Discrete variable- A variable with a basic unit of measurement that cannot be
subdivided. (people)
Hypothesis- A statement about the relationship between variables that is
derived from a theory. Hypothesis are more specific than theories, and all terms
and concepts are fully defined.
Data- in social science research, information that is represented by numbers
Descriptive Statistics- The branch of statistics concerned with 1)summarizing
the distribution of a single variable 2) measuring the relationship between two or
more variables.
Measure of association- statistics that summarize the strength and direction of
the relationship between variables.
Theory- generalized explanation of the relationship between two or more
variables.
Populations- total collection of all cases in which the research is interested
Inferential statistics- statistics concerned with making generalizations from
samples to populations.
Independent variable- variable that is identified as a causal variable. the
independent variable is thought to cause the dependent variable.
level of measurement- mathematical characteristics of a variable as determined
by the measurement process. A major criterion for selecting statistical
techniques.
Statistics- set of mathematical techniques for organizing and analyzing data.
Data reduction - summarizing many scores with a few statistics
dependent variable- variable that is identified as an effect, result of outcome of
something.
Variable- any trait that can change values from case to case.
Data value- value of variable associated with one element of population
Data set-collection of measurements or observations
Univariate- summarize one variable (GPA)
Bivariate- describe relationship between two variables
Mulitivariate- descriptive statistics relationship between three or more variables
Raw Score-single measurement/observation
Continuous variable- variable with a unit of measurement that can be
subdivided. (rounding of the scores)
Research- process of gathering information systematically to answer questions
or test theories.
Sample- subset of a population in inferential statistics. Discrete variable- A
variable with a basic unit of measurement that cannot be subdivided.
Hypothesis- A statement about the relationship between variables that is
derived from a theory. Hypothesis are more specific than theories, and all terms
and concepts are fully defined.
Data- in social science research, information that is represented by numbers
- the sum of scores
Basic rule of precedence- find all squares and square roots first, multiple, divide,
Sigma, add, subtract
Validity- describe if it measures the concept it is intended to measure
Reliability- quality of measuring instrument
Nominal Level of Measurement:
Categories are not numbers
Gender, area code, provinces
Cannot be ranked, added, divided
Categories must be exhaustive (categories must exists for every score)
Homogenous (comparable cases)
No ambiguity exists mutually exclusive
discrete
Ordinal Level of Measurement:
Ranked from high to low
More or less = classified
Limitation-scores position respect to other scores
discrete
Interval Level
numbers
Ordered categories exactly the same
Distance is not equal
onlly interval ratio level can be continous
Ration Scale Equal differences on scale reflect equal difference in magnitude
Distance is equal
******
Type
Nominal
Ordinal
Ratio
Interval
dichotomous
******
Description
Classification of objects
-can only be discrete
Variable can be ranked
-can only be discrete
Variables can be ranked,
distance is equal
-can only be continous
Variables can be ranked,
distance is not equal
-can only be continous
Variable comprises only
two categories
example
-ethic groups
-job satisfaction
productivity
Income, age ,salary
temperature
Gender
********
*****
Chapter 2
Percentage: %= x 100 -frequency over # of cases in all categories
n
Proportion:
N
-with small # of cases less than 20 report actual frequency
-always report proportions and percentages
Ratio compares parts to parts
23females/19 males
=1.21 females for every male
(1)
f2
Rates
# of actual occurrence divided by possible occurrence
usually multiplied by 10 to eliminate decimal points
crude death rate (CDR) multiplied by 1000
CDR= # of deaths X 1000
Total pop
Percentage Change
Measures increase or decrease in a score @ 2 different times
o {(f2-f1)} X100
f1
-2nd set(-)1st set / divide by 1st set X100
Frequency distribution
organized table of # of individuals in each category on the scale of
measurement
first step in any statistical analysis
graph or table
set of categories that make up original measurement scale
record of the number of individuals in each category
to understand how many times something has occurred
first step in statistical data
categories must be discrete 0-99/100-199/200-299 (class intervals)
# of categories must be between 6 and 20
lower class limits- smallest # that can belong to different classe interval 0-99
upper class limits- largest number that can belong to different classe interval 0-99
Class midpoints-middle of two classes
-add lower case to upper, divide by 2
State class limits:
class intervals that organize variables into discrete, non-overlapping
intervals.
when stated as a discrete category
Real class limits:
divide distance between the class intervals and add to upper class, and
subtract from lower class . ex: stated limits: 18-19, real limits: 17.5-19.5
when stated as a continous category
Cumulative frequency and Percentage:
give glance at how many cases fall below a given score in the distribution.
research may want to make a point of how cases are spread acress the range
of scores.
