minitab: an overview

MINITAB: AN OVERVIEW
Rajender Parsad
I.A.S.R.I., Library Avenue, New Delhi – 110 012 rajender@iasri.res.in
The functionality of MINITAB is accessible through interactive windows and menus, or through a command language called session commands. There are three windows viz. Data window, Session window and Project Manager. Data window is a worksheet in a spreadsheet format, with rows and columns that intersect to form individual cells. A worksheet can contain up to 4000 columns, 1000 constants, and up to 10,000,000 rows depending on memory of the computer. The text output generated by the analyses is displayed in Session window. The Project Manager contains folders that allow one to navigate, view, and manipulate various parts of the project. Minitab has the advanced Design of Experiments
(DOE) capabilities. One can screen the factors to determine which are important for explaining process variation. It can generate two-level full and fractional factorial designs, and Plackett-Burman designs, Box-Behnken and central composite designs, simplex centroid and simplex lattice designs and Taguchi orthogonal array designs. It also allows one to perform one way analysis of variance, two-way analysis of variance for balanced data, test for equality of variances, and generate various plots. Balanced ANOVA models with crossed or nested and fixed or random factors can also be analyzed. The option General MANOVA analyzes balanced or unbalanced MANOVA models with crossed or nested and fixed or random factors. The analysis of covariance is also possible with option General MANOVA.
For initiatinfg the work on MINITAB. From thw Windows Taskbar, choose Start
→
Programs
→
MINITAB 14 (MINITAB SOLUTIONS)
→
MINITAB 14 (MINITAB 15).
Minitab opens with two main windows viz. Session Window and Data Window. The first screen of MINITAB are shown as
Minitab: An Overview
Under the Data Menu: the following options are available
Subset Worksheet - copies specified rows from the active worksheet to the new worksheet
Split Worksheet - splits or unstacks the active worksheet into two or more new worksheets based on one or more "By" variables
Merge Worksheets - combines two worksheets into one new worksheet
Sort - sorts one or more columns of data
Rank - assigns rank scores to values in a column
Delete Rows - deletes specified rows from columns in the worksheet
Erase Variables - erases any combination of columns, stored constants and matrices
Copy - copies selections from one position in the worksheet to another; can copy entire selections or a subset
Stack - stacks columns on top of each other to make longer columns
Unstack - unstacks (or splits) columns into shorter columns
Transpose Columns - switches columns to rows
Concatenate - combines two or more text columns side by side into one new column
Code - recode values in columns
Change Data Type - changes columns from one data type (such as numeric, text, or date/time) to another
Display Data - displays data from the current worksheet in the Session window
Extract from Date/Time to Numeric/Text - extracts one or more parts of a date/time column, such as the year, the quarter, or the hour, and saves that data in a numeric or a text column.
In the worksheet, one can enter the data in columns numbered as C1, C2, …. The names of the variables can be written in the row below the row cotaining column numbers C1, C2, …
Calc Menu has the following sub-options
Calculator - does arithmetic using an algebraic expression, which may contain arithmetic operations, comparison operations, logical operations, and functions
Column Statistics - calculates various statistics based on a column you select
Row Statistics - calculates various statistics for each row of the columns you select
Standardize - centers and scales columns of data
Make Patterned Data - provides an easy way to fill a column with numbers or date/time values that follow a pattern. See also Generating Patterned Data Overview for related information.
Make Mesh Data - creates a regular (x,y) mesh to use for drawing contour, 3D surface and wireframe plots, with the option to create the z-variable as well
I-180
Minitab: An Overview
Make Indicator Variables - creates indicator (dummy) variables that you can use in regression analysis. See also Generating Patterned Data Overview for related information.
Set Base - fixes a starting point for Minitab's random number generator
Random Data - displays commands for generating a random sample of numbers, sampled either from columns of the worksheet or from a variety of distributions
Probability Distributions - displays commands that allow you to compute probabilities, probability densities, cumulative probabilities, and inverse cumulative probabilities for continuous and discrete distributions
Matrices - displays commands for doing matrix operations
The main menu for statistical data analysis Stat. Under this option, following suboptions are available:
Basic Statistics
Regression
ANOVA (Analysis of Variance)
DOE (Design of Experiments)
Control Charts
Quality Tools
Reliability/Survival
Multivariate
Time Series
Tables
Nonparametrics
EDA (Exploratory Data Analysis)
Power and Sample Size
In Basic statistics, following sub-options can be used through selecting Stat > Basic Statistics
Select one of the following commands: Display Descriptive Statistics , Store Descriptive
Statistics , Graphical Summary, 1-Sample Z, 1-Sample t, 2-Sample t, Paired t, 1 Proportion, 2
Proportions, 1-Sample Poisson Rate, 2-Sample Poisson Rate, 1 Variance, 2 Variances,
Correlation, Covariance, Normality Test, Goodness-of-Fit Test for Poisson. Then further subsub options can be used.
