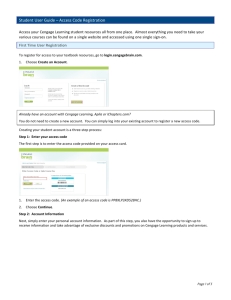
Business Statistics: Australia/New Zealand, 5th Ed.

Licensed to: iChapters User
Licensed to: iChapters User
Business Statistics - Australia and New Zealand
5th Edition
Eliyathamby A. Selvanathan
Saroja Selvanathan
Gerald Keller
Publishing Manager: Alison Green
Senior Publishing Editor: Michelle Aarons
Senior Project Editor: Ronald Chung
Developmental Editor: Melina Deliyannis
Publishing Assistant : Meagan Carlsson
Permissions Research Manager: Corrina Tauschke
Cover Design: Kar Heng Goh
Art Direction & Text Design: Olga Lavecchia
Editor: Marta Veroni
Proofreader: David Fryer
Indexer: Russell Brooks
Typeset by KnowledgeWorks Global Limited (KGL)
Any URLs contained in this publication were checked for currency during the production process. Note, however, that the publisher cannot vouch for the ongoing currency of URLs.
Fourth edition of Australian Business Statistics published by
Cengage Learning Australia in 2006.
© 2011 Cengage Learning Australia Pty Limited
Copyright Notice
This Work is copyright. No part of this Work may be reproduced, stored in a retrieval system, or transmitted in any form or by any means without prior written permission of the Publisher. Except as permitted under the
Copyright�Act�1968, for example any fair dealing for the purposes of private study, research, criticism or review, subject to certain limitations. These limitations include: Restricting the copying to a maximum of 10% of this
Work; providing an appropriate notice and warning with the copies of the
Work disseminated; taking all reasonable steps to limit access to these copies to people authorised to receive these copies; ensuring you hold the appropriate Licences issued by the Copyright�Agency�Limited (“CAL”), supply a remuneration notice to CAL and pay any required fees. For details of CAL licences and remuneration notices please contact CAL at
Level�15,�233�Castlereagh�Street, Sydney�NSW�2000, Tel:�(02)�9394�7600,
Fax:�(02)�9394�7601
Email:�info@copyright.com.au
Website:�www.copyright.com.au
For product information and technology assistance, in Australia call 1300 790 853 ; in New Zealand call 0800 449 725
For permission to use material from this text or product, please email aust.permissions@cengage.com
National Library of Australia Cataloguing-in-Publication Data
Author: Selvanathan, E. Antony, 1954-
Title: Business statistics : Australia New Zealand / Eliyathamby A.
Selvanathan; Saroja Selvanathan; Gerald Keller.
Edition: 5th ed
ISBN: 9780170184793 (pbk.)
Notes: Includes index.
Subjects: Commercial statistics. Management--Statistical methods.
Economics--Statistical methods.
Other Authors/Contributors: Selvanathan, Saroja. Keller, Gerald.
Dewey Number: 519.5
Cengage Learning Australia
Level 7, 80 Dorcas Street
South Melbourne, Victoria Australia 3205
Cengage Learning New Zealand
Unit 4B Rosedale Office Park
331 Rosedale Road, Albany, North Shore 0632, NZ
For learning solutions, visit cengage.com.au
1 2 3 4 5 6 7 15 14 13 12 11
210 x 276
Copyright 2010 Cengage Learning. All Rights Reserved. May not be copied, scanned, or duplicated, in whole or in part. Due to electronic rights, some third party content may be suppressed from the eBook and/or eChapter(s).
Editorial review has deemed that any suppressed content does not materially affect the overall learning experience. Cengage Learning reserves the right to remove additional content at any time if subsequent rights restrictions require it.
Licensed to: iChapters User
1
What is statistics?
Learning objectives
This chapter provides an introduction to the two general bodies of methods that together constitute the subject called statistics: descriptive statistics and inferential statistics.
At the completion of this chapter, you should be able to:
LO1 describe the two major branches of statistics –– descriptive statistics and inferential statistics
LO2 understand the key statistical concepts –– population, sample, parameter, statistic and census
LO3 provide examples of practical applications in which statistics have a major role to play
LO4 understand how statistics are used by business managers
LO5 understand the basics of the computer spreadsheet package Microsoft Excel and its capabilities in aiding with statistical data analysis for large amounts of data.
Introduction to statistics
1.1
Key statistical concepts
1.2
Practical applications
1.3
How managers use statistics
1.4
Statistics and the computer
1.5
Worldwide web and learning centre
Introduction to statistics
Statistics is a body of principles and methods concerned with extracting useful information from a set of data to help people make decisions. Today we have access to more data than ever, through the ever-increasing use of computers, and we risk confusion unless we can effectively screen the data for useful information. The role of this book is to describe how, when and why managers and statisticians conduct statistical procedures. Such description is important as you come across different kinds of information and data to which you need to apply different statistical procedures.
Statistics can be subdivided into two basic areas: descriptive statistics and inferential statistics .
Descriptive statistics
Descriptive statistics deals with methods of organising, summarising and presenting data in a convenient and informative form. One form of descriptive statistics uses graphical techniques , which allow statistics practitioners to present data in ways that make it easy for the reader to extract useful information. In Chapter 2 we will present a variety of graphical methods. Another form of descriptive statistics uses numerical
Copyright 2010 Cengage Learning. All Rights Reserved. May not be copied, scanned, or duplicated, in whole or in part. Due to electronic rights, some third party content may be suppressed from the eBook and/or eChapter(s).
Editorial review has deemed that any suppressed content does not materially affect the overall learning experience. Cengage Learning reserves the right to remove additional content at any time if subsequent rights restrictions require it.
