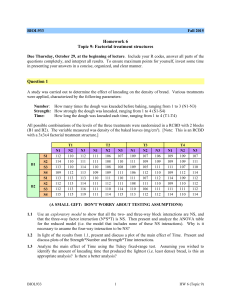
Three-way ANOVA Chapter
advertisement

Cohen_Chapter22.j.qxd 8/23/02 11:56 M Page 688 Chapter 22 • Three-Way ANOVA 688 Three-Way ANOVA You will need to use the following from previous chapters: 22 Chapter A CONCEPTUAL FOUNDATION Symbols k: Number of independent groups in a one-way ANOVA c: Number of levels (i.e., conditions) of an RM factor n: Number of subjects in each cell of a factorial ANOVA NT: Total number of observations in an experiment Formulas Formula 16.2: SSinter (by subtraction) also Formulas 16.3, 16.4, 16.5 Formula 14.3: SSbet or one of its components Concepts Advantages and disadvantages of the RM ANOVA SS components of the one-way RM ANOVA SS components of the two-way ANOVA Interaction of factors in a two-way ANOVA So far I have covered two types of two-way factorial ANOVAs: two-way independent (Chapter 14) and the mixed design ANOVA (Chapter 16). There is only one more simple two-way ANOVA to describe: the two-way repeated measures design. [There are other two-way designs, such as those including randomeffects or nested factors, but they are not commonly used—see Hays (1994) for a description of some of these.] Just as the one-way RM ANOVA can be described in terms of a two-way independent-groups ANOVA, the two-way RM ANOVA can be described in terms of a three-way independent-groups ANOVA. This gives me a reason to describe the latter design next. Of course, the threeway factorial ANOVA is interesting in its own right, and its frequent use in the psychological literature makes it an important topic to cover, anyway. I will deal with the three-way independent-groups ANOVA and the two-way RM ANOVA in this section and the two types of three-way mixed designs in Section B. Computationally, the three-way ANOVA adds nothing new to the procedure you learned for the two-way; the same basic formulas are used a greater number of times to extract a greater number of SS components from SStotal (eight SSs for the three-way as compared with four for the two-way). However, anytime you include three factors, you can have a three-way interaction, and that is something that can get quite complicated, as you will see. To give you a manageable view of the complexities that may arise when dealing with three factors, I’ll start with a description of the simplest case: the 2 × 2 × 2 ANOVA. A Simple Three-Way Example 688 At the end of Section B in Chapter 14, I reported the results of a published study, which was based on a 2 × 2 ANOVA. In that study one factor contrasted subjects who had an alcohol-dependent parent with those who did not. I’ll call this the alcohol factor and its two levels, at risk (of codependency) and control. The other factor (the experimenter factor) also had two levels; in one level subjects were told that the experimenter was an exploitive person, and in the other level the experimenter was described as a nurturing person. All of the subjects were women. If we imagine that the experiment was replicated using equal-sized groups of men and women, the original Cohen_Chapter22.j.qxd 8/23/02 11:56 M Page 689 Section A • Conceptual Foundation 689 two-way design becomes a three-way design with gender as the third factor. We will assume that all eight cells of the 2 × 2 × 2 design contain the same number of subjects. As in the case of the two-way ANOVA, unbalanced threeway designs can be difficult to deal with both computationally and conceptually and therefore will not be discussed in this chapter (see Chapter 18, section A). The cell means for a three-factor experiment are often displayed in published articles in the form of a table, such as Table 22.1. Nurturing Exploitive Row Mean Control: Men Women Mean 40 30 35 28 22 25 34 26 30 At risk: Men Women Mean Column mean 36 40 38 36.5 48 88 68 46.5 42 64 53 41.5 Table 22.1 Graphing Three Factors The easiest way to see the effects of this experiment is to graph the cell means. However, putting all of the cell means on a single graph would not be an easy way to look at the three-way interaction. It is better to use two graphs side by side, as shown in Figure 22.1. With a two-way design one has to decide which factor is to be placed along the horizontal axis, leaving the other to be represented by different lines on the graph. With a three-way design one chooses both the factor to be placed along the horizontal axis and the factor to be represented by different lines, leaving the third factor to be represented by different graphs. These decisions result in six different ways that the cell means of a three-way design can be presented. Let us look again at Figure 22.1. The graph for the women shows the twoway interaction you would expect from the study on which it is based. The graph for the men shows the same kind of interaction, but to a considerably lesser extent (the lines for the men are closer to being parallel). This difference Women Figure 22.1 Men At risk 80 80 70 70 60 60 50 50 40 40 30 30 Control 20 0 Nurturing Exploitive Graph of Cell Means for Data in Table 22.1 At risk Control 20 0 Nurturing Exploitive Cohen_Chapter22.j.qxd 8/23/02 11:56 M Page 690 690 Chapter 22 • Three-Way ANOVA in amount of two-way interaction for men and women constitutes a three-way interaction. If the two graphs had looked exactly the same, the F ratio for the three-way interaction would have been zero. However, that is not a necessary condition. A main effect of gender could raise the lines on one graph relative to the other without contributing to a three-way interaction. Moreover, an interaction of gender with the experimenter factor could rotate the lines on one graph relative to the other, again without contributing to the three-way interaction. As long as the difference in slopes (i.e., the amount of two-way interaction) is the same in both graphs, the three-way interaction will be zero. Simple Interaction Effects A three-way interaction can be defined in terms of simple effects in a way that is analogous to the definition of a two-way interaction. A two-way interaction is a difference in the simple main effects of one of the variables as you change levels of the other variable (if you look at just the graph of the women in Figure 22.1, each line is a simple main effect). In Figure 22.1 each of the two graphs can be considered a simple effect of the three-way design—more specifically, a simple interaction effect. Each graph depicts the two-way interaction of alcohol and experimenter at one level of the gender factor. The three-way interaction can be defined as the difference between these two simple interaction effects. If the simple interaction effects differ significantly, the three-way interaction will be significant. Of course, it doesn’t matter which of the three variables is chosen as the one whose different levels are represented as different graphs—if the three-way interaction is statistically significant, there will be significant differences in the simple interaction effects in each case. Varieties of Three-way Interactions Just as there are many patterns of cell means that lead to two-way interactions (e.g., one line is flat while the other goes up or down, the two lines go in opposite directions, or the lines go in the same direction but with different slopes), there are even more distinct patterns in a three-way design. Perhaps the simplest is when all of the means are about the same, except for one, which is distinctly different. For instance, in our present example the results might have shown no effect for the men (all cell means about 40), no difference for the control women (both means about 40), and a mean of 40 for at-risk women exposed to the nice experimenter. Then, if the mean for atrisk women with the exploitive experimenter were well above 40, there would be a strong three-way interaction. This is a situation in which all three variables must be at the “right” level simultaneously to see the effect—in this variation of our example the subject must be female and raised by an alcohol-dependent parent and exposed to the exploitive experimenter to attain a high score. Not only might the three-way interaction be significant, but one cell mean might be significantly different from all of the other cell means, making an even stronger case that all three variables must be combined properly to see any effect (if you were sure that this pattern were going to occur, you could test a contrast comparing the average of seven cell means to the one you expect to be different and not bother with the ANOVA at all). More often the results are not so clear-cut, but there is one cell mean that is considerably higher than the others (as in Figure 22.1). This kind of pattern is analogous to the ordinal interaction in the two-way case and tends to cause all of the effects to be significant. On the other hand, a three-way interaction could arise because the two-way interaction reverses its pattern when changing levels of the third variable (e.g., imagine that in Figure 22.1 Cohen_Chapter22.j.qxd 8/23/02 11:56 M Page 691 Section A • Conceptual Foundation the labels of the two lines were reversed for the graph of men but not for the women). This is analogous to the disordinal interaction in the two-way case. Or, the two-way interaction could be strong at one level of the third variable and much weaker (or nonexistent) at another level. Of course, there are many other possible variations. And consider how much more complicated the three-way interaction can get when each factor has more than two levels (we will deal with a greater number of levels in Section B). Fortunately, three-way (between-subjects) ANOVAs with many levels for each factor are not common. One reason is a practical one: the number of subjects required. Even a design as simple as a 2 × 3 × 4 has 24 cells (to find the number of cells, you just multiply the numbers of levels). If you want to have at least 5 subjects per cell, 120 subjects are required. This is not an impractical study, but you can see how quickly the addition of more levels would result in a required sample size that could be prohibitive. Main Effects In addition to the three-way interaction there are three main effects to look at, one for each factor. To look at the gender main effect, for instance, just take the average of the scores for all of the men and compare it to the average of all of the women. If you have the cell means handy and the design is balanced, you can average all of the cell means involving men and then all of the cell means involving women. In Table 22.1, you can average the four cell means for the men (40, 28, 36, 48) to get 38 (alternatively, you could use the row means in the extreme right column and average 34 and 42 to get the same result). The average for the women (30, 22, 40, 88) is 45. The means for the other main effects have already been included in Table 22.1. Looking at the bottom row you can see that the mean for the nurturing experimenter is 36.5 as compared to 46.5 for the exploitive one. In the extreme right column you’ll find that the mean for the control subjects is 30, as compared to 53 for the at-risk subjects. Two-Way Interactions in Three-Way ANOVAs Further complicating the three-way ANOVA is that, in addition to the threeway interaction and the three main effects, there are three two-way interactions to consider. In terms of our example there are the gender by experimenter, gender by alcohol, and experimenter by alcohol interactions. We will look at the last of these first. Before graphing a two-way interaction in a three-factor design, you have to “collapse” (i.e., average) your scores over the variable that is not involved in the two-way interaction. To graph the alcohol by experimenter (A × B) interaction you need to average the men with the women for each combination of alcohol and experimenter levels (i.e., each cell of the A × B matrix). These means have also been included in Table 22.1. The graph of these cell means is shown in Figure 22.2. If you compare this overall two-way interaction with the two-way interactions for the men and women separately (see Figure 22.1), you will see that the overall interaction looks like an average of the two separate interactions; the amount of interaction seen in Figure 22.2 is midway between the amount of interaction for the men and that amount for the women. Does it make sense to average the interactions for the two genders into one overall interaction? It does if they are not very different. How different is too different? The size of the three-way interaction tells us how different these two two-way interactions are. A statistically significant three-way interaction suggests that we should be cautious in interpreting any of the two-way interactions. Just as a significant two-way interaction tells us to look carefully at, and possible test, the 691 Cohen_Chapter22.j.qxd 8/23/02 11:56 M Page 692 692 Chapter 22 • Three-Way ANOVA Figure 22.2 Average of Men and Women Graph of Cell Means in Table 22.1 after Averaging Across Gender 70 At risk 60 50 40 30 Control 20 0 Nurturing Exploitive simple main effects (rather than the overall main effects), a significant threeway interaction suggests that we focus on the simple interaction effects—the two-way interactions at each level of the third variable (which of the three independent variables is treated as the “third” variable is a matter of convenience). Even if the three-way interaction falls somewhat short of significance, I would recommend caution in interpreting the two-way interactions and the main effects, as well, whenever the simple interaction effects look completely different and, perhaps, show opposite patterns. So far I have been focusing on the two-way interaction of alcohol and experimenter in our example, but this choice is somewhat arbitrary. The two genders are populations that we are likely to have theories about, so it is often meaningful to compare them. However, I can just as easily graph the three-way interaction using “alcohol” as the third factor, as I have done in Figure 22.3a. To graph the overall two-way interaction of gender and experimenter, you can go back to Table 22.1 and average across the alcohol factor. For instance, the mean for men in the nurturing condition is found by averaging the mean for control group men in the nurturing condition (40) with Figure 22.3a Graph of Cell Means in Table 22.1 Using the “Alcohol” Factor to Distinguish the Panels At Risk Control Women 80 80 70 70 60 60 50 50 40 40 Men 30 Men 30 20 Women 20 0 Nurturing Exploitive 0 Nurturing Exploitive Cohen_Chapter22.j.qxd 8/23/02 11:56 M Page 693 Section A • Conceptual Foundation 693 Figure 22.3b Average of Control and at Risk Graph of Cell Means in Table 22.1 after Averaging Across the “Alcohol” Factor 70 60 Women 50 40 Men 30 20 0 Nurturing Exploitive the mean for at-risk men in the nurturing condition (36), which is 38. The overall two-way interaction of gender and experimenter is shown in Figure 22.3b. Note that once again the two-way interaction is a compromise. (Actually, the two two-way interactions are not as different as they look; in both cases the slope of the line for the women is more positive—or at least less negative). For completeness, I have graphed the three-way interaction using experimenter as the third variable, and the overall two-way interaction of gender and alcohol in Figures 22.4a and 22.4b. An Example of a Disordinal Three-Way Interaction In the three-factor example I have been describing, it looks like all three main effects and all three two-way interactions, as well as the three-way interaction, could easily be statistically significant. However, it is important to note that in a balanced design all seven of these effects are independent; the seven F ratios do share the same error term (i.e., denominator), but the sizes of the numerators are entirely independent. It is quite possible to have Figure 22.4a Exploitive Nurturing Women 80 80 70 70 60 60 50 50 Women 40 Men 40 Men 30 30 20 20 0 Control At risk 0 Control At risk Graph of Cell Means in Table 22.1 Using the “Experimenter” Factor to Distinguish the Panels Cohen_Chapter22.j.qxd 8/23/02 11:56 M Page 694 694 Chapter 22 • Three-Way ANOVA Figure 22.4b Average of Nurturing and Exploitive Graph of Cell Means in Table 22.1 after Averaging Across the “Experimenter” Factor 70 Women 60 50 Men 40 30 20 0 Control At risk a large three-way interaction while all of the other effects are quite small. By changing the means only for the men in our example, I will illustrate a large, disordinal interaction that obliterates two of the two-way interactions and two of the main effects. You can see in Figure 22.5a that this new three-way interaction is caused by a reversal of the alcohol by experimenter interaction from one gender to the other. In Figure 22.5b, you can see that the overall interaction of alcohol by gender is now zero (the lines are parallel); the gender by experimenter interaction is also zero (not shown). On the other hand, the large gender by alcohol interaction very nearly obliterates the main effects of both gender and alcohol (see Figure 22.5c). The main effect of experimenter is, however, large, as can be seen in Figure 22.5b. An Example in which the Three-Way Interaction Equals Zero Finally, I will change the means for the men once more to create an example in which the three-way interaction is zero, even though the graphs for the Women Figure 22.5a Rearranging the Cell Means of Table 22.1 to Depict a Disordinal 3-Way Interaction Men At risk 80 80 70 70 60 60 50 50 40 40 30 Control 30 Control 20 0 20 Nurturing Expoitive 0 At risk Nurturing Expoitive Cohen_Chapter22.j.qxd 8/23/02 11:56 M Page 695 Section A • Conceptual Foundation Average of men and women 695 Figure 22.5b Regraphing Figure 22.5a after Averaging Across Gender 70 60 At risk 50 Control 40 30 20 0 Nurturing Exploitive Average of Nurturing and Exploitive 70 Women 60 Men 50 40 30 20 0 Control At risk two genders do not look the same. In Figure 22.6, I created the means for the men by starting out with the women’s means and subtracting 10 from each (this creates a main effect of gender); then I added 30 only to the men’s means that involved the nurturing condition. The latter change creates a two-way interaction between experimenter and gender, but because it affects both the men/nurturing means equally, it does not produce any threeway interaction. One way to see that the three-way interaction is zero in Figure 22.6 is to subtract the slopes of the two lines for each gender. For the women the slope of the at-risk line is positive: 88 − 40 = 48. The slope of the control line is negative: 22 − 30 = −8. The difference of the slopes is 48 − (−8) = 56. If we do the same for the men, we get slopes of 18 and −38, whose difference is also 56. You may recall that a 2 × 2 interaction has only one df, and can be summarized by a single number, L, that forms the basis of a simple linear contrast. The same is true for a 2 × 2 × 2 interaction or any higher-order interaction in which all of the factors have two levels. Of course, quantifying a three-way interaction gets considerably more complicated when the factors have more than two levels, but it is safe to say that if the two (or more) graphs are exactly the same, there will be no three-way interaction (they will continue to be identical, even if a different factor is chosen to distinguish the Figure 22.5c Regraphing Figure 22.5a after Averaging Across the “Experimenter” Factor Cohen_Chapter22.j.qxd 8/23/02 11:56 M Page 696 696 Chapter 22 • Three-Way ANOVA Figure 22.6 Rearranging the Cell Means of Table 22.1 to Depict a Zero Amount of Three-Way Interaction Women Men At risk 80 80 70 70 60 60 50 50 40 40 At risk 30 30 Control 20 20 Control 0 Nurturing Expoitive 0 Nurturing Expoitive graphs). Bear in mind, however, that even if the graphs do not look the same, the three-way interaction will be zero if the amount of two-way interaction is the same for every graph. Calculating the Three-Way ANOVA Calculating a three-way independent-groups ANOVA is a simple extension of the method for a two-way independent-groups ANOVA, using the same basic formulas. In particular, there is really nothing new about calculating MSW (the error term for all the F ratios); it is just the ordinary average of the cell variances when the design is balanced. (It is hard to imagine that anyone would calculate an unbalanced three-way ANOVA with a calculator rather than a computer, so I will not consider that possibility. The analysis of unbalanced designs is described in general in Chapter 18, Section A). Rather than give you all of the cell standard deviations or variances for the example in Table 22.1, I’ll just tell you that SSW equals 6,400; later I’ll divide this by dfW to obtain MSW. (If you had all of the raw scores, you would also have the option of obtaining SSW by calculating SStotal and subtracting SSbetween-cells as defined in the following.) Main Effects