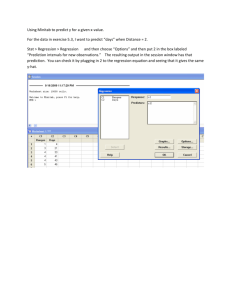
For performing regression analysis, from the menus choose Stat > Regression and then select one of the following commands to fit a model relating a response to one or more predictors :
Regression - does simple, multiple and polynomial regression
Stepwise - does stepwise regression, forward selection, and backward elimination
Best Subsets - does best subsets regression
Fitted Line Plot - fits a simple linear or polynomial regression model and plots the regression line through the actual data or the log10 of the data
Partial Least Squares - does partial least squares regression
Binary Logistic Regression - does logistic regression for a binary response variable
Ordinal Logistic Regression - does logistic regression for an ordinal response variable
Nominal Logistic Regression - does logistic regression for a nominal response variable
I-181
Minitab: An Overview
For performing Analysis of variance, Choose: Stat > ANOVA . This option allows to perform analysis of variance, test for equality of variances, and generate various plots. The analysis can be carried out, using the suitable sub-option.
One-Way - performs a one-way analysis of variance, with the response in one column, subscripts in another and performs multiple comparisons of means
One-Way (Unstacked) - performs a one-way analysis of variance, with each group in a separate column
Two-way - performs a two-way analysis of variance for balanced data
Analysis of Means - displays an Analysis of Means chart for normal, binomial, or Poisson data
Balanced ANOVA - analyzes balanced ANOVA models with crossed or nested and fixed or random factors
General Linear Model - analyzes balanced or unbalanced ANOVA models with crossed or nested and fixed or random factors. You can include covariates and perform multiple comparisons of means.
Fully Nested ANOVA - analyzes fully nested ANOVA models and estimates variance components
Balanced MANOVA - analyzes balanced MANOVA models with crossed or nested and fixed or random factors
General MANOVA - analyzes balanced or unbalanced MANOVA models with crossed or nested and fixed or random factors. You can also include covariates.
Test for Equal Variances - performs Bartlett's and Levene's tests for equality of variances
Interval Plot - produces graphs that show the variation of group means by plotting standard error bars or confidence intervals
Main Effects Plot - generates a plot of response main effects
Interactions Plot - generates an interaction plots (or matrix of plots)
Minitab can also be used for generating the layout of designs for two-level full and fractional factorial designs using Stat > DOE > Factorial . For generating Box-Behnken and central composite designs, use Stat > DOE > Response Surface . Simplex centroid and simplex lattice designs for mixture experiments can be obtained using Stat > DOE> Mixture .
Taguchi orthogonal arrays can be generated using Stat > DOE> Taguchi .
Minitab can perform principal components analysis, factor analysis, cluster analysis, discriminant analysis, and correspondence analysis. For performing multivariate data analysis, choose: Stat > Multivariate and then any one of the following sub-options depending upon the analysis required to be performed.
Principal Components - performs principal components analysis
Factor Analysis - performs factor analysis
Item Analysis performs item analysis
I-182
Minitab: An Overview
Cluster Observations - performs agglomerative hierarchical clustering of observations
Cluster Variables - performs agglomerative hierarchical clustering of variables
Cluster K-Means - performs K-means non-hierarchical clustering of observations
Discriminant Analysis - performs linear and quadratic discriminant analysis
Simple Correspondence Analysis - performs simple correspondence analysis on a two-way contingency table
Multiple Correspondence Analysis - performs multiple correspondence analysis on three or more categorical variables
Choosing: Stat > EDA performs exploratory data analysis to explore data before using more traditional methods, or to examine residuals from a model. They are particularly useful for identifying extraordinary observations and noting violations of traditional assumptions such as nonlinearity or nonconstant variance. Following sub-options may be used:
Stem-and-Leaf - does a stem-and-leaf plot
Boxplot - does a box-and-whiskers plot
Letter Values - prints a letter-value display
Median Polish - uses median polish to analyze a two-way layout
Resistant Line - fits a line to data using a procedure that is resistant to outliers
Resistant Smooth - smoothes data (usually a time series)
Rootogram - prints a suspended rootogram
Minitab may also be used for Control Charts, Quality Tools, Reliability/Survival, Time
Series, Tables, Nonparametrics and Power and Sample Size. The other menus in Minitab are:
Graph, Editor, Tools, Windows and Help. Once we click on help, we get the following screen.
I-183
Minitab: An Overview
Some practical exercises using MINITAB are given in the sequel.
