Computer exercise 1: Simple linear regression
advertisement

732A20 Data Mining and Statistical Learning
Department of Computer and Information Science
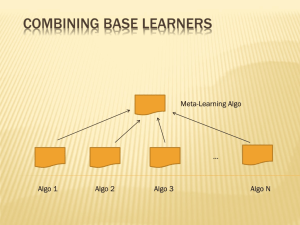
Computer lab 10: Bagging and boosting
Learning objective
The main objective of this computer lab is to make the student aquainted with bagging
and boosting techniques for improving predictions
After completing the lab the student shall be able to:
(i)
Run the Ensemble node in SAS Enterprise Miner .
(ii)
Understand under what circumstances bagging and boosting can improve
predictions
Recommended reading
Chapters 8.1, 8.2, 8.7 and 10.1-10.9 in Hastie et al.
Assignment 1: A simple example of bagging
The Excel file bodyfatregression.xls contains records of waist measure (cm), weight (kg)
and body fat (%) for 110 persons. Your task is to carry out a regression analysis with and
without bagging and to compare the results obtained. Choose body fat as target variable
and the waist measure and weight as inputs
Import the data file to SAS and create a diagram consisting of nodes for data input, data
partition (70% for training and 30% for testing), and regression. Then, run the diagram
and export the fit statistics to an assessment node.
Augment the diagram with a branch consisting of nodes for group processing, regression
and ensemble runs. Then, run this branch of the diagram with the group processing and
ensemble nodes set for bagging with 10 loops. Examine how the fit statistics vary from
sample to sample in the output of the bagging procedure. Also, export the fit statistics of
the ensemble predictor to the assessment node, and compare its performance to that of the
regression on the original data set.
Assignment 2: Model selection involving bagging and boosting
The data file spambase.xls contains information about the frequency of various words,
characters etc for a total of 4601 e-mails. Furthermore, these e-mails have been classified
as spams (spam = 1) or regular e-mails (spam = 0). Your task is to develop a suitable
classification model using a tree model, a logistic regression model or a neural network
as the basic classifier and bagging and boosting for improving (if possible) the
performance of the classifier. Detailed information about the mail attributes is given
below.
a) Define a data flow diagram with common nodes for data input and data partition
(70% for training and 30% for test), and separate branches with nodes for tree
732A20 Data Mining and Statistical Learning
Department of Computer and Information Science
models, (logistic) regression and neural network classifiers. Also, add a common
assessment node to the diagram.
b) Run the diagram and make suitable changes of the model settings to improve the
predictive power of the three types of models.
c) Augment the diagram with branches for group processing, a basic classifier (tree,
logistic regression or neural network) and an ensemble node.
d) Define the settings of the group processing and ensemble nodes so that bagging is
undertaken. Set the number of loops to a maximum of ten..
e) Run the different branches of the constructed diagram and export the fit statistics
to a common assessment node. Which method performed best on the selected test
set? Can the results obtained be generalized to other data sets?
f) Repeat the previous task but include also branches for boosting in your data flow
diagram.
Attribute Information for spambase:
The last column of 'spambase.xls' denotes whether the e-mail was
considered spam (1) or not (0), i.e. unsolicited commercial e-mail.
Most of the attributes indicate whether a particular word or
character was frequently occurring in the e-mail. The run-length
attributes (55-57) measure the length of sequences of consecutive
capital letters. For the statistical measures of each attribute,
see the end of this file. Here are the definitions of the attributes:
48 continuous real [0,100] attributes of type word_freq_WORD
= percentage of words in the e-mail that match WORD,
i.e. 100 * (number of times the WORD appears in the e-mail) /
total number of words in e-mail. A "word" in this case is any
string of alphanumeric characters bounded by non-alphanumeric
characters or end-of-string.
6 continuous real [0,100] attributes of type char_freq_CHAR
= percentage of characters in the e-mail that match CHAR,
i.e. 100 * (number of CHAR occurrences) / total characters in e-mail
1 continuous real [1,...] attribute of type capital_run_length_average
= average length of uninterrupted sequences of capital letters
1 continuous integer [1,...] attribute of type
capital_run_length_longest
= length of longest uninterrupted sequence of capital letters
1 continuous integer [1,...] attribute of type capital_run_length_total
= sum of length of uninterrupted sequences of capital letters
= total number of capital letters in the e-mail
732A20 Data Mining and Statistical Learning
Department of Computer and Information Science
1 nominal {0,1} class attribute of type spam
= denotes whether the e-mail was considered spam (1) or not (0),
i.e. unsolicited commercial e-mail.
To hand in
Highlighted items.