importing sequential files
advertisement

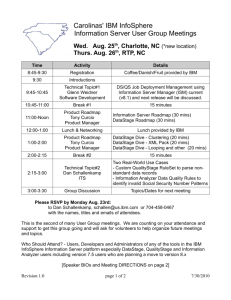
IMPORTING SEQUENTIAL FILES INFORMATION SERVER V8.7 Prepared by: March Haber, march@il.ibm.com Last Updated: January, 2012 IBM MetaData Workbench Enablement Series Table of Contents: Table of Contents:................................................................................................................... 2 Introduction............................................................................................................................... 3 Objective ................................................................................................................................... 3 Working with Sequential Files.................................................................................................. 4 Data Files .................................................................................................................................. 5 Metadata Workbench Data Lineage Analysis........................................................................... 5 Importing Sequential Files – From the DataStage and QualityStage Designer.................... 6 Publish the Sequential File Definition – From the DataStage and QualityStage Designer .. 8 Modify the Data File – From the DataStage and QualityStage Designer........................... 10 Deleting Data Files - From the Metadata Asset Manager....................................................... 11 Synchronizing Published Sequential Files.............................................................................. 12 Summary ................................................................................................................................. 13 IBM Confidential Information Page 2 of 13 IBM MetaData Workbench Enablement Series Introduction Data is at the core of our business and therefore proper management and understanding of such is essential. Furthermore, data remains at the hub of the IBM Information Server. Whether it is the ETL processes of DataStage and QualityStage, profiling by Information Analyzer or definition and understanding by Business Glossary and MetaData Workbench, all require and reference a data source. For purposes of identification and re-use, it becomes imperative that care be taken in how data structures are imported into the IBM Information Server. Several mechanisms for import exist, however in all cases the imported structure can be accessed and utilized by any of the IBM Information Server applications. Objective Learn how to import sequential files or complex flat file structures, displaying and re-using such structures within the IBM Information Server applications. For users of IBM DataStage and QualityStage: ETL Developers will often as parts of their development cycle create Table Definitions. These definitions are viewed as templates or user-defined structures, often identical to an actual physical source. They shortcut the development process, but due to their flexible nature and disassociation from the physical source, they are not considered for Lineage within the IBM MetaData Workbench. IBM Confidential Information Page 3 of 13 IBM MetaData Workbench Enablement Series Working with Sequential Files Sequential Files are often the source of a DataStage and QualityStage Job or provide Lookup Data for such Jobs. Such files may be imported into the IBM Information Server for purposes of analyzing and understanding their dependencies and usages. Sequential Files are imported from the DataStage and QualityStage Designer, by invoking the Sequential File Definitions import or the ODBC Connector. When complete, this import process creates a Table Definition representing the structure of the Sequential File, including Column Definitions and their datatypes. It is recommended to publish the created Table Definition as a Shared Table. This will allow the IBM MetaData Workbench analysis services to report on the data dependencies of the Sequential File, including searching on the File and viewing the DataStage Jobs which read or write from the File. It is not required to import Sequential Files to facilitate Data Lineage analysis within the Metadata Workbench. The Metadata Workbench will link DataStage File Stages, from different Jobs, together, when one Stage is reading and the other is writing to an identical File. An identical file is determined by the defined file name and location of the DataStage Stage. File Name: #FileDir#/DataFile.txt IBM Confidential Information Page 4 of 13 IBM MetaData Workbench Enablement Series Data Files Data Files further may be assigned a Business Term, Business Label or a Data Steward via InfoSphere Business Glossary or InfoSphere MetaData Workbench, in addition to allowing the authoring of its Description or Business Name. Data Files and Relational Databases are collectively referred as Implemented Data Resources, within the Information Server. When published, the following components and relationships are captured and defined: Data File – A user-defined structure defined during import Data File Structure – The component of the File, defined during publication Data File Field – The fields of the File, defined during import Metadata Workbench Data Lineage Analysis Data Lineage Analysis reports include the display of Data Files, as the Source or Target of a DataStage Job. The Data File created by the publication method, must reflect the fully qualified file name and location defined within the DataStage File Stages. When the file name or location includes Job Parameters or Environment Variables, those are replaced with their Default Values when evaluating Design Metadata, and with their Runtime Values when evaluating Operational Metadata. Note the example below – the defined file is evaluated as such: InputData (EWS_ProductionSourceStaging) connected to Datafile: C:/EWS/Prod/AmericaProd.txt,(found physical table) For more information please refer to the Metadata Workbench Administration Guide. IBM Confidential Information Page 5 of 13 IBM MetaData Workbench Enablement Series Importing Sequential Files – From the DataStage and QualityStage Designer Sequential File Definition import wizard: • • Launch the DataStage and QualityStage client. Select the menu item Import | Table Definitions | Sequential File Definitions. The Import dialog displays. o o o o o o Select the Directory containing the Sequential File or Complex Flat File to import. Select the File, from the list of displayed files, to be imported. Set the DataStage Project Folder to contain the Table Definition to be created by the import process. Click Import. The Define Sequential MetaData dialog appears. Choose the appropriate delimiters and options for the File. Click