¾ t-test
Example 2.1
: In a certain experiment to compare two types of pig foods A and B, the following results of increase in weights were observed in same set of 8 pigs:
Food A: 49 53 51 52 47 50 52 53
Food B: 52 55 52 53 50 54 54 53
Can we conclude that food B is better than A?
Solution: Paired t-test is to be used here.
The data has to be entered in the worksheet of the MINITAB in the following manner in two separate columns C1 and C2:
49 52
53
52
55
51 52
53
47 50
50 54
52 54
53 53
Steps: STAT
→
BASIC STATISTICS
→
PAIRED t
→
Enter C1 in First sample and C2 in second sample
→
OK
Output: Paired T-Test and CI: C1, C2
Paired T for C1 - C2
C1
N Mean
8 50.8750
C2 8 52.8750
Difference 8 -2.00000
St Dev
2.1002
SE Mean
0.7425
1.5526 0.5489
1.30931 0.46291
95% CI for mean difference: (-3.09461, -0.90539)
T-Test of mean difference = 0 (vs not = 0): T-Value = -4.32 P-Value = 0.003.
¾ Correlation and Regression
Example 2.2: In diabetic rats the blood sugar and endogenous insulin levels were estimated.
Find out if there is correlation between these two parameters
1 2 3 4 5 6 7 8
Insulin 16 21 18 11 10 8 20 11 IU
Solution: For obtaining the correlation coefficient using MINITAB from the menus choose:
Stat
→
Basic Statistics
→
Correlation
→
Select two or more numeric variables
→
Check the box Display p-values and click button OK.
The output of the above example with MINITAB is
Pearson correlation of x and y = -0.984
P-Value = 0.000
I-184
Minitab: An Overview
To calculate Spearman's rank correlation coefficient using MINITAB, ensure that there are no missing values in the data. If the data are not ranked, then use Data
→
Rank and then compute the Pearson's correlation on the columns of ranked data as explained earlier. Don't forget to uncheck Display p-values as the p-value given here is not accurate for Spearman's r. Don’t use p-values to interpret Spearman's r.
To obtain the partial correlation using MINITAB:
1 Regress the first variable on the other variables and store the residuals.
2 Regress the second variable on the other variables and store the residuals.
3 Calculate the correlation between the two columns of residuals.
Example 2.3: Given the following data, fit a simple linear regression equation between y and x
1
. Also fit a multiple linear regression equation with y as dependent and x
1
, x
2
, x
3
and x
4
as independent variables.
Observation
No. y x
1 x
2 x
3 x
4
1 78.5
2 74.3
7
1
26
29
6
15
60
22
3 104.3
4 87.6
5 95.9
6 109.2
7 102.7
8 72.5
9 93.1
10 115.9
11
11
7
11
3
1
2
21
56
31
52
55
71
31
54
47
8
8
6
9
17
22
18
4
20
47
33
22
6
44
22
26
11 83.8
12 113.3
13 119.4
1
11
10
40
66
68
23
9
8
34
12
12
For fitting a regression equation using MINITAB: From the menus choose:
Stat
→
Regression
→
Select Response Variable
→
Select one or more independent variables.
¾ Multiple Linear Regression
The output for the above example obtained using MINITAB is
Regression Analysis: y versus x
1
, x
2
, x
3
, x
4
The regression equation is y = 53.6 + 1.59 x
1
+ 0.661 x
2
+ 0.084 x
3
- 0.076 x
4
Predictor Coef SE Coef T
Constant 53.6300 10.2700 5.22 x1 1.5887 0.2670 5.95 x2 x3 x4
0.6606
0.0845
-0.0758
0.1140
0.2493
0.1144
5.79
0.34
-0.66
RMSE (S) = 3.00032 R-Sq = 97.7% R-Sq(adj) = 96.5%
0.001
0.000
0.000
0.743
0.526
P
I-185
Minitab: An Overview
Source
Regression
Residual Error
DF
4
8
Analysis of Variance
SS
3015.59
72.02
MS
753.90
9.00
F
83.75
P
0.000
Total 12 3087.61
Source x1 x2 x3
DF Seq SS
1 1546.50
1 1462.49
1 2.64
1 3.96 x4
From the above example, it can be seen that 97.7% of the variation in y is explained by x
1
, x
2
, x
3
and x
4
. Coefficients of x
1
and x
2 are significantly different from zero whereas that of x
3
and x
4
are not.
¾ ANOVA and ANCOVA
Example 2.4: A trial was designed to evaluate 15 rice varieties grown in soil with a toxic level of iron. The experiment was in a RCB design with three replications. Guard rows of a susceptible check variety were planted on two sides of each experimental plot. Scores for tolerance for iron toxicity were collected from each experimental plot as well as from guard rows. For each experimental plot, the score of susceptible check (averaged over two guard rows) constitutes the value of the covariate for that plot. Data on the tolerance score of each variety (Y variable) and on the score of the corresponding susceptible check (X variable) are shown below:
Scores for tolerance for iron toxicity (Y) of 15 rice varieties and those the corresponding guard rows of a susceptible check variety (X) in a RCB trial
Variety
Number
1.
