A Data Warehouse Architecture in Layers for Science and
advertisement

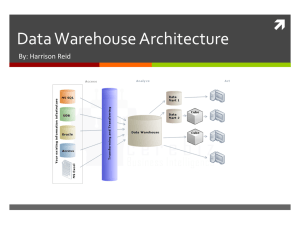
A Data Warehouse Architecture in Layers for Science and Technology André Luís Andrade Menolli1, and Maria Madalena Dias2 1 Departamento de Ciência da Computação, Faculdades Luiz Meneghel, Rod. BR 369, Km 54, Caixa Postal 261 86360-000 Bandeirantes, Paraná, Brasil a_menolli@hotmail.com 2 Departamento de Informática, Universidade Estadual de Maringá, Avenida Colombo 5790 870200-900 Maringá, Paraná, Brasil mmdias@din.uem.br http://www.din.uem.br/~mmdias Abstract The data warehousing technology has been widely used in companies with the aim of offering organization, management and data integration. In the knowledge discovery process in database, the first step is the data preparation, where the data must be organized and stored in the data warehouse (DW). The construction of a DW is a complex and laborious task because it demands a high knowledge of the involved company business, and also of the contents of data sources and of the technologies, such as database, data integration and data warehousing. The choice of the architecture is an important decision to be making to build a DW. This paper presents a DW layered architecture of integrated and increased data marts for management in Science and Technology (S&T). This architecture is applied to build a DW that integrates the institutional bases of CNPq and CAPES. Keywords. Data Warehouse, Science and Technology, Data Integration. 1. Introduction Companies of different activities and government organizations have data in several data sources that contain important information for the support to decisions making. Thus, to make these decisions are necessary the understanding and preparation of these data. Data Warehousing provides tools to support decisions making through the integration of all company data in a repository. The data can be accessed easily and analyzed without the lost time involved in the manipulation and processing. “DW is an integrated, non-volatile, time- variant set of data based on subject matter, supporting management decisions” [19]. The organization can to build a DW or integrated Data Marts (DM) that facilitates the process and does not require great initial investment. DM is a departmental DW, it´s built for an organization’s particular area [19]. Not only companies, but any market segment which want to do the data integration of several databases, a DW can be built, making possible the use of an integrated database in the decisions making. The outcome of the use of a DW for the information processing is a direct profit of productivity and time. The data are easily accessed and analyzed without expending time in the manipulation and in the processing. The decisions are taken quickly and safely, because the data are available at the exact moment they are necessary and with the necessary consistency. To have a good planning in S&T is necessary that the manager has safe information for the decision making. For this, a DW is built, and DW architecture would have to be chosen or defined. The Brazilian Science & Technology (S&T) environment have important databases that are consolidated and trustworthy. The main bases are: Brazilian Research Groups [5], Brazilian Researchers Curriculum (Lattes Curriculum) [5], and Brazilian Postgraduation [4]. Despite exist in Brazil important databases, those databases are independent and do not give a global vision of research in Brazil. It is necessary integrate theses databases, because the CAPES database there are just data about Brazilian Postgraduation while the CNPq database there are data only about Brazilian researcher. Hence is very important the integration of these databases to understand the behavior of research and researchers in Brazil and a DW is a way to obtain it. The remainder of this paper is organized as it follows: Section 2, architectures proposed by other authors are related; Section 3, the proposed architecture is described; Section 4, the steps to build a DW for management in S&T are described and its data model is presented; Section 5, some results obtained through queries to the DW are showed. Finally, in the Section 6 the conclusions of this paper are presented, and in the Section 7 some future works are suggested. This architecture is constituted of five layers, represented in Figure 1 and described in the following sections. The thick arrows represent the load of data, and the fine arrows represent the access to the data. In the architecture in layers, the main advantage is the independence of the layers, which facilitates the maintenance of the layers. A layer hides details of implementation of the others layers. Interfaces between the layers are defined to allow access of services provided for the layers. 