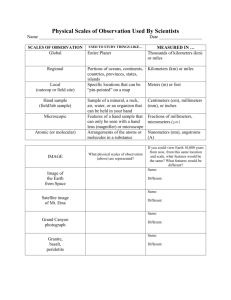
Methods Organizational Research
advertisement

Organizational Research Methods http://orm.sagepub.com/ Using Mixed-Model Item Response Theory to Analyze Organizational Survey Responses: An Illustration Using the Job Descriptive Index Nathan T. Carter, Dev K. Dalal, Christopher J. Lake, Bing C. Lin and Michael J. Zickar Organizational Research Methods 2011 14: 116 originally published online 26 April 2010 DOI: 10.1177/1094428110363309 The online version of this article can be found at: http://orm.sagepub.com/content/14/1/116 Published by: http://www.sagepublications.com On behalf of: The Research Methods Division of The Academy of Management Additional services and information for Organizational Research Methods can be found at: Email Alerts: http://orm.sagepub.com/cgi/alerts Subscriptions: http://orm.sagepub.com/subscriptions Reprints: http://www.sagepub.com/journalsReprints.nav Permissions: http://www.sagepub.com/journalsPermissions.nav Citations: http://orm.sagepub.com/content/14/1/116.refs.html >> Version of Record - Dec 10, 2010 OnlineFirst Version of Record - Apr 26, 2010 What is This? Downloaded from orm.sagepub.com at Hong Kong Inst of Education Library on March 20, 2012 Using Mixed-Model Item Response Theory to Analyze Organizational Survey Responses: An Illustration Using the Job Descriptive Index Organizational Research Methods 14(1) 116-146 ª The Author(s) 2011 Reprints and permission: sagepub.com/journalsPermissions.nav DOI: 10.1177/1094428110363309 http://orm.sagepub.com Nathan T. Carter1, Dev K. Dalal1, Christopher J. Lake1, Bing C. Lin1,2, and Michael J. Zickar1 Abstract In this article, the authors illustrate the use of mixed-model item response theory (MM-IRT) and explain its usefulness for analyzing organizational surveys. The authors begin by giving an overview of MM-IRT, focusing on both technical aspects and previous organizational applications. Guidance is provided on how researchers can use MM-IRT to check scoring assumptions, identify the influence of systematic responding that is unrelated to item content (i.e., response sets), and evaluate individual and group difference variables as predictors of class membership. After summarizing the current body of research using MM-IRT to address problems relevant to organizational researchers, the authors present an illustration of the use of MM-IRT with the Job Descriptive Index (JDI), focusing on the use of the ‘‘?’’ response option. Three classes emerged, one most likely to respond in the positive direction, one most likely to respond in the negative direction, and another most likely to use the ‘‘?’’ response. Trust in management, job tenure, age, race, and sex were considered as correlates of class membership. Results are discussed in terms of the applicability of MM-IRT and future research endeavors. Keywords item response theory, latent class analysis, invariance testing Item response theory (IRT) models have played a large role in organizational researchers’ understanding regarding measures of a variety of domains, including job attitudes (e.g., Collins, Raju, & Edwards, 2000; Donovan, Drasgow, & Probst, 2000; Wang & Russell, 2005), personality 1 2 Bowling Green State University, OH, USA Department of Psychology, College of Arts and Sciences, Portland State University, OR, USA Corresponding Author: Nathan T. Carter, Department of Psychology, Bowling Green State University, 214 Psychology Building, Bowling Green, OH 43402, USA Email: ntcarte@bgsu.edu 116 Downloaded from orm.sagepub.com at Hong Kong Inst of Education Library on March 20, 2012 Carter et al. 117 (e.g., Chernyshenko, Stark, Chan, Drasgow, & Williams, 2001; Zickar, 2001; Zickar & Robie, 1999), general mental ability (e.g., Chan, Drasgow, & Sawin, 1999), performance ratings (e.g., Maurer, Raju, & Collins, 1998), vocational interests (e.g., Tay, Drasgow, Rounds, & Williams, 2009), and employee opinions (e.g., Ryan, Horvath, Ployhart, Schmitt, & Slade, 2000). Recent extensions of IRT models provide increased flexibility in the questions researchers and practitioners may ask about the response–trait relationship in organizational surveys. In this article, we explain how organizational survey data can be analyzed using mixed- (or mixture-) model IRT (MM-IRT). MM-IRT combines features of traditional IRT models (e.g., the partial credit model [PCM]) and latent class analysis (LCA; see Lazarsfeld & Henry, 1968) and identifies subgroups of respondents for whom the item response–latent variable relationships indicated by the item response functions (IRFs) are considerably different. Here, we explain the technical features of MM-IRT and discuss some of its potential uses, including checking scoring assumptions, identifying systematic responding, and evaluating potential correlates of class membership. We then illustrate the use of MM-IRT by applying the framework to answer some fundamental questions about the measurement properties of the Job Descriptive Index (JDI; Balzer et al., 1997; Smith, Kendall, & Hulin, 1969), a commercially available survey that measures facets of job satisfaction with five separate scales measuring persons’ satisfaction with their work, coworkers, supervision, pay, and