The calculation of the main effects is also the same as in the two-way ANOVA; the SS for a main effect is just the biased variance of the relevant group means multiplied by the total N. Let us say that each of the eight cells in our example contains five subjects, so NT equals 40. Then the SS for the experimenter factor (SSexper) is 40 times the biased variance of 36.5 and 46.5 (the nurturing and exploitive means from Table 22.1), which equals 40(25) = 1000 (the shortcut for finding the biased variance of two numbers is to take the square of the difference between them and then divide by 4). Similarly, SSalcohol = 40(132.25) = 5290, and SSgender = 40(12.25) = 490. The Two-Way Interactions When calculating the two-way ANOVA, the SS for the two-way interaction is found by subtraction; it is the amount of the SSbetween-cells that is left after sub- Cohen_Chapter22.j.qxd 8/23/02 11:56 M Page 697 Section A • Conceptual Foundation tracting the SSs for the main effects. Similarly, the three-way interaction SS is the amount left over after subtracting the SSs for the main effects and the SSs for all the two-way interactions from the overall SSbetween-cells. However, finding the SSs for the two-way interactions in a three-way design gets a little tricky. In addition to the overall SSbetween-cells, we must also calculate some intermediate “two-way” SSbetween terms. To keep track of these I will have to introduce some new subscripts. The overall SSbetween-cells is based on the variance of all the cell means, so no factors are “collapsed,” or averaged over. Representing gender as G, alcohol as A, and experimenter as E, the overall SSbetween-cells will be written as SSGAE. We will also need to calculate an SSbetween after averaging over gender. This is based on the four means (included in Table 22.1) I used to graph the alcohol by experimenter interaction and will be represented by SSAE. Because the design is balanced, you can take the simple average of the appropriate male cell mean and female cell mean in each case. Note that SSAE is not the SS for the alcohol by experimenter interaction because it also includes the main effects of those two factors. In similar fashion, we need to find SSGA from the means you get after averaging over the experimenter factor and SSGE by averaging over the alcohol factor. Once we have calculated these four SSbetween terms, all of the SSs we need for the three-way ANOVA can be found by subtraction. Let’s begin with the calculation of SSGAE; the biased variance of the eight cell means is 366.75, so SSGAE = 40(366.75) = 14,670. The means for SSAE are 35, 25, 38, 68, and their biased variance equals 257.75, so SSAE = 10,290. SSGA is based on the following means: 34, 26, 42, 64, so SSGA = 40(200.75) = 8,030. Finally, SSGE, based on means of 38, 38, 35, 55, equals 2,490. Next we find the SSs for each two-way interaction: SSA × E = SSAE − SSalcohol − SSexper = 10,290 − 5,290 − 1,000 = 4,000 SSG × A = SSGA − SSgender − SSalcohol = 8,030 − 490 − 5,290 = 2,250 SSG × E = SSGE − SSgender − SSexper = 2,490 − 490 − 1,000 = 1,000 Finally, the SS for the three-way interaction (SSG × A × E) equals SSGAE − SSA × E − SSG × A − SSG × E − SSgender − SSalcohol − SSexper = 14,670 − 4,000 − 2,250 − 1,000 − 490 − 5,290 − 1,000 = 640 Formulas for the General Case It is traditional to assign the letters A, B, and, C to the three independent variables in the general case; variables D, E, and so forth, can then be added to represent a four-way, five-way, or higher ANOVA. I’ll assume that the following components have already been calculated using Formula 14.3 applied to the appropriate means: SSA, SSB, SSC, SSAB, SSAC, SSBC, SSABC. In addition, I’ll assume that SSW has also been calculated, either by averaging the cell variances and multiplying by dfW or by subtracting SSABC from SStotal. The remaining SS components are found by Formula 22.1: a. b. c. d. SSA × B = SSAB − SSA − SSB Formula 22.1 SSA × C = SSAC − SSA − SSC SSB × C = SSBC − SSB − SSC SSA × B × C = SSABC − SSA × B − SSB × C − SSA × C − SSA − SSB − SSC At the end of the analysis, SStotal (whether or not it has been calculated separately) has been divided into eight components: SSA, SSB, SSC, the four interactions listed in Formula 22.1, and SSW. Each of these is divided by its corresponding df to form a variance estimate, MS. Using a to represent the 697 Cohen_Chapter22.j.qxd 8/23/02 11:56 M Page 698 698 Chapter 22 • Three-Way ANOVA number of levels of the A factor, b for the B factor, c for the C factor, and n for the number of subjects in each cell, the formulas for the df components are as follows: a. b. c. d. e. f. g. h. dfA = a − 1 dfB = b − 1 dfC = c − 1 dfA × B = (a − 1)(b − 1) dfA × C = (a − 1)(c − 1) dfB × C = (b − 1)(c − 1) dfA × B × C = (a − 1)(b − 1)(c − 1) dfW = abc (n − 1) Formula 22.2 Completing the Analysis for the Example Because each factor in the example has only two levels, all of the numerator df’s are equal to 1, which means that all of the MS terms are equal to their corresponding SS terms—except, of course, for the error term. The df for the error term (i.e., dfW) equals the number of cells (abc) times one less than the number of subjects per cell (this gives the same value as NT minus the number of cells); in this case dfW = 8(4) = 32. MSW = SSW/dfW; therefore, MSW = 6400/32 = 200. (Reminder: I gave the value of SSW to you to reduce the amount of calculation.) Now we can complete the three-way ANOVA by calculating all of the possible F ratios and testing each for statistical significance: MSgender 490 Fgender = = = 2.45 MSW 200 MSalcohol 5,290 Falcohol = = = 26.45 MSW 200 MSexper 1,000 Fexper = = = 5 MSW 200 MSA × E 4,000 FA × E = = = 20 MSW 200 MSG × A 2,250 FG × A = = = 11.35 MSW 200 MSG × E 1000 FG × E = = = 5 MSW 200 MSG × A × E 640 FG × A × E = = = 3.2 MSW 200 Because the df happens to be 1 for all of the numerator terms, the critical F for all seven tests is F.05 (1,32), which is equal (approximately) to 4.15. Except for the main effect of gender, and the three-way interaction, all of the F ratios exceed the critical value (4.15) and are therefore significant at the .05 level. Follow-Up Tests for the Three-Way ANOVA Decisions concerning follow-up comparisons for a factorial ANOVA are made in a top-down fashion. First, one checks the highest-order interaction Cohen_Chapter22.j.qxd 8/23/02 11:56 M Page 699 Section A • Conceptual Foundation for significance; in a three-way ANOVA it is the three-way interaction. (Twoway interactions are the simplest possible interactions and are called firstorder interactions; three-way interactions are known as second-order interactions, etc.) If the highest interaction is significant, the post hoc tests focus on the various simple effects or interaction contrasts, followed by appropriate cell-to-cell comparisons. In a three-way ANOVA in which the three-way interaction is not significant, as in the present example, attention turns to the three two-way interactions. Although all of the two-way interactions are significant in our example, the alcohol by experimenter interaction is the easiest to interpret because it replicates previous results. It would be appropriate to follow up the significant alcohol by experimenter interaction with four t tests (e.g., one of the relevant t tests would determine whether at-risk subjects differ significantly from controls in the exploitive condition). Given the disordinal nature of the interaction (see Figure 22.2), it is likely that the main effects would simply be ignored. A similar approach would be taken to the two other significant two-way interactions. Thus, all three main effects would be regarded with caution. Note that because all of the factors are dichotomous, there would be no follow-up tests to perform on significant main effects, even if none of the interactions were significant. With more than two levels for some or all of the factors, it becomes possible to test partial interactions, and significant main effects for factors not involved in significant interactions can be followed by pairwise or complex comparisons, as described in Chapter 14, Section C. I will illustrate some of the complex planned and post hoc comparisons for the threeway design in Section B. Types of Three-Way Designs Cases involving significant three-way interactions and factors with more than two levels will be considered in the context of mixed designs in Section B. However, before we turn to mixed designs, let us look at some of the typical situations in which three-way designs with no repeated measures arise. One situation involves three experimental manipulations for which repeated measures are not feasible. For instance, subjects perform a repetitive task in one of two conditions: They are told that their performance is being measured or that it is not. In each condition half of the subjects are told that performance on the task is related to intelligence, and the other half are told that it is not. Finally, within each of the four groups just described, half the subjects are treated respectfully and half are treated rudely. The work output of each subject can then be analyzed by a 2 × 2 × 2 ANOVA. Another possibility involves three grouping variables, each of which involves selecting subjects whose group is already determined. For instance, a group of people who exercise regularly and an equal-sized group of those who don’t are divided into those high and those relatively low on self-esteem (by a median split). If there are equal numbers of men and women in each of the four cells, we have a balanced 2 × 2 × 2 design. More commonly one or two of the variables involve experimental manipulations and two or one involve grouping variables. The example calculated earlier in this section involved two grouping variables (gender and having an alcohol-dependent parent or not) and one experimental variable (nurturing vs. exploitive experimenter). To devise an interesting example with two experimental manipulations and one grouping variable, start with two experimental factors that are expected to interact (e.g., one factor is whether or not the subjects are told that performance on the experimental task is related to intelligence, and the other factor is whether or not the group of subjects run together will know 699 Cohen_Chapter22.j.qxd 8/23/02 11:56 M Page 700 Chapter 22 • Three-Way ANOVA 700 each other’s final scores). Then, add a grouping variable by comparing subjects who are either high or low on self-esteem, need for achievement, or some other relevant aspect of personality. If the two-way interaction differs significantly between the two groups of subjects, the three-way interaction will be significant. The Two-Way RM ANOVA One added benefit of learning how to calculate a three-way ANOVA is that you now know how to calculate a two-way ANOVA in which both factors involve repeated measures. In Chapter 15, I showed you that the SS components of a one-way RM design are calculated as though the design were a two-way independent-groups ANOVA with no within-cell variability. Similarly, a two-way RM ANOVA is calculated just as shown in the preceding for the three-way independent-groups ANOVA, with the following modifications: (1) One of the three factors is the subjects factor—each subject represents a different level of the subjects factor, (2) the main effect of subjects is not tested, and there is no MSW error term, (3) each of the two main effects that is tested uses the interaction of that factor with the subjects factor as the error term, and (4) the interaction of the two factors of interest is tested by using as the error term the interaction of all three factors (i.e., including the subjects factor). If one RM factor is labeled Q and the other factor, R, and we use S to represent the subjects factor, the equations for the three F ratios can be written as follows: MSQ FQ = , MSQ × S MSR FR = MSR × S MSQ × R FQ × R = MXQ × R × S Higher-Order ANOVA This text will not cover factorial designs of higher order than the three-way ANOVA. Although higher-order ANOVAs can be difficult to interpret, no new principles are introduced. The four-way ANOVA produces 15 different F ratios to test: four main effects, 6 two-way interactions, 4 three-way interactions, and 1 four-way interaction. Testing each of these 15 effects at the .05 level raises serious concerns about the increased risk of Type I errors. Usually, all of the F ratios are not tested; specific hypotheses should guide the selection of particular effects to test. Of course, the potential for an inflated rate of Type I errors only increases as factors are added. In general, an N-way ANOVA produces 2N − 1 F ratios that can be tested for significance. In the next section I will delve into more complex varieties of the threeway ANOVA—in particular those that include repeated measures on one or two of the factors. A SUMMARY 1. To display the cell means of a three-way factorial design, it is convenient to create two-way graphs for each level of the third variable and place these graphs side by side (you have to decide which of the three variables will distinguish the graphs and which of the two remaining variables will be placed along the X axis of each graph). Each two-way graph depicts a simple interaction effect; if the simple interaction effects are significantly different from each other, the three-way interaction will be significant. 2. Three-way interactions can occur in a variety of ways. The interaction of two of the factors can be strong at one level of the third factor and close Cohen_Chapter22.j.qxd 8/23/02 11:56 M Page 701 Section A • Conceptual Foundation 3. 4. 5. 6. 7. 8. 701 to zero at a different level (or even stronger at a different level). The direction of the two-way interaction can reverse from one level of the third variable to another. Also, a three-way interaction can arise when all of the cell means are similar except for one. The main effects of the three-way ANOVA are based on the means at each level of one of the factors, averaging across the other two. A twoway interaction is the average of the separate two-way interactions (simple interaction effects) at each level of the third factor. A two-way interaction is based on a two-way table of means created by averaging across the third factor. The error term for the three-way ANOVA, MSW, is a simple extension of the error term for a two-way ANOVA; in a balanced design, it is the simple average of all of the cell variances. All of the SSbetween components are found by Formula 14.3, or by subtraction using Formula 22.1. There are seven F ratios that can be tested for significance: the three main effects, three two-way interactions, and the three-way interaction. Averaging simple interaction effects together to create a two-way interaction is reasonable only if these effects do not differ significantly. If they do differ, follow-up tests usually focus on the simple interaction effects themselves or particular 2 × 2 interaction contrasts. If the threeway interaction is not significant, but a two-way interaction is, the significant two-way interaction is explored as in a two-way ANOVA—with simple main effects or interaction contrasts. Also, when the three-way interaction is not significant, any significant main effect can be followed up in the usual way if that variable is not involved in a significant twoway interaction. All three factors in a three-way ANOVA can be grouping variables (i.e., based on intact groups), but this is rare. It is more common to have just one grouping variable and compare the interaction of two experimental factors among various subgroups of the population. Of course, all three factors can involve experimental manipulations. The two-way ANOVA in which both factors involve repeated measures is analyzed as a three-way ANOVA, with the different subjects serving as the levels of the third factor. The error term for each RM factor is the interaction of that factor with the subject factor; the error term for the interaction of the two RM factors is the three-way interaction. In an N-way factorial ANOVA, there are 2N − 1 F ratios that can be tested. The two-way interaction is called a first-order interaction, the three-way is a second-order interaction, and so forth. EXERCISES 1. Imagine an experiment in which each subject is required to use his or her memories to create one emotion: either happiness, sadness, anger, or fear. Within each emotion group, half of the subjects participate in a relaxation exercise just before the emotion condition, and half do not. Finally, half the subjects in each emotion/relaxation condition are run in a dark, sound-proof chamber, and the other half are run in a normally lit room. The dependent variable is the subject’s systolic blood pressure when the subject signals that the emotion is fully present. The design is balanced, with a total of 128 subjects. The results of the three-way ANOVA for this hypothetical experiment are as follows: SSemotion = 223.1, SSrelax = 64.4, SSdark = 31.6, SSemo × rel = 167.3, SSemo × dark = 51.5; SSrel × dark = 127.3, and SSemo × rel × dark = 77.2. The total sum of squares is 2,344. a. Calculate the seven F ratios, and test each for significance. Cohen_Chapter22.j.qxd 8/23/02 11:56 M Page 702 Chapter 22 • Three-Way ANOVA 702 b. Calculate partial eta squared for each of the three main effects (use Formula 14.9). Are any of these effects at least moderate in size? 2. In this exercise there are 20 subjects in each cell of a 3 × 3 × 2 design. The levels of the first factor (location) are urban, suburban, and rural. The levels of the second factor are no siblings, one or two siblings, and more than two siblings. The third factor has only two levels: presently married and not presently married. The dependent variable is the number of close friends that each subject reports having. The cell means are as follows: No Siblings Married Not Married 1 or 2 Siblings Married Not Married 2 or more Siblings Married Not Married Urban Suburban Rural 1.9 4.7 3.1 5.7 2.0 3.5 2.3 4.5 3.0 5.3 3.3 4.6 3.2 3.9 4.5 6.2 2.9 4.6 a. Given that SSW equals 1,094, complete the three-way ANOVA, and present your results in a summary table. b. Draw a graph of the means for Location × Number of Siblings (averaging across marital status). Describe the nature of the interaction. c. Using the means from part b, test the simple effect of number of siblings at each location. 3. Seventy-two patients with agoraphobia are randomly assigned to one of four drug conditions: SSRI (e.g., Prozac), tricyclic antidepressant (e.g., Elavil), antianxiety (e.g., Xanax), or a placebo (offered as a new drug for agoraphobia). Within each drug condition, a third of the patients are randomly assigned to each of three types of psychotherapy: psychodynamic, cognitive/behavioral, and group. The subjects are assigned so that half the subjects in each drug/therapy group are also depressed, and half are not. After 6 months of treatment, the severity of agoraphobia is measured for each subject (30 is the maximum possible phobia score); the cell means (n = 3) are as follows: a. Given that SSW equals 131, complete the three-way ANOVA, and present your results in a summary table. SSRI Tricyclic Antianxiety Placebo Psychodynamic Not Depressed 10 Depressed 8.7 Cog/Behav Not Depressed 9.5 Depressed 10.3 Group Not Depressed 11.6 Depressed 9.7 11.5 8.7 19.0 14.5 22.0 19.0 11.0 14.0 12.0 10.0 17.0 16.5 12.6 12.0 19.3 17.0 13.0 11.0 b. Draw a graph of the cell means, with separate panels for depressed and not depressed. Describe the nature of the therapy × drug interaction in each panel. Does there appear to be a three-way interaction? Explain. c. Given your results in part a, describe a set of follow-up tests that would be justifiable. d. Optional: Test the 2 × 2 × 2 interaction contrast that results from deleting Group therapy and the SSRI and placebo conditions from the analysis (extend the techniques of Chapter 13, Section B, and Chapter 14, Section C). 4. An industrial psychologist is studying the relation between motivation and productivity. Subjects are told to perform as many repetitions of a given clerical task as they can in a 1-hour period. The dependent variable is the number of tasks correctly performed. Sixteen subjects participated in the experiment for credit toward a requirement of their introductory psychology course (credit group). Another 16 subjects were recruited from other classes and paid $10 for the hour (money group). All subjects performed a small set of similar clerical tasks as practice before the main study; in each group (credit or money) half the subjects (selected randomly) were told they had performed unusually well on the practice trials (positive feedback), and half were told they had performed poorly (negative feedback). Finally, within each of the four groups created by the manipulations just described, half of the subjects (at random) were told that performing the tasks quickly and accurately was correlated with other important job skills (self motivation), whereas the other half were told that good performance would help the experiment (other motivation). The data appear in the following table: Cohen_Chapter22.j.qxd 8/23/02 11:56 M Page 703 Section B • Basic Statistical Procedures CREDIT SUBJECTS PAID SUBJECTS Positive Feedback Negative Feedback Positive Feedback Negative Feedback Self 22 25 26 30 12 15 12 10 21 17 15 21 25 23 30 26 Other 11 18 12 14 20 23 21 26 33 29 35 29 21 22 19 17 a. Perform a three-way ANOVA on the data. Test all seven F ratios for significance, and present your results in a summary table. b. Use graphs of the cell means to help you describe the pattern underlying each effect that was significant in part a. c. Based on the results in part a, what post hoc tests would be justified? 