2. Related Works 3.1. Data Source Layer In the project of a DW, the choice of the architecture and development methodology should be the first decisions to be making, because the organization of the components depends of these choices. Inmon [19] presents a DW architecture in that a global DW is built to the necessity of whole company. The data storage is composed by a decision support for common data repository, available for the all company. In this architecture it is possible to build a centralized DW or a distributed DW. According to [19], this architecture has as advantage the access to the data corporate vision, however, this architecture has a high implementation cost and a long time of development. Kimball et al. [17] proposed the Data Warehouse Bus Architecture in that the storage area is composed by several data marts projected to maintain the data integration. This Architecture is divided in two great components, the Back Room and the Front Room. The Back Room represents the tools and the processes for the acquisition of the data sources (Extraction, Transformation and Load - ETL). The Front Room represents all tools and processes necessary for interaction with the final user. According to [17], in spite of the Bus Architecture make possible to search the first results faster and with less cost, it has complex metadata to manage data distribution and integration. Singh [9] presents an architecture model in multiple layers for a DW, containing the following layers: Message of the Application Layer, Metadata Layer, Information Access Layer, Data Access Layer, DW Layer, Staging Area Layer, Operational Data Layer, and the Process Management Layer. This architecture proposes a model in layers but it does not follow the style of architecture in layers presented for [14]. In any DW environment the extraction of data from some data source is necessary, because DW is not a conventional database. The Data Source layer represents all data sources that are used as information suppliers to DW. These data sources can be in the reference format or in others formats. The reference format is chosen by the DW planner according with the format in that the data will be stored in DW. 3.2. ETL Layer In this layer the data are extracted of the data sources and they are stored in the staging area. In this layer there are the largest problems in the development of a DW. According to [3], estimate that more than 1/3 of the cost and time are spent to ETL and problems like extraction, transformation and cleaning, which can take up 80% of the time spent in the development of a DW [11]. The ETL layer is divided in two modules, a migration module and another of extraction, transformation and load. The migration module transfers data in several formats for a reference format chosen by DW planner. The module of extraction, transformation and load collects relevant data, cleans, integrates, transforms and stores these data in the staging area. When a data source does not be in the reference format, a data model must be defined and a data structure must be created in the reference format for these data. The ETL layer makes possible the integration of data of several sources, facilitating the maintenance and the insert of new data sources 3. Proposed Data Warehouse Architecture 3.3. Staging Area Layer In this paper is proposed a layered architecture of integrated and incremental data marts. In this architecture, new data marts can be implemented or data marts can be modified allowing inclusion of new requirements. The main characteristic of this architecture is the replace of data sources of several formats for a standardized database, facilitating the data integration. The staging area is an intermediate step between the extraction of the data source and the load in DW. In this area the data receive the first cleanings, transformations and integrations. According to [16], a fundamental concept that greatly simplifies DW projects and facilitates maintenance is the use of data staging areas. Starting from the logical project of the staging area, it is possible to have a good In the analysis area layer are defined the responsible components for the search of information and interesting knowledge in DW. These components can be classified as: OLAP tools, data mining tools and materialized views. For any type of component that is used, a special data preparation is necessary. The OLAP tools allow analysis and management, providing a great profit of performance, as fast access to a great variety of data views organized through the multidimensional database. The data mining tools in general are more complex than the OLAP tools. The complexity of these tools is Institutions of Education Research Groups Researcher OLAP and Data Mining Tools Data Mart 1 Common Data Data Mart N Work DB1 Work DB N DB 1 DB 2 Data extraction, transformation and loading Data Warehouse Analysis Area The metadata contains information about data used by several components of the architecture. The information contained in this repository is essential for the complete operation and maintenance of the components. It is necessary to know the information on the data that compose the DW, as the data were integrated and transformed, and as information and knowledge can be extracted from DW. The structuring of the data stored in the metadata repository is done through rules defined in the ETL layer and by data models and descriptive tables of the DW layer. Staging Area 3.5. Analysis Area Layer 