opportunities for promotions (9 items). Our discussion and results are presented in concert with Table 1 that outlines the process from beginning to end that a researcher would use when conducting an MM-IRT analysis. We first show how these steps are accomplished and then how we address each of these steps in our analysis of the JDI. The JDI was chosen for this illustration for several reasons. First, it has consistently been found to be one of the most frequently used measures of job satisfaction (see Bowling, Hendricks, & Wagner, 2008; Connolly & Viswesvaran, 2000; Cooper-Hakim & Viswesvaran, 2005; Judge, Heller, & Mount, 2002). In fact, the JDI Office at Bowling Green State University continues to acquire around 150 data-sharing agreements per year (J. Z. Gillespie, personal communication, October 28, 2009). In addition, the JDI’s ‘‘Yes,’’ ‘‘No,’’ ‘‘?’’ response format has been examined with conventional IRT analyses (e.g., Hanisch, 1992), and measures using similar response scales (i.e., ‘‘Yes,’’ ‘‘No,’’ ‘‘?’’) have been investigated in past MM-IRT research (e.g., Hernandez, Drasgow, & Gonzalez-Roma, 2004). In sum, the JDI provided a well-known measure with properties that have been of interest in the past and in the current research and application, allowing for an accessible and substantively interesting measure for the illustrative MM-IRT analyses. An Introduction to Mixed-Model IRT IRT is essentially a collection of formulated models that attempt to describe the relationship between observed item responses and latent variables (e.g., attitude, personality, and interests). The IRFs of IRT are logistic regressions that start with observed responses and use conditional probabilities of responding to an item in a particular way (e.g., strongly agree) to find an appropriate transformation of the sum score to represent the underlying or latent variable. Additionally, the models parameterize different properties of items (depending on the model) that are on a scale common to the estimates of persons’ standing on the latent variable. Although any number of item properties could be included, IRT models are generally concerned with the location and discrimination of items. The item’s location reflects its difficulty (in an ability context) or extremity (in attitudes or personality). In situations where items have more than two options, the item’s location is often quantified by threshold parameters. Thresholds represent the point on the latent variable continuum at which the probability of responding to one option becomes greater than choosing another; thus, there will be one less threshold parameter than there are options. Generally, the average of these thresholds can be considered an estimate of the item’s location. An item’s discrimination is a reflection of 117 Downloaded from orm.sagepub.com at Hong Kong Inst of Education Library on March 20, 2012 118 Organizational Research Methods 14(1) its sensitivity to variability in the latent variable. Discrimination parameters are typically quantified as the regression line’s slope at the point of the item’s location on the trait continuum. IRT models are advantageous for several reasons. Most pertinent to this article is that they place persons and items on a common scale, providing measurement researchers an appropriate framework for determining whether group differences in observed sum scores are likely to be due to differences on the latent variable or for other, extraneous reasons, such as membership to a protected class, response sets, or individual differences other than what the researcher is attempting to measure.1 Conventional IRT models assume that item responses are drawn from one homogenous subpopulation. This implies that one set of IRFs can be used to describe the relationship between item responses and the latent trait. However, it may be plausible that there are subgroups of respondents with different response–trait relationships; in other words, more than one set of item parameters may be needed to model item responding. In fact, it has been noted that such heterogeneity can be expected in situations where the studied population is complex (von Davier, Rost, & Carstensen, 2007), which organizational researchers are likely to encounter. Typically, researchers examine the viability of the homogenous subpopulation assumption by conducting differential item functioning (DIF) analyses based on important manifest group variables. For organizational researchers, these groups are typically based on legally, ethically, or practically important manifest variables such as respondent sex and race. However, it is possible that differences in the response–trait relationship are better described by latent groupings that may or may not correspond to the previously mentioned observed variables. These unobserved groups may exist for a variety of reasons, including differential endorsement strategies and comparison processes that may result from different sociocultural experiences (Rost, 1997). MM-IRT identifies unobservable groups of respondents with different response–trait relationships, in effect an exploratory method of DIF detection wherein subgroups are identified a posteriori (Mislevy & Huang, 2007). In the