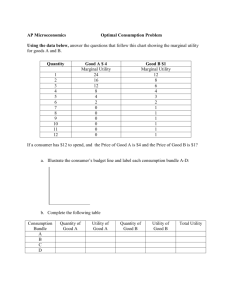
Multiple_discrete - Department of Civil Engineering
advertisement

The Generalized Multiple Discrete-Continuous Extreme Value (GMDCEV) Model: Allowing for Non-Additively Separable and Flexible Utility Forms Chandra R. Bhat The University of Texas at Austin Department of Civil, Architectural & Environmental Engineering 1 University Station C1761, Austin, Texas 78712 Tel: 512-471-4535, Fax: 512-475-8744 Email: bhat@mail.utexas.edu and Abdul Rawoof Pinjari University of South Florida Department of Civil & Environmental Engineering 4202 E. Fowler Ave., ENB 118, Tampa, Florida 33620 Tel: 813-974-9671, Fax: 813-974-2957 Email: apinjari@usf.edu ABSTRACT Many consumer choice situations are characterized by the simultaneous demand for multiple alternatives that are imperfect substitutes for one another. A simple and parsimonious Multiple Discrete-Continuous Extreme Value (MDCEV) econometric approach to handle such multiple discreteness was formulated by Bhat (2005) within the broader Kuhn-Tucker (KT) multiple discrete-continuous economic consumer demand model of Wales and Woodland (1983). However, the MDCEV model, and other extant multiple discrete-continuous models, use an additively-separable utility function, with the assumption that the marginal utility of one good is independent of the consumption of another good. The implication is that the marginal rates of substitution between any pair of goods is dependent only on the quantities of the two goods in the pair, and independent of the quantity of other goods, thus substantially reducing the ability of the utility function to accommodate rich and flexible substitution patterns. Also, the specification of a quasiconcave and increasing utility function with respect to the consumption of goods in extant models, when coupled with the additive utility across goods, immediately implies that goods cannot be inferior and cannot be complements. In this paper, we develop a closedform model formulation for multiple discrete-continuous choices that allows a non-additive utility structure, and accommodates rich substitution structures and complementarity effects. As importantly, the utility functional form proposed here remains within the class of flexible forms, while also retaining global theoretical consistency properties (unlike the Translog and related flexible quadratic functional forms). The result is also clarity in the interpretation of the model parameters. The proposed Generalized Multiple DiscreteContinuous Extreme Value (GMDCEV) model is easy to estimate, and should represent a substantially more accurate representation of the underlying behavioral process for many multiple discrete-continuous choice situations. Keywords: Discrete-continuous system, Multiple discreteness, Kuhn-Tucker demand systems, Mixed discrete choice, Random Utility Maximization, Non-additively separable utility form. 1. INTRODUCTION Several consumer demand choices related to travel and other decisions are characterized by a discrete dimension as well as a continuous dimension. Examples of such choice situations include vehicle type holdings and usage, appliance choice and energy consumption, housing tenure (rent or purchase) and square footage, brand choice and quantity, and activity type choice and duration of time investment of participation. There is a substantial amount of literature now that underscores the importance of considering the interrelatedness in the discrete and continuous dimensions of choice to obtain unbiased statistical estimates of model parameters. Two broad model structures may be identified in the literature to handle such discrete-continuous choice situations. The first structure (sometimes referred to as the “reduced-form” structure) typically has a separate equation for the discrete choice and another separate equation for the continuous choice, with jointness introduced through the statistical correlation in the random stochastic components of each equation. This first structure has seen extensive use and has proved useful to handle many empirical situations, but it is not based off an underlying (and unifying) theoretical economic model. The second structure to discrete-continuous choice modeling, and the one of interest in this paper, originates from microeconomic consumer utility maximization theory. While much work in the context of consumer utility maximization has been focused on the case of a single discrete-continuous (SDC) choice situation (where the choice involves the selection of one of many alternatives and the continuous dimension associated with the chosen alternative), there has been increasing interest and research recently in the multiple discrete-continuous choice (MDC) situation (where the choice situation involves 1 the selection of one or more alternatives, along with a continuous quantity dimension associated with the consumed alternatives). 1.1. MDC Context and Utility Framework Multiple discrete-continuous (MDC) choice situations are quite ubiquitous in consumer decision-making, and constitute a generalization of the more classical single discretecontinuous choice situation. Examples of MDC contexts include the participation decision of individuals in different types of activities over the course of a day and the duration in the chosen activity types (see Bhat, 2005), and household holdings of multiple vehicle body/fuel types and the annual vehicle miles of travel on each vehicle (Bhat et al., 2009, Ahn et al., 2008). There are several differences between the single discrete choice (SDC) and MDC utility frameworks, primarily originating in the functional form of the utility function. MDC models typically assume imperfect substitution among alternatives based on a more general utility function than the SDC case, which assumes perfect substitution among alternatives. But, at a basic level, the choice process faced by the consumer in both the SDC and MDC situations is formulated as follows: K Max U ( x) subject to p k 1 k x k E , x k 0, (1) where U(x) is the utility function corresponding to a consumption vector x, p k is the unit price of good k, and E is the total expenditure. Note that the vector x may or may not include an outside composite (or numeraire) good that is always consumed and has a unit price equal to unity. 2 The functional form of the utility function U(x) determines the characteristics of, and the solution for, the constrained utility maximization formulation of Equation (1). More importantly, the functional form determines whether the formulation corresponds to an SDC or an MDC model. For instance, Hanemann (1984) considers the “perfect substitutes” case when he writes the utility function U(x) as follows (Hanemann considers an outside good, which we will assume to be good 1): K U ( x ) U * ( k x k , x1 ), (2) k 2 where U * is a bivariate utility function and k (k = 2, …, K) represents the quality index specific to each inside good k. This functional form assures that, in addition to the outside good which is consumed, exactly one inside good (k = 2, 3, …, K) is also consumed. Hanemann (1984) refers to this as the “extreme corner solution”.1 As is typical in SDC analysis, rather than deriving the consumption function based on solving the constrained maximization problem of the direct utility function in Equation (2), Hanemann assumes a functional form for the indirect utility function, introduces random stochasticity into the formulation, and then derives expressions for the probabilities of the discrete and continuous choices. Chiang (1991) and Chintagunta (1993) extend Hanemann’s SDC formulation to include the possibility of no inside goods being selected for consumption by including a “reservation price”. If the quality-adjusted prices of all the inside goods exceed the reservation price, no inside goods are selected, but if the quality adjusted prices of one 1 Of course, the utility function in Equation (2) is easily modified for the case when there is no outside good, and only one of the inside goods is consumed. In this case, the utility function becomes U ( x ) K k xk . k 2 This, of course, corresponds to the case of the traditional discrete choice model, since all the expenditure is on the chosen good and so the continuous component drops out. 3 or more of the inside goods are below the reservation price, an inside good is selected based on Hanemann’s framework. The demand functions for the continuous components of choice are obtained using Roy’s identity (Roy, 1947). As indicated above, SDC analysis is usually undertaken using an indirect utility approach, based on the argument that it is usually difficult and, often intractable, to adopt a direct utility approach for estimating