2.
3.
4.
5.
X Y X Y X Y
15 22 16 13 16 14
16 14 15 23 15 23
15 24 15 24 15 23
16 13 15 23 15 23
17 17 17 16 16 16
6.
7.
8.
9.
16 14 15 23 15 23
16 13 15 23 16 13
16 16 17 17 16 16
17 14 15 23 15 24
10. 17 17 17 17 15 26
11. 16 15 15 24 15 25
12. 16 15 15 23 15 23
13. 15 24 15 24 16 15
14. 15 25 15 24 15 23
15. 15 24 15 25 16 16
I-186
Minitab: An Overview
For performing the ANOVA for the above data using MINITAB: First enter the data in the
Worksheet of MINITAB in four columns C1: rep; C2: trt; C3: Y and C4: X. Now fFrom menus choose Stat
→
ANOVA
→
General Linear Model . In the response variable Box, enter the variable Y, in the model enter trt rep. Specify the terms for comparing means as trt and the method for multiple comparisons. As the interest is in making all possible pairwise treatment comparisons, select Tukey or Bonferroni method. Check the Box TEST for multiple comparison output. If only ANOVA is to be performed, then C4 is not required. The out put obtained is given in the sequel.
The usual analysis of variance without using the covariate (X variable) is as follows:
Source DF SS Mean Square F (F-calc) p(Pr>F)
18.99 1.04 0.445
52.02 2.85 0.075
18.24
R-Square R-Sq(Adj) s (Root MSE) C.V.
0.4201 (42.01%) 8.88% 4.2704 21.5436
Y - Mean
19.82222
Least Squares Treatment Means for yield are
Treatment Mean SE mean
1 16.33
2 20.00
3 23.67
4 19.67
5 16.33
6 20.00
7 16.33
2.466
2.466
2.466
2.466
2.466
2.466
2.466
8 16.33
9 20.33
10 20.00
11 21.33
12 20.33
13 21.00
2.466
2.466
2.466
2.466
2.466
2.466
14 24.00
15 21.67
2.466
2.466
Neither Bonferroni Simultaneous Tests nor Tukey Simultaneous Tests for making all possible pairwise treatment comparisons resulted into p<0.05.
For performing analysis of covariance, in addition to the above, define covariate X in the diaglog box. Using the covariate, analysis is the following:
I-187
Minitab: An Overview
Source x
DF Seq SS Adj. SS Mean Square F (F-calc) p(Pr>F)
1 589.430 398.752
398.752
96.24 0.000
Treatment 14 156.797 152.561
Replication 2 22.480 22.480
Error 28 111.871 111.871
10.897
11.240
4.143
2.63 0.015
2.71 0.084
R-Square R-Sq(Adj) s (Root MSE) C.V.
0.8730 (87.30%) 79.30% 2.03552 10.2689
Y - Mean
19.82222
Coef P
Constant 114.673 9.673 11.85 0.000
It is interesting to note that the use of a covariate has resulted into a considerable reduction in the error mean square and hence the CV has also reduced drastically. This has helped in catching the small differences among the treatment effects as significant. This was not possible when the covariate was not used. The covariance analysis will thus result into a more precise comparison of treatment effects. Least Squares Treatment Means for yield are
Treatment Mean SE mean
1 16.87
1.177
2 18.51
3 20.15
4 18.18
5 22.96
1.185
1.229
1.185
1.356
6 18.51
7 16.87
8 20.93
9 20.87
10 24.60
11 19.84
1.185
1.177
1.265
1.177
1.265
1.185
12 18.84
13 19.51
14 20.48
15 20.18
1.185
1.185
1.229
1.185
The probability of significance of pairwise comparisons among the least square estimates of the treatment effects based on Tukey Simultaneous Tests are given below
I-188
Minitab: An Overview
1 .
2 0.9994 .
3 0.8280 .
4 1.0000 1.0000 0.9959
5 0.0930 0.5359 0.9754 0.4249
.
6 0.9994 1.0000 0.9994 1.0000
0.5359
.
.
7 1.0000 0.9994 0.8280 1.0000
0.093
0.9994
.
8 0.5536 0.9840 1.0000 0.9551
0.9945
0.9840
0.5536
.