3.6. Metadata New Data Source ETL The DW layer represents integrated data marts. Dimensional model was used in the data model of the data marts and a bus matrix was elaborated to identify the intersection between the data marts. The dimensional model was used because, according to [21], there are two main advantages of using a dimensional model in data warehouse environments. At first, a dimensional model provides a multidimensional analysis space in relational database environments. At second, a typical and not normalized dimensional model has a simple schema structure, which it simplifies the processing of query and improves performance. In the definition of the DW data model, the first step is the definition of the data marts that are in a single data source initially. In the second step, the dimensions are identified for data marts defined in the first step and the intersection between the data marts and their dimensions are marked. In the third step, is elaborated the bus matrix. In the sequence, the granularity of the fact tables of the data marts would have to be declared. Also is verified which dimensions are related to these tables. Finally, are defined the facts that compose the fact tables. Following this implementation model, there is the possibility of superposition of facts between the fact tables of the data marts, and replication of dimensions. To solve this problem is used a common data area, which it consists of dimensions and facts used by several data marts. Migration for Standard Database Standard Data Source Source in other formats Figure 1. Proposed Architecture Data Sources 3.4. Data Warehouse Layer related with the complexity of the algorithms that implement the data mining techniques. The main objective of the data mining tool is to discover occult and relevant knowledge in the database. A simpler solution than data mining techniques is the use of materialized views. In this area there are many studies developing methods to facilitate queries and maintenance of data cubes. In [18] was developed several algorithms to compute set of aggregations related in data cube. An advantage of the use of materialized views is that the time of queries processing is lesser than other methods. A disadvantage is the great space in disk that is necessary to store the queries. A solution can be the use of dedicated disk storage for managing materialized views, separate from DW, and not decreasing the DW performance [20]. Metadata Repository idea of the attributes and sources tables necessary to populate the DW. The data staging should just contain necessary information to populate the warehouse. This layer and the ETL layer include all databases and tools that are necessary to transform, integrate, load, control the quality and clean the data [2]. The staging area, defined in this work, uses a normalized data model to allow a best data consistence and to facilitate the integration process among different databases. Besides the data of DW, the metadata should store data relative to the logical project, data model of the data marts, of the control area and of the aggregate; data relative to the physical project; data relative to the maintenance; and data relative to the queries of the users 4. DW for Management in S&T A DW for management in S&T was built following the defined steps for [17]. Initially a planning on the activities was made and had been identified the necessary resources. With the definition of the business requirements it was possible lists the data that need to be stored in the DW to give supported to the management in S&T. The DW was projected according to the star schema. This modeling has been chosen for the already presented advantages in this research work and because dimensional modeling is widely accepted as the viable technique for delivering data to final users in a DW [1], [7], [13], [17]. A Bus Matrix was used to define data integration rules. This matrix represents the fact and dimensions tables previously structured from way to maintain integration between the data marts, as shown in Figure 2. If occur superposition of dimensions in the data marts, is created a common area, as shown in DW layer of Figure 1, reducing the data replication between the data marts. The ETL, Staging Area and DW layers were projected and implemented using resources as triggers and stored procedures of SGBD Oracle [15], besides tools as ERWin [6] for data modeling, Rational Rose [10] for the project of the layers and Delphi [8] for creation of the module of migration of the ETL layer. The implementation of the migration module have been developed in Delphi 7.0 to make possible migration and integration of the data, because for each institution there was a different database of CAPES. The extraction, transformation and load module of the ETL layer was implemented through storedprocedures built with the PL-SQL language of Oracle, solution that was quite efficient in performance and flexibility. 