following sections, we provide a general definition of MM-IRT and discuss the estimation of item and person parameters under the Rasch family of models. We focus here on the use of Rasch-based IRT models because these are the models available in the WINMIRA program (von Davier, 2001), a user-friendly software program that can be used by researchers to conduct such analyses without the more intensive programming involved when estimating other mixed IRT models. MM-IRT Model Definition As noted above, MM-IRT is a hybrid of IRT and LCA, which uncovers unobservable groups whose item parameters, and therein IRFs, differ substantially. The most general form of the LCA model can be written: PðuÞ ¼ G X pg PðujgÞ; ð1Þ g¼1 where P(u) denotes the probability of a vector of observed responses, u ¼ x1, x2, . . . , xi. The term P(u|g) denotes the probability of the response vector within an unobservable group, g, of the size, p. The p parameter, also called the mixing proportions parameter, is used to represent the proportion of respondents belonging to the gth group and carries the assumption: G X pg ¼ 1; g¼1 that is, the summation across the proportion parameter estimates must be equal to 1. 118 Downloaded from orm.sagepub.com at Hong Kong Inst of Education Library on March 20, 2012 ð2Þ Carter et al. 119 The conditional probability of observed responses within a group, P(u|g), can be replaced by any number of conventional dichotomous or polytomous IRT models, assuming that the basic form of the model holds across groups with a different set of values for the IRT model’s parameters. Here, we focus on the use of the PCM (Masters, 1982), which is stated: expðhyj sih Þ ; for h ¼ 0; 1; 2 . . . m; M P expðsyj sis Þ PðUij ¼ hÞ ¼ ð3Þ s¼0 or that the probability of person j responding h to an item, i, is determined by the distance between person j’s standing on the latent trait, y, and the sum of the h option thresholds for the s ¼ h þ 1 possible observed response options: sih ¼ h X tig ; with si0 ¼ 0: ð4Þ s¼1 The option location parameter, tis, is the location of the threshold, s, on the scale of y for the ith item. This IRT model assumes that there is one latent population of respondents who use the same response process (i.e., who use scales similarly). Note that the s term here is simply a counting variable for purposes of summation that corresponds to the levels of h. The PCM is a polytomous Rasch model and therefore assumes equal discriminations across items, whereas other polytomous IRT models do not (e.g., the graded response model). Although Rasch models often have worse fit than models that allow item discriminations to vary (see Maijde Meij, 2008), the WINMIRA program uses only Rasch-based measurement models. Estimation is much easier using the simple Rasch models because of the exclusion of multiplicative parameter terms (Rost, 1997). Although we hope that commercially available user-friendly software will someday incorporate more complex models, we proceeded cautiously with the Rasch-based PCM, paying careful attention to item-level fit to test whether the model was tenable for our data. Other researchers using attitudinal (Eid & Rauber, 2000) and personality data (Hernandez et al., 2004; Zickar, Gibby, & Robie, 2004) have found acceptable fit using similar models. Although we focus on the Rasch models available in WINMIRA, it should be noted that our discussion of MM-IRT generalizes easily to IRT models that allow for discrimination to vary. However, doing so requires more extensive programming experience using a more complex program such as LatentGOLD 4.5 (Vermunt & Magidson, 2005). The mixed PCM (MPCM) is obtained by substituting the IRF (Equation 3) in place of the P(u|g) term2 in Equation 1, or PðUij ¼ hÞ ¼ G X g¼1 pg h X expðhyjg sihg Þ ; with s ¼ tisg : ihg M P s¼1 expðsyjg sisg Þ ð5Þ s¼0 According to this model, each person and item have as many sets of relevant parameters as there are groups; so in a 3-class solution, each person will have three estimates of y, and each item will have three times the number of item parameters in the single-group version of the PCM. The item and group-proportion parameters are estimated simultaneously using an extended expectation-maximization (EM) algorithm, using conditional maximum likelihood in the maximization step. Because the sum score can be considered a sufficient estimate of y in Rasch models, the trait estimate is not involved in the EM procedure. The y estimates are obtained using the item and group-proportion parameters established in the EM procedure and then are estimated by setting the observed total score equal to the right-hand side of the model in Equation 5 and solving for y 119 Downloaded from orm.sagepub.com at Hong Kong Inst of Education Library on March 20, 2012 120 Organizational Research Methods 14(1) iteratively. This is an important point, because this means y for person j in one group will not differ greatly from their estimate in another group; this is because estimation of y is based on the observed sum score, which is the same for a given person, j, across groups (Rost, 1997). The researcher using MM-IRT need only to specify the number of subpopulations believed to underlie what would typically be