Licensed to: iChapters User
2 Business Statistics – Australian/New Zealand Edition example 1.1
LO1 example 1.2
LO1, LO3 techniques to summarise data. One such method that you have already used frequently calculates the average or mean. Chapter 4 introduces several numerical statistical measures that describe different features of the data.
The actual technique we use depends on what specific information we would like to extract. Consider the use of descriptive statistics in the following examples.
Business statistics marks
A student enrolled in a business program is attending his first lecture of the compulsory business statistics course. The student is somewhat apprehensive because he believes the myth that the course is difficult. To alleviate his anxiety, the student asks the lecturer about last year’s exam marks of the business statistics course. Because, like all statistics lecturers, this one is friendly and helpful, he obliges and provides a list of the final marks.
The marks are composed of all the within semester assessment items plus the end-ofsemester final exam. What information can the student obtain from the list?
This is a typical statistics problem. The student has the data (marks) and needs to apply statistical techniques to get the information he requires. This is a function of descriptive statistics .
In this example, we can see at least three important pieces of information. The first is the ‘typical’ mark. We call this a measure of central location.
The average is one such measure. In Chapter 4 we will introduce another useful measure of central location, the median.
Suppose the student was told that the average mark last year was 67. Is this enough information to reduce his anxiety? The student would likely respond ‘no’ because he would like to know whether most of the marks were close to 67 or were scattered far below and above the average. He needs a measure of variability . The simplest such measure is the range, which is calculated by subtracting the smallest number from the largest. Suppose the largest mark is 96 and the smallest is 24, then the range is (96 – 24 ¼ ) 72. Unfortunately, this provides little information as the range doesn’t say where most of the marks are located.
Whether most data are located near 24 or near 96 or somewhere in the middle, the range is still 72. We need other measures of variability such as the variance and standard deviation, to reflect the true picture of the spread of the data, which will be introduced in Chapter 4. Moreover, the student must determine more about the marks. In particular he needs to know how the marks are distributed between 24 and 96. The best way to do this is to use a graphical technique, the histogram, to be introduced in Chapter 2.
Comparing weekly sales between two outlets
A fast-food franchiser wishes to compare the weekly sales level over the past year at two particular outlets. Descriptive statistical methods could be used to summarise the actual sales levels (perhaps broken down by food item) in terms of a few numerical measures, such as the average weekly sales level and the degree of variation from this average that weekly sales may undergo. Tables and charts could be used to enhance the presentation of the data so that a manager could quickly focus on the essential differences in sales performance at the two outlets.
There is much more to statistics, however, than these descriptive methods. Decisionmakers are frequently forced to make decisions based on a set of data that is only a small subgroup (sample) of the total set of relevant data (population).
Copyright 2010 Cengage Learning. All Rights Reserved. May not be copied, scanned, or duplicated, in whole or in part. Due to electronic rights, some third party content may be suppressed from the eBook and/or eChapter(s).
Editorial review has deemed that any suppressed content does not materially affect the overall learning experience. Cengage Learning reserves the right to remove additional content at any time if subsequent rights restrictions require it.
Licensed to: iChapters User example 1.3
LO1–LO4
Chapter 1 What is statistics?
3
Inferential statistics
Inferential statistics is a body of methods for drawing conclusions (i.e. making inferences) about characteristics of a population, based on information available in a sample taken from the population. The following example illustrates the basic concepts involved in inferential statistics.
Profitability of a new life insurance policy
An Australia-wide automobile club (consisting of about 1 million members) is contemplating extending its services to its members by introducing a new life insurance policy. After some careful financial analysis, the club has determined that the proposed insurance policy would break even if at least 10% of all current members subscribing to the club also purchase the policy. The question here is how can inferential statistics be used by the automobile club to make a decision about introducing their new life insurance policy.
To obtain additional information before reaching a decision on whether or not to proceed with the new insurance policy, the automobile club has decided to conduct a survey of 500 randomly selected current members. The collection of all its current
1 million or so members is called the population . The 500 members selected from the entire population for the analysis are referred to as a sample . Each member in the sample is asked if they would purchase the policy if it were offered at some specified price.
Suppose that 60 of the members in this sample reply positively. While a positive response by 60 out of 500 members (12%) is encouraging, it does not assure the automobile club that the proposed insurance policy will be profitable. The challenging question here is how to use the response from these 500 sampled members to conclude that at least 10% of all 1 million or so members would also respond positively. The data are the proportion of positive response among the 500 members in the sample. However, we are not so much interested in the response of the 500 members as we are in knowing what the response would be from all of its current members. To accomplish this goal we need another branch of statistics – inferential statistics .
If the automobile club concludes, based on the sample information, that at least 10% of all its members in the population would purchase the proposed insurance policy, the club is relying on inferential statistics. The club is drawing a conclusion, or making a statistical inference, about the entire population of its 1 million or so members on the basis of information provided by only a sample of 500 members taken from the population. The available data tell us that 12% of this particular sample of members would purchase; the inference that at least 10% of all its members would purchase the new insurance policy may or may not be correct. It may be that, by chance, the club selected a particularly agreeable sample and that, in fact, no more than 5% of the entire population of members would purchase.
Whenever an inference is made about an entire population on the basis of evidence provided by a sample taken from the population, there is a chance of drawing an incorrect conclusion. Fortunately, other statistical methods allow us to determine the reliability of the statistical inference. They enable us to establish the degree of confidence we can place in the inference, assuming the sample has been properly chosen. These methods would enable the automobile club in Example 1.3 to determine, for example, the likelihood that less than 10% of the population of its members would purchase, given that 12% of the members sampled said they would purchase. If this likelihood is deemed small enough, the automobile club will probably proceed with its new venture.