4.1. Data Model of Staging Area The staging area modeling was made using the relational data model normalized together with techniques of the dimensional modeling, thus avoiding redundancy of the data and facilitating the conversion of the data for DW. The tables were modeled according to the BUS matrix, and the attributes of the tables are based in the defined dimensions. In the Figure 3 is shown a partial data model of staging area. The model is normalized, but it also possesses a modeling used in dimensional models in some relationships. This modeling is bases on the approach proposed by Kimball et al [17] in which for tables that possess fields with more of one value it is created a mini-dimension to support the several values of the field. To relate this mini-dimension with the derived table, it is created a bridge table, which creates a group of values for each individual that possesses some fields in mini-dimension. In the data model presents in the Figure 3 the tables in light gray indicate mini-dimensions, while the dark gray indicates bridge tables. Using this modeling in staging area the data integration from stage area to DW is easier and fast. Figure 2. Bus Matrix of DW Figure 3. Partial Data Model of Staging Area This same approach is used in the DW for dimensions that possess fields with more of one value. From the data sources until the data in the formats that appear in the model, shown in the Figure3, the following steps are executed: 1. Separating the data by granularity. 2. Cleaning values of attributes. 3. Transforming the data. 4. Changing the operational keys by substitute keys. 5. Guaranteeing the quality of the data. The uses of these steps give the follows benefits to the data: quality, standardization and consistency, facilitating the data integration and the data load in the DW. 4.2. Data Model of DW The DW was projected according to the star schema, however the star schema does not accept many-to-many relationships, and this type of relationship presented in the staging area of our project, was transformed into many-to-many relationships between facts and dimensions in the DW. According to Song et al [21], those relationships in a dimensional model causes several difficult issues, such as losing the star schema structure, increasing complexity in forming queries, and degrading query performance by adding more joins. Therefore, it is desirable that we handle the many-tomany relationships while still keeping the structure of the star schema. There are some works to solve this problem, as [22], [23], [24], [25], [26], [17]. Among these solutions, the chosen one was presented in [17]. The many-to-many relationships between facts and dimensions and the relationships between dimensions and mini-dimensions presented previously are shown in Figure 4. In Figure 4 it is also possible to verify that more than one fact table uses the same dimension, according to what was proposed with the use of the DW Bus architecture matrix. 4.3. Analysis Area In this layer were made some studies using different types of tools. Some case studies were accomplished with Oracle9i OLAP'S tool, but the need to follow very rigid steps through a pre-established model interfere a little his use. In the next section are presented some results of those case studies. 5 Case Studies A DW is an inquiry database that can aid in the process of decision making. Thus, in this section the results of case studies are presented accomplished with DW built, that integrate data about Brazilian research institution and researchers. In these studies, queries were made on intellectual property, and publication number of papers and books. Through queries to DW some results was obtained, some expected and others surprising. The analysis of these results must be made carefully, because the origin databases are slightly outdated (the data about postgraduate courses are of the year of 1998 and of Lattes Curriculum from 1997 to 1999) and only contain regional data, therefore the national reality can not be reflected, but give a good idea how is the behavior of research and of researchers in Brazil. Figure 4. Partial Data Model of DW 5.1. Study on Intellectual Property The Brazil has some problems because does not have the culture to make patents and registers. An example of this is that Japanese companies patented the process of cupuaçu (fruit from Brazil north region) derivatives. These companies there are five patents of products elaboration process with cupuaçu. The manufacture process was developed by the Emprapa (Brazilian Company of Agricultural Research), an agency of the federal government, and announced it has about three years, but it did not registered [12]. The application of DW demonstrated that amongst all the processes and products created by the researchers since 1990, only 0.08% patents were generated. 