9 0.5302 0.9789 1.0000 0.9418
0.9958
0.9789
0.5302
1.0000
10 0.0077 0.0930 0.5359 0.0622
0.9994
0.0930
0.0077
0.6586
11 0.8890 0.9999 1.0000 0.9992
0.9219
0.9999
0.889
1.0000
12 0.9959 1.0000 1.0000 1.0000
0.651
1.0000
0.9959
0.9958
13 0.9504 1.0000 1.0000 0.9999
0.8529
1.0000
0.9504
0.9999
14 0.7204 0.9959 1.0000 0.9829
0.9917
0.9959
0.7204
1.0000
15 0.7967 0.9992 1.0000 0.9949
0.9655
0.9992
0.7967
1.0000
9 10 11 12 13 14 15
9 .
11 1.0000 0.3659 .
12 0.9945 0.1363 1.0000 .
13 0.9999 0.2713 1.0000 1.0000
14 1.0000 0.651 1.0000 0.9994
1.0000
.
15 1.0000 0.4762 1.0000 0.9999
1.0000
1.0000
.
.
Treatments 1 and 7 and 7 and 10 are found to be significantly different.
¾ Combined Analysis of Data
For the data in Example 6.2 in Fundamentals of Design of Experiments given in Module 2:
Enter the data in Worksheet of MINITAB in 5 columns: C1: Year; C2: Rep; C3: blk; C4: trt;
C5: Yield.
Here Yr, Rep, Blk and trt represent respectively denote the year, replication, block and treatment.
At the first instance, split the worksheet for two years separately. This can be achieved by selecting Data
→
Split Worksheet
→
by Variable Yr . Now using the worksheet for Year 1, choose from the menu: STAT
→
ANOVA
→
General Linear Model. In the response variable Box, enter the variable yield, in Model enter Rep blk(rep) trt and Click OK .
The output obtained is given in the sequel.
I-189
Minitab: An Overview
Source rep
Analysis of Variance for yield: Year 1 (Using Adjusted SS for Tests)
DF
3
Seq SS Adj SS Adj MS F P
186.046
186.046
62.015
7.53 0.000
358.943
14.956
1.82
3442.148
3442.148
71.711
8.7 0.000
trt
Error
Total
120
195
988.707
6025.758
988.707
S = 2.87040 R-Sq = 83.59% R-Sq(adj) = 73.34%
8.239
Similarly, the analysis of data for second year can be performed, the results obtained are given in the sequel.
Analysis of Variance for yield: Year 2 (Using Adjusted SS for Tests)
Source rep
DF
48
3
Seq SS
176.399
Adj SS
176.399
Adj MS F
58.800
11.81
P
0.000
trt
Error
48
120
3353.212
597.305
556.491
23.187
4.66
3353.212
597.305
69.859
4.978
14.03 0.000
Total 195 5413.927
S = 2.23104 R-Sq = 88.97% R-Sq(adj) = 82.07%
The interpretations are same as given in Example 2 Section 6. Equality of error variance can be tested using F-test. As above, the errors are heterogeneous. Therefore, the data were transformed by dividing each observation with corresponding root mean square error. For this we create a new column of root mean square error in the worksheet and create a new variable
= original variable/sqrt(MSE) using CALC
→
CALCULATOR .
In addition to the above steps, select new variable as response variable, enter model as yr rep(yr) blk( rep yr) trt trt*yr, Define Yr in the Subdiaglog Box Random Factors. Now Click on Results and Check on the Display expected mean squares and variance components. The results obtained are
General Linear Model: Transformed Variable versus yr, trt, rep, blk
Factor Type Levels Values yr random 2 rep(yr) random 8 blk(yr rep) random 56 trt fixed 49
1, 2
1, 2, 3, 4, 1, 2, 3, 4
1, 2, 3, 4, 5, 6, 7, 1, 2, 3, 4, 5, 6, 7, 1, 2, 3,
4, 5, 6, 7, 1, 2, 3, 4, 5, 6, 7, 1, 2, 3, 4, 5, 6,
7, 1, 2, 3, 4, 5, 6, 7, 1, 2, 3, 4, 5, 6, 7, 1, 2,
3, 4, 5, 6, 7
1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15,
16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27,
28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39,
40, 41, 42, 43, 44, 45, 46, 47, 48, 49
I-190
Minitab: An Overview
Analysis of Variance for transformed variable, using Adjusted SS for Tests
Source yr
DF
1
Seq SS
4911.415
Adj SS Adj MS F P
4911.415 4911.415 422.37 0.000 x rep(yr) blk(yr rep)
6
48
58.828
439.557
58.828
139.74
9.805
2.80 0.023 x
2.911
2.58 0.00
trt yr*trt
Error
48
48
240
391
968.42
130.857
271.335
6780.412
Total x Not an exact F-test.