parameters and obtaining analytic expressions for demand functions. However, as clearly articulated by Bunch (2009), the direct utility approach has the advantage of being closely tied to an underlying behavioral theory, so that interpretation of parameters in the context of consumer preferences is clear and straightforward. Further, the direct utility approach also provides insights into identification issues. Of course, when one moves to the MDC models, the indirect utility approach all but falls apart because multiple inside goods can be selected for consumption and nonnegativity of the consumption vector must be guaranteed (see Wales and Woodland, 1983). Thus, in addition to conceptual and behavioral advantages, it has been the norm to examine MDC situations using the direct utility approach, especially because, through clever stochastic term distribution assumptions, one can obtain a closed form for the probability of the consumption patterns of goods. Earlier direct utility-based MDC models have their origins in Hanemann’s (1978) and Wales and Woodland’s (1983) Kuhn-Tucker or KT first-order conditions approach for constrained random utility maximization. This approach assumes the utility function U(x) to be random (from the analyst’s perspective) over the population, and then derives the consumption vector for the random utility specification subject to the linear budget constraint by using the KT conditions for constrained optimization. All earlier MDC 4 models (with the exception of a recent study by Vasquez-Lavin and Hanemann, 2008) have adopted, as in the SDC case, an additively separable utility function, which assumes that the marginal utility of one good is independent of the consumption of another good. This assumption has at least two important implications. First, the marginal rate of substitution between any pair of goods is dependent only on the quantities of the two goods in the pair, and independent of the quantity of other goods. As indicated by Pollak and Wales (1992), this has consequences on the preferences directly. For example, let there be three food items: milk (x1), cornflakes (x2), and raisin bran (x3). Consider an individual who tends to have milk and cornflakes, or milk and raisin bran, but not milk alone. Such an individual may prefer the triplet [20,1,20] over [10,10,20], but may also prefer [10,10,1] over [20,1,1]. This violates additive utility, because, if the individual prefers [20,1,20] over [10,10,20], s/he must prefer [20,1,x3] over [10,10,x3] according to additive utility. Overall, the additively separable assumption substantially reduces the ability of the utility function to accommodate rich and flexible substitution patterns. Second, the specification of a quasiconcave and increasing utility function with respect to the consumption of goods, along with additive utility across goods, immediately implies that goods cannot be inferior and cannot be complements (i.e., they must be strict substitutes; see Deaton and Muellbauer, 1980, page 139). 1.2. Paper Objectives and Structure The objective of this paper is to extend Bhat’s (2008) multiple discrete-continuous extreme value (MDCEV) model to relax the assumption of an additively separable utility function. In doing so, we propose a particular utility functional form that remains within the class of 5 flexible forms, while also retaining global theoretical consistency properties. The form also allows clarity in the interpretation of parameters and helps understand identification issues. In addition, we show that, with a specific way of introducing stochasticity, we are able to retain the closed form and simple nature of the MDCEV formulation. The structure of the Jacobian in the likelihood function is also relatively simple because of the way stochasticity is introduced. The non-additively separable utility-based MDCEV (i.e. the Generalized MDCEV or GMDCEV) model can be compared with the basic MDCEV model using wellestablished likelihood ratio tests to examine the hypothesis of additively separable utility. The rest of this paper is structured as follows. The next section formulates a functional form for the non-additive utility specification that enables the isolation of the role of different parameters in the specification. This section also identifies empirical identification considerations in estimating the parameters in the utility specification. Section 3 discusses the stochastic form of the utility specification, the resulting general structure for the probability expressions, and associated identification considerations. For presentation ease, Sections 2 and 3 consider the case of the absence of an outside good. In Section 4, we extend the discussions of the earlier sections to the case when an outside good is present. Section 5 provides an empirical demonstration of the GMDCEV model proposed in this paper. The final section concludes the paper. 2. FUNCTIONAL FORM OF UTILITY SPECIFICATION The starting point for our utility functional form is Bhat (2008), who proposes a linear BoxCox version of the constant elasticity of substitution (CES) direct utility function for MDC models: 6 K U ( x) k 1 k k xk k 1 1 k k (3) where U(x) is a strictly quasi-concave, strictly increasing, and continuously differentiable function with respect to the consumption quantity (Kx1)-vector x ( xk 0 for all k), and k , k and k are parameters associated with good k. The function in Equation (3) is a valid utility function if k 0 , k 0 , and k 1 for all k. For presentation ease, we assume temporarily that there is no outside good, so that corner solutions (i.e., zero consumptions) are allowed for all the goods k (this assumption is being made only to streamline the presentation and should not be construed as limiting in any way; in fact, as we will show later, the econometrics become much easier when there is an outside good). The possibility of corner solutions implies that the term k , which is a translation parameter, should be greater than zero for all k.2 The reader will note that there is an assumption of additive separability of preferences in the utility form of Equation (3). Bhat’s utility form clarifies the role of the various parameters k , k and k , and explicitly indicates the inter-relationships between these parameters that relate to theoretical and empirical identification issues.3 In particular, k represents the baseline marginal utility, or the marginal utility at the point of zero consumption. Thus, a higher baseline k 2 As illustrated in Kim et al. (2002) and Bhat (2005), the presence of the translation parameters makes the indifference curves strike the consumption axes at an angle (rather than being asymptotic to the consumption axes), thus allowing corner solutions. 3 The utility formulation of Equation (3) also imposes the untestable, but intuitive, condition of weak complementarity (see Mäler, 1974), which implies that the consumer receives no utility from a non-essential good’s attributes if s/he does not consume it (i.e., a good and its quality attributes are weak complements, or Uk = 0 if xk = 0, where Uk is the sub-utility function for the kth good). The reader is referred to Hanemann (1984), von Haefen (2004), and Herriges et al. (2004) for a detailed discussion of the advantages of using the weak complementarity assumption. 7 implies less likelihood of a corner solution for good k. k is the vehicle to introduce corner solutions for good k (that is, zero consumption for good k). But it also serves the role of a satiation parameter that determines the rate at which the marginal utility of good k decreases with consumption of the good; the higher the value of k , the less is the satiation effect in the consumption of x k . The entire range of satiation effects from immediate and full satiation (flat line) to linear satiation (constant marginal utility) can be accommodated by different values of k . Finally, the express role of k is to capture satiation effects. When k 1 for all k, this represents the case of absence of satiation effects or, equivalently, the case of constant marginal utility. The utility function in Equation (3) in such a situation collapses to k xk , which represents the perfect substitutes case as k proposed by Deaton and Muellbauer (1980) and applied in Hanemann (1984), Chiang (1991), Chintagunta (1993), and Arora et al. (1998), among others. Intuitively, when there is no satiation, the consumer will invest all expenditures on the single good with the highest price-normalized marginal (and constant) utility k / pk . This is the case of single discreteness. As k moves downward from the value of 1, the satiation effect for good k increases. When k 0 k , the utility function collapses to the