5. Imagine that subjects are matched in blocks of three based on height, weight, and other physical characteristics; six blocks are formed in this way. Then the subjects in each block are randomly assigned to three differSAD 703 ent weight-loss programs. Subjects are measured before the diet, at the end of the diet program, 3 months later, and 6 months later. The results of the two-way RM ANOVA for this hypothetical experiment are given in terms of the SS components, as follows: SSdiet = 403.1, SStime = 316.8, SSdiet × time = 52, SSdiet × S = 295.7, SStime × S = 174.1, and SSdiet × time × S = 230. a. Calculate the three F ratios, and test each for significance. b. Find the conservatively adjusted critical F for each test. Will any of your conclusions be affected if you do not assume that sphericity exists in the population? 6. A psychologist wants to know how both the affective valence (happy vs. sad vs. neutral) and the imageability (low, medium, high) of words affect their recall. A list of 90 words is prepared with 10 words from each combination of factors (e.g., happy, low imagery: promotion; sad, high imagery: cemetery) randomly mixed together. The number of words recalled in each category by each of the six subjects in the study is given in the following table: NEUTRAL HAPPY Subject No. Low Medium High Low Medium High Low Medium High 1 2 3 4 5 6 5 2 5 3 4 3 6 5 7 6 9 5 9 7 5 5 8 7 2 3 2 3 4 4 5 6 4 5 7 5 6 6 5 6 7 6 3 5 4 4 4 6 4 5 3 4 5 4 8 6 7 5 9 4 a. Perform a two-way RM ANOVA on the data. Test the three F ratios for significance, and present your results in a summary table. b. Find the conservatively adjusted critical F for each test. Will any of your conclusions be affected if you do not assume that sphericity exists in the population? c. Draw a graph of the cell means, and describe any trend toward an interaction that you can see. d. Based on the variables in this exercise, and the results in part a, what post hoc tests would be justified and meaningful? An important way in which one three-factor design can differ from another is the number of factors that involve repeated measures (or matching). The design in which none of the factors involve repeated measures was covered in Section A. The design in which all three factors are RM factors will not be covered in this text; however, the three-way RM design is a straightforward extension of the two-way RM design described at the end of Section A. This section will focus on three-way designs with either one or two RM factors (i.e., mixed designs), and it will also elaborate on the general principles of dealing with three-way ANOVAs, as introduced in Section A, and consider B BASIC STATISTICAL PROCEDIRES Cohen_Chapter22.j.qxd 8/23/02 11:56 M Page 704 704 Chapter 22 • Three-Way ANOVA the complexities of interactions and post hoc tests when the factors have more than two levels each. One RM Factor I will begin with a three-factor design in which there are repeated measures on only one of the factors. The ANOVA for this design is not much more complicated than the two-way mixed ANOVA described in the previous chapter—for instance, there are only two different error terms. Such designs arise frequently in psychological research. One simple way to arrive at such a design is to start with a two-way ANOVA with no repeated measures. For instance, patients with two different types of anxiety disorders (generalized anxiety vs. specific phobias) are treated with two different forms of psychotherapy (psychodynamic vs. behavioral). The third factor is added by measuring the patients’ anxiety at several points in time (e.g., beginning of therapy, end of therapy, several months after therapy has stopped); I will refer to this factor simply as time. To illustrate the analysis of this type of design I will take the two-way ANOVA from Section B of Chapter 14 and add time as an RM factor. You may recall that that example involved four levels of sleep deprivation and three levels of stimulation. Performance was measured only once—after 4 days in the sleep lab. Now imagine that performance on the simulated truck driving task is measured three times: after 2, 4, and 6 days in the sleep lab. The raw data for the three-factor study are given in Table 22.2, along with the various means we will need to graph and analyze the results; note that the data for Day 4 are identical to the data for the corresponding two-way ANOVA in Chapter 14. To see what we may expect from the results of a threeway ANOVA on these data, the cell means have been graphed so that we can look at the sleep by stimulation interaction at each time period (see Figure 22.7). You can see from Figure 22.7 that the sleep × stimulation interaction, which was not quite significant for Day 4 alone (see Chapter 14, section B), increases over time, perhaps enough so as to produce a three-way interaction. We can also see that the main effects of stimulation and sleep, significant at Day 4, are likely to be significant in the three-way analysis. The general decrease in scores from Day 2 to Day 4 to Day 6 is also likely to yield a significant main effect for time. Without regraphing the data, it is hard to see whether the interactions of time with either sleep or stimulation are large or small. However, because these interactions are less interesting in the context of this experiment, I won’t bother to present the two other possible sets of graphs. To present general formulas for analyzing the kind of experiment shown in Table 22.2, I will adopt the following notation. The two between-subject factors will be labeled A and B. Of course, it is arbitrary which factor is called A and which B; in this example the sleep deprivation factor will be A, and the stimulation factor will be B. The lowercase letters a and b will stand for the number of levels of their corresponding factors—in this case, 4 and 3, respectively. The within-subject factor will be labeled R, and its number of levels, c, to be consistent with previous chapters. Let us begin with the simplest SS components: SStotal, and the SSs for the numerators of each main effect. SStotal is based on the total number of observations, NT, which for any balanced three-way factorial ANOVA is equal to abcn, where n is the number of different subjects in each cell of the A × B table. So, NT = 4 3 3 5 = 180. The biased variance obtained by entering all 180 scores is 43.1569, so SStotal = 43.1569 180 = 7,768.24. SSA is based AB means Column means Total AB means Interrupt AB means Jet Lag AB means None Day 4 24 29 28 20 20 24.2 22 18 16 25 27 21.6 16 19 20 11 14 16.0 14 17 18 12 10 14.2 19.0 Day 2 26 30 29 23 21 25.8 24 20 15 27 28 22.8 17 19 22 11 15 16.8 16 18 20 14 11 15.8 20.3 5 6 10 7 7 7.0 14.0 9 6 11 7 10 8.6 17 15 13 19 22 17.2 24 25 27 20 20 23.2 Day 6 PLACEBO 11.67 13.67 16.0 11.0 9.33 12.33 17.77 14.0 14.67 17.67 9.67 13.0 13.8 21 17.67 14.67 23.67 25.67 20.53 24.67 28.0 28.0 21.0 20.33 24.4 Subject Means 24 19 20 27 26 23.2 25.5 25 21 19 25 24 22.8 27 29 34 23 25 27.6 29 26 23 29 35 28.4 Day 2 15 11 11 19 17 14.6 21.0 16 13 12 18 19 15.6 26 30 32 20 23 26.2 28 23 24 30 33 27.6 Day 4 14 8 15 17 10 12.8 17.65 10 9 8 12 14 10.6 33 17 25 18 20 22.6 26 23 25 27 22 24.6 Day 6 MOTIVATION Table 22.2 17.67 12.67 15.33 21.0 17.67 16.87 21.38 17.0 14.33 13.0 18.33 19.0 16.33 28.67 25.33 30.33 20.33 22.67 25.46 27.67 24.0 24.0 28.67 30.0 26.87 Subject Means 25 16 19 27 26 22.6 25.1 23 29 28 20 21 24.2 24 30 30 25 23 26.4 29 24 23 31 29 27.2 Day 2 23 16 18 26 24 21.4 23.65 23 28 26 17 19 22.6 25 27 31 24 21 25.6 26 22 20 30 27 25.0 Day 4 18 14 12 21 21 17.2 20.5 20 23 23 12 17 19.0 20 24 25 17 22 21.6 26 23 17 30 25 24.2 Day 6 CAFFEINE 22.0 15.33 16.33 24.67 23.67 20.4 23.08 22.0 26.67 25.67 16.33 19.0 21.93 23 27.0 28.67 22.0 22.0 24.53 27.0 23.0 20.0 30.33 27.0 25.47 16.53 17.35 23.51 25.58 Subject Row Means Means Cohen_Chapter22.j.qxd 8/23/02 11:56 M Page 705 Cohen_Chapter22.j.qxd 8/23/02 11:56 M Page 706 706 Chapter 22 • Three-Way ANOVA Figure 22.7 30 Graph of the Cell Means in Table 22.2 25 Motivation 20 Caffeine 15 Placebo Day 2 10 7 0 None Jet-Lag Interrupt Total 30 25 Caffeine 20 Day 4 Motivation 15 Placebo 10 7 0 None Jet-Lag Interrupt Total 30 25 20 Caffeine 15 Motivation 10 7 Placebo 0 None Jet-Lag Interrupt Day 6 Total on the means for the four sleep deprivation levels, which can be found in the rightmost column of the table, labeled “row means.” SSB is based on the means for the three stimulation levels, which are found where the bottom row of the table (Column Means), intersects the columns labeled “Subject Means” (these are averaged over the three days, as well as the sleep levels). The means for the three different days are not in the table but can be found by averaging the three Column Means for Day 2, the three for Day 4, and similarly for Day 6. The SSs for the main effects are as follows: SSA = σ2(25.58, 23.51, 17.35, 16.53) 180 = 15.08 180 = 2,714.4. SSB = σ2(17.77, 21.38, 23.08) 180 = 4.902 180 = 882.36. SSR = σ2(23.63, 21.22, 17.38) = 6.622 180 = 1,192.0 As in Section A, we will need the SS based on the cell means, SSABR, and the SSs for each two-way table of means: SSAB, SSAR, and SSBR. In addition, because one factor has repeated measures we will also need to find the means for each subject (averaging their scores for Day 2, Day 4, and Day 6) and the SS based on those means, SSbetween-subjects. Cohen_Chapter22.j.qxd 8/23/02 11:56 M Page 707 Section B • Basic Statistical Procedures The cell means we need for SSABR are given in Table 22.2, under Day 2, Day 4, and Day 6, in each of the rows labeled AB Means; there are 36 of them (a b c). The biased variance of these cell means is 30.746, so SSABR = 30.746 180 = 5,534.28. The means for SSAB are found by averaging across the 3 days for each combination of sleep and stimulation levels and are found in the rows for AB Means under “Subject Means.” The biased variance of these 12 (i.e., a b) means equals 22.078, so SSAB = 3,974. The nine means for SSBR are the column means of Table 22.2, except for the columns labeled “Subject Means.” SSBR = σ2(20.3, 19.0, 14.0, 25.5, 21.0, 17.65, 25.1, 23.65, 20.5) 180 = 2,169.14. Unfortunately, there was no convenient place in Table 22.2 to put the means for SSAR. They are found by averaging the (AB) means for each day and level of sleep deprivation over the three stimulation levels. SSAR = σ2(27.13, 25.6, 24, 25.6, 24.47, 20.47, 21.27, 18.07, 12.73, 20.53, 16.73, 12.33) 180 = 4,066.6. Finally, we need to calculate SSbetween-subjects for the 60 (a b n) subject means found in Table 22.2 under “Subject Means” (ignoring the entries in the rows labeled AB Means and Column Means, of course). SSbetween-subjects = 32.22 180 = 5,799.6. Now we can get the rest of the SS components we need by subtraction. The SSs for the two-way interactions are found just as in Section A from Formula 22.1a, b, and c (except that factor C has been changed to R): SSA × B = SSAB − SSA − SSB SSA × R = SSAR − SSA − SSR SSB × R = SSBR − SSB − SSR Plugging in the SSs for the present example, we get SSA × B = 3,974 − 2,714.4 − 882.4 = 377.2 SSA × R = 4,066.6 − 2,714.4 − 1,192 = 160.2 SSB × R = 2,169.14 − 882.4 − 1,192 = 94.74 The three-way interaction is found by subtracting from SSABR the SSs for three two-way interactions and the three main effects (Formula 22.1d). SSA × B × R = SSABR − SSA × B − SSA × R − SSB × R − SSA − SSB − SSR SSA × B × R = 5,534.28 − 377.2 − 160.2 − 94.74 − 2,714.4 − 882.4 − 1192 = 113.34 As in the two-way mixed design there are two different error terms. One of the error terms involves subject-to-subject variability within each group— or, in the case of the present design, within each cell formed by the two between-group factors. This is the error component you have come to know as SSW, and I will continue to call it that. The total variability from one subject to another (averaging across the RM factor) is represented by a term we have already calculated: SSbetween-subjects, or SSbet-s, for short. In the one-way RM ANOVA this source of variability was called the “subjects” factor (SSsub), or the main effect of “subjects,” and because it did not play a useful role, we ignored it. In the mixed design of the previous chapter it was simply divided between SSgroups and SSW. Now that we have two between-group factors, that source of variability can be divided into four components, as follows: SSbet-s = SSA + SSB + SSA × B + SSW This relation can be expressed more simply as SSbet-s = SSAB + SSW The error portion, SSW, is found most easily by subtraction: SSW = SSbet-S − SSAB Formula 22.3 707 Cohen_Chapter22.j.qxd 8/23/02 11:56 M Page 708 708 Chapter 22 • Three-Way ANOVA This SS is the basis of the error term that is used for all three of the betweengroup effects. The other error term involves the variability within subjects. The total variability within subjects, represented by SSwithin-subjects, or SSW-S, for short, can be found by taking the total SS and subtracting the betweensubject variability: SSW-S = SStotal − SSbet-S Formula 22.4 The within-subject variability can be divided into five components, which include the main effect of the RM factor and all of its interactions: SSW-S = SSR + SSA × R + SSB × R + SSA × B × R + SSS × R The last term is the basis for the error term that is used for all of the effects involving the RM factor (it was called SSS × RM in Chapter 16). It is found conveniently by subtraction: SSS × R = SSW-S − SSR − SSA × R − SSB × R − SSA × B × R Formula 22.5 We are now ready to get the remaining SS components for our example. SSW = SSbet-S − SSAB = 5,799.6 − 3,974 = 1,825.6 SSW-S = SStotal − SSbet-S = 7,768.24 − 5,799.6 = 1,968.64 SSS × R = SSW-S − SSR − SSA × R − SSB × R − SSA × B × R = 1,968.64 − 1,192 − 160.2 − 94.74 − 113.34 = 408.36 A more tedious but more instructive way to find SSS × R would be to find the subject by RM interaction separately for each of the eight cells of the between-groups (AB) matrix and then add these eight components together. This overall error term is justified only if you can assume that all eight interactions would be the same in the entire population. As mentioned in the previous chapter, there is a statistical test (Box’s M criterion) that can be used to give some indication of whether this assumption is reasonable. Now that we have divided SStotal into all of its components, we need to do the same for the degrees of freedom. This division, along with all of the df formulas, is shown in the degrees of freedom tree in Figure 22.8. The df’s we will need to complete the ANOVA are based on the following formula: a. b. c. d. e. f. g. h. i. dfA = a − 1 dfB = b − 1 dfA × B = (a − 1)(b − 1) dfR = c − 1 dfA × R = (a − 1)(c − 1) dfB × R = (b − 1)(c − 1) dfA × B × R = (a − 1)(b − 1)(c − 1) dfW = ab(n − 1) dfS × R = dfW dfR = ab(n − 1)(c − 1) For the present example, dfA = 4 − 1 = 3 dfB = 3 − 1 = 2 dfA × B = 3 2 = 6 dfR = 3 − 1 = 2 dfA × R = 3 2 = 6 dfB × R = 2 2 = 4 dfA × B × R = 3 2 2 = 12 dfW = 4 3 (5 − 1) = 48 dfS × R = dfW dfR = 48 2 = 96 Formula 22.6 Cohen_Chapter22.j.qxd 8/23/02 11:56 M Page 709 Section B • Basic Statistical Procedures df total [abcn–1] 709 Figure 22.8 Degrees of Freedom Tree for Three-Way ANOVA with Repeated Measures on One Factor df within-subjects [abn(c–1)] df between-subjects [abn–1] df groups [ab–1] df R [c–1] df W [ab(n–1)] df S × R [ab(n–1)(c–1)] df A × R [(a–1)(c–1)] df B × R [(b–1)(c–1)] df A × B × R [(a–1)(b–1)(c–1)] df A [a–1] df B [b–1] df A × B [(a–1)(b–1)] Note that the sum of all the df’s is 179, which equals dftotal (NT − 1 = abcn − 1 = 180 − 1). The next step is to divide each SS by its df to obtain the corresponding MS. The results of this step are shown in Table 22.3 along with the F ratios and their p values. The seven F ratios were formed according to Formula 22.7: Source SS df MS F p Between-subjects Sleep deprivation Stimulation Sleep × Stim Within-groups 5,799.6 2714.4 882.4 375.8 1825.6 59 3 2 6 48 904.8 441.2 62.63 38.03 23.8 11.6 1.65 <.001 <.001 >.05 Within-subjects Time Sleep × Time Stim × Time Sleep × Stim × Time Subject × Time 1,968.64 1192 160.2 94.74 114.74 408.36 120 2 6 4 12 96 596 26.7 23.7 9.56 4.25 140.2 6.28 5.58 2.25 <.001 <.001 <.001 <.05 Note: The errors that you get from rounding off the means before applying Formula 14.3 are compounded in a complex design. If you retain more digits after the decimal place than I did in the various group and cell means or use raw-score formulas or analyze the data by computer, your F ratios will differ by a few tenths of a point from those in Table 22.3 (fortunately, your conclusions should be the same). If you are going to present your findings to others, regardless of the purpose, I strongly recommend that you use statistical software, and in particular a program or package that is quite popular (so that there is a good chance that its bugs have already been eliminated, at least for basic procedures, such as those in this text). Table 22.3 Cohen_Chapter22.j.qxd 8/23/02 11:56 M Page 710 710 Chapter 22 • Three-Way ANOVA a. MSA FA = MSW Formula 22.7 MSB b. FB = MSW c. MSA × B FA × B = MSW d. MSR FR = MSS × R e. MSA × R FA × R = MSS × R MSB × R f. FB × R = MSS × R g. MSA × B × R FA × B × R = MSS × R Interpreting the Results Although the three-way interaction is significant, the ordering of most of the effects is consistent enough that the main effects are interpretable. The significant main effect of sleep is due to a general decline in performance across the four levels, with “no deprivation” producing the least deficit and “total deprivation” the most, as would be expected. It is also no surprise that overall performance significantly declines with increased time in the sleep lab. The significant stimulation main effect seems to be due mainly to the consistently lower performance of the placebo group rather than the fairly small difference between caffeine and reward. In Figure 22.9, I have graphed the sleep by stimulation interaction, by averaging the three panels of Figure 22.7. Although the interaction looks like it might be significant, we know from Table 22.3 that it is not. Remember that the error term for testing this interaction is based on subject-to-subject variability within each cell and does not benefit from the added power of repeated measures. The other two interactions use MSS × RM as their error term and therefore do gain the extra power usually conferred by repeated measures. Of course, even if the sleep by stimulation interaction were significant, its interpretation would be qualified by the significance of the three-way interaction. The significant three-way interaction tells us to be cautious in our interpretation of the other six F ratios and suggests that we look at simple interaction effects. There are three ways to look at simple interaction effects in a three-way ANOVA (depending on which factor is looked at one level at a time), but the most interesting two-way interaction for the present example is sleep deprivation by stimulation, so we will look at that interaction at each level of the time factor. The results have already been graphed this way in Figure 22.7. It is easy to see that the three-way interaction in this study is due to the progressive increase in the sleep by stimulation interaction over time. Cohen_Chapter22.j.qxd 8/23/02 11:56 M Page 711 Section B • Basic Statistical Procedures 30 Figure 22.9 20 Caffeine Motivation Placebo 10 5 0 711 None Jet-Lag Interrupt Total Assumptions The sphericity tests and adjustments you learned in Chapters 15 and 16 are easily extended to apply to this design as well. Box’s M criterion can be used to test that the covariances for each pair of RM levels are the same (in the population) for every combination of the two between-group factors. If M is not significant, the interactions can be pooled across all the cells of the twoway between-groups part of the design and then tested for sphericity with Mauchley’s W. If you cannot perform these tests (or do not trust them), you can use the modified univariate approach as described in Chapter 15. A factorial MANOVA is also an option (see section C). The df’s