Copyright 2010 Cengage Learning. All Rights Reserved. May not be copied, scanned, or duplicated, in whole or in part. Due to electronic rights, some third party content may be suppressed from the eBook and/or eChapter(s).
Editorial review has deemed that any suppressed content does not materially affect the overall learning experience. Cengage Learning reserves the right to remove additional content at any time if subsequent rights restrictions require it.
Licensed to: iChapters User
4 Business Statistics – Australian/New Zealand Edition
1.1 Key statistical concepts
The foregoing example introduced three key considerations present in the solution to any statistical problem: the population, the sample and the statistical inference. We now discuss each of these concepts in more detail.
Population
A population is the group of all items of interest to a statistics practitioner. It is frequently very large and may, in fact, be infinitely large. In the language of statistics, the word population does not necessarily refer to a group of people. It may, for example, refer to the population of diameters of ball bearings produced at a large plant. In Example 1.3, the population of interest consists of all 1 million or so members.
A descriptive measure of a population is called a parameter . The parameter of interest in Example 1.3 was the proportion of all members who would purchase the new policy.
Sample
A sample is a subset of data drawn from the population. In Example 1.3, the sample of interest consists of the 500 selected members.
A descriptive measure of a sample is called a statistic . We use sample statistics to make inferences about population parameters. In Example 1.3, the proportion of the 500 members who would purchase the life insurance policy would be a sample statistic that could be used to estimate the corresponding population parameter of interest, the population proportion. Unlike a parameter, which is a constant, a statistic is a variable whose value varies from sample to sample. In Example 1.3, 12% is a value of the sample statistic based on the selected sample.
Statistical inference
Statistical inference is the process of making an estimate, forecast or decision about a population parameter, based on the sample data. Because populations are usually very large, it is impractical and expensive to investigate or survey every member of a population. (Such a survey is called a census .) It is far cheaper and easier to take a sample from the population of interest and to draw conclusions about the population parameters based on information provided by the sample.
For instance, political pollsters predict, on the basis of a sample of about 1500 voters, how the entire 13 million eligible voters from the Australian population will cast their ballots; and quality control supervisors estimate the proportion of defective units being produced in a massive production process from a sample of only several hundred units.
Because a statistical inference is based on a relatively small subgroup of a large population, statistical methods can never decide or estimate with certainty. Since decisions involving large amounts of money often hinge on statistical inferences, the reliability of the inferences is very important. As a result, each statistical technique includes a measure of the reliability of the inference. For example, if a political pollster predicts that a candidate will receive 40% of the vote, the measure of reliability might be that the true proportion (determined on election day) will be within 3% of the estimate on 95% of the occasions when such a prediction is made. For this reason, we build into the statistical inference a measure of reliability. There are two such measures, the confidence level and the significance level . The confidence level is the proportion of times that an estimating procedure would be correct, if the sampling procedure were repeated a very large number of times. For example, a 95% confidence level would mean that, in a very
Copyright 2010 Cengage Learning. All Rights Reserved. May not be copied, scanned, or duplicated, in whole or in part. Due to electronic rights, some third party content may be suppressed from the eBook and/or eChapter(s).
Editorial review has deemed that any suppressed content does not materially affect the overall learning experience. Cengage Learning reserves the right to remove additional content at any time if subsequent rights restrictions require it.
Licensed to: iChapters User
Chapter 1 What is statistics?
5 large number of repeated samples, estimates based on this form of statistical inference will be correct 95% of the time. When the purpose of the statistical inference is to draw a conclusion about a population, the significance level measures how frequently the conclusion will be wrong in the long run. For example, a 5% significance level means that, in repeated samples, this type of conclusion will be wrong 5% of the time. We will introduce these terms in Chapters 11 and 13.
1.2 Practical applications
Throughout the text, you will find examples, exercises and cases that describe actual situations from the business world in which statistical procedures have been used to help make decisions. For each example, exercise or case, you will be asked to choose and apply the appropriate statistical technique to the given data and to reach a conclusion.
We cover such applications in accounting, economics, finance, management and marketing. Below is a summary of some of the case studies we have analysed in this textbook with partial data, to illustrate additional applications of inferential statistics. But you will have to wait until you work through these cases in the relevant chapters (where some data is also presented) to find out the conclusions and results.
Case 2.11
Confidence returning to the Australian residential property market
After 18 months of silence, property investors appear to have regained their confidence and have started investing again in the residential property market. Low interest rates and attractive gross rental yield at more than 5 per cent are the main drivers behind the luring of investors with increased confidence back into the rental market. Many investors are also of the belief that the market has hit the bottom. According to recent ABS statistics, the number of investment property home loans taken increased by 2.4 per cent in May 2009. The following data, published in
Wealth, The Australian (22 July 2009), originated from the Australian Property Monitors. Use suitable graphical techniques to prepare a report on the current situation of the Australian residential property market.
City
Sydney
Melboune
Brisbane
Adelaide
Perth
Hobart
Darwin
Canberra
Newcastle
Gold Coast
Sunshine Coast
Gross rental yield (%)
4.66
4.17
5.23
5.14
5.18
4.55
4.01
4.64
4.36
4.08
5.23
Houses
Annual percentage change
1.8
4.3
8.8
4.7
3.0
3.4
2.1
0.2
4.0
2.2
8.1
Gross rental yield (%)
5.22
4.78
5.91
5.81
4.96
4.60
4.34
4.83
4.75
4.75
4.79
Units
Annual percentage change
1.6
4.5
11.7
3.5
0.6
1.8
3.1
0.9
2.6
8.2
6.4
Copyright 2010 Cengage Learning. All Rights Reserved. May not be copied, scanned, or duplicated, in whole or in part. Due to electronic rights, some third party content may be suppressed from the eBook and/or eChapter(s).