following linear expenditure system (LES) form: K x U ( x ) k k ln k 1 k 1 k (4) The LES form above is empirically indistinguishable or similar to the functional form used in the environmental economics literature (von Haefen et al., 2004, Mohn and Hanemann, 8 2005, von Haefen and Phaneuf, 2005, von Haefen, 2003, Phaneuf et al., 2000, Phaneuf and Herriges, 2000, and Herriges et al., 2004). Overall, k , in addition to allowing corner solutions, controls satiation by translating consumption quantity, while k controls satiation by exponentiating consumption quantity. Clearly, both these effects operate in different ways, and different combinations of their values lead to different satiation profiles. However, empirically speaking, it is very difficult to disentangle the two effects separately, which leads to serious empirical identification problems and estimation breakdowns when one attempts to estimate both k and k parameters for each good. Thus earlier studies have either constrained k to zero for all goods (technically, assumed k 0 k ) and estimated the k parameters, or constrained k to 1 for all goods and estimated the k parameters. This is discussed in detail by Bhat (2008), who suggests testing both these normalizations and selecting the model with the best fit. Vasquez-Lavin and Hanemann (2008) extended Bhat’s additively separable linear Box-Cox form and presented a quadratic version of it, as below: K U ( x) k 1 k k k m x m x m 1 K k 1 1 1 1 k km 2 m 1 m m k (5) where k 0 , k 0 , and k 1 for all k. The new interaction parameters km allow quadratic effects (when k = m) as well as allow the marginal utility of good k to be dependent on the level of consumption of other goods (note that km = mk for all k and m). Of course, if km 0 for all k and m, the utility function collapses to Bhat’s linear Box-Cox 9 form. If k 0 k , the function collapses to the well-known direct basic translog utility function (see Christensen et al., 1975), and if k 1 k , we obtain the quadratic utility function used by Wales and Woodland (1983). The quadratic form of Equation (5) is a flexible functional form that has enough parameters to provide a second-order approximation to any true unknown direct twice-differentiable utility functional form. It also is a non-additive functional form. However, the flexibility is also a limitation, since the function can provide nonsensical results and be theoretically inconsistent for some combinations of the parameters and consumption bundles, an issue that has not received much attention in the literature (but see Sauer et al., 2006). In fact, it is not possible to achieve global consistency (over all consumption bundles) in terms of the strictly increasing and quasi-concave nature of the utility function using the translog form. In the next section, we extend Vasquez-Lavin and Hanemann’s discussion to clarify the role of parameters, identify issues of theoretical consistency and restrictions that need to be maintained, present identification considerations, and recommend a flexible form similar to the translog but that is easier to estimate and reduces global inconsistency problems associated with the translog. 2.1 Role of Parameters in Non-Additively Separable Utility Specification 2.1.1. Role of k The marginal utility of consumption with respect to good k can be written from Equation (5) as: 10 U ( x ) x k 1 x k k k 1 m K m x m 1 1 k km m 1 m m (6) The difference between the above expression and the corresponding one in Bhat’s (2008) linear Box-Cox additively separable case is the presence of the second term in parenthesis, which includes the consumptions of other goods. Thus, the formulation is not additively separable, but one in which the marginal utility of a good is dependent on the consumption amounts of other goods. The marginal utility at zero consumption of good k collapses to: U ( x ) x k xk 0 m m x m k k km 1 1 m m m k (7) From above, it is clear that k is no more the baseline (marginal) utility of good k at the point of zero consumption of good k. Rather, it should be viewed as the baseline (marginal) utility of good k at the point at which no good has yet been “consumed”; that is, when xm 0 m (no consumption decision has yet been made). This also indicates that, if prices of all goods are the same, then the good with the highest value of k will definitely see some positive consumption.4 Another important point to note from Equation (6) is that for the utility function to be strictly increasing, the following condition should be satisfied for all possible values of the consumption vector x: 4 If there is price variation across goods, one needs to take the derivative of the utility function with respect to expenditures (ek = pk xk ) on the goods. Then ∂U / ∂ek = ψk / pk at the point of no consumption of any goods, and the good with the highest price-normalized marginal utility ψk / pk will definitely see some positive consumption. 11 m K m x m 1 1 0 for all k. k km m 1 m m (8) This is in addition to the condition in the linear case where k 0 k . The condition above is needed because we are considering the case of economic goods. In addition, a sufficiency condition for maintaining the decreasing marginal utility (or strict quasiconcavity) of the utility function is that the left side of Equation (8) be a non-increasing function of xk. We return to these conditions later in the paper. 2.1.2. Role of k As in the linear case, the k parameter allows for corner solutions. In particular, the k terms shift the position of the point at which the indifference curves are asymptotic to the axes from (0,0,0…,0) to ( 1 , 2 , 3 , ..., K ) , so that the indifference curves strike the positive orthant with a finite slope. This, combined with the consumption point corresponding to the location where the budget line is tangential to the indifference curve, results in the possibility of zero consumption of good k. In addition to allowing corner solutions, the k terms also serve as satiation parameters. In general, the higher the value of k , the less is the satiation effect in the consumption of x k . However, unlike the linear case, k affects satiation for good k in two ways. The first effect is through the first linear term on the right side of Equation (5), and the second is through the second term on the right side of Equation (5) that generates quadratic effects. The overall effect depends on the sign and magnitude of the parameter kk in the second term. If this term is negative, and 12 particularly for high values of k , we can get an inappropriate parabolic shape for the contribution of alternative k to overall utility within the range of x k . In particular, beyond a certain point of consumption of alternative k, there is negative marginal utility. This is because of the violation of the condition in Equation (8). An illustration is provided in Figure 1, which plots the utility contribution of alternative k for k 1 , k 0 , kk 0.02 , km 0 m k , and different values of k ( k = 1, 10, and 30). As can be observed, for the k value of 30, we get a profile that peaks at about 110 units, and violates the requirement that the utility function be strictly increasing. On the other hand, if kk is positive and quite high in magnitude, it is possible that, for high k values, there is in fact an increase in the marginal utility effect at low values of x k (essentially a violation of the strictly quasi-concave assumption of the utility function). This is because the left side of Equation (8) becomes an increasing function of x k at low x k values. Figure 2 illustrates such a case for k 1 , k 0 , kk 0.2 , km 0 m k , and different values of k ( k = 1, 10, and 30). For k = 10, one can discern the increasing marginal utility until about 6.5 units after which the shape becomes one of decreasing marginal utility. The increasing marginal utility at low values is particularly pronounced for k = 30, which continues until a value of 40 units before starting to decrease in marginal utility. We will return to these issues in Section 2.2. The translation parameters m of other goods also have an impact on the utility contribution of good k, through the influence on the baseline (marginal) utility of good k 13 (see Equation (7)). Specifically, for a given value of x m , the baseline (marginal) utility for good k increases as m increases for positive km values and decreases as m increases for negative km values. 