and p levels for the within-subjects effects in Table 22.3 were based on the assumption of sphericity. Fortunately, the effects are so large that even using the most conservative adjustment of the df’s (i.e., lower-bound epsilon), all of the effects remain significant at the .05 level (although the three-way interaction is just at the borderline with p = .05). Follow-up Comparisons: Simple Interaction Effects To test the significance of the simple interaction effects just discussed, the appropriate error term is MSwithin-cell, as defined in section C of Chapter 16, rather than MSW from the overall analysis. This entails adding SSW to SSS × R and dividing by the sum of dfW and dfS × R. Thus, MSwithin-cell equals (1,827 + 407)/(48 + 96) = 2,234/144 = 15.5. However, given the small sample sizes in our example, it would be even safer (with respect to controlling Type I errors) to test the two-way interaction in each simple interaction effect as though it were a separate two-way ANOVA. There is little difference between the two approaches in this case because MSwithin-cell is just the ordinary average of the MSW terms for the three simple interaction effects, and these do not differ much. The middle graph in Figure 22.7 represents the results of the two-way experiment of Chapter 14 (Section B), so if we don’t pool error terms, we know from the Chapter 14 analysis that the two-way interaction after 4 days is not statistically significant (F = 1.97). Because the interaction after 2 days is clearly less than it is after 4 days (and the error term is similar), it is a good guess that the two-way interaction after 2 days is not statistically significant, either (in fact, F < 1). However, the sleep × stimulation interaction becomes quite strong after 6 days; indeed, the F for that simple interaction effect is statistically significant (F = 2.73, p < .05). Although it may not have been predicted specifically that the sleep × stimulation interaction would grow stronger over time, it is a perfectly reasonable Graph of the Cell Means in Table 22.2 After Averaging Across the Time Factor Cohen_Chapter22.j.qxd 8/23/02 11:56 M Page 712 712 Chapter 22 • Three-Way ANOVA result, and it would make sense to focus our remaining follow-up analyses on Day 6 alone. We would then be dealing with an ordinary 4 × 3 ANOVA with no repeated measures, and post hoc analyses would proceed by testing simple main effects or interaction contrasts exactly as described in Chapter 14, Section C. Alternatively, we could have explored the significant three-way interaction by testing the sleep by time interaction for each stimulation level or the stimulation by time interaction for each sleep deprivation level. In these two cases, the appropriate error term, if all of the assumptions of the overall analysis are met, is MSS × RM from the omnibus analysis. However, as you know by now, caution is recommended with respect to the sphericity assumption, which dictates that each simple interaction effect be analyzed as a separate two-way ANOVA in which only the interaction is analyzed. Follow-up Comparisons: Partial Interactions As in the case of the two-way ANOVA, a three-way ANOVA in which at least two of the factors have three levels or more can be analyzed in terms of partial interactions, either as planned comparisons or as a way to follow up a significant three-way interaction. However, with three factors in the design, there are two distinct options. The first type of partial interaction involves forming a pairwise or complex comparison for one of the factors and crosses that comparison with all levels of the other two factors. For instance, you could reduce the stimulation factor to a comparison of caffeine and reward (pairwise) or to a comparison of placebo with the average of caffeine and reward (complex) but include all the levels of the other two factors. The second type of partial interaction involves forming a comparison for two of the factors. For example, caffeine versus reward and jet lag versus interrupted crossed with the three time periods. If a pairwise or complex comparison is created for all three factors, the result is a 2 × 2 × 2 subset of the original design, which has only one numerator df and therefore qualifies as an interaction contrast. A significant partial interaction may be decomposed into a series of interaction contrasts, or one can plan to test several of these from the outset. Another alternative is that a significant three-way interaction can be followed directly by post hoc interaction contrasts, skipping the analysis of partial interactions, even when they are possible. A significant three-way (i.e., 2 × 2 × 2) interaction contrast would be followed by a test of simple interaction effects, and, if appropriate, simple main effects (i.e., t tests between two cells). Follow-Up Comparisons: Three-Way Interaction Not Significant When the three-way interaction is not significant, attention shifts to the three two-way interactions. If none of the two-way interactions is significant, any significant main effect with more than two levels can be explored further with pairwise or complex comparisons among its levels. If only one of the two-way interactions is significant, the factor not involved in the interaction can be explored in the usual way if its main effect is significant. Any significant two-way interaction can be followed up with an analysis of its simple effects or with partial interactions and/or interaction contrasts, as described in Chapter 14, Section C. Planned Comparisons for the Three-Way ANOVA Bear in mind that a three-way ANOVA with several levels of each factor creates so many possibilities for post hoc testing that it is rare for a researcher Cohen_Chapter22.j.qxd 8/23/02 11:56 M Page 713 Section B • Basic Statistical Procedures to follow every significant omnibus F ratio (remember, there are seven of these) with post hoc tests and every significant post hoc test with more localized tests until all allowable cell-to-cell comparisons are made. It is more common when analyzing a three-way ANOVA to plan several comparisons based on one’s research hypotheses. Although a set of orthogonal contrasts is desirable, more often the planned comparisons are a mixture of simple effects, two- and three-way interaction contrasts, and cell-to-cell comparisons. If there are not too many of these, it is not unusual to test each planned comparison at the .05 level. However, if the planned comparisons are not orthogonal, and overlap in various ways, the cautious researcher is likely to use the Bonferroni adjustment to determine the alpha for each comparison. After the planned comparisons have been tested, it is not unusual for a researcher to test the seven F ratios of the overall analysis but to report and follow up only those effects that are both significant and interesting (and whose patterns of means make sense). When the RM Factor Has Only Two Levels If you have only one RM factor in your three-way ANOVA, and that factor has only two levels, you have the option of creating difference scores (i.e., the difference between the two RM levels) and conducting a two-way ANOVA on the difference scores. For this two-way ANOVA, the main effect of factor A is really the interaction of the RM factor with factor A, and similarly for factor B. The A × B interaction is really the three-way interaction of A, B, and the RM factor. The parts of the three-way ANOVA that you lose with this trick are the three main effects and the A × B interaction, but if you are only interested in interactions involving the RM factor, this shortcut can be convenient. The most likely case in which you would want to use difference scores is when the two levels of the RM factor are measurements taken before and after some treatment. However, as I mentioned in Chapter 16, this type of design is a good candidate for ANCOVA (you would use factorial ANCOVA if you had two between-group factors). Published Results of a Three-way ANOVA (One RM Factor) It is not hard to find published examples of the three-way ANOVA with one RM factor; the 2 × 2 × 2 design is probably the most common and is illustrated in a study entitled “Outcome of Cognitive-Behavioral Therapy for Depression: Relation to Hemispheric Dominance for Verbal Processing” (Bruder, et al., 1997). In this experiment, two dichotic listening tasks were used to assess hemispheric dominance: a verbal (i.e., syllables) task for which most people show a right-ear advantage (indicating left-hemispheric cerebral dominance for speech) and a nonverbal (i.e., complex tones) task for which most subjects exhibit a left-ear advantage. These two tasks are the levels of the RM factor. The dependent variable was a measure of perceptual asymmetry (PA), based on how much more material is reported from the right ear as compared to the left ear. Obviously, a strong main effect of the RM factor is to be expected. All of the subjects were patients with depression. The two betweengroups factors were treatment group (cognitive therapy or placebo) and therapy response or outcome (significant clinical improvement or not). The experiment tested whether people who have greater left-hemisphere dominance are more likely to respond to cognitive therapy; this effect is not expected for those “responding” to a placebo. The results exhibited a clear pattern, as I have shown in Figure 22.10 (I redrew their figure to make the 713 Cohen_Chapter22.j.qxd 8/23/02 11:56 M Page 714 714 Chapter 22 • Three-Way ANOVA Figure 22.10 Graph of Cell Means for the Bruder, et al. (1997) Study Placebo Cognitive Therapy 25 25 20 20 Responders 15 Nonresponders 10 15 10 5 Nonresponders 5 Responders 0 –5 Syllables Tones 0 Syllables Tones –5 presentation consistent with similar figures in this chapter). The authors state: There was a striking difference in PA between cognitive-therapy responders and nonresponders on the syllables test but not on the complex tones test. In contrast, there was no significant difference in PA between placebo responders and nonresponders on either test. The dependence of PA differences between responders and nonresponders on treatment and test was reflected in a significant Outcome × Treatment × Test interaction in an overall ANOVA of these data, F (1, 72) = 5.81, p = .018. Further analyses indicated that this three-way interaction was due to the presence of a significant Outcome × Test interaction for cognitive therapy, F (1, 29) = 5.67, p = .025, but not for placebo, F (1, 43) = 0.96, p = .332. Cognitivetherapy responders had a significantly larger right-ear (left-hemisphere) advantage for syllables when compared with nonresponders, t (29) = 2.58, p = .015, but no significant group difference was found for the tones test, t (29) = −1.12, p = .270. Notice that the significant three-way interaction is followed by tests of the simple interaction effects, and the significant simple interaction is, in turn, followed by t tests on the simple main effects of that two-way interaction (of course, the t tests could have been reported as Fs, but it is common to report t values for cell-to-cell comparisons when no factors are being collapsed). Until recently, F values less than 1.0 were usually shown as F < 1, p > .05 (or ns), but there is a growing trend to report Fs and ps as given by one’s statistical software output (note the reporting of F = 0.96 above). Two RM Factors There are many ways that a three-way factorial design with two RM factors can arise in psychological research. In one case you begin with a two-way RM design and then add a grouping factor. For instance, tension in the brow and cheek, as measured electrically (EMG), can reveal facial expressions that are hard to observe visually. While watching a happy scene from a movie, cheek tension generally rises in a subject (due to smiling), whereas brow tension declines (due to a decrease in frowning). The opposite pattern occurs while watching a sad scene. If tension is analyzed with a 2 (brow vs. cheek) × 2 (happy vs. sad) ANOVA, a significant interaction is likely to emerge. This is not an impressive result in itself, but the degree of the twoway (RM) interaction can be used as an index of the intensity of a subject’s (appropriate) emotional reactions. For example, in one (as yet unpublished) experiment, half the subjects were told to get involved in the movie scenes Cohen_Chapter22.j.qxd 8/23/02 11:56 M Page 715 Section B • Basic Statistical Procedures they were watching, whereas the other half were told to analyze the scene for various technical details. As expected, the two-way interaction was stronger for the involved subjects, producing a three-way interaction. In another experiment subjects were selected from an introductory psychology class based on their responses to an empathy questionnaire. Not surprisingly, there was again a three-way interaction due to the stronger two-way interaction for the high-empathy as compared to the low-empathy subjects. The example I will use to illustrate the calculation of a three-way ANOVA with two RM factors was inspired by a published study in industrial psychology entitled: “Gender and attractiveness biases in hiring decisions: Are more experienced managers less biased?” (Marlowe, Schneider & Nelson, 1996). For pedagogical reasons, I changed the structure and conclusions of the experiment quite a bit. In my example the subjects are all men who are chosen for having a corporate position in which they are frequently making hiring decisions. The between-groups factor is based on how many years of experience a subject has in such a position: little experience (less than 5 years), moderate experience (5 to 10 years), or much experience (more than 10 years). The dependent variable is the rating a subject gives to each resume (with attached photograph) he is shown; low ratings indicate that the subject would not be likely to hire the applicant (0 = no chance), whereas high ratings indicate that hiring would be likely (9 = would certainly hire). The two RM factors are the gender of the applicant and his or her attractiveness, as based on prior ratings of the photographs (above-average, average, below average). Each subject rates five applicants in each of the six attractiveness/gender categories; for each subject and each category, the five ratings have been averaged together and presented in Table 22.4. To reduce the necessary calculations I have included only four subjects in each experience group. Of course, the 30 applicants rated by each subject would be mixed randomly for each subject, eliminating both the possibility of simple order effects and the need for counterbalancing. In addition, the resumes would be counterbalanced with the photographs, so no photograph would be consistently paired with a better resume (the resumes would be similar anyway). For the sake of writing general formulas in which it is easy to spot the between-group and RM factors, I will use the letter A to represent the between-groups factor (amount of hiring experience, in this example) and Q and R to represent the two RM factors (gender and attractiveness, respectively). The “subject” factor will be designated as S. You have seen this factor before written as “between-subjects,” “sub” or “S,” but with two RM factors the shorter abbreviation is more convenient. The ANOVA that follows is the most complex one that will be described in this text. It requires all of the SS components of the previous analysis plus two more SS components that are extracted to create additional error terms. The analysis can begin in the same way as the previous one—with the calculation of SStotal and the SSs for the three main effects. The total number of observations, NT, equals aqrn = 3 2 3 4 = 72. SStotal, as usual, is equal to the biased variance of all 72 observations times 72, which equals 69.85. SSA is based on the means of the three independent groups, which appear in the Row Means column, in the rows that represent cell means (i.e., each group mean is the mean of the six RM cell means). SSR is based on the means for the attractiveness levels, which appear in the Column Means row under the columns labeled “Mean” (which takes the mean across gender). The gender means needed for SSQ are not in the table but can be found by averaging separately the column means for females and for males. The SSs for the main effects can now be found in the usual way. 715 Cell Mean Col Mean High Cell Mean Moderate Cell Mean Low Male 5.2 6.0 5.6 5.8 5.65 5.4 4.8 5.2 6.0 5.35 5.8 6.6 6.4 5.0 5.95 5.65 Female 5.2 5.8 5.6 4.4 5.25 4.8 5.4 4.2 4.6 4.75 4.4 5.2 3.6 4.0 4.30 4.77 BELOW 5.1 5.9 5.0 4.5 5.125 5.21 5.1 5.1 4.7 5.3 5.05 5.2 5.9 5.6 5.1 5.45 Mean 6.0 5.6 6.2 5.2 5.75 5.87 5.6 5.4 5.0 6.2 5.55 5.8 6.4 6.0 7.0 6.3 Female 7.0 6.2 7.8 6.8 6.95 6.32 6.0 6.6 5.8 5.4 5.95 6.0 5.2 6.2 6.8 6.05 Male AVERAGE Table 22.4 6.5 5.9 7.0 6.0 6.35 6.095 5.8 6.0 5.4 5.8 5.75 5.9 5.8 6.1 6.9 6.175 Mean 7.0 6.6 5.2 6.8 6.40 6.83 6.4 5.8 7.6 7.2 6.75 7.4 7.6 6.6 7.8 7.35 Female 5.6 4.8 6.4 5.8 5.65 6.68 7.0 7.6 6.8 6.4 6.95 7.6 8.0 7.8 6.4 7.45 Male ABOVE 6.3 5.7 5.8 6.3 6.025 6.755 6.7 6.7 7.2 6.8 6.85 7.5 7.8 7.2 7.1 7.4 Mean 5.97 5.83 5.93 5.60 5.8333 6.02 5.87 5.93 5.77 5.97 5.8833 6.2 6.5 6.3 6.37 6.3417 Row Means Cohen_Chapter22.j.qxd 8/23/02 11:56 M Page 716 Cohen_Chapter22.j.qxd 8/23/02 11:56 M Page 717 Section B • Basic Statistical Procedures SSA = 72 σ2(6.3417, 5.8833, 5.8333) = 3.77 SSQ = 72 σ2(5.8233, 6.2167) = 2.785 SSR = 72 σ2(5.21, 6.095, 6.755) = 28.85 As in the previous analysis we will need SSbetween-subjects based on the 12 overall subject means (across all six categories of applicants). These are the row means (ignoring the rows labeled “Cell Means” and “Column Means,” of course) in Table 22.4. SSbet-S = 72 σ2(6.2, 6.5, 6.3, 6.37, 5.87, 5.93, 5.77, 5.97, 5.97, 5.83, 5.93, 5.6) = 4.694 = SSS Because this is the same SS you would get if you were going to calculate a main effect of subjects, I will call this SS component SSS. Before we get enmeshed in the complexities of dealing with two RM factors, we can complete the between-groups part of the analysis. I will use Formula 16.2 from the two-way mixed design with an appropriate change in the subscripts: SSW = SSS − SSA Formula 22.8 For this example, SSW = 4.694 − 3.77 = .924 dfA = a − 1 = 3 − 1 = 2 dfW = a(n − 1) = an − a = 12 − 3 = 9 Therefore, SSA 3.77 MSA = = = 1.885 2 2 and SSW .924 MSW = = = .103 9 9 Finally, 1.885 FA = = 18.4 .103 The appropriate critical F is F.05(2,9) = 4.26, so FA is easily significant. A look at the means for the three groups of subjects shows us that managers with greater experience are, in general, more cautious with their hirability ratings (perhaps they have been “burned” more times), especially when comparing low to moderate experience. However, there is no point in trying to interpret this finding before testing the various interactions, which may make this finding irrelevant or even misleading. I have completed the between-groups part of the analysis at this point just to show you that at least part of the analysis is easy and to get it out of the way before the more complicated within-subject part of the analysis begins. With only one RM factor there is only one error term that involves an interaction with the subject factor, and that error term is found easily by subtraction. However, with two RM factors the subject factor interacts with each RM factor separately, and with the interaction of the two of them, yielding three different error terms. The extraction of these extra error terms requires the collapsing of more intermediate tables, and the calculation of more intermediate SS terms. Of course, the calculations are performed the same way as always—there are just more of them. Let’s begin, however, with the numerators of the various interaction terms, which involve the same procedures as the three-way analysis with only one RM factor. First, we can 717 Cohen_Chapter22.j.qxd 8/23/02 11:56 M Page 718 718 Chapter 22 • Three-Way ANOVA get SSAQR from the 18 cell means in Table 22.4 (all of the female and male columns of the three Cell Means rows). SSAQR = 72 σ2(cell means) = 72 .694 = 49.96 The means needed to find SSAR are averaged across the Q factor (i.e., gender); they are found in the three Cell Mean rows, in the columns labeled “Means.” SSAR = 72 σ2(5.45, 6.175, 7.4, 5.05, 5.75, 6.85, 5.125, 6.35, 6.025) = 72 .5407 = 38.93 The means for SSQR are the Column Means in Table 22.4 for females and males (but not Means) and are averaged across all subjects, regardless of group. SSQR = 72 σ2(4.77, 5.65, 5.87, 6.32, 6.83, 6.68) = 72 .4839 = 34.84 The means needed for SSAQ do not have a convenient place in Table 22.4; those means would fit easily in a table in which the female columns are all adjacent (for Below, Average, and Above), followed by the three male columns. Using Table 22.4, you can average together for each group all of the female cell means and then all of the male cell