Editorial review has deemed that any suppressed content does not materially affect the overall learning experience. Cengage Learning reserves the right to remove additional content at any time if subsequent rights restrictions require it.
Licensed to: iChapters User
6 Business Statistics – Australian/New Zealand Edition
Case 4.7
Aussies and Kiwis are leading in education
According to recently (18 December 2008) published statistics on the human development index
(HDI) by the UN, Australians are leading the world. The HDI is calculated using three indices, namely, education index, GDP index and life expectancy index. The education index data for the top 20, the middle 20 and the bottom 20 of the 176 countries listed in the UN report are stored in file C04-01.
Use suitable numerical summary (central and variability) measures to analyse the data.
Top 20
Australia
Denmark
Finland
New Zealand
. . .
. . .
United States
Education index
0.993
0.993
0.993
0.993
. . .
. . .
0.968
Bottom 20
Guinea-Bissau
Sudan
Mauritania
Angola
. . .
. . .
Burkina Faso
Source: Human Development Report 2009 , United Nations
Development Program (UNDP), New York, 2009.
Education index
0.541
0.539
0.537
0.535
. . .
. . .
0.274
Case 14.4
Month
May-98
Jun-98
Jul-98
Aug-98
.
Sep-98
.
Jan-09
Feb-09
Mar-09
Apr-09
May-09
The price of petrol: City versus country town
It is claimed widely in the Australian news media that country drivers pay higher prices for petrol than city drivers. In order to investigate this claim, data were collected on monthly average petrol prices for a metropolitan area, Melbourne, and a country area, Bendigo, in Victoria and are stored in file
C14-04. Applying the appropriate statistical techniques to the data, investigate whether there is any difference in the average price of petrol in the metropolitan area and the country area.
Monthly average price of unleaded petrol (cents per litre)
Melbourne
68.9
68.7
Bendigo
74.9
76.9
.
109.4
123.9
118.1
67.9
66.7
65.6
.
119.0
119.5
.
110.2
116.0
119.1
74.9
74.1
73.0
.
118.4
119.9
Source: Australian Automobile Association, www.aaa.asn.au/issues/petrol.htm, accessed December 2009.
Copyright 2010 Cengage Learning. All Rights Reserved. May not be copied, scanned, or duplicated, in whole or in part. Due to electronic rights, some third party content may be suppressed from the eBook and/or eChapter(s).
Editorial review has deemed that any suppressed content does not materially affect the overall learning experience. Cengage Learning reserves the right to remove additional content at any time if subsequent rights restrictions require it.
Licensed to: iChapters User
Chapter 1 What is statistics?
7
Case 20.1
Gold lotto
Gold lotto is a national lottery that operates as follows. Players select eight different numbers (six primary and two supplementary numbers) between 1 and 45. Once a week, the corporation that runs the lottery selects eight numbers (six primary and two supplementary numbers) at random between 1 and 45. Winners are determined by how many numbers on their tickets agree with the numbers drawn. In selecting their numbers, players often look at past patterns as a way to help predict future drawings. A regular feature that appears in the newspaper identifies the number of times each number has occurred in the past. The data recorded in the following table appeared in the 19 July 2009 edition of the Queensland Sunday Mail after the completion of draw 2921. What would you recommend to anyone who believes that past patterns of the lottery numbers are useful in predicting future drawings?
14
.
2
.
15
Lotto number
1
Drawing frequency of lotto numbers since draw 413
Number of times drawn
233
Lotto number
16
Number of times drawn
207
Lotto number
31
224
.
.
211
228
17
.
.
29
30
210
.
.
212
193
32
.
.
44
45
Number of times drawn
218
219
.
.
211
220
Case 21.1
How good are the New Zealander’s average hourly earnings?
Wages in the labour market are very much influenced by the demand and supply of labour. In any profession or industry, when there is an oversupply of labour, the workers will be at a disadvantage and will not be able to demand high wages and vice-versa. During the mining boom in Perth, unusually high wages were paid, due to the shortage of workers to work in the mining fields. This has impacted heavily on the other sectors of the economy (for example, the house prices in Perth were inflated to astonishingly high levels). In New Zealand also in the last few decades, average hourly earnings have fluctuated a little, depending on the state of the economy, especially on the level of labour supply. When the number of unemployed persons increases, it is expected that the average hourly earnings would fall. The data in file C21-01 presents the quarterly data for the average hourly earnings and the total number of unemployed persons in New Zealand during the period March
1994 to March 2009. Is there any evidence in New Zealand to support the proposition that the higher (lower) the number of unemployed the lower (higher) the average hourly earnings?
Period
Mar. 1994
Jun. 1994
Sep. 1994
Dec. 1994
. . .
Mar. 2008
Number unemployed
170 300
147 000
135 800
134 800
. . .
96 000
Average hourly earnings
14.98
15.10
15.10
15.16
. . .
23.66
Copyright 2010 Cengage Learning. All Rights Reserved. May not be copied, scanned, or duplicated, in whole or in part. Due to electronic rights, some third party content may be suppressed from the eBook and/or eChapter(s).
Editorial review has deemed that any suppressed content does not materially affect the overall learning experience. Cengage Learning reserves the right to remove additional content at any time if subsequent rights restrictions require it.
Licensed to: iChapters User
8 Business Statistics – Australian/New Zealand Edition
Period
Jun. 2008
Sep. 2008
Dec. 2008
Mar. 2009
Number unemployed
87 500
93 900
102 800
128 800
Average hourly earnings
24.00
24.37
24.60
24.91
Source: Income Tables, Statistics New Zealand, July 2009.