S = 1.06328 R-Sq = 96.00% R-Sq(adj) = 93.48%
968.42
20.175
7.40 0.00
130.857
271.335
2.726
1.131
2.41 0.00
Expected Mean Squares, using Adjusted SS
Source Expected Mean Square for Each Term
1 yr (6) + 4.0000 (5) + 7.0000 (3) + 49.0000 (2) + 196.0000 (1)
2 rep(yr) (6) + 7.0000 (3) + 49.0000 (2)
3 blk(yr rep) (6) + 5.2500 (3)
4 trt (6) + 3.5000 (5) + Q[4]
5 yr*trt (6) + 3.5000 (5)
6 Error (6)
Error Terms for Tests, using Adjusted SS
Source ErrorDF Error MS Synthesis of Error MS
1 yr 8.33 11.628 (2) + 1.1429 (5) - 1.1429 (6)
2 rep(yr) 39.06 3.505 1.3333 (3) - 0.3333 (6)
3 blk(yr rep) 240.00 1.131
4 trt 48.00 2.726
5 yr*trt 240.00 1.131
(6)
(5)
(6)
It can easily be seen that the testing of random effects has been one in one step using
MINITAB.
¾ Factorial Experiments:
The data given in Example 7.1 can be analyzed using MINITAB:
Enter the data in the worksheet of the MINITAB in 6 columns C1: Rep, C2: Block; C3:N;
C4: P; C5:K; C6: Yield.
Choose: Stat
→
ANOVA
→
General Linear Model. Now in the Dialog Box define Yield as
Response Variable. In the model define rep block (rep) n k n*p n*k p*k n*p*k. Now Choose comparisons, click the Radio Button of Pairwise Comparisons. In the Terms define n p k n*p n*k p*k n*p*k, Check the boxes of Tukey Method and Test.
I-191
Minitab: An Overview
Analysis of Variance for yield, using Adjusted SS for Tests
Source DF Seq SS Adj SS Adj MS F P rep 3 15.7187 15.7187 5.2396 10.71 0.000 blk(rep) 8 14.5571 14.1946 1.7743 3.63 0.003 n 2 89.1108 89.1108 44.5554 91.05 0.000 p 2 55.9270 55.9270 27.9635 57.14 0.000 k 1 3.2173 3.2173 3.2173 6.57 0.014 n*p 4 4.2752 4.2752 1.0688 2.18 0.087 n*k 2 0.7301 0.7301 0.3650 0.75 0.480 p*k 2 0.1128 0.1128 0.0564 0.12 0.891 n*p*k 4 2.1958 2.1958 0.5490 1.12 0.359
Error 43 21.0427 21.0427 0.4894
Total 71 206.8876
S = 0.699547 R-Sq = 89.83% R-Sq(adj) = 83.21%
The probability of significance of pairwise comparisons among levels of N based on Tukey
Simultaneous Tests are i/j 40 80 120
40 .
80 0.0000 .
The probability of significance of pairwise comparisons among levels of P based on Tukey
Simultaneous Tests are i/j 0 40 80
0 .
40 0.0000 .
The probability of significance of pairwise comparisons among levels of K based on Tukey
Simultaneous Tests are
Difference
K
40 -0 of Means
0.4228
SE of Adjusted
Difference T-Value P-Value
0.1649 2.564 0.0139
Similarly the probability of significance of pairwise comparisons among levels of N*P, N*K,
P*K and N*P*K based on Tukey Simultaneous Tests can be obtained.
¾ Diagnostics and Remedial Measures
Steps for carrying out these Diagnostics and Remedial Measures using MINITAB
First of all fit the model as per the design adopted using the options Stat
→
ANOVA
→
General Linear Model from the menus and from the Dialog Box Select storage and store residuals in a column in the worksheet. Once the residuals are stored on the worksheet, then use the following steps.
I-192
Minitab: An Overview
Testing Normality
From the menus choose: Stat
→
Basic Statistics
→
Normality
→
In the Dialog Box. Select the stored residual as variable in Variable list and then select one of the three tests viz. Anderson-
Darling, Ryan-Joiner and Kolmogrov-Smirnov tests and Click OK.
Test for Homogeneity of Variances
From the menus choose: Stat
→
ANOVA
→
Test for Equality of Variances
→
In the Dialog Box.
Select the stored residual in the Response Box and Treatment in the Factors Box and then choose the confidence level and Click OK.
Transformations of Data
For making logarithmic, square root and arcsine transformation, one can use the
Calc
→
Calculator. It is followed by storing the result in a variable by entering a target column in the worksheet. Then define the functions that are to be used for transformation in the
Expression SubDialog Box. For logarithmic transformation, define LOGT (Column number or variable name to be transformed) and Click OK. The transformed data will be stored in the target column. For square root transformation, use SQRT (Column number or variable name to be transformed) in the Expression SubDialog Box and for Arcsine transformation, use the expression ASIN (sqrt of the column number in which data is given/100)*180*7/22. The multiplication by 180*7/22 is done to convert the data from radians to degrees. If the original data lies between 0 and 1, then do not divide by 100.