means, thus producing the six AQ means. SSAQ = 72 σ2(6.3, 6.383, 5.683, 6.083, 5.483, 6.185) = 72 .1072 = 7.72 Now we can get the SSs for all of the interactions by subtraction, using Formula 22.1 (except that B and C have been changed to Q and R): SSA × Q = SSAQ − SSA − SSQ = 7.72 − 3.77 − 2.785 = 1.16 SSA × R = SSAR − SSA − SSR = 38.93 − 3.77 − 28.85 = 6.31 SSQ × R = SSQR − SSQ − SSR = 34.84 − 2.785 − 28.85 = 3.21 SSA × Q × R = SSAQR − SSA × Q − SSA × R − SSQ × R − SSA − SSQ − SSR = 49.96 − 1.16 − 6.31 − 3.21 − 3.77 − 2.785 − 28.85 = 3.875 The next (and trickiest) step is to calculate the SSs for the three RM error terms. These are the same error terms I described at the end of Section A in the context of the two-way RM ANOVA. For each RM factor the appropriate error term is based on the interaction of the subject factor with that RM factor. The more that subjects move in parallel from one level of the RM factor to another, the smaller the error term. The error term for each RM factor is based on averaging over the other factor. However, the third RM error term, the error term for the interaction of the two RM factors, is based on the three-way interaction of the subject factor and the two RM factors, with no averaging of scores. To the extent that each subject exhibits the same twoway interaction for the RM factors, this error term will be small. Two more intermediate SSs are required: SSQS, and SSRS. These SSs come from two additional two-way means tables, each one averaging scores over one of the RM factors but not the other. (Note: The A factor isn’t mentioned for these components because it is simply being ignored. Some of the subject means are from subjects in the same group, and some are from subjects in different groups, but this distinction plays no role for these SS components.) You can get SSRS from the entries in the columns labeled “Means” (ignoring the rows labeled “Cell Means” and “Column Means,” of course) in Table 22.4; in all there are 36 male/female averages, or RS means: SSRS = 72 σ2(RS means) = 72 .6543 = 47.11 To find the QS means, you need to create, in addition to the row means in Table 22.4, two additional means for each row: one for the “females” in that row, and one for the “males,” for a total of 24 “gender” row means. Cohen_Chapter22.j.qxd 8/23/02 11:56 M Page 719 Section B • Basic Statistical Procedures SSQS = 72 σ2(6.13, 6.27, 6.6, 6.4, 6.07, 6.53, 6.4, 6.33, 5.6, 6.13, 5.53, 6.33, 5.6, 5.93, 6, 5.93, 5.8, 6.13, 5.8, 5.87, 5.0, 6.87, 5.33, 5.87) = 72 .1737 = 12.51 (Note: the means are in the order “female, male” for each subject (i.e.,row)— top to bottom—of Table 22.4.) Now we are ready to get the error terms by subtraction, using Formula 22.9A. SSQ × S = SSQS − SSQ − SSS − SSA × Q Formula 22.9A So, SSQ × S = 12.51 − 2.785 − 4.694 − 1.16 = 3.87 [Note: I subtracted the group by gender interaction at the end of the preceding calculation because what we really want (and what I mean by SSQ × S) is the gender by subject interaction within each group (i.e., level of the A factor), added across all the groups. This is not the same as just finding the gender by subject interaction, ignoring group. Any group by gender interaction will increase the gender by subject interaction when ignoring group, but not if you calculate the interaction separately within each group. Rather than calculating the gender by subject interaction for each group, it is easier to calculate the overall interaction ignoring group and then subtract the group by gender interaction. The same trick is used to find SSR × S.] SSR × S = SSRS − SSR − SSS − SSA × R Formula 22.9B Therefore, SSR × S = 47.11 − 28.85 − 4.694 − 6.31 = 7.26 Finally, the last error term, SSQ × R × S, can be found by subtracting all of the other SS components from SStotal. To simplify this last calculation, note that SStotal is the sum of all the cell-to-cell variation and the four error terms: SStotal = SSAQR + SSW + SSQ × S + SSR × S + SSQ × R × S Formula 22.9C So, SSQ × R × S = SStotal − SSAQR − SSW − SSQ × S − SSR × S = 69.85 − 49.96 − .924 − 3.87 − 7.26 = 7.836 The degrees of freedom are divided up for this design in a way that is best illustrated in a df tree, as shown in Figure 22.11. The formulas for the df’s are as follows: a. b. c. d. e. f. g. h. i. j. k. dfA = a − 1 dfQ = q − 1 dfR = r − 1 dfA × Q = (a − 1)(q − 1) dfA × R = (a − 1)(r − 1) dfQ × R = (q − 1)(r − 1) dfA × Q × R = (a − 1)(q − 1)(r − 1) dfW = a (n − 1) dfQ × S = dfQ dfW = a(q − 1)(n − 1) dfR × S = dfR dfW = a(r − 1)(n − 1) dfQ × R × S = dfQ dfR dfW = a(q − 1)(r − 1)(n − 1) For this example, Formula 22.10 719 Cohen_Chapter22.j.qxd 8/23/02 11:56 M Page 720 720 Chapter 22 • Three-Way ANOVA dfA = 3 − 1 = 2 dfQ = 2 − 1 = 1 dfR = 3 − 1 = 2 dfA × Q = 2 1 = 2 dfA × R = 2 2 = 4 dfQ × R = 1 2 = 2 dfA × Q × R = 2 1 2 = 4 dfW = 3 3 = 9 dfQ × S = dfQ dfW = 1 9 = 9 dfR × S = dfR dfW = 2 9 = 18 dfQ × R × S = dfQ dfR dfW = 1 2 9 = 18 Note that the sum of all the df’s is 71, which equals dftotal (NT − 1 = aqrn − 1 = 72 − 1). When you have converted each SS to an MS, the seven F ratios are formed as follows: MSA FA = MSW a. MSQ b. FQ = MSQ × S MSA × R FA × R = MSR × S f. MSQ × R FQ × R = MSQ × R × S Formula 22.11 MSA × Q × R g. FA × Q × R = MSQ × R × S MSR FR = MSR × S c. e. MSA × Q d. FA × Q = MSQ × S The completed analysis is shown in Table 22.5. Notice that each of the three different RM error terms is being used twice. This is just an extension df total [aqrn–1] Figure 22.11 Degrees of Freedom Tree for 3-Way ANOVA with Repeated Measures on Two Factors df between-S [an–1] df A [a–1] df within-S [an(qr–1)] df W [a(n–1)] df Q [q–1] df AXQ [(a–1)(q–1)] df QXS [a(n–1)(q–1)] df R [r–1] df QXR [(q–1)(r–1)] df AXR [(a–1)(r–1)] df RXS [a(n–1)(r–1)] df AXQXR [(a–1)(q–1)(r–1)] df QXRXS [a(n–1)(q–1)(r–1)] Cohen_Chapter22.j.qxd 8/23/02 11:56 M Page 721 Section B • Basic Statistical Procedures Source SS df MS Between-groups Hiring Experience Within-group error 4.694 3.77 .924 11 2 9 1.885 .103 Within-subjects Gender Group × Gender Gender × Subject 65.156 2.785 1.16 3.87 60 1 2 9 2.785 .580 .430 6.48 1.35 <.05 >.05 Attractiveness Group × Atttract Attract × Subject 28.85 6.31 7.26 2 4 18 14.43 1.578 .403 35.81 3.92 <.001 <.05 2 4 18 1.60 .970 .435 3.69 2.23 <.05 >.05 Gender × Attract Group × Gender × Attract Gender × Attract × Subject 3.21 3.875 7.836 F p 18.4 <.001 721 Table 22.5 Note: The note from Table 22.3 applies here as well. of what you saw in the two-way mixed design when the S × RM error term was used for both the RM main effect and its interaction with the betweengroups factor. Interpreting the Results Although the three-way interaction was not significant, you will probably want to graph all of the cell means in any case to see what’s going on in your results; I did this in Figure 22.12, choosing applicant gender as the variable whose levels are represented by different graphs and hiring experience levels to be represented as different lines on each graph. You can see by comparing the two graphs in the figure why the F ratio for the three-way interaction was not very small, even though it failed to attain significance. The threeway interaction is due almost entirely to the drop in hirability from average to above average attractiveness only for highly experienced subjects judging male applicants. It is also obvious (and not misleading) that the main effect of attractiveness should be significant (with the one exception just mentioned, all the lines go up with increasing attractiveness), and the main effect of gender as well (the lines on the “male” graph are generally higher.) That Female Male Low Low 7 7 Moderate Moderate High 6 6 High 5 0 5 Below Average Above 0 Below Average Above Figure 22.12 Graph of the Cell Means for the Data in Table 22.4 Cohen_Chapter22.j.qxd 8/23/02 11:56 M Page 722 722 Chapter 22 • Three-Way ANOVA Figure 22.13 Graph of the Cell Means for Table 22.4 After Averaging Across Gender Average of Female and Male Applicants Low 7 Moderate High 6 5 0 Below Average Above the line for the low experience group is consistently above the line for moderate experience seems to account, at least in part, for the significance of the main effect for that factor. The significant attractiveness by experience (i.e., group) interaction is clearly due to a strong interaction for the male condition being averaged with a lack of interaction for the females (Figure 22.13 shows the male and female conditions averaged together, which bears a greater resemblance to the male than female condition). This is a case when a three-way interaction that is not significant should nonetheless lead to caution in interpreting significant two-way interactions. Perhaps, the most interesting significant result is the interaction of attractiveness and gender. Figure 22.14 shows that although attractiveness is a strong factor in hirability for both genders, it makes somewhat less of a difference for males. However, the most potentially interesting result would have been the three-way interaction, had it been significant; it could have shown that the impact of attractiveness on hirability changes with the experience of the employer, but more for male than female applicants. Figure 22.14 Graph of the Cell Means for Table 22.4 After Averaging Across the Levels of Hiring Experience Average of the Three Hiring Experience Levels 7 Female Male 6 5 0 Below Average Above Cohen_Chapter22.j.qxd 8/23/02 11:56 M Page 723 Section B • Basic Statistical Procedures Assumptions For each of the three RM error terms (Q × S, R × S, Q × R × S), pairwise interactions should be the same for each independent group; these assumptions can be tested with three applications of Box’s M test. With interactions pooled across groups, sphericity can then be tested with Mauchly’s W for each of the three error terms (Huynh & Mandeville, 1979). In the preceding example, sphericity is not an issue for gender, which has only two levels, but sphericity can be tested separately for both attractiveness and the gender by attractiveness interaction. However, rather than relying on the outcome of statistical tests of assumptions, researchers often “play it safe” by ensuring that all of the groups have the same number of subjects and adjusting the df with epsilon before testing effects involving a repeated-measures factor. Follow-Up Comparisons Given the significance of the attractiveness by experience interaction, it would be reasonable to perform follow-up tests, similar to those described for the two-way mixed design in Chapter 16. This includes the possibility of analyzing simple effects (a one-way ANOVA at each attractiveness level or a one-way RM ANOVA for each experience group), partial interactions (e.g., averaging the low and moderate experience conditions and performing the resulting 2 × 3 ANOVA) or interaction contrasts (e.g., the average of the low and moderate conditions and the high condition crossed with the average and above average attractiveness conditions). Such tests, if significant, could justify various cell-to-cell comparisons. To follow up on the significant gender by attractiveness interaction, the most sensible approach would be simply to conduct RM t tests between the genders at each level of attractiveness. In general, planned and post hoc comparisons for the three-way ANOVA with two RM factors follow the same logic as those described for the design with one RM factor. The only differences concern the error terms for these comparisons. If your between-group factor is significant, involves more than two levels, and is not involved in an interaction with one of the RM factors, you can use MSW from the overall analysis as your error term. For all other comparisons, using an error term from the overall analysis requires some questionable homogeneity assumption. For tests involving one or both of the two RM factors, it is safest to perform all planned and post hoc comparisons using an error term based only on the conditions included in the test. Published Results of a Three-way ANOVA (Two RM Factors) Banaji and Hardin (1996) studied automatic stereotyping by presenting common gender pronouns to subjects (e.g., she, him) and measuring their reaction times to judging the gender of the pronouns (i.e., male or female; no neutral pronouns were used in their Experiment 1). The interesting manipulation was that the pronouns were preceded by primes—words that subjects were told to ignore but which could refer to a particular gender by definition (i.e., mother) or by stereotype (i.e., nurse). The gender of the prime on each trial was either female, male, neutral (i.e., postal clerk) or just a string of letters (nonword). The authors describe their 4 × 2 × 2 experimental design as a “mixed factorial, with subject gender the betweensubjects factor” (p. 138). An excerpt of their results follows: The omnibus Prime Gender (female, male, neutral, nonword) × Target Gender (female, male) × Subject Gender (female, male) three-way analysis of variance yielded the predicted Prime Gender × Target Gender interaction, F (3,198) = 723 Cohen_Chapter22.j.qxd 8/23/02 11:56 M Page 724 Chapter 22 • Three-Way ANOVA 724 72.25, p < .0001 . . . No other reliable main effects or interactions were obtained as a function of either subject gender or target gender (Fs < 1) (p. 138). The significant two-way interaction was then followed with an interaction contrast (dropping the neutral and nonword prime conditions) and cell-tocell comparisons: The specific Prime Gender × Target Gender interaction (excluding the neutral conditions) was also reliable, F (1,66) = 117.56, p < .0001. Subjects were faster to judge male pronouns after male than female primes, t (67) = 11.59, p < .0001, but faster to judge female pronouns after female than male primes, t (67) = 6.90, p < .0001 (p. 138). B SUMMARY 1. The calculation of the three-way ANOVA with repeated measures on one factor follows the basic outline of the independent three-way ANOVA, as described in Section A, but adds elements of the mixed design, as delineated in Chapter 16. The between-subject factors are labeled A and B, whereas the within-subject factor is labeled R (short for RM). The number of levels of the factors are symbolized by a, b, and c, respectively. The following steps should be followed: a. Begin with a table of the individual scores and then find the mean for each level of each factor, the mean for each different subject (averaging across the levels of the RM factor), and the mean for each cell of the three-way design. From your table of cell means, create three “two-way” tables of means, in each case taking a simple average of the cell means across one of the three factors. b. Use Formula 14.3 to find SStotal from the individual scores; SSA, SSB, and SSR from the means at each factor level; SSbetween-subjects from the means for each subject; SSABR from the cell means; and SSAB, SSAR, and SSBR from the two-way tables of means. c. Find the SS components for the three two-way interactions, the three-way interaction, and the two error terms (SSW and SSS × R) by subtraction. Divide these six SS components, along with the three SS components for the main effects, by their respective df to create the nine necessary MS terms. d. Form the seven F ratios by using MSW as the error term for the main effects of A and B and their interaction and then, using MSS × R as the error term for the main effect of the RM factor, its interaction with A, its interaction with B, and the three-way interaction. 2. The calculation of the three-way ANOVA with repeated measures on two factors is related to both the independent three-way ANOVA and the two-way RM ANOVA. The between-subject factor is labeled A, whereas the two RM factors are labeled R and Q. The number of levels of the factors are symbolized by a, r, and q, respectively. The following steps should be followed. a. Begin with a table of the individual scores and then find the mean for each level of each factor, the mean for each different subject (averaging across the levels of both RM factors), and the mean for each cell of the three-way design. From your table of cell means, create three “two-way” tables of means, in each case taking a simple average of the cell means across one of the three factors. In addition, create two more two-way tables in which scores are averaged over one RM factor or the other, but not both, and subjects are not averaged across groups (i.e., each table is a two-way matrix of subjects by one of the RM factors.). b. Use Formula 14.3 to find SStotal from the individual scores; SSA, SSQ, and SSR from the means at each factor level; SSS from the means for each subject; SSABR from the cell means; SSAB, SSAR, and SSBR from the Cohen_Chapter22.j.qxd 8/23/02 11:56 M Page 725 Section B • Basic Statistical Procedures 725 two-way tables of means; and SSQS and SSRS from the additional twoway tables of subject means. c. Find the SS components for the three two-way interactions, the three-way interaction, and the four error terms (SSW, SSQ × S, SSR × S, and SSQ × R × S) by subtraction. Divide these eight SS components, along with the three SS components for the main effects by their respective df to create the 11 necessary MS terms. d. Form the seven F ratios by using MSW as the error term for the main effect of A; MSQ × S as the error term for both the main effect of Q and its interaction with A; MSR × S as the error term for both the main effect of R and its interaction with A; and MSQ × R × S as the error term for both the interaction of Q and R, and the three-way interaction. 3. If the three-way interaction is not significant, the focus shifts to the twoway interactions. A significant two-way interaction is followed either by an analysis of simple effects or by an analysis of partial interactions and/or interaction contrasts, as described in Chapter 14. Any significant main effect for a factor not involved in a two-way interaction can be explored with pairwise or complex comparisons among its levels (if there are more than two). 4. If the three-way interaction is significant, it is common to test the simple interaction effects. Any significant simple interaction effect can be followed by an analysis of simple main effects and finally by cell-to-cell comparisons, if warranted. Alternatively, the significant three-way interaction can be localized by analyzing partial interactions involving all three factors; for example, either one or two of the factors can be reduced to only two levels. It is also reasonable to skip this phase and proceed directly to test various 2 × 2 × 2 interaction contrasts, which are then followed by simple interaction effects and cell-to-cell comparisons if the initial tests are significant. 5. Three-way ANOVAs that include RM factors require homogeneity and sphericity assumptions that are a simple extension of those for the twoway mixed design. Because tests of these assumptions can be unreliable, and their violation is likely in many psychological experiments and the violation can greatly inflate the Type I error rate, especially when conducting post hoc tests, it is usually recommended that post hoc comparisons, and even planned ones, use an error term based only on the factor levels included in the comparison and not the error term from the overall analysis. EXERCISES 1. A total of 60 college students participated in a study of attitude change. Each student was randomly assigned to one of three groups that differed according to the style of persuasion that was used: rational arguments, emotional appeal, and stern/commanding (Style factor). Each of these groups was randomly divided in half, with one subgroup hearing the arguments from a fellow student, and the other from a college administrator (Speaker factor). Each student heard arguments on the same four campus issues (e.g., tuition increase), and attitude change was measured for each of the four issues (Issue factor). The sums of squares for the three-way mixed ANOVA are as follows: SSstyle = 50.4, SSspeaker = 12.9, SSissue = 10.6, SSstyle × speaker = 21.0, SSstyle × issue = 72.6, SSspeaker × issue = 5.3, SSstyle × speaker × issue = 14.5, SSW = 189, and SStotal = 732.7. a. Calculate the seven F ratios, and test each for significance. b. Find the conservatively adjusted critical F for each test involving a repeatedmeasures factor. Will any of your conclu- Cohen_Chapter22.j.qxd 8/23/02 11:56 M Page 726 Chapter 22 • Three-Way ANOVA 726 a. Calculate the three-way mixed-design ANOVA for the data. Present your results in a summary table. b. Use graphs of the cell means to help you describe the pattern underlying each effect that was significant in part a. c. Do you need to retest any of your results in part a if you make no assumptions about sphericity? Explain. d. How can you transform the data above so it can be analyzed by a two-way independent-groups ANOVA? Which effects from the analysis in part a would no longer be testable? e. If a simple order effect is present in the data, which error term is being inflated? How can you remove the extra variance from that error term? 3. The dean at a large college is testing the effects of a new advisement system on students’ feelings of satisfaction with their educational experience. A random sample of 12 first-year students coming from small high schools was selected, along with an equalsized sample of students from large high schools. Within each sample, a third of the students were randomly assigned to the new system, a third to the old system, and a third to a combination of the two systems. Satisfaction was measured on a 10-point scale (10 = completely satisfied) at the end of each student’s first, second, third, and fourth years. The data for the study appear in the following table: sions be affected if you do not make any assumptions about sphericity? 