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ __ _ _ _
The objective of the problem described in Case 2.11 is to use the descriptive graphical and numerical techniques to analyse the Australian residential property market data across a number of major Australian cities; Case 4.7 is to compare the central location and variability of the education index of the top and bottom 20 countries in the world; Case 14.4 is to compare two populations, the variable of interest being the average price of petrol in a metropolitan area versus a country town. Case 20.1 is a day-to-day real-life application. The objective of the problem is to see how statistical inference can be used to determine whether some numbers in a lotto draw occur more often than others. Case 21.1 illustrates another statistical objective. In this case, we need to analyse the relationship between two variables: average hourly earnings and the total number of unemployed persons in New Zealand. By applying the appropriate statistical technique, we will be able to determine whether the two variables are related, and, if so, whether reducing the number of unemployed leads to higher average salary earnings. As you will discover, the technique also permits statistics practitioners to include other variables to determine whether they affect average salary earnings.
1.3 How managers use statistics
As we have already pointed out, statistics is about acquiring and using information.
However, the statistical result is not the end product. Managers use statistical techniques to help them make decisions. In general, statistical applications are driven by the managerial problem. The problem creates the need to acquire information. This in turn drives the data-gathering process. When the manager acquires data, he or she must convert the data into information by means of one or more statistical techniques. The information then becomes part of the decision process.
Many business students will take or have already taken a subject in marketing. In the introductory marketing subject, students are taught about market segmentation.
Markets are segmented to develop products and services for specific groups of consumers. For example, the Coca-Cola Company produces several different cola products.
There is Coca-Cola Classic, Coke, Diet Coke and Caffeine-Free Diet Coke. Each product is aimed at a different market segment. Coca-Cola Classic is aimed at people who are older than 30, Coke is aimed at the teen market, Diet Coke is marketed towards individuals concerned about their weight or sugar intake, and Caffeine-Free Diet Coke is for people who are health-conscious. In order to segment the cola market, Coca-Cola had to determine that all consumers were not identical in their wants and needs. The company then had to determine the different parts of the market and ultimately design products that were profitable for each part of the market. As you might guess, statistics plays a critical but not exclusive role in this process.
Because there is no single way to segment a market, managers must try different segmentation variables. Segmentation variables include geographic (e.g. states, cities,
Copyright 2010 Cengage Learning. All Rights Reserved. May not be copied, scanned, or duplicated, in whole or in part. Due to electronic rights, some third party content may be suppressed from the eBook and/or eChapter(s).
Editorial review has deemed that any suppressed content does not materially affect the overall learning experience. Cengage Learning reserves the right to remove additional content at any time if subsequent rights restrictions require it.
Licensed to: iChapters User
Chapter 1 What is statistics?
9 country towns), demographic (e.g. age, gender, occupation, income, religion), psychographic (e.g. social class, lifestyle, personality) and behaviouristic (e.g. brand loyalty, usage, benefits sought). Consumer surveys are generally used by marketing researchers to determine which segmentation variables to use. For example, Coca-Cola used age and lifestyle. The age of consumers generally determines whether they buy Coca-Cola Classic or Coke. Lifestyle determines whether they purchase regular, diet or caffeine-free cola.
Surveys and statistical techniques would tell the marketing manager that the ‘average’
Coca-Cola Classic drinker is older than 30, whereas the ‘average’ Coke drinker is a teenager. Census data and surveys are used to measure the size of the two segments. Surveys would also inform about the number of cola drinkers who are concerned about kilojoules and/or caffeine. The conversion of the raw data in the survey into statistics is only one part of the process. The marketing manager must then make decisions about which segments to pursue (not all segments are profitable), how to sell and how to advertise.
In this book, we will address the part of the process that collects the raw data and produces the statistical result. By necessity, we must leave the remaining elements of the decision process to the other subjects that constitute business programs. We will demonstrate, however, that all areas of management can and do use statistical techniques as part of the information system.
1.4 Statistics and the computer
In almost all practical applications of statistics, the statistics practitioner must deal with large amounts of data. In order to calculate various statistical measures, the statistics practitioner would have to perform various calculations on the data; although the calculations do not require any great mathematical skill, the sheer amount of arithmetic makes this aspect of the statistical method time-consuming and tedious. Fortunately, numerous commercially prepared computer programs are available to perform these calculations. In most of the examples used to illustrate statistical techniques in this book, we will provide two methods for answering the question:
1 Calculating manually . Except where doing so is prohibitively time-consuming, we will show how to answer the questions using hand calculations (with only the aid of a calculator). It is useful for you to produce some solutions in this way, because by doing so you will gain insights into statistical concepts.
2 Using Microsoft Excel . Many business students own a spreadsheet package, and university and TAFE subjects incorporate a spreadsheet into their curriculum. We have chosen to use Microsoft Excel 2007 because we believe that it is and will continue to be the most popular spreadsheet package and is the most accessible package. Excel also comes with a limited statistical tool called Data Analysis . Consequently, we have included (in the CD that accompanies this book) a statistical software add-in, Data
Analysis Plus 7.0
for Excel 2007 (and Data Analysis Plus 5.1 for earlier versions of
Excel), and also created various other macros that can be loaded on to your computer to enable you to use Excel for almost all procedures. Detailed instructions are provided for all techniques. An introduction to the use of Excel is provided in Appendix
1.B of this chapter.
We anticipate that most instructors will choose both methods described above. For example, many instructors prefer to have students solve small-sample problems involving few calculations manually, but turn to the computer for large-sample problems or more complicated techniques.
Copyright 2010 Cengage Learning. All Rights Reserved. May not be copied, scanned, or duplicated, in whole or in part. Due to electronic rights, some third party content may be suppressed from the eBook and/or eChapter(s).