Now perform the analysis again and test normality and homogeneity of error terms. If the errors are now normal and homogeneous, perform the analysis on the transformed data, otherwise use an appropriate non-parametric test. For performing the non-parametric analysis, from the menus choose: Stat
→
Nonparametrics
→
Appropriate test (Friedman, say)
→
In the
Dialog Box select Response, Treatment and Block variables and Click OK.
Example 2.4: Suppose an entomologist is interested in determining whether four different kinds of traps caught equivalent insects when applied to same field. Each of the traps is used six times on the field and resulting data (number of insects per hour) are as shown below alongwith mean, variance and range.
II IV
7
Y i S i
2
17 2
28 45 31 36
61 98 71 79
118 172 143 168 147
37
From the table it is clear that variances are heterogeneous and variance is proportional to mean.
Obtain the residuals for testing the normality and homogeneity of error terms. The residuals obtained are given below:
I-193
Minitab: An Overview
A
B
C
D
VI
S i
2
-1.00 0.75 -1.25
3.25
-11.75
-14.00 9.75 0.00
-3.25
-4.75
12.25
-13.00 11.75 23.00
-19.25
12.25
-14.75
28.00 -22.25 -33.00
23.75
-10.75
14.25
0 50.35
0 94.85
0 314.85
0 650.20
Normality of error terms:
Anderson-Darling Test Ryan-Joiner Test Kolmogrov-Smirnov Test
Statistic
(AD) p-value Statistic
(RJ) p-value Statistic
(KS) p-value
0.208 0.848 0.992 >0.100 0.110 >0.150
The errors were found to be normally distributed. Therefore, homogeneity of error variances was tested using Bartlett's test.
Using MINITAB, we get the output as
Bartlett's Test (normal distribution)
Test statistic = 8.32, p-value = 0.040
The
S i
2
Y i .
are 5.77, 5.32, 3.43 and 5.43, indicating that variance is proportional to mean.
Therefore, square root transformation should be used. After application of square root transformation, the residuals are
Treatment Replication Variance
I II III IV V VI
S i
2
A
B
C
D
-0.03614 -0.92542 1.05800
0.20614
0.98287
-1.28544 0.928
-1.34939 0.87854 -0.40473
-0.12183
-0.42993
1.42735 0.999
-0.28226 0.78841 0.99143
-1.08068
0.30794
-0.72483 0.694
1.66779 -0.74153 -1.64469
0.99637
-0.86087
0.58293 1.622
Normality of error terms on the transformed data:
Anderson-Darling Test Ryan-Joiner Test Kolmogrov-Smirnov Test
Statistic
(AD) p-value Statistic
(RJ) p-value Statistic
(KS) p-value
0.391 0.353 0.984 >0.100 0.127 >0.150
The errors remain normally distributed after transformation. The results of homogeneity of error variances using Bartlett's test are
Bartlett's Test (normal distribution): Test statistic = 0.89, p-value = 0.828
Hence, we conclude that the errors are normally distributed and have a constant variance after transformation.
I-194
Minitab: An Overview
The results of analysis of variance with original and transformed data are given in the sequel.
ANOVA: Original Data
Source DF Seq SS Adj. SS Mean Square F (F-calc) p(Pr>F)
Replication 5 689.0 689.0
137.8
0.37 0.86
Treatment 3 70828.5 70828.5
Error 15 5551.0 5551.0
23609.5
370.1
63.80 0.00
R-Square R-Sq(Adj) s (Root MSE)
Tukey Simultaneous Tests for All Pairwise Treatment Comparisons
1 2 3 4
1 .
2 0.3525 .
3 0.0001
4 0.0000 0.0000 0.0001 .
ANOVA: Transformed Data
Source DF Seq SS Adj. SS Mean Square F (F-calc) p(Pr>F)
Replication 5 5.055 5.055
Treatment 3 326.603 326.603
Error 15 21.214 21.214
1.011
108.868
1.414
0.71 0.622
76.98 0.000
R-Square R-Sq(Adj) s (Root MSE)
Tukey Simultaneous Tests for All Pairwise Treatment Comparisons
1 2 3 4
1 .
2 0.0091
0.0015
.
With transformed data treatments 1 and 2 are significantly different whereas with original data, they were not.
I-195
Minitab: An Overview
¾
¾
Probit Analysis
Example 1: Finney (1971) gave a data representing the effect of a series of doses of carotene (an insecticide) when sprayed on Macrosiphoniella sanborni (some obscure insects). The Table below contains the concentration, the number of insects tested at each dose, the proportion dying and the probit transformation (probit+5) of each of the observed proportions.