2. Based on a questionnaire they had filled out earlier in the semester, students were classified as high, low, or average in empathy. The 12 students recruited in each category for this experiment were randomly divided in half, with one subgroup given instructions to watch videotapes to check for the quality of the picture and sound (detail group) and the other subgroup given instructions to get involved in the story portrayed in the videotape. All subjects viewed the same two videotapes (in counterbalanced order): one presenting a happy story and one presenting a sad story. The dependent variable was the subject’s rating of his or her mood at the end of each tape, using a 10-point happiness scale (0 = extremely sad, 5 = neutral, and 10 = extremely happy). The data for the study appear in the following table: LOW EMPATHY AVERAGE EMPATHY HIGH EMPATHY Happy Sad Happy Sad Happy Sad Detail 6 6 5 7 4 6 5 5 7 4 6 5 5 7 5 5 4 5 4 2 3 5 4 5 7 8 7 5 6 5 3 3 1 5 4 5 Involved 5 5 6 4 5 4 4 4 4 5 3 5 6 6 7 4 6 4 2 2 1 4 2 4 7 8 9 7 6 7 2 1 1 2 1 2 SMALL HIGH SCHOOL LARGE HIGH SCHOOL First Second Third Fourth First Second Third Fourth Old System 4 5 3 5 4 5 4 4 5 4 5 4 4 4 6 6 5 6 4 5 5 7 4 5 5 7 4 5 6 6 4 5 New System 6 7 5 6 5 8 4 6 6 9 4 7 7 9 5 7 7 7 6 6 8 8 7 5 8 8 7 6 8 8 7 8 Combined 5 4 6 5 5 5 6 6 6 6 5 6 6 7 6 6 9 8 9 8 7 7 6 6 7 7 5 6 7 6 5 8 Cohen_Chapter22.j.qxd 8/23/02 11:56 M Page 727 Section B • Basic Statistical Procedures a. Calculate the appropriate three-way ANOVA for the data. Present your results in a summary table. b. Use graphs of the cell means to help you describe the pattern underlying each effect that was significant in part a. Describe a partial interaction that would be meaningful. How might you use trend components? c. What analyses of simple effects are justified, if any, by the results in part a? What error term should you use in each case if you make no assumptions about sphericity? d. Find the conservatively adjusted critical F for each test involving a repeatedmeasures factor. Will any of your conclusions be affected if you do not make any assumptions about sphericity? 4. Imagine an experiment in which all subjects solve two types of problems (spatial and verbal), each at three levels of difficulty (easy, moderate, and hard). Half of the 24 subjects are given instructions to use visual imagery, and half are told to use subvocalization. The dependent variable is the number of eye movements that a subject makes during the 5-second problem-solving period. The cell means for this experiment are given in the following table: SUBVOCAL INSTRUCTIONS 727 a. Given that SStype × S = 224, SSdifficulty × S = 130, SStype × difficulty × S = 62, and SSW = 528, perform the appropriate three-way ANOVA on the data. Present your results in a summary table. b. Graph the Type × Difficulty means, averaging across instruction group. Compare this graph to the Type × Difficulty graph for each instruction group. Can the overall Type × Difficulty interaction be meaningfully interpreted? Explain. c. Find the conservatively adjusted critical F for each test. Will any of your conclusions be affected if you do not assume that sphericity exists in the population? d. Given the results you found in part a, which simple effects can be justifiably analyzed? 5. Imagine that the psychologist in Exercise 6 of Section A runs her study under two different conditions with two different random samples of subjects. The two conditions depend on the type of background music played to the subjects as they memorize the list of words: very happy or very sad. The number of words recalled in each word category for each subject in the two groups is given in the following table: IMAGERY INSTRUCTIONS Difficulty Spatial Verbal Spatial Verbal Easy Moderate Hard 1.5 2.5 2.7 1.6 1.9 2.1 3.9 5.2 7.8 2.2 2.4 2.8 SAD NEUTRAL HAPPY Low Medium High Low Medium High Low Medium High Happy Music 4 2 4 2 4 3 6 5 7 5 8 5 9 7 5 4 8 6 3 4 3 4 5 5 5 6 5 6 7 5 6 7 5 6 7 6 4 5 4 4 5 6 4 6 5 4 5 4 9 6 7 5 10 5 Sad Music 5 3 6 3 4 5 6 5 7 6 10 5 9 9 6 7 9 7 2 3 2 3 4 4 4 6 4 4 6 5 6 5 5 6 7 6 3 4 3 4 5 4 4 5 3 4 5 4 6 5 6 5 8 5 Cohen_Chapter22.j.qxd 8/23/02 11:56 M Page 728 Chapter 22 • Three-Way ANOVA 728 items correctly identified in a subsequent recognition test. Six subjects are selected from each of the following categories: damage confined to the right cerebral hemisphere, damage confined on the left, and equal damage to the two hemispheres. Within each category, subjects are matched into three pairs, and one member of each pair is randomly selected to receive training, and the other member is not. a. Perform the appropriate three-way mixed-design ANOVA on the data (don’t forget that subjects are matched on the Training factor). Present your results in a summary table. b. How many different order conditions would be needed to counterbalance this study? How can you tell from the cell sizes that this study could not have been properly counterbalanced? c. Describe a meaningful partial interaction involving all three factors. Describe a set of orthogonal contrasts for completely analyzing the three-way interaction. a. Perform a three-way mixed-design ANOVA on the data. Present your results in a summary table. b. Find the conservatively adjusted critical F for each test. Will any of your conclusions be affected if you do not assume that sphericity exists in the population? c. Draw a graph of the cell means (with separate panels for the two types of background music), and describe the nature of any effects that are noticeable. Which 2 × 2 × 2 interaction contrast appears to be the largest? d. Based on the variables in this exercise, and the results in part a, what post hoc tests would be justified and meaningful? 6. A neuropsychologist is testing the benefits of a new cognitive training program designed to improve memory in patients who have suffered brain damage. The effects of the training are being tested on four types of memory: abstract words, concrete words, human faces, and simple line drawings. Each subject performs all four types of tasks. The dependent variable is the number of NO TRAINING TRAINING Abstract Concrete Faces Drawings Abstract Concrete Faces Drawings Right brain damage 11 13 9 19 20 18 7 10 4 5 9 1 12 10 14 18 19 17 10 7 13 8 11 5 Left brain damage 5 7 3 5 8 5 13 15 11 11 7 15 7 9 5 10 8 12 15 17 13 12 9 15 Equal damage 7 8 6 6 5 7 11 8 14 7 9 5 8 7 9 9 11 7 11 9 13 9 7 11 C OPTIONAL MATERIAL Multivariate Analysis of Variance Multifactor experiments have become very popular in recent years, in part because they allow for the testing of complex interactions, but also because they can be an efficient (not to mention economical) way to test several hypotheses in one experiment, with one set of subjects. This need for efficiency is driven to some extent by the ever-increasing demand to publish as well as the scarcity of funding. Given the current situation, it is not surprising that researchers rarely measure only one dependent variable. Once you have invested the resources to conduct an elaborate experiment, the cost is usually not increased very much by measuring additional variables; it makes sense to squeeze in as many extra measures or tasks as you can without exhausting the subjects and without one task interfering with another. Having gathered measures on several DVs, you can then test each DV separately Cohen_Chapter22.j.qxd 8/23/02 11:56 M Page 729 Section C • Optional Material 729 with the appropriate ANOVA design. However, if each DV is tested at the .05 level, you are increasing the risk of making a Type I error in the overall study—that is, you are increasing the experimentwise alpha. You can use the Bonferroni adjustment to reduce the alpha for each test, but there is an alternative that is frequently more powerful. This method, in which all of the DVs are tested simultaneously, is called the multivariate analysis of variance (MANOVA); the term multivariate refers to the incorporation of more than one DV in the test (all of the ANOVA techniques you have learned thus far are known as univariate tests). Although it seems clear to me that the most common use of MANOVA at present is the control of experimentwise alpha, it is certainly not the most interesting use. I think it is safe to say that the most interesting use of MANOVA is to find a combination of the DVs that distinguishes your groups better than any of the individual DVs separately. In fact, the MANOVA can attain significance even when none of the DVs does by itself. This is the type of situation I will use to introduce MANOVA. The choice of my first example is also dictated by the fact that MANOVA is much simpler when it is performed on only two groups. The Two-Group Case: Hotelling’s T 2 Imagine that a sample of high school students is divided into two groups depending on their parents’ scores on a questionnaire measuring parental attitudes toward education. One group of students has parents who place a high value on education, and the other group has parents who place relatively little value on education. Each student is measured on two variables: scholastic aptitude (for simplicity I’ll use IQ) and an average of grades for the previous semester. The results are shown in Figure 22.15. Notice that almost all of the students from “high value” (HV) homes (the filled circles) have grades that are relatively high for their IQs, whereas nearly all the students from “low value” (LV) homes show the opposite pattern. However, if you performed a t test between the two groups for IQ alone, it would be nearly zero, and although the HV students have somewhat higher grades on average, a t test on grades alone is not likely to be significant, either. But you can see that the two groups are fairly well separated on the graph, so it should come as no surprise that there is a way to combine the two DVs into a quantity that will distinguish the groups significantly. HV homes LV homes 110 Figure 22.15 Plot in which Two Groups of Students Differ Strongly on Two Variables IQ 100 90 70 80 90 Grades 100 Cohen_Chapter22.j.qxd 8/23/02 11:56 M Page 730 730 Chapter 22 • Three-Way ANOVA A simple difference score, IQ − grades (i.e., IQ minus grades), would separate the groups rather well, with the LV students clearly having the higher scores. (This difference score is essentially an underachievement score; in this hypothetical example students whose parents do not value education do not get grades as high as their IQs suggest they could, whereas their HV counterparts tend to be “overachievers”). However, the MANOVA procedure can almost always improve on a simple difference score by finding the weighted combination of the two variables that produces the largest t value possible. (If you used GPA on a four-point scale to replace grades, it would have to be multiplied by an appropriate constant before it would be reasonable to take a difference score, but even if you transform both variables to z scores, the MANOVA procedure will find a weighted combination that is better than just a simple difference. In many cases, a sum works better than a difference score, in which case MANOVA finds the best weighted sum.) Given the variables in this problem, the discriminant function, which creates the new variable to be tested, can be written as W1 IQ + W2 Grades + Constant (the constant is not relevant to the present discussion). For the data in Figure 22.15, the weights would come out close to W1 = 1 and W2 = −1, leading to something resembling a simple difference score. However, for the data in Figure 22.16, the weights would be quite different. Looking at the data in Figure 22.16, you can see that once again the two groups are well separated, but this time the grades variable is doing most of the discrimination, with IQ contributing little. The weights for the discriminant function would reflect that; the weight multiplying the z score for grades would be considerably larger than the weight for the IQ z score. It is not a major complication to use three, four, or even more variables to discriminate between the two groups of students. The raw-score (i.e., unstandardized) discriminant function for four variables would be written as W1X1 + W2X2 + W3X3 + W4X4 + Constant. This equation can, of course, be expanded to accommodate any number of variables. Adding more variables nearly always improves your ability to discriminate between the groups, but you pay a price in terms of losing degrees of freedom, as you will see when I discuss testing the discriminant function for statistical significance. Unless a variable is improving your discrimination considerably, adding it can actually reduce your power and hurt your significance test. Going back to the two-variable case, the weights of the discriminant function become increasingly unreliable (in terms of changing if you repeat the experiment with a new random sample) as the correlation of the two vari- HV homes LV homes Figure 22.16 Plot in which Two Groups of Students Differ Strongly on One Variable and Weakly on a Second Variable 110 IQ 100 90 70 80 90 Grades 100 Cohen_Chapter22.j.qxd 8/23/02 11:56 M Page 731 Section C • Optional Material ables increases. It is not a good idea to use two variables that are nearly redundant (e.g., both SAT scores and IQ). The likelihood of two of your variables being highly correlated increases as you add more variables, which is another reason not to add variables casually. The weights of your discriminant function depend on the discriminating power of each variable individually (its rpb with the grouping variable) and the intercorrelations among the variables. When your variables have fairly high intercorrelations, the discriminant loading of each variable can be a more stable indicator of its contribution to the discriminant function. A DV’s discriminant loading is its ordinary Pearson correlation with the scores from the discriminant function. High positive correlations among your DVs reduce the power of MANOVA when all the DVs vary in the same direction across your groups (Cole, Maxwell, Arvey, & Salas, 1994), which is probably the most common case. In fact, it has been suggested that one can obtain more power by running separate univariate ANOVAs for each of the highly correlated DVs and adjusting the alpha for each test according to the Bonferroni inequality. On the other hand, MANOVA becomes particularly interesting and powerful when some of the intercorrelations among the DVs are negative or when some of the DVs vary little from group to group but correlate highly (either positively or negatively) with other DVs. A DV that fits the latter description is acting like a “suppressor” variable in multiple regression. The advantage of that type of relation was discussed in Chapter 17. In the two-group case the discriminant weights will be closely related to the beta weights of multiple regression when you use your variables to predict the grouping variable (which can just be coded arbitrarily as 1 for one group, and 2 for the other). This was touched upon in Chapter 17, section C, under “Multiple Regression with a Dichotomous Criterion.” Because discriminant functions are not used nearly as often as multiple regression equations, I will not go into much detail on that topic. The way that discriminant functions are most often used is as the basis of the MANOVA procedure, and when performing MANOVA, there is usually no need to look at the underlying discriminant function. We are often only interested in testing its significance by methods I will turn to next. Testing T 2 for Significance It is not easy to calculate a discriminant function, even when you have only two groups to discriminate (this requires matrix algebra and is best left to statistical software), but it is fairly easy to understand how it works. The discriminant function creates a new score for each subject by taking a weighted combination of that subject’s scores on the various dependent variables. Then, a t test is performed on the two groups using the new scores. There are an infinite number of possible discriminant functions that could be tested, but the one that is tested is the one that creates the highest possible t value. Because you are creating the best possible combination of two or more variables to obtain your t value, it is not fair to compare it to the usual critical t. When combining two or more variables, you have a greater chance of getting a high t value by accident. The last step of MANOVA involves finding the appropriate null hypothesis distribution. One problem in testing our new t value is that the t distribution cannot adjust for the different number of variables that can go into our combination. We will have to square the t value so that it follows an F distribution. To indicate that our new t value has not only been squared but that it is based on a combination of variables, it is customary to refer to it as T 2—and in particular, Hotelling’s T 2—after the mathematician who determined its distri- 731 Cohen_Chapter22.j.qxd 8/23/02 11:56 M Page 732 732 Chapter 22 • Three-Way ANOVA bution under the null hypothesis. T 2 follows an F distribution, but it first must be reduced by a factor that is related to the number of variables, P, that were used to create it. The formula is n1 + n2 − P − 1 F = T 2 P(n1 + n2 − 2) Formula 22.12 where, n1 and n2 are the sizes of the two groups. The critical F is found with P and n1 + n2 − P − 1 degrees of freedom. Notice that when the sample sizes are fairly large compared to P, T 2 is multiplied by approximately 1/P. Of course, when P = 1, there is no adjustment at all. There is one case in which it is quite easy to calculate T 2. Suppose you have equal-sized groups of left- and right-handers and have calculated t tests for two DVs: a verbal test and a spatial test. If across all your subjects the two DVs have a zero correlation, you can find the square of the point-biserial correlation corresponding to each t test (use Formula 10.13 without taking the square root) and add the two together. The resulting rpb2 can be converted back to a t value by using Formula 10.12 (for testing the significance of rpb). However, if you use the square of that formula to get t2 instead, what you are really getting is T 2 for the combination of the two DVs. T 2 can then be tested with the preceding formula. If the two DVs are positively correlated, finding T 2 as just described would overestimate the true value (and underestimate it if the DVs are negatively correlated). If you have any number of DVs, and each possible pair has a zero correlation over all your subjects, you can add all the squared point-biserial rs and convert to T 2, as just described. If any two of your DVs have a nonzero correlation with each other, you can use multiple regression to combine all of the squared point-biserial rs; the combination is called R2. The F ratio used in multiple regression to test R2 would give the same result as the F for testing T 2 in this case. In other words, the significance test of a MANOVA with two groups is the same as the significance test for a multiple regression to predict group membership from your set of dependent variables. If you divide an ordinary t value by the square root of n/2 (if the groups are not the same size, n has to be replaced by the harmonic mean of the two sample sizes), you get g, a sample estimate of the effect size in the population. If you divide T 2 by n/2 (again, you need the harmonic mean if the ns are unequal) you get MD2, where MD is a multivariate version of g, called the Mahalanobis distance. In Figure 22.17 I have reproduced Figure 22.15, but added a measure of distance. The means of the LV and HV groups are not far apart on either IQ or grades separately, but if you create a new axis from the discriminant function that optimally combines the two variables, you can see that the groups are well separated on the new axis. Each group has a mean (called a centroid) in the two-dimensional space formed by the two variables. The MD is the standardized distance between the centroids, taking into account