Editorial review has deemed that any suppressed content does not materially affect the overall learning experience. Cengage Learning reserves the right to remove additional content at any time if subsequent rights restrictions require it.
Licensed to: iChapters User
10 Business Statistics – Australian/New Zealand Edition
To allow as much flexibility as possible, most examples, exercises and cases are accompanied by a set of data stored on the CD that comes with this book. You can solve these problems using a software package. In addition, we have provided the required summary statistics of the data so that students without access to a computer to solve these problems.
Ideally, students will solve the small-sample, relatively simple problems by manual calculation and use the computer to solve the others. The approach we prefer to take is to minimise the time spent on manual calculations and to focus instead on selecting the appropriate method for dealing with a problem, and on interpreting the output after the computer has performed the necessary calculations. In this way, we hope to demonstrate that statistics can be as interesting and practical as any other subject in your curriculum.
Applets and spreadsheets
Books written for statistics courses taken by mathematics or statistics students are considerably different from this one. Not surprisingly, such courses feature mathematical proofs of theorems and derivations of most procedures. When the material is covered in this way, the underlying concepts that support statistical inference are exposed and relatively easy to see. However, this book was created for an applied course in statistics.
Consequently, we will not address directly the mathematical principles of statistics.
However, as we have pointed out above, one of the most important functions of statistics practitioners is to properly interpret statistical results, whether produced manually or by computer. And, to correctly interpret statistics, students require an understanding of the principles of statistics.
To help students understand the basic foundation, we offer two approaches. First, we have created several Excel spreadsheets that allow for what-if analyses. By changing some of the inputs, students can see for themselves how statistics works. (The name derives from ‘ What happens to the statistics if I change this value?’) Second, we have created applets, which are computer programs that perform similar what-if analyses or simulations. The applets and the spreadsheet applications appear in a number of chapters, where they are explained in greater detail.
1.5 Worldwide web and learning centre
To assist students in the various aspects of using a computer to learn statistics, we have created a web page. It offers useful information, including additional exercises and cases, corrections to the different printings and supplements, and updates on the data sets and macros. You can email the authors via the site to make comments or ask questions about the installation of the files stored on the CD. Our web page can be accessed from the publisher’s home page at www.cengage.com.au/selvanathan5e.
Copyright 2010 Cengage Learning. All Rights Reserved. May not be copied, scanned, or duplicated, in whole or in part. Due to electronic rights, some third party content may be suppressed from the eBook and/or eChapter(s).
Editorial review has deemed that any suppressed content does not materially affect the overall learning experience. Cengage Learning reserves the right to remove additional content at any time if subsequent rights restrictions require it.
Licensed to: iChapters User
Chapter 1 What is statistics?
11
IMPORTANT TERMS
Census 4
Confidence level 4
Degree of confidence 3
Descriptive statistics 2
Inferential statistics 3
Parameter 4
Population 4
Reliability 3
Sample 4
Significance level 4
Statistic 4
Statistical inference 4
Statistics 1
Exercises
1.1
In your own words, define and give an example of each of the following statistical terms: a population b sample c parameter d statistic e statistical inference
1.2
Briefly describe the difference between descriptive statistics and inferential statistics.
1.3
A bank manager with 12 000 customers commissions a survey to gauge customer views on internet banking which would incur lower bank fees. In the survey, 21% of the 300 customers interviewed said they are interested in internet banking.
a What is the population of interest?
b What is the sample?
c Is the value 21% a parameter or a statistic?
1.4
A light bulb manufacturer claims that less than
5% of his bulbs are defective. When 1000 bulbs were drawn from a large production run, 1% were found to be defective.
a What is the population of interest?
b What is the sample?
c What is the parameter?
d What is the statistic?
e Does the value 5% refer to the parameter or to the statistic?
f Is the value 1% a parameter or a statistic?
g Explain briefly how the statistic can be used to make inferences about the parameter to test the claim.
1.5
Suppose you believe that, in general, graduates of business programs are offered higher salaries upon graduating than are graduates of arts and science programs. Describe a statistical experiment that could help test your belief.
1.6
You are shown a coin that its owner says is fair in the sense that it will produce the same number of heads and tails when flipped repeatedly.
a Describe an experiment to test this claim.
b What is the population in your experiment?
c What is the sample?
d What is the parameter?
e What is the statistic?
f Describe briefly how statistical inference can be used to test the claim.
1.7
Suppose that in Exercise 1.6 you decide to flip the coin 100 times.
a What conclusion would you be likely to draw if you observed 95 heads?
b What conclusion would you be likely to draw if you observed 55 heads?
c Do you believe that, if you flip a perfectly fair coin 100 times, you will always observe exactly 50 heads? If you answered ‘no’, what numbers do you think are possible? If you answered ‘yes’, how many heads would you observe if you flipped the coin twice? Try it several times, and report the results.
1.8
The owner of a large fleet of taxis is trying to estimate his costs for next year’s operations.
One major cost is fuel purchases. To estimate fuel purchases, the owner needs to know the total distance his taxis will travel next year, the cost of a litre of fuel, and the fuel mileage (kilometres per litre) of his taxis. The owner has been provided with the first two figures (distance estimate and cost). However, because of the high cost of petrol, the owner has recently converted his taxis to operate on gas. He measures the fuel mileage (in kilometres per litre) for 50 taxis.
a What is the population of interest?
b What is the parameter the owner needs?
c What is the sample?
d What is the statistic?
e Describe briefly how the statistic will produce the kind of information the owner wants.
Copyright 2010 Cengage Learning. All Rights Reserved. May not be copied, scanned, or duplicated, in whole or in part. Due to electronic rights, some third party content may be suppressed from the eBook and/or eChapter(s).