Concentration
(mg/1)
No. of insects (n)
No. of affected (r)
%kill (P) Log concentration
(x)
Empirical probit
0 49 0 0 - -
Steps for carrying out the Probit Analysis using MINITAB
For the data given in example 1, first enter the data in the Worksheet of MINITAB in three coumns C1: dose
;
C2: total Insects; C3: Insects killed or affected. Now create a column C4 for logdose by using LOGT(C1) using menu Calc.
Now Choose Stat > Reliability/Survival > Probit Analysis.
From the dialog box; Choose the data format "Success/trial" or "Response/frequency". In the present case, the data is in success trial format, therefore, enter C3, the column containing the number of successes in Number of Successes box and C2, the total number of trials in
Number of Trials subbox. In the subbox for stress/stimulus enter C4, the column containing the logdose. Since, there is only one stimulus, therefore, the subbox pertaining to Factor
(optional) may be left blank. Choose the distribution as normal.
The other options available on the dialog box are: Estimate, Graphs, Options, Results and
Storage.
Using the option Estimate, One can
estimate percentiles for the percents you specify. These percentiles are added to the default table of percentiles.
estimate survival probabilities for the stress values you specify.
One can also change the method of estimation for the confidence intervals and the level of confidence. The default option is two sided 95% fiducial intervals.
Other options may also be used, as and when required. For this example, we chose the additional percentiles as 65 and survival probabilities for stress level 0.9 (logdose).
I-196
Minitab: An Overview
Probit Analysis: affect, total versus logdose
Distribution: Normal
Response Information
Variable Value Count affect Success 132
Failure 111 total Total 243
Estimation Method: Maximum Likelihood
Regression Table
Standard
Variable Coef Error Z P
Constant -2.88746 0.350134 -8.25 0.000 logdose 4.21320 0.478303 8.81 0.000
Log-Likelihood = -120.052
Goodness-of-Fit Tests
Method Chi-Square DF P
Pearson 1.72888 3 0.631
Deviance 1.73897 3 0.628
Tolerance Distribution: Parameter Estimates
Standard 95.0% Normal CI
Parameter Estimate Error Lower Upper
Mean 0.685338 0.0220962 0.642030 0.728646
StDev 0.237349 0.0269451 0.190001 0.296497
Table of Percentiles
Standard 95.0% Normal CI
Percent Percentile Error Lower Upper
1 0.133180 0.0686394 -0.0013503 0.267711
2 0.197882 0.0617254 0.0769020 0.318861
3 0.238933 0.0573944 0.126442 0.351423
4 0.269813 0.0541723 0.163638 0.375989
5 0.294933 0.0515787 0.193840 0.396025
6 0.316313 0.0493935 0.219504 0.413123
7 0.335060 0.0474969 0.241967 0.428152
8 0.351845 0.0458160 0.262047 0.441643
9 0.367110 0.0443030 0.280278 0.453943
10 0.381162 0.0429251 0.297031 0.465294
20 0.485580 0.0332991 0.420314 0.550845
30 0.560872 0.0274617 0.507048 0.614696
40 0.625206 0.0238086 0.578542 0.671870
50 0.685338 0.0220962 0.642030 0.728646
60 0.745470 0.0224241 0.701519 0.789420
I-197
Minitab: An Overview
65 0.776793 0.0233958 0.730939 0.822648
70 0.809804 0.0249330 0.760936 0.858672
80 0.885096 0.0299366 0.826422 0.943771
90 0.989513 0.0389715 0.913131 1.06590
91 1.00357 0.0402991 0.924581 1.08255
92 1.01883 0.0417626 0.936978 1.10068
93 1.03562 0.0433947 0.950564 1.12067
94 1.05436 0.0452427 0.965688 1.14304
95 1.07574 0.0473792 0.982882 1.16860
96 1.10086 0.0499232 1.00301 1.19871
97 1.13174 0.0530936 1.02768 1.23580
98 1.17279 0.0573685 1.06035 1.28523
99 1.23750 0.0642153 1.11164 1.36336
Table of Survival Probabilities
95.0% Normal CI
Stress Probability Lower Upper
0.9 0.182888 0.122757 0.258650
Interpretation: The goodness-of-fit tests (p-values = 0.631, 0.628) suggest that the distribution and the model fits the data adequately. In this case, the fitting is done on normal equivalent deviate only without adding 5. Therefore, log LD50 or lof ED50 corresponds to the value of Probit=0.
Log LD50 is obtained as 0.685338. Therefore, the stress level at which the
50% of the insects will be killed is (10
0.685338
=4.845 mg/l). Similarly the stress level at which
65% of the insects will be killed is (10
0.776793
= 5.981 mg/l). At logdose = 0.9, what percentage of insects will be killed? Results indicate that 18.29% of the insects will be killed.
If there are more than one factor used for experimentation, then for the analysis of data follow the same steps as in Example 1 with the addition that in the factor subbox define factor as f.
I-198