the correlation between the two variables. If you had three discriminator variables, you could draw the points of the two groups in threedimensional space, but you would still have two centroids and one distance between them. The MD can be found, of course, if you have even more discriminator variables, but unfortunately I can’t draw such a case. Because T 2 = (n/2)MD2, even a tiny MD can attain statistical significance with a large enough sample size. That is why it is useful to know MD in addition to T 2, so you can evaluate whether the groups are separated enough to be easily discriminable. I will return to this notion when I discuss discriminant analysis. Cohen_Chapter22.j.qxd 8/23/02 11:56 M Page 733 Section C • Optional Material HV homes LV homes 110 LV centroid Mahalanobis Distance HV centroid IQ 100 90 Discriminant function 70 80 90 100 Grades The Multigroup Case: MANOVA The relation between Hotelling’s T 2 and MANOVA is analogous to the relation between the ordinary t test and the univariate ANOVA. Consistent with this analogy, the Hotelling’s T 2 statistic cannot be applied when you have more than two groups, but its principles do apply. A more flexible statistic, which will work for any number of groups and any number of variables, is the one known as Wilk’s lambda; it is symbolized as Λ (an uppercase Greek letter, corresponding to the Roman L), and calculated simply as: Λ = SSW/SStotal. This statistic should remind you of η2 (eta squared). In fact, Λ = 1 − η2. Just as the significance of η2 can be tested with an F ratio, so can Λ. In the simple case of only two groups and P variables, Wilks’ Λ can be tested in an exact way with the following F ratio: 1 − Λ n1 + n2 − P − 1 F = Λ P Formula 22.13 The critical F is based on P and n1 + n2 − P − 1 degrees of freedom. The ratio of 1 − Λ to Λ is equal to SSbet / SSW, and when this ratio is multiplied by the ratio of df’s as in Formula 22.13, the result is the familiar ratio, MSbet/MSW, that you know from the one-way ANOVA and gives the same value as Formula 22.12. [In the two-group case, Λ = df/(T2 + df) where df = n1 + n2 − 2.] The problem that you encounter as soon as you have more than two groups (and more than one discriminator variable) is that more than one discriminant function can be found. If you insist that the scores from each of the discriminant functions you find are completely uncorrelated with those from each and every one of the others (and we always do), there is, fortunately, a limit to the number of discriminant functions you can find for any given MANOVA problem. The maximum number of discriminant functions, s, cannot be more than P or k − 1 (where k is the number of groups), whichever is smaller. We can write this as s = min(k − 1, P). Unfortunately, there is no universal agreement on how to test these discriminant functions for statistical significance. Consider the case of three groups and two variables. The first discriminant function that is found is the combination of the two variables that yields the largest possible F ratio in an ordinary one-way ANOVA. This combination of variables provides what is called the largest or greatest characteristic root (gcr). However, it is possible to create a second discriminant function whose scores are not correlated with the scores from the first function. (It is not possible to create a third function with scores uncorrelated with the first two; we 733 Figure 22.17 Plot of Two Groups of Students Measured on Two Different Variables Including the Discriminant Function and the Group Centroids Cohen_Chapter22.j.qxd 8/23/02 11:56 M Page 734 734 Chapter 22 • Three-Way ANOVA know this because, for this case, s = 2). Each function corresponds to its own lowercase lambda (λ), which can be tested for significance. Having more than one little lambda to test is analogous to having several pairs of means to test in a one-way ANOVA—there is more than one way to go about it while trying to keep Type I errors down and to maximize power at the same time. The most common approach is to form an overall Wilk’s Λ by pooling (through multiplication) the little lambdas and then to test Λ with an F ratio (the F ratio will follow an F distribution only approximately if you have more than three groups and more than two DVs). Pillai’s trace (sometimes called the Pillai-Bartlett statistic) is another way of pooling the little lambdas, and it leads to a statistic that appears to be more robust than Wilk’s Λ with respect to violations of the assumptions of MANOVA (see the following). Therefore, statisticians tend to prefer Pillai’s trace especially when sample sizes are small or unequal. A third way to pool the little lambdas, Hotelling’s trace (sometimes called the Hotelling-Lawley trace), is reported and tested by the common statistical software packages but is rarely used. All three of the statistics just described lead to similar F ratios in most cases, and it is not very common to attain significance with one but not the others. All of these statistics (including the one to be described next) can be calculated when there are only two groups, but in that case they all lead to exactly the same F ratio. A different approach to testing a multigroup MANOVA for significance is to test only the gcr for significance, usually with Roy’s largest root test. Unfortunately, it is possible to attain significance with one of the “multipleroot” tests previously described, even though the gcr is not significant. In such a case, it is quite difficult to pinpoint the source of your multivariate group differences, which is why some authors of statistical texts (notably, Harris, 1985) strongly prefer gcr tests. The gcr test is a reasonable alternative when its assumptions are met and when the largest root (corresponding to the best discriminant function) is considerably larger than any of the others. But consider the following situation. The three groups are normals, neurotics, and psychotics, and the two variables are degree of orientation to reality and inclination to seek psychotherapy. The best discriminant function might consist primarily of the reality variable, with normals and neurotics being similar but very different from psychotics. The second function might be almost as discriminating as the first, but if it was weighted most heavily on the psychotherapy variable, it would be discriminating the neurotics from the other two groups. When several discriminant functions are about equally good, a multiple-root test, like Wilk’s lambda or Pillai’s trace, is likely to be more powerful than a gcr test. The multiple-root test should be followed by a gcr test if you are interested in understanding why your groups differ; as already mentioned, a significant multiple-root test does not guarantee a significant gcr test (Harris, 1985). A significant gcr test, whether or not it is preceded by a multiple root test, can be followed by a separate test of the next largest discriminant function, and so on, until you reach a root that is not significant. (Alternatively, you can recalculate Wilk’s Λ without the largest root, test it for significance, and then drop the second largest and retest until Wilk’s Λ is no longer significant.) Each significant discriminant function (if standardized) can be understood in terms of the weight each of the variables has in that function (or the discriminant loading of each variable). I’ll say a bit more about this in the section on discriminant analysis. Any ANOVA design can be performed as a MANOVA; in fact, factorial MANOVAs are quite common. A different set of discriminant functions is found for each main effect, as well as for the interactions. A significant two- Cohen_Chapter22.j.qxd 8/23/02 11:56 M Page 735 Section C • Optional Material way interaction might be followed by separate one-way MANOVAs (i.e., simple main effects), and a significant main effect in the absence of interaction might be followed by pairwise comparisons. However, even with a (relatively) simple one-way multigroup MANOVA, follow-up tests can get quite difficult to interpret when several discriminant functions are significant. For instance, if you redid the MANOVA for each pair of groups in the normals/neurotics/psychotics example, you would get a very different discriminant function in each case. The situation can get even more complex and difficult to interpret as the number of groups and variables increases. However, the most common way of following up a significant one-way MANOVA is with separate univariate ANOVAs for each DV. Then any significant univariate ANOVA can be followed up as described in Chapter 13. Of course, this method of following up a MANOVA is appropriate when you are not interested in multivariate relations and are simply trying to control Type I errors. With respect to this last point, bear in mind that following a significant MANOVA with separate tests for each DV involves a danger analogous to following a significant ANOVA with protected t tests. Just as adding one control or other kind of group that is radically different from the others (i.e., the complete null is not true) destroys the protection afforded by a significant ANOVA, adding one DV that clearly differentiates the groups (e.g., a manipulation check) can make the MANOVA significant and thus give you permission to test a series of DVs that may be essentially unaffected by the independent variable. All of the assumptions of MANOVA are analogous to assumptions with which you should already be familiar. First, the DVs should each be normally distributed in the population and together follow a multivariate normal distribution. For instance, if there are only two DVs, they should follow a bivariate normal distribution as described in Chapter 9 as the basis of the significance test for linear correlation. It is generally believed that a situation analogous to the central limit theorem for the univariate case applies to the multivariate case, so violations of multivariate normality are not serious when the sample size is fairly large. Unfortunately, as in the case of bivariate outliers, multivariate outliers can distort your results. Multivariate outliers can be found just as you would in the context of multiple regression (see Chapter 17, section B). Second, the DVs should have the same variance in every population being sampled (i.e., homogeneity of variance), and, in addition, the covariance of any pair of DVs should be the same in every population being sampled. The last part of this assumption is essentially the same as the requirement, described in Chapter 16, that pairs of RM levels in a mixed design have the same covariance at each level of the between-groups factor. In both cases, this assumption can be tested with Box’s M test but is generally not a problem when all of the groups are the same size. It is also assumed that no pair of DVs exhibits a curvilinear relation. These assumptions are also the basis of the procedure to be discussed next, discriminant analysis. Discriminant Analysis When a MANOVA is performed, the underlying discriminant functions are tested for significance, but the discriminant functions themselves are often ignored. Sometimes the standardized weight or the discriminant loading of each variable is inspected to characterize a discriminant function and better understand how the groups can be differentiated. Occasionally, it is appropriate to go a step further and use a discriminant function to “predict” an 735 Cohen_Chapter22.j.qxd 8/23/02 11:56 M Page 736 736 Chapter 22 • Three-Way ANOVA individual’s group membership; that procedure is called discriminant analysis. Discriminant analysis (DA) is to MANOVA as linear regression and prediction is to merely testing the significance of the linear relation between two variables. As in the case of MANOVA, DA is much simpler in the twogroup case, so that is where I’ll begin. In a typical two-group MANOVA situation you might be comparing right- and left-handers on a battery of cognitive tasks, especially those tasks known to be lateralized in the brain, to see if the two groups are significantly different. You want to see if handedness has an impact on cognitive functioning. The emphasis of discriminant analysis is different. In discriminant analysis you want to find a set of variables that differentiates the two groups as well as possible. You might start with a set of variables that seem likely to differ between the two groups and perform a stepwise discriminant analysis in which variables that contribute well to the discrimination (based on statistical tests) are retained and those which contribute little are dropped (this procedure is similar to stepwise regression, which is described in much detail in Chapter 17). The weights of the resulting standardized (i.e., variables are converted to z scores) discriminant function (also called a canonical variate because discriminant analysis is a special case of canonical correlation), if significant, can be compared to get an idea of which variables are doing the best job of differentiating the two groups. (The absolute sizes of the weights, but not their relation to one other, are arbitrary and are usually “normalized” so that the squared weights sum to 1.0). Unfortunately, highly correlated DVs can lead to unreliable and misleading relative weights, so an effort is generally made to combine similar variables or delete redundant ones. Depending on your purpose for performing a discriminant analysis, you may want to add a final step: classification. This is fairly straightforward in the two-group case. If you look again at Figure 22.17, you can see that the result of a discriminant analysis with two groups is to create a new dimension upon which each subject has a score. It is this dimension that tends to maximize the separation of the two groups while minimizing variability within groups (eta squared is maximized, which is the same in this case as R2, where R is both the canonical correlation and the coefficient of multiple correlation). This dimension can be used for classification by selecting a cutoff score; every subject below the cutoff score is classified as being in one group, whereas everyone above the cutoff is classified as being in the other group. The simplest way to choose a cutoff score is to halve the distance between the two group centroids. In Figure 22.17 this cutoff score results in two subjects being misclassified. The most common way to evaluate the success of a classification scheme is to calculate the rate of misclassification. If the populations represented by your two groups are unequal in size, or there is a greater cost for one type of classification error than the other (e.g., judging erroneously from a battery of tests that a child be placed in special education may have a different “cost” from erroneously denying special education to a child who needs it), the optimal cutoff score may not be in the middle. There are also alternative ways to make classifications, such as measuring the Mahalanobis distance between each subject and each of the two centroids. But, you may be wondering, why all this effort to classify subjects when you already know what group they are in? The first reason is that the rate of correct classification is one way of evaluating the success of your discriminant analysis. The second reason is analogous to linear regression. The regression equation is calculated for subjects for whom you know both X and Y scores, but it can be used to predict the Y scores for new subjects for whom you only have X scores. Similarly, the discriminant function and cutoff score for your present data can be used to classify future subjects whose correct group is Cohen_Chapter22.j.qxd 8/23/02 11:56 M Page 737 Section C • Optional Material 737 not known. For instance, you measure a sample of babies on a battery of perceptual tests, wait a few years until it is known which children have learning difficulties, and perform a discriminant analysis. Then new babies are tested and classified according to the results of the original study. If your misclassification rate is low, you can confidently recommend remedial measures for babies classified in the (future) learning disabled group and perhaps eliminate the disability before the child begins school. Of course, classification can also be used retroactively, for instance to classify early hominids as Neanderthal or Cro Magnon based on various skeletal measures (assuming there are some specimens you can be relatively sure about). With two significant discriminant functions and three groups, the centroids of the groups will not fall on one straight line, but they can be located on a plane formed by the two (orthogonal) discriminant functions. Figure 22.18 depicts the normals/neurotics/psychotics example; each discriminant function is named after the DV that carries the largest weight on it. Instead of a cutoff score, classification is made by assigning a region around each group, such that the regions are mutually exclusive and exhaustive (i.e., every subject must land in one, but only one, region). The regions displayed in Figure 22.18 form what is called a territorial map. Of course, it becomes impossible to draw the map in two dimensions as you increase the number of groups and the number of variables, but it is possible to extend the general principle of classification to any number of dimensions. Unfortunately, having several discriminant functions complicates the procedure for testing their significance, as discussed under the topic of MANOVA. Using MANOVA to Test Repeated Measures There is one more application of MANOVA that is becoming too popular to be ignored: MANOVA can be used as a replacement for the univariate oneway RM ANOVA. To understand how this is done, it will help to recall the direct-difference method for the matched t test. By creating difference scores, a two-sample test is converted to a one-sample test against the null hypothesis that the mean of the difference scores is zero in the population. Now sup- Inclination to Seek Psychotherapy Figure 22.18 High Centroid for Neurotics Orientation to Reality Low High Centroid for Psychotics Centroid for Normals Low A Territorial Map of Three Groups of Subjects Measured Along Two Discriminant Functions Cohen_Chapter22.j.qxd 8/23/02 11:56 M Page 738 738 Chapter 22 • Three-Way ANOVA pose that your RM factor has three levels (e.g., before, during, and after some treatment). You can create two sets of difference scores, such as beforeduring (BD), and during-after (DA). (The third difference score, before-after, would be exactly the same as the sum of the other two—because there are only two df, there can only be two sets of nonredundant difference scores.) Even though you now have two dependent variables, you can still perform a one-sample test to determine whether your difference scores differ significantly from zero. This can be accomplished by performing a one-sample MANOVA. The MANOVA procedure will “find” the weighted combination of BD and DA that produces a mean score as far from zero as possible. Finding the best weighted average of the difference scores sounds like an advantage over the ordinary RM ANOVA, which just deals with ordinary averages, and it can be—but you pay a price for the “customized” combinations of MANOVA. The price is a considerable loss of degrees of freedom in the error term. For a one-way RM ANOVA, dferror equals (n − 1)(P − 1), where n is the number of different subjects (or matched blocks), and P is the number of levels of the RM factor. If you perform the analysis as a one-sample MANOVA on P − 1 difference scores, dferror drops to n − P + 1 (try a few values for n and P, and you will notice the differences). In fact, you cannot use the MANOVA approach to RM analysis when the number of subjects is less than the number of RM levels (i.e., n < P); your error term won’t have any degrees of freedom. And when n is only slightly greater than P, the power of the MANOVA approach is usually less than the RM ANOVA. So, why is the MANOVA alternative strongly encouraged by many statisticians and becoming increasingly popular? Because MANOVA does not take a simple average of the variances of the possible difference scores and therefore does not assume that these variances are all the same (the sphericity assumption), the MANOVA approach is not vulnerable to the Type I error inflation that occurs with RM ANOVA when sphericity does not exist in the population. Of course, there are adjustments you can make to RM ANOVA, as you learned in Chapter 15, but now that MANOVA is so easy to use on RM designs (thanks to recent advances in statistical software), it is a reasonable alternative whenever your sample is fairly large. As I mentioned in Chapter 15, it is not an easy matter to determine which approach has greater power for fairly large samples and fairly large departures from sphericity. Consequently, it has been suggested that in such situations both procedures be routinely performed and the better of the two accepted in each case. This is a reasonable approach with respect to controlling Type I errors only if you use half of your alpha for each test (usually .025 for each), and you evaluate the RM ANOVA with the ε adjustment of the df. Complex MANOVA The MANOVA approach can be used with designs more complicated than the one-way RM ANOVA. For instance, in a two-way mixed design, MANOVA can be used to test the main effect of the RM factor, just as described for the oneway RM ANOVA. In addition, the interaction of the mixed design can be tested by forming the appropriate difference scores separately for each group of subjects and then using a two- or multigroup (i.e., one-way) MANOVA. A significant one-way MANOVA indicates that the groups differ in their level-to-level RM differences, which demonstrates a group by RM interaction. The MANOVA approach can also be extended to factorial RM ANOVAs (as described at the end of Section A in this chapter) and designs that are called doubly multivariate. The latter design is one in which a set of DVs is measured at several points in time or under several different conditions within the same subjects. Cohen_Chapter22.j.qxd 8/23/02 11:56 M Page 739 Section C • Optional Material 1. In the simplest form of multivariate analysis of variance (MANOVA) there are two independent groups of subjects measured on two dependent variables. The MANOVA procedure finds the weighted combination of the two DVs that yields the largest possible t value for comparing the two groups. The weighted combination of (two or more) DVs is called the discriminant function, and the t value that is based on it, when squared, is called Hotelling’s T2. 