Editorial review has deemed that any suppressed content does not materially affect the overall learning experience. Cengage Learning reserves the right to remove additional content at any time if subsequent rights restrictions require it.
Licensed to: iChapters User
Appendix 1.A
Instructions for the CD-ROM
The CD that accompanies this book contains the following software and support material: n n n n n n n n
Data Analysis Plus 7.0 (a statistical software add-in for Excel, which is consistent with Office 2007) a help file for Data Analysis Plus 7.0
Data Analysis Plus 5.1 (which works with earlier versions of Excel (Office 1997,
2000, XP, 2003) a help file for Data Analysis Plus 5.1
data files in Excel format
Excel workbooks
Seeing Statistics (Java applets that teach a number of important statistical concepts)
Formula card listing every formula in the book
Installation instructions
To install the above software on your computer, insert the CD into the appropriate drive. The
CD should automatically start and bring up the CD-ROM main menu. If it doesn’t, select the drive in which the CD is located from ‘My Computer’ and click cengage.exe
from the CD’s list of files. Now you will need to install Data Analysis Plus 7.0 and the data sets.
To install Data Analysis 7.0 (for Excel 2007), click Install Data Analysis 7.0
and run through the instructions. The package will be installed into the X1start folder of the most recent version of Excel on your computer. If properly installed, Data Analysis Plus will show as an item in the
Add-Ins of the main menu in Excel. Additionally, the help file for Data Analysis Plus 7.0
will be stored in the My Documents folder on your computer. You can access this file by selecting the Help button or it will automatically appear when you make a mistake when using Data Analysis Plus.
To install Data Analysis 5.1 (for earlier versions of Excel), click Install Data Analysis 5.1
and run through the instructions. To install the data sets, click Install Data Sets .
The Excel workbooks and Seeing Statistics applets can be accessed at any time via the main menu on the CD. (You will have to run the CD each time you wish to access any of these features. Alternatively, you can store the Excel workbooks on your hard drive.)
To manually install Data Analysis Plus and the data files, open the CD, navigate the manual install folder, and click the README file. This file contains the instructions you need to load the software manually.
For technical support, please send an email to aust.customerservice@cengage.com making reference to the book’s details (title, authors, ISBN).
Copyright 2010 Cengage Learning. All Rights Reserved. May not be copied, scanned, or duplicated, in whole or in part. Due to electronic rights, some third party content may be suppressed from the eBook and/or eChapter(s).
Editorial review has deemed that any suppressed content does not materially affect the overall learning experience. Cengage Learning reserves the right to remove additional content at any time if subsequent rights restrictions require it.
Licensed to: iChapters User
>>Figure A1.1
Blank Excel screen
Appendix 1.B
Introduction to Microsoft Excel
The purpose of this appendix is to introduce you to Microsoft Excel and provide enough instruction to allow you to use Excel to produce statistical results. We suggest that you obtain an
Excel instruction book to help you learn more about the software (e.g. for Office 2003, use Selvanathan & Selvanathan, Learning Statistics and Excel in Tandem , 2nd edn, Thomson Learning,
2006; for Office 2007, use the 3rd edn).
Opening Excel
Usually a Microsoft Excel icon will be on your computer desktop. To execute Excel, just double-click the icon. Alternatively, you can run Microsoft Excel via your Windows operating system: just click
Start , All Programs , Microsoft Office and Microsoft Excel 2007. Then click on the Office button
(on the top left-hand corner), select New from the menu, and then click on Create .
The Excel screen depicted in Figure A1.1 will appear after the program has booted up. (Unless stated otherwise, ‘clicking’ refers to tapping the left button on your mouse once; ‘double-clicking’ means quickly tapping the left button twice.) The screen that appears may be slightly different from that illustrated, depending on your version of Excel.
The Excel workbook and worksheet
Excel files are called workbooks, which contain worksheets. A worksheet consists of rows and columns. The rows are numbered, and the columns are identified by letters.
If you click the Office button on the top left-hand corner of the Excel screen and select New , you will see a worksheet like Figure A1.1. Notice that the cell in row 2 column A is active , which means that you can type in a number, word or formula in cell A2. You can designate any cell as active by moving the mouse pointer (which now appears as a large plus sign) and clicking.
Copyright 2010 Cengage Learning. All Rights Reserved. May not be copied, scanned, or duplicated, in whole or in part. Due to electronic rights, some third party content may be suppressed from the eBook and/or eChapter(s).
Editorial review has deemed that any suppressed content does not materially affect the overall learning experience. Cengage Learning reserves the right to remove additional content at any time if subsequent rights restrictions require it.
Licensed to: iChapters User
14 Business Statistics – Australian/New Zealand Edition
Alternatively, you can use any of the four Up , Down , Left or Right arrow keys. (These appear on your keyboard as arrows pointing up, down, left and right respectively.)
At the bottom left-hand corner of the screen you will see the word Ready . As you begin to type something into the active cell, the word Ready changes to Enter . Above this word you will find the tabs Sheet1 , Sheet2 and Sheet3 , the three worksheets that comprise this workbook.
You can operate on any of these as well as other sheets that may be created. To change the worksheet, use your mouse pointer and click the sheet you wish to move to.
Inputting data
To input data, open a new workbook by clicking the Office button and then selecting New . Data are usually stored in columns. Activate the cell in the first row of the column in which you plan to type the data. If you wish, you may type the name of the variable. For example, if you plan to type your assignment marks in column A you may type ‘Assignment Marks’ in cell A1. Hit the Enter key and cell A2 becomes active. Begin typing the marks, following each one by Enter . Use the arrow key or mouse pointer to move to a new column if you wish to enter another set of numbers.