2.1.3. Role of k The express role of k is to reduce the marginal utility with increasing consumption of good k; that is, it represents a satiation parameter. However, as in the case of the k effect on consumption of good k, there are two effects of the k parameter – one through the first linear term on the right side of Equation (5) and the second through the quadratic effect caused by the combination of the first and second terms on the right side of Equation (5). The overall k effect depends on the sign and magnitude of the parameter kk in the second term. If this term is negative, and particularly for values of k close to 1, we can get a “nonsensical” parabolic shape for the utility contribution of alternative k within the usual possible range of x k . An illustration is provided in Figure 3, which plots the utility contribution of alternative k for k 1, k 1 , kk 0.03 , km 0 m k , and different values of k . As can be observed, at the k value of 0.6, we get a profile peaks at about 150 units and decreases thereafter, violating the requirement that the utility function be strictly increasing. On the other hand, if kk is positive and quite high in magnitude, it is possible that, for high k values, there is in fact an increase in the marginal utility effect at some low values of x k . Figure 4 illustrates such a case for k 1, k 1 , kk 0.2 , 14 km 0 m k , and different values of k . The non-conforming utility profile is obvious for the k value of 0.8. The m parameters for other goods also impact the baseline (marginal) utility of good k (see Equation (7)). For a given value of x m , the baseline (marginal) utility for good k decreases as m falls down from 1 for positive km values and increases as m falls down from 1 for negative km values. 2.2. Empirical Identification Issues Associated with Utility Form The total number of parameters in the flexible utility functional form of Equation (5) rises rapidly with the number of alternatives, especially in the km terms (k = 1, 2, …, K; m = 1, 2, …, K). There are also identification issues that arise with the utility form. As in the linear case, empirically speaking, it is next to impossible to disentangle the effects of the k and k parameters for each good separately (see Bhat, 2008). Thus one has to impose some constraints on the k and k parameters. While many combinations of constraints are possible, the easiest approaches are to constrain k to zero for all goods (technically, assume k 0 k ) and estimate the k parameters (the profile), or constrain k to 1 for all goods and estimate the k parameters (the profile). In the case of the non-additively separable utility function, there is an additional empirical identification issue in both the profile case and the profile case. This is because the kk parameters in the quadratic utility functional form essentially also serve as 15 “satiation” parameters by providing appropriate curvature to the utility function. However, empirically speaking, it is difficult to disentangle the kk effects from the k effects (for the profile) and from the k effects (for the profile) as long as the kk effects do not become that negative as to bring on a parabolic shape at even low to moderate consumption levels (this latter case would anyway be inappropriate to represent the utility function). In fact, a utility profile based on a combination of kk and k values for the profile case can be closely approximated by a utility function based solely on k values with kk 0 . Similarly, a utility profile based on a combination of kk and k values for the profile case can be closely approximated by a utility function based solely on k values with kk 0 . This is illustrated in Figures 5 for the profile, with k 1 , k 0 k , and km 0 m k . The figure shows that alternative k’s contribution to utility based on a certain combination of k and kk values can be closely replicated by other combination values of k and kk . In particular, the utility profiles corresponding to combinations of k and kk values can be replicated very closely by a profile that corresponds to k 1 and some specific kk value, or by a profile that corresponds to kk 0 and some specific k value. Thus, in Figure 5, the utility profiles corresponding to k 7.45 and kk 0 , and k 1 and kk 1.3 , are able to closely replicate all the other utility profiles. A similar situation may be observed from Figure 6 for the profile, where the utility profiles of different combinations of kk and k values can be approximated closely by the profile corresponding to k 0.442 and kk 0 , and k 0 and kk 1.38 . 16 The discussion above suggests that, without loss of empirical generality, one can normalize k 1 (and estimate kk ) or set kk 0 (and estimate k ) for each good k in the profile case. In the profile case, one can normalize k 0 (and estimate kk ) or set kk 0 (and estimate k ) for each good k in the utility function. We propose to set kk 0 for each good, since this immediately removes the possibility of a parabolic shape for the utility contribution of good k. At the same time, we immediately ensure that the marginal utility is strictly decreasing over the entire range of consumption values of the good k. These are important theoretical considerations that we are able to maintain globally without any loss in functional form flexibility. In fact, the functional form proposed in this paper remains within the class of flexible forms, while also retaining global theoretical consistency properties (unlike the translog and related flexible quadratic functional forms). The result is also clarity in the interpretation of the k and k parameters, which now have the same interpretation as satiation parameters corresponding to good k as in the linear utility function case of Bhat (2008). Besides, the baseline marginal utility of good k now remains unchanged with the consumption of good k, which is intuitive. There is still, however, one remaining issue, which is that the baseline marginal utility of all goods should be positive ( k 0 , k = 1, 2, …, K). The only way this condition will hold globally is if km 0 for all k and m (see Equation (7)). The condition km 0 implies that the goods k and m are complements (since the consumption of good m would increase the baseline marginal utility of good k and therefore consumption of good k). However, we would also like to allow rich substitution patterns in the utilities of goods by 17 allowing km 0 for some pairs of goods. As we discuss later, our methodology accommodates this, while also recognizing the constraint k 0 (k = 1, 2, …, K) during estimation and ensuring that it holds in the range of consumptions observed in the data. To summarize, we propose the following general formulation for the non-additively separable utility specification: K U ( x) k 1 k k k m x m x m 1 k 1 1 1 1 k km 2 mk m m k (9) In the above function, the analyst will need to set k 0 k and estimate the profile, or set k 1 and estimate the profile. The profile takes the following form: K x x 1 U ( x ) k ln k 1 k km m ln m 1 , 2 m k k 1 k m (10) and the profile takes the following form: K 1 x k 1k 1 k 1 km x m 1m 1 . U ( x ) 2 mk m k 1 k (11) In actual application, it would behoove the analyst to estimate models based on both the estimable profiles above, and choose the one that provides a better statistical fit. In the rest of this paper, we will use the general form in Equation (9) for ease in presentation. 18 3. THE ECONOMETRIC MODEL 3.1. Optimal Expenditure Allocations The consumer maximizes utility U(x) as provided by Equation (9) subject to the budget constraint that K K k 1 k 1 pk xk ek E , where pk is the unit price of good k, ek is the expenditure on good k, and E is total expenditure across all goods. The analyst can solve for the optimal expenditure allocations by forming the Lagrangian and applying the KuhnTucker (KT) conditions. The Lagrangian function for the problem is: K L U ( x ) ek E , k 1 (12) where is the Lagrangian multiplier associated with the expenditure constraint (that is, it can be viewed as the marginal utility of total expenditure or income). The KT first-order conditions for the optimal expenditure allocations (the ek* values) are given by: k ek* 1 pk pk k k ek* 1 pk pk k k 1 0, if ek* 0 , k = 1, 2, …, K (13) k 1 0, if ek* 0 , k = 1, 2, …, K, where k is the baseline utility of good k as given in Equation (7). 