ORACLE Architecture and Terminology
advertisement

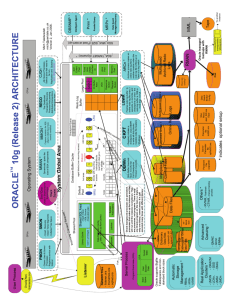
ORACLE Architecture and Terminology This section will provide a basic understanding of ORACLE including the concepts and terminology of the ORACLE Server. It is important that you read through this section to familiarize yourself with the concepts and terminology to be used throughout this manual. Most of the information contained in this section is DIRECTLY extracted from ``ORACLE7 Server Concepts Manual'' and all credit should be attributed to ORACLE. Before you can begin to use ORACLE, you must have a basic understanding of the architecture of ORACLE to help you start thinking about an ORACLE database in the correct conceptual manner. Figure 1 illustrates a typical variation of ORACLE's memory and process structures; some of the memory structures and processes in this diagram are discussed in the following section. For more information on these memory structures and processes, see page 1-15 of ``ORACLE7 Server Concepts Manual.'' Figure 1. ORACLE Architecture Memory Structures and Processes The mechanisms of ORACLE execute by using memory structures and processes. All memory structures exist in the main memory of the computers that constitute the database system. Processes are jobs or tasks that work in the memory of these computers. Memory Structures ORACLE creates and uses memory structures to complete several jobs. For example, memory is used to store program code being executed and data that is shared among users. Several basic memory structures are associated with ORACLE: the system global area (which includes the database and redo log buffers, and the shared pool) and the program global area. Processes A process is a ``thread of control'' or a mechanism in an operating system that can execute a series of steps. Some operating systems use the terms job or task. An ORACLE database system has two general types of processes: user processes and ORACLE processes. A user process is created and maintained to execute the software code of an application program (such as a PRO*C program) or an ORACLE tool (such as SQL*PLUS). The user process also manages the communication with the server processes. User processes communicate with the server processes through the program interface. ORACLE processes are called by other processes to perform functions on behalf of the invoking process. ORACLE creates a server process to handle requests from connected user processes. ORACLE also creates a set of background processes for each instance (see ``ORACLE7 Server Concepts Manual'' pages 1-18, 1-19). Database Structures The relational model has three major aspects: Structures Structures are well-defined objects that store the data of a database. Structures and the data contained within them can be manipulated by operations. Operations Operations are clearly defined actions that allow users to manipulate the data and structures of a database. The operations on a database must adhere to a predefined set of integrity rules. Integrity Rule Integrity rules are the laws that govern which operations are allowed on the data and structures of a database. Integrity rules protect the data and the structures of a database. An ORACLE database has both a physical and a logical structure. By separating physical and logical database structure, the physical storage of data can be managed without affecting the access to logical storage structures. databases and data files A database's data is collectively stored in the data files that constitute each table space of the database. For example, the simplest ORACLE database would have one table space, with one data file. A more complicated database might have three table spaces, each comprised of two data files (for a total of six data files). schema objects, segments, and table spaces When a schema object such as a table or index is created, its segment is created within a designated table space in the database. For example, suppose a table is created in a specific table space using the CREATE TABLE command with the TABLESPACE option. The space for this table's data segment is allocated in one or more of the data files that constitute the specified tablespace. An object's segment allocates space in only one tablespace of a database. Data files associated with a tablespace store all the database data in that tablespace. One or more data files form a logical unit of database storage called a tablespace. A data file can be associated with only one tablespace, and only one database. After a data file is initially created, the allocated disk space does not contain any data; however, the space is reserved to hold only the data for future segments of the associated tablespace - it cannot store any other program's data. As a segment (such as the data segment for a table) is created and grows in a tablespace, ORACLE uses the free space in the associated data files to allocate extents for the segment. The data in the segments of objects (data segments, index segments, rollback segments, and so on) in a tablespace are physically stored in one or more of the data files that constitute the tablespace. Note that a schema object does not correspond to a specific data file; rather, a data