DNA Replication and Protein Synthesis Activity

Directions for DNA Replication and Protein Synthesis Activity (Insulin Activity)
I use this activity to reinforce DNA Replication and Protein Synthesis AFTER I have already taught these to the students. I highly recommend using the DNA replication, transcription and translation animations available from the
DNALC website (www.dnalc.org/resources/animations) when teaching these concepts. In addition to reinforcing these concepts, this lesson helps:
introduce students to peer-reviewed journal articles
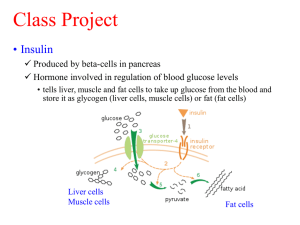
provide a basis for learning about insulin, diabetes, the pancreas, endocrinology, etc
provide an example of how mutations cause genetic diseases (type 1 diabetes)
provide a solid example for the roles of the ER and golgi bodies in cells
You could either do this activity with each class, or to reduce the amount of time and supplies needed, combine the efforts from multiple classes. For example, each class would create a portion of the DNA and then you would join the sections to create the complete DNA. Then each class would create a portion of the mRNA and then you would join the sections to create the complete mRNA; and finally, each class would decode and create a section of the preproinsulin amino acid sequence and you would join those to create the complete preproinsulin polypeptide.
Finally, you would demonstrate the post-translational modifications for each class using the completed preproinsulin polypeptide.
DNA Replication
1.
Divide students into groups of 4-5 students (preferably 5 students per group)
2.
Pass out the Preproinsulin journal article entitled “Nucleotide Sequence of Human Preproinsulin
Complementary DNA.” This research article was published in 1980 and was among early work to uncover the structure and process of synthesizing insulin. I personally take time to read through the article with my students and do an entire lesson about peer-reviewed journal articles (see my slides from my CSTA presentation on using peer-reviewed journal articles in the classroom); however, you could just use it for its printed source of the preproinsulin gene, which is a comparatively short gene and so is good for using in DNA replication and protein synthesis modeling activities like this one.
3.
Following the instructions on the Insulin Activity worksheet, teams of students should use the given mRNA sequence printed in the research article to construct the DNA sequence for the preproinsulin gene using the nucleotide sheets provided. Students should cut out the nucleotides and tape them together in the correct order. Students should create two complementary strands. If you don’t have a color printer, you may want to print different nucleotides on different colored paper. Be careful not to confuse the ribonucleotides with the deoxyribonucleotides. This will take students a LONG time. You may want to divide the gene up so that each group does a different section. Or assign it as a homework assignment (in which case, each group member would take a segment home to complete and bring back).
4.
Following the instructions on the Insulin Activity worksheet, teams of students should work together in the roles designated to replicate the preproinsulin gene. This will take a long time so I recommend you only have students replicate the first 100 nucleotides, or however much is needed for you to see that they understand the process. This step is when the DNA Replication animation from the DNALC website really comes in handy.
Protein Synthesis
5.
In a separate or follow up activity, have the student teams create the preproinsulin mRNA using the ribonucleotide sheets provided. Students should cut out the ribonucleotides and tape them together in the correct order. If you did the DNA replication activity with them above, you can have them use the DNA and act out the steps of transcription in a similar manner. Use the Transcription animation from the DNALC website to help. If you did not do the DNA Replication activity with them, then have them use the mRNA sequence in the research paper as their guide. To save time, you can assign different groups to complete different sections of the mRNA and then join them together.
6.
Have students model translation by having them pretend to be ribosomes and putting the amino acids in the correct order according to the mRNA sequence of ribonucleotides. Use the attached RNA decoder, or provide one of your own. You can introduce additional factors like tRNA and models of the ribosomal structure if you’d like. The amino acids are available on one of the sheets included with the Insulin Activity worksheet. Each amino acid shows the basic structure of amino acids but contains a box that represents the functional group.
Students should fill in the abbreviation for each amino acid in this box to specify which it is as they join these together to form the preproinsulin polypeptide. To save time, you can assign different groups to complete different sections of the polypeptide and then join them together. Use the Translation animation from the
DNALC website to help.
RNA Decoder for the Protein Synthesis Activity
7.
Use the final preproinsulin polypeptide created by the class to demonstrate the post-translational modifications that occur in processing the preproinsulin polypeptide into the final insulin protein. These are detailed to some extent in the research article, but you can find out more by doing a little online research. I have attached a useful diagram that I found on Wikipedia (don’t tell the kids!) that demonstrates the process.
More is available in my slides from my CSTA presentation on using peer-reviewed journal articles in the classroom. Here are some additional helpful sites:
http://www.vivo.colostate.edu/hbooks/pathphys/endocrine/pancreas/insulin.html
http://themedicalbiochemistrypage.org/insulin.php
I like to pretend like our classroom is a cell and block off regions that represent the ER and golgi, assign students jobs, and act out the process. a.
The preproinsulin polypeptide is synthesized in Beta islet cells of the pancreas via ribosomes on the external membrane of the ER. The signal region at the start of the polypeptide, also known as the D chain, binds to a receptor on the outside of the ER and the remaining portion of the preproinsulin polypeptide moves through the channel and into the ER. b.
The D chain is cleaved by a protease and the resulting polypeptide is called proinsulin. c.
Inside the ER, the proinsulin polypeptide folds into a stable shape facilitated by the C chain so that three disulfide bonds form correctly between the A chain and the B-chain. d.
Proinsulin is transported from the ER into the golgi, where it is packaged into secretory vesicles along with endopeptidases that cleave the C chain from the polypeptide, forming the final insulin protein.
Insulin is actually two polypeptides (the A chain and B chain) held together in their quaternary structure by three disulfide bonds. e.
The secretory vesicles fuse with the cell membrane to release insulin into the blood in response to a signal cascade triggered by increased levels of glucose in the blood.
Diagram of Post Translational Modifications for Insulin for the Protein Synthesis Activity
Cytosol
ER
Lumen
Golgi
Secretory
Vesicle