2. T2 can be converted into an F ratio for significance testing; the larger the number of DVs that contributed to T2, the more the F ratio is reduced before testing. The T2 value is a product of (half) the sample size, and an effect size measure like g (called the Mahalanobis distance), which measures the multivariate separation between the two groups. 3. When there are more than two independent groups, the T2 statistic is usually replaced by Wilks’ Λ, the ratio of error variability (i.e., SSW) to total variability (you generally want Λ to be small). However, when there are more than two groups and more than one DV, there is more than one discriminant function that can be found (the maximum number is one less than the number of groups or the number of DVs, whichever is smaller) and therefore more than one lambda to calculate. The most common way to test a MANOVA for significance is to pool the lambdas from all the possible discriminant functions and test the pooled Wilks’ Λ with an approximate F ratio (Pillai’s trace is a way of combining the lambdas that is more robust when the assumptions of MANOVA are violated). 4. When there are more than one discriminant function that can be found, the first one calculated is the one that produces the largest F ratio; this one is called the greatest characteristic root (gcr). An alternative to testing the pooled lambdas is to test only the gcr (usually with Roy’s test). The gcr test has an advantage when one of the discriminant functions is much larger than all of the others. If, in addition to finding out whether the groups differ significantly, you want to explore and interpret the discriminant functions, you can follow a significant gcr test by testing successively smaller discriminant functions until you come to one that is not significant. Alternatively, you can follow a significant test of the pooled lambdas by dropping the largest discriminant function, retesting, and continuing the process until the pooled lambda is no longer significant. 5. The most common use of MANOVA is to control Type I errors when testing several DVs in the same experiment; a significant MANOVA is then followed by univariate tests of each DV. However, if the DVs are virtually uncorrelated, or one of the DVs very obviously differs among the groups, it may be more legitimate (and powerful) to skip the MANOVA test and test all of the DVs separately, using the Bonferroni adjustment. Another use for MANOVA is to find combinations of DVs that discriminate the groups more efficiently than any one DV. In this case you want to avoid using DVs that are highly correlated because this will lead to unreliable discriminant functions. 6. If you want to use a set of DVs to predict which of several groups a particular subject is likely to belong to, you want to use a procedure called discriminant analysis (DA). DA finds discriminant functions, as in MANOVA, and then uses these functions to create territorial maps, regions based on combinations of the DVs that tend to maximally capture the groups. With only two groups, a cutoff score on a single discriminant function can be used to classify subjects as likely to belong to one group or the other (e.g., high school dropouts or graduates). To the extent that the groups tend to differ on the discriminant function, the rate of misclassification will be low, and the DA will be considered suc- 739 C SUMMARY Cohen_Chapter22.j.qxd 8/23/02 11:56 M Page 740 740 Chapter 22 • Three-Way ANOVA cessful. DA can also be used as a theoretical tool to understand how groups differ in complex ways involving several DVs simultaneously. 7. It may not be efficient or helpful to use all of the DVs you have available for a particular discriminant analysis. There are procedures, such as stepwise discriminant analysis, that help you systematically to find the subset of your DVs that does the best job of discriminating among your groups. These stepwise procedures are similar to the procedures for stepwise multiple regression. 8. The MANOVA procedure can be used as a substitute for the one-way RM ANOVA by forming difference scores (between pairs of RM levels) and then finding the weighted combination of these difference scores that best discriminates them from zero (the usual expectation under the null hypothesis). Because MANOVA does not require the sphericity assumption, the df does not have to be conservatively adjusted. However, in the process of “customizing” the combination of difference scores, MANOVA has fewer degrees of freedom available than the corresponding RM ANOVA [n − P + 1 for MANOVA, but (n − 1)(P − 1) for RM ANOVA]. MANOVA cannot be used in place of RM ANOVA when there are fewer subjects than treatment levels, and MANOVA is not recommended when the number of subjects is only slightly larger than the number of treatments. However, when the sample size is relatively large, MANOVA is likely to have more power than RM ANOVA, especially if the sphericity assumption does not seem to apply to your data. EXERCISES 1. In a two-group experiment, three dependent variables were combined to give a maximum t value of 3.8. a. What is the value of T 2? b. Assuming both groups contain 12 subjects each, test T 2 for significance. c. Find the Mahalanobis distance between these two groups. d. Recalculate parts b and c if the sizes of the two groups are 10 and 20. 2. In a two-group experiment, four dependent variables were combined to maximize the separation of the groups. SSbet = 55 and SSW = 200. a. What is the value of Λ? b. Assuming one group contains 20 subjects and the other 25 subjects, test Λ for significance. c. What is the value of T 2? d. Find the Mahalanobis distance between these two groups. 3. Nine men and nine women are tested on two different variables. In each case, the t test falls short of significance; t = 1.9 for the first DV, and 1.8 for the second. The correlation between the two DVs over all subjects is zero. a. What is the value of T 2? b. Find the Mahalanobis distance between these two groups. c. What is the value of Wilks’ Λ? d. Test T 2 for significance. Explain the advantage of using two variables rather than one to discriminate the two groups of subjects. 4. What is the maximum number of (orthogonal) discriminant functions that can be found when a. There are four groups and six dependent variables? b. There are three groups and eight dependent variables? c. There are seven groups and five dependent variables? 5. Suppose you have planned an experiment in which each of your 12 subjects is measured under six different conditions. a. What is the df for the error term if you perform a one-way RM ANOVA on your data? b. What is the df for the error term if you perform a MANOVA on your data? 6. Suppose you have planned an experiment in which each of your 20 subjects is measured under four different conditions. Cohen_Chapter22.j.qxd 8/23/02 11:56 M Page 741 Section C • Optional Material a. What is the df for the error term if you perform a one-way RM ANOVA on your data? b. What is the df for the error term if you perform a MANOVA on your data? The SS components for the interaction effects of the three-way ANOVA with independent groups. a. b. c. d. SSA × B = SSAB − SSA − SSB Formula 22.1 SSA × C = SSAC − SSA − SSC SSB × C = SSBC − SSB − SSC SSA × B × C = SSABC − SSA × B − SSB × C − SSA × C − SSA − SSB − SSC The df components for the three-way ANOVA with independent groups: a. b. c. d. e. f. g. h. dfA = a − 1 dfB = b − 1 dfC = c − 1 dfA × B = (a − 1)(b − 1) dfA × C = (a − 1)(c − 1) dfB × C = (b − 1)(c − 1) dfA × B × C = (a − 1)(b − 1)(c − 1) dfW = abc (n − 1) Formula 22.2 The SS for the between-groups error term of the three-way ANOVA with one RM factor: SSW = SSbet-S − SSAB Formula 22.3 The within-subjects portion of the total sums of squares in a three-way ANOVA with one RM factor: SSW − S = SStotal − SSbet-S Formula 22.4 The SS for the within-subjects error term of the three-way ANOVA with one RM factor: SSS × R = SSW − S − SSR − SSA × R − SSB × R − SSA × B × R Formula 22.5 The df components for the three-way ANOVA with one RM factor. a. b. c. d. e. f. g. h. i. dfA = a − 1 dfB = b − 1 dfA × B = (a − 1)(b − 1) dfR = c − 1 dfA × R = (a − 1)(c − 1) dfB × R = (b − 1)(c − 1) dfA × B × R = (a − 1)(b − 1)(c − 1) dfW = ab(n − 1) dfS × R = dfW × dfR = ab(n − 1)(c − 1) 741 Formula 22.6 KEY FORMULAS Cohen_Chapter22.j.qxd 8/23/02 11:56 M Page 742 742 Chapter 22 • Three-Way ANOVA The F ratios for the three-way ANOVA with one RM factor: a. MSA FA = MSW Formula 22.7 MSB b. FB = MSW c. MSA × B FA × B = MSW d. MSR FR = MSS × R e. MSA × R FA × R = MSS × R MSB × R f. FB × R = MSS × R g. MSA × B × R FA × B × R = MSS × R The SS for the between-groups error term of the three-way ANOVA with two RM factors: SSW = SSS − SSA Formula 22.8 The SS components for the within-subjects error terms of the three-way ANOVA with two RM factors: a. SSQ × S = SSQS − SSQ − SSS − SSA × Q Formula 22.9 b. SSR × S = SSRS − SSR − SSS − SSA × R c. SSQ × R × S = SStotal − SSAQR − SSW − SSQ × S − SSR × S The df components for the three-way ANOVA with two RM factors: a. b. c. d. e. f. g. h. i. j. k. dfA = a − 1 dfQ = q − 1 dfR = r − 1 dfA × Q = (a − 1)(q − 1) dfA × R = (a − 1)(r − 1) dfQ × R = (q − 1)(r − 1) dfA × Q × R = (a − 1)(q − 1)(r − 1) dfW = a(n − 1) dfQ × S = dfQ × dfW = a(q − 1)(n − 1) dfR × S = dfR × dfW = a(r − 1)(n − 1) dfQ × R × S = dfQ × dfR × dfW = a(q − 1)(r − 1)(n − 1) Formula 22.10 Cohen_Chapter22.j.qxd 8/23/02 11:56 M Page 743 Key Formulas • Optional Material The F ratios for the three-way ANOVA with two RM factors: a. MSA FA = MSW b. MSQ FQ = MSQ × S c. MSR FR = MSR × S Formula 22.11 MSA × Q d. FA × Q = MSQ × S e. MSA × R FA × R = MSR × S f. MSQ × R FQ × R = MSQ × R × S g. MSA × Q × R FA × Q × R = MSQ × R × S The F ratio for testing the significance of T2 calculated for P dependent variables and two independent groups: n1 + n2 − P − 1 F = T2 P(n1 + n2 − 2) Formula 22.12 The F ratio for testing the significance of Wilks’ lambda calculated for P dependent variables and two independent groups: 1 − Λ n1 + n2 − P − 1 F = Λ P Formula 22.13 743 Cohen_Chapter22.j.qxd 8/23/02 11:56 M Page 744 744 Chapter 22 • Three-Way ANOVA REFERENCES Banaji, M. R., & Hardin, C. D. (1996). Automatic stereotyping. Psychological Science, 7, 136–141. Bruder, G. E., Stewart, J. W., Mercier, M. A., Agosti, V., Leite, P., Donovan, S., & Quitkin, F. M. (1997). Outcome of cognitive-behavioral therapy for depression: Relation to hemispheric dominance for verbal processing. Journal of Abnormal Psychology, 106, 138–144. Cole, D. A., Maxwell, S. E., Arvey, R., & Salas, E. (1994). How the power of MANOVA can both increase and decrease as a function of the intercorrelations among the dependent variables. Psychological Bulletin, 115, 465–474. Harris, R. J. (1985). A primer of multivariate statistics (2nd ed.). Orlando, Florida: Academic Press. Hays, W. L. (1994). Statistics (5th ed.). New York: Harcourt Brace College Publishing. Huynh, H., & Mandeville, G. K. (1979). Validity conditions in repeated measures designs. Psychological Bulletin, 86, 964–973. Marlowe, C. M., Schneider, S. L., & Nelson, C. E. (1996). Gender and attractiveness biases in hiring decisions: Are more experienced managers less biased? Journal of Applied Psychology, 81, 11–21. Cohen_Chapter22.j.qxd 8/23/02 11:56 M Page 745 Appendix • Answers to the Odd-Numbered Exercises 745 CHAPTER 22 d) For Fyear and Fsize × year, conservative F.05 (1, 18) = 4.41; for Fsystem × year and Fsize × system × year, conservative F.05 (2, 18) = 3.55. All of the conclusions involving RM factors will be affected by not assuming that sphericity holds, as none of these tests are significant at the .05 level once df’s are adjusted by lower-bound epsilon. It is recommended that conclusions be determined after adjusting df’s with an exact epsilon calculated by statistical software. Section A 1. a & b) Femotion = 74.37/14.3 = 5.2, p < .01, η = .122 Frelax = 64.4/14.3 = 4.5, p < .05, η2 = .039 Fdark = 31.6/14.3 = 2.21, n.s. , η2 = .019 Femo × rel = 55.77/14.3 = 3.9, p < .05, η2 = .095 Femo × dark = 17.17/14.3 = 1.2, n.s, η2 = .031. Frel × dark = 127.3/14.3 = 8.9, p < .01, η2 = .074 Femo × rel × dark = 25.73/14.3 = 1.8, n.s., η2 = .046 2 Assuming that a moderate effect size is about .06 (or 6%), the main effect of emotion is more than moderate, as are the two-way interactions of emotion × relaxation and relaxation × dark. 3. a) Source Drug Therapy Depression Drug × Therapy Therapy × Depression Drug × Depression Drug × Therapy × Depress Within-groups SS 496.8 32.28 36.55 384.15 df MS 3 165.6 2 16.14 1 6.55 6 64.03 F p 60.65 5.91 13.4 23.45 < .001 < .01 < .01 < .001 31.89 2 15.95 5.84 < .05 20.26 3 6.75 2.47 n.s. 10.2 131 6 48 1.7 2.73 .62 n.s. Section B 1. a) Fstyle = 25.2/3.5 = 7.2, p < .01 Fspeaker = 12.9/3.5 = 3.69, n.s. Fissue = 3.53/2.2 = 1.6, n.s. Fstyle × speaker = 10.5/3.5 = 3.0, n.s. Fstyle × issue = 12.1/2.2 = 5.5, p < .01 Fspeaker × issue = 1.767/2.2 = .80, n.s. Fstyle × speaker × issue = 2.417/2.2 = 1.1, n.s. 3. b) For Fissue and Fspeaker × issue, conservative F.05 (1, 54) = 4.01; for Fstyle × issue and Fstyle × speaker × issue, conservative F.05 (2, 54) = 4.01. None of the conclusions involving RM factors will be affected. a) Source b) Although there are some small differences between the two graphs, indicating that the threeway interaction is not zero, the two graphs are quite similar. This similarity suggests that the three-way interaction is not large, and is probably not significant. This observation is consistent with the F ratio being less than 1.0 for the three-way interaction in this example. c) You could begin by exploring the large drug by therapy interaction , perhaps by looking at the simple effect of therapy for each drug. Then you could explore the therapy by depression interaction , perhaps by looking at the simple effect of depression for each type of therapy. d) L = [(11.5 − 8.7) − (11 − 14) ] − [ (19 − 14.5) − (12 − 10) ] = [2.8 − (-3)] − [4.5 − 2] = 5.8 − 2.5 = 3.3; SScontrast = nL2 / Σc2 = 3 (3.3)2 / 8 = 32.67 / 8 = 4.08375; Fcontrast = 4.08375 / 2.73 = 1.5 (not significant, but better than the overall three-way interaction). 5. a) Fdiet = 201.55 / 29.57 = 6.82, p < .05 Ftime = 105.6 / 11.61 = 9.1, p < .01 Fdiet × time = 8.67 / 7.67 = 1.13, n.s. b) conservative F.05 (1, 5) = 6.61; given the usual .05 criterion, none of the three conclusions will be affected (the main effect of time is no longer significant at the .01 level, but it is still significant at the .05 level). Between-Subjects Size System Size × System Within-groups Within-Subjects Year Size × Year System × Year Size × System × Year Subject × Year SS df MS 21.1 1 21.1 61.6 2 30.8 1.75 2 .88 52.1 18 2.89 F p 7.29 10.65 .30 <.05 <.01 >.05 4.36 4.70 6.17 3 3 6 1.46 1.57 1.03 2.89 3.11 2.04 <.05 <.05 >.05 9.83 27.19 6 54 1.64 .50 3.26 <.01 b) You can see that the line for the new system is generally the highest (if you are plotting by year), the line for the old system is lowest, and the combination is in between, producing a main effect of system. The lines are generally higher for the large school, producing a main effect of size. However, the ordering of the systems is the same regardless of size, so there is very little size by system interaction. Ratings generally go up over the years, producing a main effect of year. However, the ratings are aberrantly high for the first year in the large school, producing a size by year, as well as a threeway interaction. One partial interaction would result from averaging the new and combined system and comparing to the old system across the other intact factors. Cohen_Chapter22.j.qxd 8/23/02 11:56 M Page 746 Chapter 22 • Three-Way ANOVA 746 image lines are clearly and consistently separate. You can see some affect by image interaction in that the lines are not parallel, especially due to the medium line. There is a noticeable background by affect interaction, because for the happy music condition, recall of happy words is higher, whereas sad word recall is higher during the sad background music. The main effect of affect is not obvious with affect plotted on the horizontal axis. The medium/low (or high/low) by sad/neutral by background contrast appears to be one of the largest of the possible 2 × 2 × 2 interaction contrasts. d) The three-way interaction is not significant, so the focus shifts to the two significant two-way interactions: affect by image and affect by background. Averaging across the imageability levels, one could look at the simple effects of affect for each type of background music; averaging across the background levels, one could look at the simple effects of affect for each level of imageability. Significant simple effects can then be followed by appropriate pairwise comparisons. There are other legitimate possibilities, as well. c) Given the significant three-way interaction, it would be reasonable to look at simple interaction effects—perhaps, the system by year interaction for each school size. This two-way interaction would likely be significant only for the large school, and would then be followed by testing the simple main effects of year for each system. To be cautious about sphericity, you can use an error term based only on the conditions included in that follow-up test. There are other legitimate possibilities for exploring simple effects, as well. 5. a) Source Between-groups Background Within-group Within-subjects Affect Background × Affect Subject × Affect Image Background × Image Subject × Image Affect × Image Back × Affect × Image Subject × Affect × Image SS df MS F p .93 42.85 1 10 .93 4.29 .22 n.s. 13.72 2 6.86 7.04 <.01 19.02 2 9.51 9.76 <.01 19.48 20 .97 131.06 2 65.53 .24 2 .12 25.59 20 1.28 18.39 4 4.60 4.71 <.01 2.32 4 .58 .59 n.s. 39.07 40 .98 51.21 <.001 Section C .09 n.s. b) The conservative F.05 (1, 10) = 4.96 for all of the F’s involving an RM factor (i.e., all F’s except the main effect of background music). The F for the affect by image interaction is no longer significant with a conservative adjustment to df; a more exact adjustment of df is recommended in this case. None of the other conclusions are affected (except that the main effect of affect and its interaction with background music are significant at the .05, instead of .01 level after the conservative adjustment). c) If you plot affect on the X axis, you can see a large main effect of image, because the three 1. a) T 2 = 3.82 = 14.44 b) F = 14.44 * (24 − 3 − 1) / 3 (22) = 4.376 > F.05 (3, 20) = 3.1, so T 2 is significant at the .05 level. c) MD 2 = T 2 /n/2 = 14.44/6 = 2.407; MD = 1.55 d) F = 14.44 * (30 − 3 − 1)/3 (28) = 4.47; harmonic mean of 10 and 20 = 13.33, MD 2 = 14.44/13.33/2 = 2.167; MD = 1.47 3. a) R2 (the sum of the two rpb2’s) = .184 + .168 = .352; T 2 = 16 * [.352/(1 − .352)] = 8.69 b) MD 2 = 8.69/4.5 = 1.93; MD = 1.39 c) Λ = 16/(8.69 + 16) = .648 d) F = (15/32) * 8.69 = 4.07 > F.05 (2, 15) = 3.68, so T 2 is significant at the .05 level. As in multiple regression with uncorrelated predictors, each DV captures a different part of the variance between the two groups; together the two DV’s account for much more variance than either one alone. 5. a) df = (6 − 1) (12 − 1) = 5 * 11 = 55 b) df = 12 − 6 + 1 = 7