3.2. Introducing Stochasticity To complete the econometric model, the analyst needs to introduce stochasticity. This is an important component of the model formulation, since how one decides to do so can make the difference between analytically tractable and intractable models. In Bhat’s additively 19 separable form of the utility function (and in other restricted versions of this formulation), the baseline marginal utility term k collapses to k , and stochasticity has been introduced through a multiplicative random element as follows: k ( zk , k ) ( zk ) e , k (14) where zk is a set of attributes characterizing alternative k and the decision maker, and k is an extreme value error term that captures idiosyncratic (unobserved) characteristics that impact the baseline utility for good j. The exponential form for the introduction of the random term guarantees the positivity of the baseline marginal utility as long as ( z k ) 0 . To ensure this latter condition, ( z k ) is further parameterized as exp( zk ) , which then leads to the following form for the baseline random utility associated with good k: k ( zk , k ) exp( zk k ) . (15) Vasquez-Lavin and Hanemann indicate that, in the non-additively separable utility form, introducing stochasticity in the multiplicative exponential form as in the additively separable case above does not help in any way in simplifying the first-order conditions for optimization in the non-additively separable utility form. They instead write k in a linear form as follows: k ( zk , k ) zk k . (16) The problem with this, however, is that it allows negative values for k , which is theoretically inappropriate. The derivation of the probability expressions for any given consumption pattern from the first order conditions in Equation (13), after introducing the form for k from the above equation in k , is also relatively messy and difficult. Further, 20 Vasquez-Lavin and Hanemann indicate that there is no closed form for the resulting probability expressions. In this paper, we propose a method to introduce stochasticity that is a logical extension of Bhat’s additively separable MDCEV formulation. The approach also helps in developing an analytically tractable form for the probability of any consumption pattern, as we discuss in Section 3.3. In particular, we include stochasticity multiplicatively in the baseline marginal utility k of the non-additively separable formulation. Thus, we write: k k e , (17) k and replace k with k in Equation (13). Essentially, we are introducing stochasticity through the baseline (marginal) utility for each alternative just as in the additively separable case. However, there is a very important interpretational difference in the way we are introducing stochasticity in the case here and in the additively separable (AS) case. Specifically, in the AS case, the stochasticity in the baseline marginal utility (Equation (15)) can be viewed as a consequence of a random utility specification as follows: k e U ( x ) k exp( z k k ) k 1 1 k k k pk (18) According to this view, any stochasticity in the KT conditions originates from the analyst’s inability to observe all factors relevant to the consumer’s utility formation. There is no stochasticity originating from random individual errors in the process of maximizing utility (subject to the expenditure constraint). An alternative perspective, equally applicable (and empirically indistinguishable from the random utility perspective) in the AS case, is that the analyst observes all factors relevant to utility formation. This corresponds to the assumption 21 of deterministic utility. However, consumers can make random errors in the optimization process, which gets manifested in the form of stochasticity in the baseline marginal utility of the KT conditions. Both the above interpretations are valid for the AS case. In the nonadditively separable case, one cannot derive a random utility specification that is consistent with the stochastic specification of the baseline marginal utility in Equation (17) and so we cannot use the first interpretation above. Thus, we use the second interpretation for the source of stochasticity for the non-additively separable case.5 3.3. Stochastic Model Form To develop the stochastic model form, we start by replacing k with k k exp( k ) in the KT conditions of Equation (13). The resulting first order conditions are: k exp( k ) ek* 1 pk pk k k exp( k ) ek* 1 pk pk k 5 k 1 0, if ek* 0 , k = 1, 2, …, K (19) k 1 0, if ek* 0 , k = 1, 2, …, K, Note that a utility function of the form: U ( x) K k 1 k k k m x m x m 1 K k 1 1 k km 1 1 exp( k ) 2 m 1 k m m leads to a baseline marginal utility form as follows: m m x m 1 K 1 k km 1 1 exp( ) km m k 2 m 1 m m 2 m k m m x m 1 1 exp( ) m m xk 0 The expression above is a function of all the error terms, and does not collapse to k exp( k ). This creates U ( x ) x k problems in developing the probability expression for the consumption vector. As we show in the next section, the analytic tractability of our model hinges critically on writing the baseline marginal utility as k exp( k ), so that the KT conditions simplify when a logarithm operator is applied. 22 K The optimal demand satisfies the conditions above plus the budget constraint k 1 ek* E . The budget constraint implies that only K-1 of the ek* values need to be estimated, since the quantity consumed of any one good is automatically determined from the quantity consumed of all the other goods. To accommodate this constraint, designate activity purpose 1 as a purpose to which the individual allocates some non-zero amount of consumption (note that the individual should consume at least one good, given the strictly increasing utility specification assumed and given that E > 0). For the first good, the KT condition may then be written as: exp( 1 ) e1* 1 1 p1 1 p1 1 1 (20) Substituting for from above into Equation (18) for the other activity purposes (k = 2, …, K), and taking logarithms, we can rewrite the KT conditions as: Vk k V1 1 if ek* 0 (k = 2, 3, …, K) Vk k V1 1 if ek* 0 (k = 2, 3, …, K), where (21) ek* Vk ln( k) ln pk ( k 1) ln 1 (k = 1, 2, 3, …, K). k pk In our estimations, one needs to solve the KT conditions above. In doing so, note that, as indicated earlier, we should ensure k 0 for each good k. This is recognized in the logarithmic transformation of k appearing above. We ensure that k 0 for each good k in our estimation by using a constrained maximum likelihood procedure, in which we explicitly impose this condition. At the same time, we also require that k 0 . This latter 23 condition can be ensured by writing k exp( zk ) . Also, since only differences in the Vk from V1 matters in the KT conditions, a constant cannot be identified in the term for one of the K alternatives. Similarly, individual-specific variables are introduced in the Vk ’s for (K-1) alternatives, with the remaining alternative serving as the base. In the case that a profile is estimated, the k values need to be greater than zero, which can be maintained by reparameterizing k as exp( k ) . Additionally, the translation parameters can be allowed to vary across individuals by writing k k wk , where wk is a vector of individual characteristics for the kth alternative, and k is a corresponding vector of parameters. In the case when an profile is estimated, the k values need to be bounded from above at the value of 1. To enforce these conditions, k can be parameterized as [1 exp( k )] , with k being the parameter that is estimated. Further, to allow the satiation parameters (i.e., the k values) to vary across individuals, Bhat (2005) writes k k yk , where y k is a vector of individual characteristics impacting satiation for the kth alternative, and k is a corresponding vector of parameters. 3.4. Probability Expressions Let the joint probability density function of the k terms be f( 1 , 2 , …, K ). Then, the probability that the individual allocates expenditure to the first M of the K goods is: 24 P( e1* , e2* , e3* , ..., eM* , 0, 0, ..., 0) | J | V1 VM 1 1 V1 VM 2 1 1 M 1 V1 VK 1 1 V1 VK 1 M 2 K 1 K f ( 1 , V1 V2 1 , V1 V3 1 , ..., V1 VM 1 , M 1 , M 2 , ..., K 1 , K ) (22) d K d K 1 ...d M 2 d M 1d 1 , where J is the Jacobian whose elements are given by (see Bhat, 2005): J ih [V1 Vi 1 1 ] [V1 Vi 1 ] ; i, h = 1, 2, …, M – 1. eh* 1 eh* 1 (23) Following Bhat (2005, 2008), consider an extreme value distribution for k and assume that k is independent of k , k , and k (k = 1, 2, …, K). The k ’s are also assumed to be independently distributed across alternatives with a scale parameter of ( can be normalized to one if there is no variation in unit prices across goods). In this case, the probability expression collapses to the following form: P e1* , e2* , e3* , ..., eM* , 0, 0, ..., 0 abs J M 1 M 1 M eVi / i1 M K eVk / k 1 ( M 1)!, (24) where the elements of the Jacobian JM are given by: J ih [V1 Vi 1 1 ] [V1 Vi 1 ] , i 1,2,...M 1; h 1,2,...M 1 eh*1 eh*1 (25) To write these Jacobian elements, define zih 1 if i h , and zih 0 if i h. Also, define the following: k 1 e k k 1 pk k for k 1, 2, ..., K . (26) 25 Then, the elements of the Jacobian can be derived to be:6 J ih 1 i 1 1 1 h 1 1,h 1 zih 1 zih i 1,h 1 1 1,i 1 ph 1 1 i 1 p1 i 1 e1 1 p1 ei 1 i 1 pi 1 (27) Unfortunately, there is no concise form for the determinant of the Jacobian for M > 1 (unlike the case of the additively separable case, where Bhat derived a simple form for any value of M). In the case when M = 1 (i.e., only one alternative is chosen) for all individuals, there are no satiation effects ( k = 1 for all k), km 0 k , m (k m) , and the Jacobian term drops out (that is, the continuous component drops out, because all expenditure is allocated to good 1). Then, the model in Equation (24) collapses to the standard MNL model. The parameters in the non-additively separable or generalized MDCEV model (GMDCEV) may be estimated in a straightforward way using the maximum likelihood inference approach. Extensions to include covariance and heteroscedasticity among the error terms ( k ) do not pose any particular problems, and may be accomplished in the same way as for the MDCEV model (see Bhat, 2008). 