Histograms
each bar represents a range of values
use real limits rather than stated limits
values contact with each other show continuous variable
display distribution of data
used for continous, but commonly used for discrete interval ratio level
frequency always on vertical axes
tells you if the data is skewed right/left, bell-shaped
Chapter 3
Measure of Central Tendency:
Idea of the typical mean, median or mode case in the distribution
Mode
Mean
frequency that occurs most
frequently
quick easy indicator of central
tendency
nominal-level variable
seldom reported alone
"average"
add all values, divide by N of values
most commonly used measure
interval-ratio level, but also used
ordinal-level (highly skewed
distribution)
X bar
Weighted/aggregate mean
o occurance of more than one
value.
o (Xi) x (2f)
o multiply values by frequencies
Value Frequency Value X
frequency
97
4
97x4=
388
94
11
94x11 =
1034
92
12
92x12
=1104
91
21
91x21 =
1911
90
30
90x30=
2700
89
12
78
9
60
total
1
100
89x12=
1068
78x9 =
702
60z1= 60
8967
A) All scores cancel out around the
mean.
B) Uses all scores-strength, weakness
affected by every score.(skews)
C) Least squares principle- mean is
closer to all scores than the other
measures of central tendency.
mean pulled in the direction of the
extremes.
Symmetric-mean and median having
same value.
Positive Skew- skewed to left. mean is
higher in value than median
Negative skew- skewed to the right,
mean is lower in value than median.
Median
represents center of distribution of
scores
when N is odd, value of median is
unambiguous (always a middle case)
when N is even the score halfway
between the two scores must be
attained
ordinal or interval-ratio
measures position or location
good choice in extreme values
(outliers)
household income=extreme values
Percentile
used for median. media is the 50th percentile
identifies specific point of case
find 37th percentile of 78,
o 78 X .37 =28.86 is the case
Decile
divide distribution into 10's
Quartile
divide distribution into quarters 0 q1(25%) q2(50%) q3(75%) q4(100%)
Measure of Dispersion
How much variety of the distribution
ex. how 'often' do graduates receive $40,000 per year.
Chapter 4
Measure of Dispersion
variety in a distribution
the taller the curve=less dispersion, the flater the curve=more dispersion
amount of diversity, heterogeneity
R -range is the distance from highest value to the lowest
o quick easy indication of variablity
o ordinal, interval-ratio
o limited= based on only 2 scores
o no information about variation between high and low scores
Q-interquartile range, only considers the middle 50% of cases in distribution
boxplot- Diagram of LH
o L--------Q1--------Q2--------Q3--------H
o
o based on information on five-number summary
o Q2(median) is marked with vertical line
o useful when two ore more data sets are being compared
Good measure of dispersion:
o use all scores in distribution
o describe average deviation
o increase in value as the distribution becomes more diverse
Standard Deviation (S)
uses all scores in distribution
increases in value as the distribution of scores becomes more diverse
distance between socres and mean (deviation)
if scores are clustered around each other, deviation would be small, vise
versa.
value of S can increase with the inclusion of one or more outliers
units of standard deviation are the same as the units of orginal data values
average distance of each score from the mean
interval-ratio, but often used with ordinal-level
the higher the SD=more distribution, lower SD=less distributions
0 value- no dispersion
N-1 is used when working with random samples rather than entire
populations.
Index of Qualitative Variation (IQV)
only measur of dispersion for nominal level variables (but can be used with any
variable)
varies from 0.00 (no variation) to 1.00 (maximum variation)
raio of the amount of variation observed in the distribution.
Variance
measure of variation equal to the square of the standard deviation s2
used in inferential statistics
Coefficient of Varition
presents the standard deviation as a percentage of the mean value
allows you to compare the variability of different variables.
The range rule of thumb-principle that many data sets (95%) of sample values lie within
two standard deviation of the mean.
Chapter 5
Normal distribution
great importance
combo of mean and SD can use normal distribution curve to contruct precise
descriptive statements about empirical distributions
theoretical model, frequency polygon or line chart that is 'unimodal' (single
mode/peak) perfectly smooth, and symmetrical=mean, median and mode are
same value.
crucial point is distance along the abscissa (horizontal)
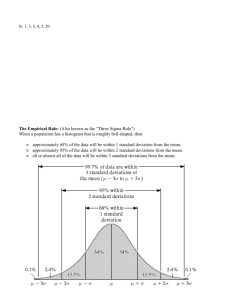
Empirical rule
68% of all values fall within 1 standard deviation of mean
95% of all values fall within 2 standard deviations of mean
99.7% of all values fall within 3 standard deviations of the mean
Z scores:
percentage of are above, below or between scores in empirical distribution
always have same value for mean and standard deviation
convert the original units of measuremen into Z scores, "standardize the normal
curve to a distribution that has a mean of 0.
how many standard deviation units a case is above or below a mean
a ruler from x to the mean
when value is less than the mean, the Zscore is negative
Ordinary values Zscore between -2 and 2
unusual values Zscore less than -2 <-2>
Normal curve table
Appendix A, detailed description of the area between Z score and the mean
Probability
method for measuring and quantifying the likelihood of obtaining a specific
sample from a specific population.
define as a fraction or a proportion.
ratio comparing frequency of occurrence / total number of possible events
in frequency distributions probability can be defined by proportions of
distribution
in graphs, can be defined as a proportion of area under the curve
Unit normal table:
lists different proportions of corresponding to each z-score location.
 0
0