5.2. Time of Defense in the Programs of Master's degree The next inquiry of this section, show the relationship between master degree programs regime and the time that the students completes the master degree. The Figure 5 shows this relationship. The Figure 5 is divided in 3 parts. The first part is the conclusion time average general in master degree in accordance with the regime period. The second part is the conclusion time average in accordance with the regime period to students who entered in the master degree program before 1996, and the last part is the conclusion time average for students who entered in the master degree program from 1996. The conclusion time average in master degree programs from some years behind decrease a lot, as is showed in Figure 5. The year of 1996 was used as delimiter, therefore, through queries was perceived that it had a great difference between the conclusion time before and after this year. Through the Figure 5 it can be verified that, from the moment that the average of conclusion time in master degree programs decrease, the difference between regimes period time average is very small, only programs with annual regime period had presented a conclusion time average a little bigger. In this study is possible visualize the importance of DW, because it used data about postgraduate institution and researchers. 5.3. Published Books Nunber of Months Conclusion Time Average in Master Degree Programs 60 50 General Average 40 Annual 30 20 Semestral Quarterly 10 0 General Before 1996 Since 1996 Year of entrance in the Program Figure 5. Conclusion time average in master degree programs The Figure 6 shows comparison in the number of published books or books chapters between men and women in diverse range of age. The difference in the number of publications until 35 years between men and women is very small. In the range of the 35 until 45 years this difference increase, and in range of the 45 until 55 years it starts to decrease. Through the Figure 6 is not possible to know the reason in the increase of the difference in the number of published books between men and women. A possible cause would be that in this range of age the women had children, but this hypothesis cannot be evidenced, because the DW built does not contain personal data of the researchers that prove this. Num be r of Book Publication or Book Chapte r Number of Publication 6 5 4 Women 3 Men 2 1 data are not inserted in the correct time. This cause a problem for the fact of results could be masked. For example, many researchers, in a certain year, did not update their publications in the database and in the following year registered their publications, when a query will be made, the result will show that this year had a great increase in the publications, what would not be true. 0 25 25 to 35 35 to 45 45 to 55 55 Range of Age Figure 6. Number of book publication 6 Conclusions The success of a DW is directly related to the definition of implementation architecture and to the choice of a development methodology. The proposed architecture was developed based on the BUS Architecture and in the methodology of integrated and incremental data marts. Each layer of the architecture was projected from way to get the biggest possible independence, and the superior layer uses parameters of the layer immediately lower to it. The definition of the architecture worried with the integration of different data sources. To facilitate this integration, a reference format was specified. Whenever any data source is not in according to this format, the same is migrated for it. The methodology of integrated and incremental data marts makes possible the integration of different data sources bit by bit, in other words, the data of each origin database can be added in different moments. This characteristic of this methodology facilitated the implementation of DW with S&T databases, considering the existence of different data sources. It also turns possible the inclusion of new data sources in the future. The modelling of staging area worked very well. Using a relational normalized data modelling was obtained a bigger consistency of the data and was facilitated the process of integration between distinct databases, at the same time where it makes possible the use of denornormalized relationships, that behave like a guide to load data from staging area to DW, facilitating the integration with DW. In the DW was used the multidimensional modeling together with the modeling of bridges table proposed in [17]. In the development of the DW some problems have been found. The main problem was relative to the source databases. There are many laws that restrict the use of these databases. Another problem that was detected in elapsing of the project is a special problem in the development of DW for S&T. As the data in S&T are not updated through the transactions that happen day by day, but, from data insertions by the researchers, it is possible that many 7 Future Works As future works the following topics can be suggested: Incorporation of other data sources, such as the Directory of the Groups of Research of Brazil, IBGE (Brazilian Institute of Geography and Statistics) data, and other data about universities and research centers. Development of OLAP tools for search of knowledge in the DW. Specification and implementation of a specialist system for metadata management, with rules defined for the extraction and the analysis of the data. Implementation of graphic interfaces to facilitate analysis of the discovered knowledge by final users. The use of data in XML format. Definition of a results analysis method that verifies