4. THE MODEL WITH AN OUTSIDE GOOD Thus far, the discussion has assumed that there is no outside numeraire good (i.e., no essential Hicksian composite good). If an outside good is present, the econometrics simplify relative to the case without an outside good. To see this, label the outside good as the first good which now has a unit price of one (i.e., p1 1) . This good, being an outside 6 The derivation is rather straightforward, but requires some cumbersome differentiation. Interested readers may obtain the derivation from the authors. 26 good, has no interaction term effects with the inside goods; i.e., 1m 0m (k 1) . The utility functional form of Equation (9) now needs to be modified as follows: U ( x) 1 1 ( x 1 K 1) 1 1 k 2 k k k m x m x m 1 k 1 1 (28) 1 1 k km 2 m k m m k In the above formula, we need 1 0 , while k 0 for k > 1. Also, we need x1 1 0 . The magnitude of 1 may be interpreted as the required lower bound (or a “subsistence value”) for consumption of the outside good. As in the “no-outside good” case, the analyst will generally not be able to estimate both k and k for the outside and inside goods. The analyst will have to use either an -profile or a -profile. One can go through the same procedure as earlier by writing the KT conditions and introducing stochasticity. For identification, we impose the condition that 1 1 . The final expression for probability in this outside good case and the GMDCEV model is the same as in Equation (24) with the following modifications to the V k terms: ek* Vk ln( k) ln pk ( k 1) ln 1 ( k 2) ; V1 (1 1) ln( e1* 1 ) . k pk (29) The Jacobian elements in this case simplify relative to Equation (27), with 1m 0m (k 1) . The elements now are given as follows: J ih 1 1 1 i 1 zih 1 zih i 1,h 1 ph 1 i 1 e1 1 ei 1 i 1 pi 1 h 1 (30) 27 5. EMPIRICAL DEMONSTRATION 5.1. The Context Transportation expenses account for nearly 20 percent of total household expenses and 1215 percent of total household income. It is little surprise, therefore, that the study of transportation expenditures has been of much interest in recent years (Gicheva et al., 2007; Cooper, 2005; Hughes et al., 2006; Thakuriah and Liao 2005, 2006, Choo et al., 2007, Sanchez et al., 2006). Several of these studies examine the factors that influence total household transportation expenditures and/or examine transportation expenditures in relation to expenditures on other commodities and services (such as in relation to housing, telecommunications, groceries, and eating out). But there has been relatively little research on identifying the many disaggregate-level components of transportation expenditures -rather all transportation expenditures are usually lumped into a single category. In the current paper, we demonstrate the use of the GMDCEV model for an empirical case of household transportation expenditures in six disaggregate categories: (1) Vehicle purchase, (2) Gasoline and motor oil (termed as gasoline in the rest of the document), (3) Vehicle insurance, (4) Vehicle operation and maintenance (labeled as vehicle maintenance from hereon), (5) Air travel, and (6) Public transportation. In addition, we consider all other household expenditures in a single “outside good” category that lumps all non-transportation expenditures, so that total transportation expenditure is endogenously determined. Households expend some positive amount on the “outside good” category, while expenditures are zero for one or more transportation categories for some households. 28 Data for the analysis is drawn from the 2002 Consumer Expenditure (CEX) Survey, which is a national level survey conducted by the US Census Bureau for the Bureau of Labor Statistics (BLS, 2003). This survey has been carried out regularly since 1980 and is designed to collect information on incomes and expenditures/buying habits of consumers in the United States. In addition, information on individual and household socio-economic, demographic, employment, and vehicle characteristics is also collected. Details of the data and sample extraction process for the current analysis are available in Ferdous et al., (2010). A non-additively separable utility form is adopted to accommodate rich substitution patterns as well as allowing complementarity among the transportation expenditure categories. Since annual household income is considered exogenous in the current analysis, we use the proportion of annual household income spent in each of the six transportation categories and the “outside” non-transportation category as the dependent variables in the analysis. The final sample for analysis includes 4100 households with the information identified above. About one-quarter of the sample reports expenditures on vehicle purchase. About 94% of the sample incurs expenditures on gasoline, and about 90% of the sample indicates vehicle maintenance expenses. About 80 percent of the sample has vehicle-insurance related expenses, suggesting that a sizeable number of households operate motor vehicles with no insurance or have insurance costs paid for them (possibly by an employer or self-employed business). About one-third of the sample reports spending money on public transportation and air travel. All together, expenditures on transportationrelated items account for about 15 percent of household income, a figure that is quite consistent with reported national figures. Of these 4100 households, a random sample of 29 3600 households was used for model estimation and the remaining sample of 500 households was held for validation. 5.2 Model Specification The MDCEV and GMDCEV models were estimated using the GAUSS matrix programming language. The analysis first estimated the best MDCEV model based on intuitive and statistical significance considerations, and then explored alternative specifications for the interaction parameters in the GMDCEV model. The profile of Equation (10) is used in all specifications, because this profile consistently provided better results than the profile. Also, the 1 value for the outside good is set to zero for convenience and stability in convergence. The results of the final MDCEV and GMDCEV specifications are provided in Table 1. In this paper, the emphasis is on demonstrating the application of the GMDCEV model, and not expressly on contributing to a substantive understanding of expenditure patterns or to policy analysis related to expenditures. However, the empirical results are intuitive. Also, while there are differences in the estimated coefficients between the MDCEV and GMDCEV models, the general pattern and direction of variable effects are similar. The alternative specific constants in the baseline utility for all the transportation categories are negative, indicating the generally higher baseline utility of the “outside” non-transportation good category relative to each transportation category (this is a reflection of the higher expenditure on the outside good than on the transportation categories). As the number of workers increases, so does the proportion of income allocated to all vehicle-related 30 transportation expenses, presumably to support the transportation needs of multi-worker households. In the context of income, the middle income group (30-70K annual income) spends a lower proportion of its income on gasoline relative to the low income group. This result indicates that transportation expenditures constitute a major share of expenditures for the low income group. Higher income groups also tend to spend a lower proportion of their resources on gasoline, most likely due to a travel saturation effect combined with high income. As one would expect, the proportion of vehicle insurance expenses decreases as income rises, while the proportion on new vehicle purchases and air travel increases as income rises. Multicar households tend to allocate a greater proportion of their income to all transportation categories, except on public transportation (the effect of multicar households on public transportation is negative in