Importing data files
Data files stored on the book’s CD accompany many of the examples, exercises and cases in this book. For example, the data set accompanying Example 2.5 (see page 45) contains 200 longdistance bills. These data are stored in a file called XM02-05 , which is stored in a directory
(or folder) called CH02 . (The XM refers to files attached to e X a M ples, XR is used for e X e R cises, and C refers to C ases.)
If you followed the instructions that accompany the CD, the Excel files will be stored in a folder called Excel , which is in the folder ABS Datasets , which in turn is in the folder ABS5 , which is most likely on the C drive. To import a file, click the Office button on the top left-hand corner of the Excel screen and select Open on the drop-down menu. Browse the directories to find the required file. Double-click each of the directories along the path until you reach the file you wish to open. For example, to import the data for Example 2.5, proceed along the following path:
C:\ABS5\ABS Datasets\Excel\CH02\XM02-05
The file will appear in the form in which it was saved. (All the files on the CD were saved by the author.) You may save your own files (see instructions below).
Performing statistical procedures
There are several ways to conduct a statistical analysis. These are Data Analysis , Data Analysis
Plus , the Insert function f x
( f x is displayed on the formula bar) and several Excel spreadsheets that have been stored on the CD that accompanies this book.
Data Analysis/Analysis Toolpak
The Analysis ToolPak is a group of statistical functions that comes with Excel. The Analysis
ToolPak can be accessed through the Menubar . Click Data on the menubar and then select Data
Analysis from the Analysis sub-menu. If Data Analysis . . . does not appear, click on the Office button (on the top left-hand corner of the Excel screen), select Excel Options and, on the dropdown menu, click on Add-Ins , which will display another menu. Select Analysis Toolpak and
Analysis Toolpak–VBA and then click OK. Now, if you go back to Data on the menubar, you will find Data Analysis added to the Analysis sub-menu. (Note that Analysis ToolPak is not the same as Analysis ToolPak-VBA .) If Analysis ToolPak is not shown, you will need to install it from the original Excel or Microsoft Office CD by running the setup program and following the instructions.
There are 19 menu items in Data Analysis . Click the one you wish to use, and follow the instructions described in this book. For example, one of the techniques in the menu Descriptive
Statistics is described in Chapter 4.
Copyright 2010 Cengage Learning. All Rights Reserved. May not be copied, scanned, or duplicated, in whole or in part. Due to electronic rights, some third party content may be suppressed from the eBook and/or eChapter(s).
Editorial review has deemed that any suppressed content does not materially affect the overall learning experience. Cengage Learning reserves the right to remove additional content at any time if subsequent rights restrictions require it.
Licensed to: iChapters User
Appendix 1.B
Introduction to Microsoft Excel 15
Data Analysis Plus
Data Analysis Plus is the collection of macros we created to augment Excel’s list of statistical procedures.
Data Analysis Plus ( stats.xls
) is supplied on the CD that accompanies this book.
The installation program that saves the data files on your computer will also save a copy of stats.xls
in a file called X1start . When this file is correctly saved on your computer, Data Analysis Plus will become an item in the Add-Ins heading in the Menubar . The instructions for Data
Analysis Plus are also described in this book. The CD also contains a help file that is associated with Data Analysis Plus .
When you select a statistical technique from the Data Analysis Plus menu a dialog box will appear. The dialog box will ask you for where the data are located ( Input Range ) and whether the name of the variable appears in the first row ( Labels ). You can specify the Input Range by typing in the range or by highlighting the data when the cursor is in the Input Range box or highlight the data before you click Data Analysis Plus . There are several techniques that require multiple columns. In most cases the columns must be adjacent. Read the Excel instructions in the book carefully. The output will appear on a New Worksheet.
Formula bar and Insert function
f x
On the formula bar you will find the f x
Insert function . Clicking this button produces other menus that allow you to specify functions that perform various calculations.
Saving workbooks
To save a file (either one you created or one we created that you have altered) click the
Office button on the top left-hand corner of the screen and select the option Save as on the drop-down menu. Enter the new file name and click Save . If you want to save an already saved file with the same name, choose Save on the drop-down menu. Caution, the original file will now be overwritten.
Copyright 2010 Cengage Learning. All Rights Reserved. May not be copied, scanned, or duplicated, in whole or in part. Due to electronic rights, some third party content may be suppressed from the eBook and/or eChapter(s).
Editorial review has deemed that any suppressed content does not materially affect the overall learning experience. Cengage Learning reserves the right to remove additional content at any time if subsequent rights restrictions require it.
Appendix A
SUMMARY SOLUTIONS FOR SELECTED EXERCISES
Chapter 1
1.4
1.6
1.8
a The complete production run.
b 1000 bulbs c The proportion of the production run that is defective.
d The proportion of sample bulbs that are defective.
e Parameter f Statistic g Because the sample proportion is less than
5% we can conclude that there is evidence to support the claim.
a Flip the coin 100 times and count the number of heads and tails.
b Outcomes of flips c Outcomes of the 100 flips d Proportion of heads e The proportion of heads in the 100 flips.
a The fuel mileage of all taxis in the fleet b The total distance travelled by each taxi in the fleet c The fuel mileage of the 50 taxis selected d The total distance travelled by each of the 50 taxis he selected from the fleet.
This page contains answers for this chapter only
Copyright 2010 Cengage Learning. All Rights Reserved. May not be copied, scanned, or duplicated, in whole or in part. Due to electronic rights, some third party content may be suppressed from the eBook and/or eChapter(s).
Editorial review has deemed that any suppressed content does not materially affect the overall learning experience. Cengage Learning reserves the right to remove additional content at any time if subsequent rights restrictions require it.