file is a repository for the data of any object within a specific tablespace. The extents of a single segment can be allocated in one or more data files of a tablespace (see Figure 3); therefore, an object can ``span'' one or more data files. The database administrator and end-users cannot control which data file stores an object. DATAFILES Every Oracle database has one or more physical datafiles that belong to logical structures called tablespaces. The datafile is divided into smaller units called data blocks. The data of logical database structures, such as tables and indexes, is physically located in the blocks of the datafiles allocated for a database. Datafiles hold the following characteristics: User-defined characteristics allow datafiles to automatically extend when the database runs out of space. One or more physical datafiles form a logical database storage unit called a tablespace. The first block of every datafile is the header. The header includes important information such as file size, block size, tablespace, and creation timestamp. Whenever the database is opened, Oracle checks to see that the datafile header information matches the information stored in the control file. If it does not, then recovery is necessary. Oracle reads the data in a datafile during normal operation and stores it in the buffer cache. For example, assume that a user wants to access some data in a table. If the requested information is not already in the buffer cache, Oracle reads it from the appropriate datafiles and stores it in memory. CONTROL FILES Every Oracle database has a control file containing the operating system filenames of all other files that constitute the database. This important file also contains consistency information that is used during recovery, such as the: Database name Timestamp of database creation Names of the database's datafiles and online and archived redo log files Checkpoint, a record indicating the point in the redo log where all database changes prior to this point have been saved in the datafiles Recovery Manager(RMAN) backup meta-data Users can multiplex the control file, allowing Oracle to write multiple copies of the control file to protect it against disaster. If the operating system supports disk mirroring, the control file can also be mirrored, allowing the O/S to write a copy of the control file to multiple disks. Every time a user mounts an Oracle database, its control file is used to identify the datafiles and online redo log files that must be opened for database operation. If the physical makeup of the database changes, such as a new datafile or redo log file is created, Oracle then modifies the database's control file to reflect the change. The control file should be backed up whenever the structure of the database changes. Structural changes can include adding, dropping, or altering datafiles or tablespaces and adding or dropping online redo logs. ONLINE REDO LOG FILES Redo logs are absolutely crucial for recovery. For example, imagine that a power outage prevents Oracle from permanently writing modified data to the datafiles. In this situation, an old version of the data in the datafiles can be combined with the recent changes recorded in the online redo log to reconstruct what was lost. Every Oracle database contains a set of two or more online redo log files. Oracle assigns every redo log file a log sequence number to uniquely identify it. The set of redo log files for a database is collectively known as the database's redo log. Oracle uses the redo log to record all changes made to the database. Oracle records every change in a redo record, an entry in the redo buffer describing what has changed. For example, assume a user updates a column value in a payroll table from 5 to 7. Oracle records the old value in undo and the new value in a redo record. Since the redo log stores every change to the database, the redo record for this transaction actually contains three parts: The change to the transaction table of the undo The change to the undo data block The change to the payroll table data block If the user then commits the update to the payroll table - to make permanent the changes executed by SQL statements - Oracle generates another redo record. In this way, the system maintains a careful watch over everything that occurs in the database. Circular Use of Redo Log Files Log Writer (LGWR) writes redo log entries to disk. Redo log data is generated in the redo log buffer of the system global area. As transactions commit and the log buffer fills, LGWR writes redo log entries into an online redo log file. LGWR writes to online redo log files in a circular fashion: when it fills the current online redo log file, called the active file, LGWR writes to the next available inactive redo log file. LGWR cycles through the online redo log files in the database, writing over old redo data. Filled redo log files are available for reuse depending on whether archiving is enabled: If archiving is disabled, a filled online redo log is available once the changes recorded in the log have been saved to the datafiles. If archiving is enabled, a filled online redo log is available once the changes have been saved to the datafiles and the file has been archived.