the MDCEV model, and positive but statistically insignificant in the GMDCEV model). Finally, non-caucasians, those residing in urban areas, and those living in the Northeast and West regions of the United States spend a higher proportion on public transportation than Caucasians, those residing in nonurban areas, and those living in the South and Midwest regions of the US. The satiation parameters, as estimated by the k parameters, indicate statistically significant satiation. The interaction parameters indicate a significant complementary effect in vehicle purchase and gasoline expenditures, and in vehicle purchase and vehicle maintenance expenditures. Also, as expected, there are complementary effects in the expenditures on gasoline, vehicle insurance, and vehicle maintenance, as well as between air travel and public transportation expenditures. This last complementary effect perhaps reflects the use of public transportation to get to/from the airport and the use of public 31 transportation at the non-home end. On the other hand, there are particularly sensitive substitution effects in gasoline and air/public transportation expenditures, and vehicle insurance and air/public transportation expenditures. Such complementary and rich substitution effects are not possible within the additively-separable utility formulation of the MDCEV model framework, and require the non-additive utility formulation of the GMDCEV framework proposed here. 5.3. Model Evaluation In this section, we compare the model performance of the GMDCEV and the MDCEV models both in the estimation sample of 3600 households as well as a validation sample of 500 households. In terms of model fit in the estimation data, the log-likelihood value at convergence of the GMDCEV model is -36522, while that of the MDCEV model is -37045. A likelihood ratio test between these two models returns a value of 1046, which is larger than the chisquared statistic value with 10 degrees of freedom at any reasonable level of significance, indicating the substantially superior fit of the GMDCEV model compared to the MDCEV model. Of course, both the MDCEV and GMDCEV models at convergence provide a much better data fit than the naïve MDCEV model with only the alternative-specific constant terms and the translation parameters (with the effect of all explanatory variables assumed to be zero), which has a log-likelihood value of -37692. To further compare the performance of the MDCEV and GMDCEV models, we computed an out-of-sample log-likelihood function (OSLLF) using the validation sample of 500 observations for (a) the naïve MDCEV model with only constants and translation 32 parameters model, (b) the MDCEV model with independent variables, and (c) the GMDCEV model. The OSLLF is computed by plugging in the out-of-sample (i.e., validation) observations into the log-likelihood function, while retaining the estimated parameters from the estimation sample. As indicated by Norwood et al. (2001), the model with the highest value of OSLLF is the preferred one, since it is most likely to generate the set of out-of-sample observations. Table 2 reports the OSLLF values for the entire validation sample (of 500 households) as well as for different socio-demographic segments within the sample. As can be observed from the first row, the OSLLF for the MDCEV and GMDCEV models are higher than for the naïve MDCEV model, and the OSLLF for the GMDCEV model is higher than the MDCEV model. The OSLLF for the MDCEV model is, in general, higher than the OSLLF for the naïve MDCEV model for all sociodemographic segments, except for the “number of workers in household = 0” and “number of vehicles > 2” segments. Finally, the OSLLF for the GMDCEV model is consistently higher than those of both the MDCEV and naïve MDCEV models for all sociodemographic segments. In summary, the data fit of the GMDCEV model is superior to that of the MDCEV model in both estimation and validation samples. 6. CONCLUSIONS Classical discrete and discrete-continuous models deal with situations where only one alternative is chosen from a set of mutually exclusive alternatives. Such models assume that the alternatives are perfectly substitutable for each other. On the other hand, many consumer choice situations are characterized by the simultaneous demand for multiple 33 alternatives that are imperfect substitutes or even complements for one another. The traditional MDCEV model developed by Bhat adopts a additively-separable utility form that assumes that the marginal utility of a good is independent of the consumption amounts of other goods. It also is not able to allow complementarity among goods. This paper develops a closed-form model formulation that allows a non-additive utility structure and complementarity effects. As importantly, the utility functional form proposed here remains within the class of flexible forms, while also retaining global theoretical consistency properties (unlike the Translog and related flexible quadratic functional forms). The result is also clarity in the interpretation of the model parameters. The proposed GMDCEV model should have several applications. In the current paper, we demonstrate the application of the formulation to the empirical case of household transportation expenditures in six disaggregate categories: (1) Vehicle purchase, (2) Gasoline and motor oil, (3) Vehicle insurance, (4) Vehicle operation and maintenance, (5) Air travel, and (6) Public transportation. In addition, we consider other household expenditures in a single “outside good” category that lumps all non-transportation expenditures, so that total transportation expenditure is endogenously determined. Households expend some positive amount on the “outside good” category, while expenditures are zero for one or more transportation categories for some households. Data for the analysis is drawn from the 2002 Consumer Expenditure (CEX) Survey, which is a national level survey conducted by the US Census Bureau for the Bureau of Labor Statistics (BLS, 2003). The results indicate statistically significant complementary and substitution effects in the utilities of selected pairs of transportation categories, and indicates the 34 substantially superior data fit of the GMDCEV model relative to the MDCEV model. The GMDCEV model performed better in a validation sample as well. 35 REFERENCES Ahn J, Jeong G, Kim Y. 2008. A forecast of household ownership and use of alternative fuel vehicles: A multiple discrete-continuous choice approach. Energy Economics 30(5): 2091-2104. Arora N, Allenby GM, Ginter JL. 1998. A hierarchical Bayes model of primary and secondary demand. Marketing Science 17: 29-44. Bhat CR. 2005. A multiple discrete-continuous extreme value model: formulation and application to discretionary time-use decisions. Transportation Research Part B 39(8): 679-707. Bhat CR. 2008. The multiple discrete-continuous extreme value (MDCEV) model: role of utility function parameters, identification considerations, and model extensions. Transportation Research Part B 42(3): 274-303. Bhat CR, Sen S, Eluru N. 2009. The impact of demographics, built environment attributes, vehicle characteristics, and gasoline prices on household vehicle holdings and use. Transportation Research Part B 43(1): 1-18. Bunch DS. 2009. Theory-based functional forms for analysis of disaggregated scanner panel data. Technical working paper, Graduate School of Management, University of California-Davis, Davis CA. Bureau of Labor Statistics (BLS). 2003. 2002 Consumer expenditure interview survey public use microdata documentation. U.S. Department of Labor Bureau of Labor Statistics, Washington, D.C., http://www.bls.gov/cex/csxmicrodoc.htm#2002. Chiang J. 1991. A simultaneous approach to whether to buy, what to buy, and how much to buy. Marketing Science 4: 297-314. Chintagunta PK. 1993. Investigating purchase incidence, brand choice and purchase quantity decisions of households. Marketing Science 12: 194-208. Christensen L, Jorgenson D, Lawrence L. 1975. Transcendental logarithmic utility functions. The American Economic Review 65: 367-83. Choo S, Lee T, Mokhtarian PL. 2007. Do transportation and communications tend to be substitutes, complements, or neither? U.S. consumer expenditures perspective, 19842002. Transportation Research Record 2010: 121-132. 