questions relative to the specific domain of S&T. Study of methods to handle the problem presented in the previous section relative to the specify S&T domain. References [1] B. Dinter, C. Sapia, G. Hofling, and M. Blaschka, “The Olap Market: State of the Art and Research Issues”, In: Proceedings of the ACM 1st International Workshop on Data Warehousing and Olap (DOLAP'98), Washington, United States of America, 1998, pp. 22-27. [2] C. Häberli, and D. Tombros, “A Data Warehouse Architecture for MeteoSwiss: An Experience Report”, In: International Workshop on Design and Management of Data Warehouses (DMDW’01), Zurich, Switzerland, 2001. [3] C. Shilakes, and J. Tylman, “Enterprise Information Portals. Enterprise Software Team”, Retrieved from http://www.sagemaker.com/company/downloa ds/eip/indepth.pdf, May, 2003. [4] CAPES, “Coordenação de Aperfeiçoamento de Pessoal de Nível Superior”, Retrieved from http://www.capes.gov.br, October, 2005. [5] CNPq, “National Council for Scientific and Technological Development”, Retrieved from http://lattes.cnpq.br/, October, 2005. [6] Computer Associates, “ERwin Brochure”, Retrieved from http://www3.ca.com/products/, October, 2005. [7] D. Meyere, and C. Cannon, Building a Better Data Warehouse, Prentice Hall, Inc., Upper Saddle River, New Jersey, United States of America, 1998. [8] Delphi 7.0, “Borland Delphi”, Retrieved http://www.borland.com/delphi/, October, 2005. from [9] H. S. Singh, Data Warehouse: Conceitos, Tecnologias, Implementação e Gerenciamento, Makron Books, Rio de Janeiro, Brasil, 2001. Data (SIGMOD’99), ACM Press, Philadelphia, Pennsylvania, United States of America, 1999, pp. 371-382. [21] Y. Song, W. Rowen, C. Medsker and E. Ewen, “An Analysis of Many-to-Many Relatioships Between Fact and Dimension Tabels in Dimensional Modeling”, In: Proceedings of International Workshop on Design and Management of Data Warehouses (DMDW’01), Zurich, Switzerland, 2001. [10] I. Jacobson, G. Booch, and J. Rumbaugh, The Unified Software Development Process, Addison-Wesley, New York, United States of America, 1999. [22] M. Krippendorf, M and Y. Song, “Translation of Star Schema into Entity-Relationship Diagrams, In: Proceedings of of 8th International Conference and Workshop on Database and Expert Systems Applications (DEXA97), 390-395, Toulouse, France, 1997. [11] I. Millet, D. H. Parente, and J. L. Fizel, “Data Warehouse Design for Ease of Data Transformation”, In: Proceedings of the 4th International Workshop on Design and Management of Data Warehouses, Toronto, Canada, 2002, pp. 82-89. [23] D. Theodoratos and T. Sellis, “Data Warehouse Schema and Instance Design”, In: Proceedings of 17th International Conf. On Conceptual Modeling (ER98), 363-376, Singapore, 1998. [12] L. Indriunas, “Biopirataria - O Brasil se defende”, In: Revista Super Interessante, Edição 193, Nº. 24, 2003. [24] W. Lehner, J. Albrecht and H. Wedekind, “Normal Forms for Multidimensional Databases”, In: Proceedings of SSDBM, 63-72, 1998. [13] M. Axel, and Y. Song, “Data Warehouse Design for Pharmaceutical Drug Discovery Research”, In: Proceedings of the 8th International Conference and Workshop on Database and Expert Systems Applications (DEXA’97), Toulouse, France, 1997, pp. 644-650. [14] M. Shaw, and D. Garlan, Software Architecture: Perspectives on an Emerging Discipline, Prentice Hall, Inc., Upper Saddle River, New Jersey, United States of America, 1996. [15] Oracle9i, “Oracle9i Database”, Retrieved from http://otn.oracle.com/software/products/oracle9i/, October, 2005. [16] R. Dumoulin, “Architecting Data Warehouses for Flexibility, Maintainability, and Performance”, Retrieved from http://www.olap.it/Articoli/architectingdwh.pdf, October, 2005. [17] R. Kimball, L. Reeves, M. Ross, and W. Thornthwaite, The Data Warehouse Lifecycle Toolkit: Expert Methods for Designing, Developing, and Deploying Data Warehouses, John Wiley & Sons Inc., New York, United States of America, 1998. [18] S. Agrawal, R. Agrawal, P. M. Deshpande, A. Gupta, J. E. Naughton, R. Ramakrishnan, and S. Sarawagi, “On the Computation of Multidimensional aggregates”, In: Proceedings of the 22nd International Conference on Very Large Databases (VLDB’96), Mumbai, India, 1996, pp. 506521. [19] W. H. Inmon, Como Construir o Data Warehouse, 2ª. Edição, Campus, Rio de Janeiro, Brasil, 1997. [20] Y. Kotidis, and N. Roussopoulos, “Dynamat: A Dynamic View Management System for Data Warehouses”, In: A. Delis, C. Faloutsos, and S. Ghandeharizadeh, eds, Proceedings ACM SIGMOD International Conference on Management of [25] T. Pedersen and C. Jensen, “Multidimensional Data Modeling for Complex Data”, In: Proceedings of 15th ICDE, 336-345, Sidney, Australia, 1999. [26] D. Moody and M. Kortink, “From Enterprise Models to Dimensional Models: A Methodology for Data Warehouse and Data Mart design”, In: Proceedings of Int’l Workshop on Designand Management of Data Warehouses (DMDW2000), Stockholm, Sweden, 2000. [27] P. Vassiliadis, “Guliver in the lan of data warehousing: pratical experiences and observations of a researcher”. In: Proceedings of Int’l Workshop on Designand Management of Data Warehouses (DMDW2000, Stockholm, Sweden, 2000.