS / Globalization information you may start here:
[NOTE:150091.1] Globalization Technology (NLS) Library index
[NOTE:60134.1]
Globalization (NLS) - Frequently Asked Questions
.
Abstract
The following sample code uses Visual Basic and DAO to link in the EMP and DEPT tables from the Ora
Microsoft Access.
Product Name, Product
Version
Oracle ODBC Driver, versions 8.1.7, 9.0, or 9.2
Platform
Windows 95, 98, NT, 2000, and XP Professional
Date Created
20-AUG-2001
Instructions
Execution Environment:
MS Access 2000
Access Privileges:
Requires access to the EMP and DEPT tables in the SCOTT sample schema.
Usage:
Run the completed sample from within Access.
Instructions:
1. Open a blank database in Access 2000.
2.
Click on the Forms tab and choose "Create a form in Design view".
3.
Add a command button to the new form.
4.
Right-click the button and choose "Properties".
5.
Choose the "Event" tab and find the "On Click" event.
6.
Click in the empty box next to the event and select the drop-down
button and choose "[Event Procedure]".
7.
Click on the button to the right of the drop-down button that looks like
three dots "..." This will bring up Visual Basic.
8.
Paste the code below into the "Command0_Click" procedure.
9.
In the following connect string:
strConnect = "ODBC;DSN=v817;UID=SCOTT;PWD=TIGER"
a.
Change "v817" to match your Data Source Name that you have
setup for your ODBC connection.
b.
Change "SCOTT" to match userid for your database.
c.
10.
Change "TIGER" to match password for your database.
Chools Tools | References... and check the following box:
a.
Microsoft DAO 3.51 Object Library
11.
Save the form by going to File->Save in Visual Basic.
save the code for the form.
This will
12.
Close out Visual Basic.
13.
In Access, go to Forms, and you will see your form there. Double
click on it and hit the Command0 button. This will run the code.
14.
You are now ready to run the sample code. The code will link the EMP
and DEPT tables from the Oracle database into MS Access using the DSN
you have specified.
PROOFREAD THIS SCRIPT BEFORE
USING IT! Due to differences in the way text
editors, e-mail packages, and operating
systems handle text formatting (spaces,
tabs, and carriage returns), this
script may not be in an executable state
when you first receive it. Check
over the script to ensure that errors of
this type are corrected.
Description
Prerequisites:
* Oracle client software version 8.1.7, 9.0, or 9.2
* Oracle ODBC Driver version 8.1.7, 9.0, or 9.2
* Microsoft Data Access Components (MDAC) version 2.6 or above
* Windows 95, 98, NT 4.0, 2000, or XP Professional
* MS Access 2000
* Visual Basic 6.0
Sample Output:
Under the "Tables" tab in MS Access, you will find the
Oracle tables EMP and DEPT linked in as the MS Access tables
EMP_TABLE and DEPT_TABLE.
References
This sample was taken
from Sample Code Repository (SCR) Entry 1476.
Sample Code
' ********************************************************************************
'
This procedure attaches an external Oracle Database table to MS Access in code
' ********************************************************************************
On Error GoTo ErrorHandler
Dim
Dim
Dim
Dim
dbs As Database
tdfMyTable1 As TableDef
tdfMyTable2 As TableDef
strConnect As String
Set dbs = CurrentDb
' Define your connection string.