36 Cooper M. 2005. The impact of rising prices on household gasoline expenditures. Consumer Federation of America, www.consumerfed.org/. Deaton A, Muellbauer J. 1980. Economics and Consumer Behavior. Cambridge University Press: Cambridge. Ferdous N, Pinjari AR, Bhat CR, Pendyala RM. 2010. A comprehensive analysis of household transportation expenditures relative to other goods and services: an application to United States consumer expenditure data. Transportation, forthcoming. Gicheva D, Hastings J, Villas-Boas S. 2007. Revisiting the income effect: gasoline prices and grocery purchases. Working Paper No. 13614, National Bureau of Economic Research, Cambridge, MA. Hanemann WM. 1978. A methodological and empirical study of the recreation benefits from water quality improvement. Ph.D. dissertation, Department of Economics, Harvard University. Hanemann WM. 1984. The discrete/continuous model of consumer demand. Econometrica 52: 541-561. Herriges JA, Kling CL, Phaneuf DJ. 2004. What’s the use? Welfare estimates from revealed preference models when weak complementarity does not hold. Journal of Environmental Economics and Management 47: 55-70. Hughes JE, Knittel CR, Sperling D. 2006. Evidence of a shift in the short-run price elasticity of gasoline demand. The Energy Journal, 29(1), 93-114. Kim J, Allenby GM, Rossi PE. 2002. Modeling consumer demand for variety. Marketing Science 21: 229-250. Mäler K-G. 1974. Environmental Economics: A Theoretical Inquiry. The Johns Hopkins University Press for Resources for the Future, Baltimore, MD. Mohn C, Hanemann M. 2005. Caught in a corner: using the Kuhn-Tucker conditions to value Montana sportfishing. In Explorations in Environmental and Natural Resource Economics: Essays in Honor of Gardner M. Brown, Jr., Halvorsen R, Layton DF (eds). Ch 10, pp. 188-207, Edward Elgar Publishing, Inc: Northampton, MA. 37 Norwood B, Ferrier P, Lusk J. 2001. Model selection criteria using likelihood functions and out-of-sample performance. Paper presented at the NCR-134 Conference on Applied Commodity Price Analysis, Forecasting, and Market Risk Management, St. Louis, Missouri, April 23-24. Phaneuf DJ, Herriges JA. 2000. Choice set definition issues in a Kuhn-Tucker model of recreation demand. Marine Resource Economics 14: 343-355. Phaneuf DJ, Kling CL, Herriges JA. 2000. Estimation and welfare calculations in a generalized corner solution model with an application to recreation demand. The Review of Economics and Statistics 82(1): 83-92. Pollak R, Wales T. 1992. Demand System Specification and Estimation. Oxford University Press: New York. Roy R. 1947. La distribution du revenu entre les divers biens. Econometrica 15: 205-225. Sanchez TW, Makarewicz C, Hasa PM, Dawkins CJ. 2006. Transportation costs, inequities, and trade-offs. Presented at the 85th Annual Meeting of the Transportation Research Board, Washington, D.C., January. Sauer J, Frohberg K, Hockmann H. 2006. Stochastic efficiency measurement: The curse of theoretical consistency. Journal of Applied Economics 9: 139-165. Thakuriah P, Liao Y. 2005. An analysis of variations in vehicle-ownership expenditures. Transportation Research Record 1926: 1-9. Thakuriah P, Liao Y. 2006. Transportation expenditures and ability to pay: evidence from consumer expenditure survey. Transportation Research Record 1985: 257-265. Vasquez Lavin F, Hanemann M. 2008. Functional forms in discrete/continuous choice models with general corner solution. Department of Agricultural & Resource Economics, University of California Berkeley. CUDARE Working Paper 1078. von Haefen RH. 2003. Incorporating observed choice into the construction of welfare measures from random utility models. Journal of Environmental Economics & Management 45(2): 145-165. von Haefen RH. 2004. Empirical strategies for incorporating weak complementarity into continuous demand system models. Working paper, Department of Agricultural and Resource Economics, University of Arizona. 38 von Haefen RH, Phaneuf DJ. 2005. Kuhn-Tucker demand system approaches to nonmarket valuation. In Applications of Simulation Methods in Environmental and Resource Economics, Scarpa R, Alberini AA (eds). Springer: The Netherlands. von Haefen RH, Phaneuf DJ, Parsons GR. 2004. Estimation and welfare analysis with large demand systems. Journal of Business and Economic Statistics 22(2): 194-205. Wales TJ, Woodland AD. 1983. Estimation of consumer demand systems with binding non-negativity constraints. Journal of Econometrics 21(3): 263-85. 39 LIST OF FIGURES Figure 1. Effect of k , due to Negative kk , on Good k’s Subutility Function Profile Figure 2. Effect of k , due to Positive kk , on Good k’s Subutility Function Profile Figure 3. Effect of k , due to Negative kk , on Good k’s Subutility Function Profile Figure 4. Effect of k , due to Positive kk , on Good k’s Subutility Function Profile Figure 5. Alternative Subutility Profiles (for Good k) with Different kk and k Values Figure 6. Alternative Subutility Profiles (for Good k) with Different kk and k Values LIST OF TABLES Table 1. Model Estimation Results Table 2. Predictive Likelihood-based Measures of Fit in the Validation Sample 40 Figure 1. Effect of k , due to Negative kk , on Good k’s Subutility Function Profile Figure 2. Effect of k , due to Positive kk , on Good k’s Subutility Function Profile 41 Figure 3. Effect of k , due to Negative kk , on Good k’s Subutility Function Profile Figure 4. Effect of k , due to Positive kk , on Good k’s Subutility Function Profile 42 Figure 5. Alternative Subutility Profiles (for Good k) with Different kk and k Values Figure 6. Alternative Subutility Profiles (for Good k) with Different kk and k Values 43 Table 1. Model Estimation Results MDCEV t-stat Parameter t-stat -7.127 -67.76 -8.143 -18.27 Gasoline/oil -2.523 -35.02 -2.919 -33.56 Vehicle insurance Vehicle maintenance -3.975 -3.446 -63.50 -52.87 -4.475 -4.230 -28.22 -30.29 Air travel -6.144 -65.24 -5.196 -41.96 Public transportation -5.820 -39.30 -4.699 -48.43 0.182 4.39 0.189 3.53 0.209 0.081 0.192 5.70 2.82 6.79 0.254 0.104 0.281 5.74 2.54 6.14 Annual HH income 30-70K Vehicle purchase Gasoline Air travel 0.809 -0.284 0.756 7.88 -3.43 7.95 1.404 -0.300 0.281 4.10 -3.03 5.01 Annual HH income >70K Vehicle purchase Gasoline Vehicle insurance Air travel 0.807 -0.792 -0.337 1.188 6.18 -6.06 -3.81 9.14 1.461 -0.881 -0.332 0.536 4.03 -5.22 -2.81 5.44 0.304 10.58 0.379 11.38 Gasoline 0.305 9.21 0.387 14.11 Vehicle insurance Vehicle maintenance 0.275 0.269 10.89 11.00 0.348 0.364 12.03 13.65 Air travel Public transportation 0.073 -0.122 2.04 -3.24 0.084 0.010 4.79 1.19 Non-Caucasian HH – Public transportation 0.417 5.71 0.084 2.02 Urban location – Public transportation 0.491 4.02 0.085 2.84 North East Region – Public transportation 0.722 9.64 0.182 3.80 Western Region – Public transportation 0.590 8.50 0.131 3.48 Baseline Utility Parameters Baseline Constants Vehicle purchase Number of workers in household Vehicle purchase Gasoline Vehicle Insurance Vehicle Maintenance Number of vehicles in household Vehicle purchase Parameter GMDCEV 44 Table 1 (Continued.) Model Estimation Results MDCEV Translation ( k ) Parameters Vehicle purchase Gasoline GMDCEV Parameter t-stat Parameter 20.889 0.196 11.10 10.58 21.607 0.166 10.67 8.81 Vehicle insurance Vehicle maintenance 0.613 0.284 17.48 16.98 0.579 0.269 15.78 16.12 Air travel Public transportation 0.677 0.237 13.81 17.70 0.548 0.187 13.44 16.81 Interaction Parameters ( km parameters) Vehicle purchase and gasoline Vehicle purchase and vehicle insurance Vehicle purchase and vehicle maintenance Vehicle purchase and air travel Vehicle purchase and public transportation Gasoline and vehicle insurance t-stat - - 1.355x10-3 0.323x10-3 2.053x10-2 3.22 2.11 4.09 Gasoline and vehicle maintenance Gasoline and air travel Gasoline and public transportation - - 5.167x10-2 -5.216x10-3 -8.205x10-3 6.33 -3.95 -4.91 Vehicle insurance and vehicle maintenance Vehicle insurance and air travel Vehicle insurance and public transportation Vehicle maintenance and air travel Vehicle maintenance and public transportation Air travel and public transportation - - 3.248x10-3 -1.409x10-3 -2.488x10-3 6.607x10-3 2.16 -4.14 -5.27 10.78 Log-likelihood with only constants and translation parameters -37692 -37692 Log-likelihood at convergence -37045 -36522 45 Table 2. Predictive Likelihood-based Measures of Fit in the Validation Sample Sample details Full validation sample Number of workers in HH 0 1 2 >2 Household income ($) < 30K/annum 30K-70K/annum >70K/annum Number of vehicles 0 1 2 >2 Race Non-Caucasian Caucasian Residential location Urban Rural Number of observations OSLLF for MDCEV OSLLF for MDCEV OSLLF for GMDCEV 500 -5630.58 -5575.26 -5475.03 14 109 240 137 -147.24 -1160.73 -2696.74 -1625.86 -147.99 -1139.70 -2667.63 -1619.94 -145.57 -1119.53 -2608.45 -1601.48 10 168 322 -103.25 -1865.47 -3661.86 -100.62 -1862.07 -3612.57 -100.40 -1835.87 -3538.75 13 94 179 214 -149.76 -1045.80 -1881.21 -2553.81 -141.42 -1016.61 -1852.94 -2564.29 -140.18 -1004.42 -1819.24 -2511.19 453 47 -5097.93 -532.64 -5047.85 -527.42 -4953.62 -521.41 470 30 -5272.37 -358.21 -5217.54 -357.72 -5125.17 -349.86 46