Preview. Ensure the data preview correctly displays the columns of the File to be imported. IBM Confidential Information Page 6 of 13 IBM MetaData Workbench Enablement Series o Click the Define Tab. Set the Column Names, SQL Type, Length, Description and other properties as appropriate. Click OK to complete the import process. The import process creates a Table Definition within the current DataStage Project. Table Definitions are specific to the DataStage Project and are not included in the display of Data Files from the Metadata Workbench or Business Glossary. Select another File for import, or click Close to close the Import MetaData dialog. o • A Table Definition The Table Definition which has been created is identified as a Sequential File. It may be necessary to view or edit the Table Definition properties to ensure the Locator Table Type indicated Sequential. IBM Confidential Information Page 7 of 13 IBM MetaData Workbench Enablement Series Publish the Sequential File Definition – From the DataStage and QualityStage Designer Shared Table Creation Wizard to publish a Table Definition as a Data File: • • • • Launch the DataStage and QualityStage client. From the DataStage Repository viewer, browse and select newly created Table Definition representing the imported Sequential File. Optional: Double-click the Table Definition to view the Table Definition details. Ensure the locator defining the type of Table Definition is set to Sequential. From the DataStage Repository viewer, select and Right-Click the Table Definition. Select Shared Table Creation Wizard from the menu. The Shared Table Creation Wizard dialog appears. IBM Confidential Information Page 8 of 13 IBM MetaData Workbench Enablement Series o o Select the Table Definition, click Next. Define the identity parameters of the Table Definition to be published. Identity parameters include the Host System and Path of the Data File. Select Create New… from the list of Association types. From the Create New Table dialog, select an existing Host System or type the name of a new Host System to be created. The host system must reflect the server, on which the Sequential File exists. Enter the complete Directory Path where the Sequential File is located. The Directory Path is used to uniquely identify the Sequential File and should not include a final slash (/ or \). Click OK to confirm the Identity details of the Sequential File. o o Click Next to proceed. Click Create to complete the process. A Data File, Data File Structure and Data File Field Assets are created within the Information Server Metadata Repository. The Table Definition displayed within the DataStage Project is updated, and bound to the published Data File. IBM Confidential Information Page 9 of 13 IBM MetaData Workbench Enablement Series Modify the Data File – From the DataStage and QualityStage Designer Metadata Management 1. 2. 5. Launch the DataStage and QualityStage client. Select the menu item Repository | Metadata Sharing | Management file menu. The Metadata Sharing dialog opens. Browse and select the newly created Data File Click Repository | Edit to edit the Data File • The name must reflect the fully qualified name as defined within the DataStage Stage. • The path must reflect the fully qualified file location as defined within the DataStage Stage. • Optional: Enter a Short or Long Description to describe and annotate the Data File asset. Click Close to save the changes. 6. 7. Optional: Click Repository | Delete to remove the selected Data File. Optional: Select the Columns tab, to view the list and structure of the contained Data File Fields 3. 4. IBM Confidential Information Page 10 of 13 IBM MetaData Workbench Enablement Series Deleting Data Files - From the Metadata Asset Manager Host Systems and Data Files may be removed from the IBM InfoSphere Metadata Asset Manager application. • • • • • • • • Browse to the Metadata Asset Manager: http://ServerName:9080/ibm/imam/console, and logon to the application with the appropriate credentials, which must include Common Metadata Administrator. Select the Repository Management Tab. Expand Browse Assets from the left navigation pane. Select Implemented Data Resources. A list of Host Systems will display. Select and expand a specific Host System to view its contained Data Files. Select a Data File to view the Asset details. Optional: Expand the Usage section of the Asset details, to view the dependency upon the Data File by other components. Click Retrieve Usage to update the list of dependencies. Select Delete from the toolbar menu item to remove the selected Asset. Click Yes to confirm the removal of the selected Asset. Deletion of a Data File will additionally remove the contained Structure and Fields. Optional: Select More Actions from the toolbar menu to view the Asset within the IBM InfoSphere Metadata Workbench. IBM Confidential Information Page 11 of 13 IBM MetaData Workbench Enablement Series Synchronizing Published Sequential Files Introduction As development and changes are made to Databases or Files and their structures, their will come a time where those changes will need to be synchronized with existing Physical Data Sources previously imported into the IBM Information Server. This synchronization should be seamless, by identifying current Information Assets and any changed content. Synchronization Synchronization requires the re-import of the Physical Data Sources. Data that has changed, will be deleted and imported, this will cause any alterations of the data, such as Definitions or Classification, to be lost. Data that has remained the same will not be affected. For example, changing a Field name will cause only the corresponding Field to be imported anew. Upon re-importing a Sequential File from within DataStage, please keep the following in mind: • • • When re-importing the File, a user will be prompted that the Shared Data File, which has been previously been published, will be disconnected. After re-importing the File, the changed Table Definition must be re-published as a Shared Data File. When re-publishing the File, the identical Host and Data File previously associated with the File should be selected. IBM Confidential Information Page 12 of 13 IBM MetaData Workbench Enablement Series Summary It is good practice to import the data structures of all sources into the IBM Information Server. This allows for a single point of reference for governance, development, definition and reporting. ETL Developers can reference the same Data Source which has been classified within Business Glossary; enriching their understanding, analyzed within Information Analyzer or depicted within a Data Lineage report from the Metadata Workbench. IBM Confidential Information Page 13 of 13