' Include the name of the DSN, User ID, and Password.
strConnect = "ODBC;DSN=MyDSN;UID=SCOTT;PWD=TIGER"
'
ATTACH THE 'EMP' TABLE FROM THE ORACLE DATABASE - PART 1
' Delete the linked table object if it already exits
DoCmd.DeleteObject acTable, "EMP_TABLE"
' Create a new table object from an Oracle table
Set tdfMyTable1 = dbs.CreateTableDef("EMP_TABLE")
tdfMyTable1.Connect = strConnect
tdfMyTable1.SourceTableName = "EMP"
' Link the table and have it appear in the 'Tables' tab
dbs.TableDefs.Append tdfMyTable1
' Deallocate memory for the table object
Set tdfMyTable1 = Nothing
MsgBox "The EMP table from the SCOTT/TIGER schema in the Oracle database has
been linked into MS Access through code. Check your 'Tables' tab.", , "Linked Table"
'
ATTACH THE 'DEPT' TABLE FROM THE ORACLE DATABASE - PART 2
' Delete the linked table object if it already exits
DoCmd.DeleteObject acTable, "DEPT_TABLE"
' Create a new table object from an Oracle table
Set tdfMyTable2 = dbs.CreateTableDef("DEPT_TABLE")
tdfMyTable2.Connect = strConnect
tdfMyTable2.SourceTableName = "DEPT"
' Link the table and have it appear in the 'Tables' tab
dbs.TableDefs.Append tdfMyTable2
' Deallocate memory for the table object
Set tdfMyTable2 = Nothing
MsgBox "The DEPT table from the SCOTT/TIGER schema in the Oracle database
has been linked into MS Access through code. Check your 'Tables' tab.", , "Linked Ta
' Deallocate memory for the database object
Set dbs = Nothing
Exit Sub
ErrorHandler:
Select Case Err
Case 3011, 7874
' The table does not exit, continue execution of the program
Resume Next
Case Else
' Display any other error messages generated
MsgBox Err & " - " & Error$, , "LINKING TABLES"
End Select
Exit Sub
Disclaimer
EXCEPT WHERE EXPRESSLY PROVIDED OTHERWISE, THE INFORMATION, SOFTWARE,
PROVIDED ON AN "AS IS" AND
"AS AVAILABLE" BASIS. ORACLE EXPRESSLY DISCLAIMS
ALL WARRANTIES OF ANY KIND, WHETHER
EXPRESS OR IMPLIED, INCLUDING, BUT NOT
LIMITED TO, THE IMPLIED WARRANTIES
OF MERCHANTABILITY, FITNESS FOR A PARTICULAR
PURPOSE AND NON-INFRINGEMENT. ORACLE
MAKES NO WARRANTY THAT: (A) THE RESULTS
THAT MAY BE OBTAINED FROM THE USE OF THE SOFTWARE WILL BE ACCURATE OR
RELIABLE; OR (B) THE INFORMATION,
OR OTHER MATERIAL OBTAINED WILL MEET YOUR
EXPECTATIONS. ANY CONTENT, MATERIALS,
INFORMATION OR SOFTWARE DOWNLOADED OR
OTHERWISE OBTAINED IS DONE AT YOUR
OWN DISCRETION AND RISK. ORACLE SHALL HAVE
NO RESPONSIBILITY FOR ANY DAMAGE DONE
TO YOUR COMPUTER SYSTEM OR LOSS OF DATA THAT
RESULTS FROM THE DOWNLOAD OF ANY CONTENT,
MATERIALS, INFORMATION OR SOFTWARE.
ORACLE RESERVES THE RIGHT TO MAKE
CHANGES OR UPDATES TO THE SOFTWARE AT ANY
TIME WITHOUT NOTICE.
Limitation of Liability
IN NO EVENT SHALL ORACLE BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL,
SPECIAL OR CONSEQUENTIAL DAMAGES,
OR DAMAGES FOR LOSS OF PROFITS, REVENUE,
DATA OR USE, INCURRED BY YOU OR ANY THIRD PARTY, WHETHER IN AN ACTION IN
CONTRACT OR TORT, ARISING FROM YOUR ACCESS TO, OR USE OF, THE SOFTWARE.
SOME JURISDICTIONS DO NOT ALLOW THE LIMITATION OR EXCLUSION OF LIABILITY.
ACCORDINGLY, SOME OF THE ABOVE LIMITATIONS MAY NOT APPLY TO YOU.