considered data coming from one homogenous subpopulation. First, a 1-class model is fit, then a 2-class model, a 3-class model, and so on. Once an increase in the number of classes no longer shows an increase in model-data fit, the models are compared and the best fitting is retained for further analysis. Identifying the latent class structure and therein unmixing groups with different response–trait relationships nested within the 1-class model, the researcher can ask both practically and theoretically interesting questions. In the following section, we show some past uses of MM-IRT in organizational research before presenting our illustration using the JDI. Applications of MM-IRT in Organizational Research In the first application of MM-IRT to organizational research, Eid and Rauber (2000) found two distinct response styles in a measure of organizational leadership satisfaction—one class that made use of the whole response scale and one that preferred extreme responses. These authors found that length of service and level within the organization explained group membership, suggesting usage of the entire response scale may be too complex or too time-consuming, and that certain employees may be more prone to use global judgments such as ‘‘good’’ and ‘‘bad.’’ Additionally, a larger percentage of females belonged to the second class compared to males. Zickar et al. (2004) examined faking in two personality inventories. In their first analysis, Zickar and colleagues applied MM-IRT to an organizational personality inventory (Personal Preferences Inventory; Personnel Decisions International, 1997) with subscales mapping onto the Big 5, and found three classes of respondents for each of the five dimensions of the personality inventory, with the exception of the Neuroticism subscale extracting four classes. In general, results suggested that there were likely three extents of faking: no faking, slight faking, and extreme faking. In their second analysis, the authors applied MM-IRT to a personality inventory (Assessment of Background and Life events; White, Nord, Mael, & Young, 1993) in a sample of military personnel. Prior to survey administration, the authors placed respondents in honest, ad lib faking, and trained faking conditions. Results suggested two response classes for each of these conditions: A faking and an honest class. Interestingly, 7.2% to 22.9% of respondents in the honest condition were placed in the faking class, 27.2% to 41.6% of participants in the coached faking condition were placed in the honest class, reflecting the inherent complexity and high variability in personality test faking. Finally, in a study of measures of extraversion and neuroticism in the Amsterdam Biographical Questionnaire (ABQ; Wilde, 1970), Maij-de Meij, Kelderman, and van der Flier (2008) found that a 3-class solution best fit the data for each scale. The classes were differentiated by the probability of using each of the ‘‘Yes,’’ ‘‘No,’’ and ‘‘?’’ responses. Participants also completed a measure of social desirability as part of the ABQ, and scores on social desirability and ethnic background had significant effects on class membership. Results from this study suggest that personality measure scores from ethnically diverse and high-stakes contexts must be interpreted with caution, as there were strong effects of ethnicity and social desirability on response class membership. Although the analyses discussed above provide valuable insight into the use of MM-IRT in organizational research, a straightforward illustrative application of MM-IRT involving attitudinal surveys is not available in the current literature. Hernandez et al. (2004) provided a thorough investigation of personality questionnaires, and Eid & Rauber (2000) investigated the use of a satisfaction questionnaire. However, their discussion considered the case of a 2-class solution in regard to predicting class membership, which has recently been noted as possibly too restrictive (Maij-de Meij 120 Downloaded from orm.sagepub.com at Hong Kong Inst of Education Library on March 20, 2012 Carter et al. 121 et al., 2008), and use of solutions with more than two classes requires the use of different analytic techniques and considerations. Additionally, some unique issues related to the use of Rasch models have not seen coverage in the literature on MM-IRT. In this illustration, we intend to address these as yet unattended issues, providing a fairly comprehensive illustration of the use of the method in organizational research. Background to the Illustration: The JDI and Similar Scales Before presenting our own illustration of MM-IRT analysis using the JDI, we begin by briefly reviewing the background of the measure and its typical assumptions for scoring to inform the interpretation of results. In addition, we review MM-IRT research analyzing measures using a ‘‘Yes,’’ ‘‘No,’’ and ‘‘?’’ response format. We then proceed with our analyses, discussing our use of the technique to (a) identify and assess the fit of the appropriate model; (b) qualify the latent classes, (c) check scoring assumptions, (d) examine the possibility of systematic response styles, and (e) examine relevant individual difference and group membership variables as a reason for the latent class structure. Step 1: Background Review of the JDI and Similar Scales Originally, Smith et al. (1969) scored the items in the five JDI scales as follows: ‘‘Yes’’ ¼ 3, ‘‘?’’ ¼ 2, and ‘‘No’’ ¼ 1. Taking data from 236 persons responding to the Work scale, they split the sample into ‘‘satisfied’’ and ‘‘dissatisfied’’ groups and found that dissatisfied persons tended to have significantly more ‘‘?’’ responses than those in the satisfied group. This led them to recommend the currently used asymmetric scoring scheme of 3 (Yes), 1 (?), and 0 (No) because the data suggested the ‘‘?’’ response was more likely to be associated with dissatisfied than satisfied persons (Balzer et al., 1997). Hanisch (1992) evaluated the viability of the Smith et al. (1969) scoring procedure using Bock’s (1972) nominal IRT model. In observing option response functions (ORFs), it was clear that the intervals between options were not equidistant, suggesting that the ‘‘Yes’’ option was well above ‘‘?’’ and ‘‘No’’ on the trait continuum and that those moderately low in y were more likely to endorse the ‘‘?’’ response, thus verifying the original scoring by Smith et al. One of the limitations of the nominal IRT model used by Hanisch is that it assumes that all respondents use the same type of response process when answering items. It may be possible, however, that even though a majority of individuals interpret the ‘‘?’’ response option as a neutral response, there are others who interpret this ambiguous option in other ways. MM-IRT will allow us to further probe how different groups of respondents interpret and use the ‘‘?’’ option. Expectations concerning class structure. Due to our review of measures using response anchors similar to the JDI, we were particularly concerned with the use of the ‘‘?’’ option. Although the research concerning the ‘‘?’’ response of the JDI have been mostly supportive of the common conceptualization of the ‘‘?’’ response as being between ‘‘Yes’’ and ‘‘No’’ responses (e.g., Hanisch, 1992; Smith et al., 1969), other researchers have shown less confidence about this assumption in the analyses of other scales (e.g., Bock & Jones, 1968; Dubois & Burns, 1975; Goldberg, 1971; Hernandez et al., 2004; Kaplan, 1972; Worthy, 1969). To date, the research available using MM-IRT to investigate the use of ‘‘?’’ have agreed with the latter group of researchers (see Hernandez et al., 2004; Maijde Meij et al., 2008; Smit, Kelderman, & van der Flier, 2003), finding that the vast majority avoid the ‘‘?’’ response. Thus, we hypothesize (Hypothesis 1) that a class will be identified that has a higher probability of using the ‘‘?’’and that the remaining classes will avoid the ‘‘?’’ response (Hernandez et al., 2004; Maij-de Meij et al., 2008; Smit et al., 2003). 121 Downloaded from orm.sagepub.com at Hong Kong Inst of Education Library on March 20, 2012 122 Organizational Research Methods 14(1) Eid and Zickar (2007) noted that latent classes can also uncover groups of respondents that are ‘‘yea-sayers’’ and ‘‘nay-sayers’’, which use one end of the scale regardless of item content (Hernandez et al., 2004; Maij-de Meij et al., 2008; Reise & Gomel, 1995; Smit et al., 2003). Thus, we expected that the persons who avoid the ‘‘?’’ response would constitute extreme responders, manifested in either one class using only extremes, or two classes, each preferring one of the two extremes (i.e., ‘‘Yes’’ or ‘‘No’’) over other options. Because there was some inconsistency in the past research concerning the division of extreme respondents, we do not formulate formal hypotheses concerning the expected number of classes. Expectations concerning systematic responding. Concerning consistency of classification across scales, we found only one study by Hernandez et al. (2004) that directly addressed this issue. These researchers found only moderate consistency in class membership across the 16 PF, as indicated by the average size of phi correlations between class membership in every scale, M ¼ .39, SD ¼ .04, most of which was due to the largest class. That is, even though for one of the scales, a respondent might be in the class that uses the ‘‘?’’ frequently, did not mean that the same person was placed in the same class for other scales. We postulated that (Hypothesis 2) respondents will be classified into a particular class across the 5 JDI scales with moderate consistency. Support for this hypothesis would suggest that although latent class membership is to some extent determined by a specific response style, it is by no means the only possible consideration. Checking scoring assumptions. Although there is some available research using MM-IRT to evaluate scoring assumptions of scales using the ‘‘?’’ option, we believe this literature is not so established that these findings can be generalized across scales. In this investigation, we will be using the MPCM to examine the viability of the assumption that ‘‘?’’ falls between the ‘‘Yes’’ and ‘‘No’’ response options and therein whether summing across options is an appropriate scoring algorithm. The Rasch models are especially useful for examining the viability of this assumption due to the additivity property of Rasch models (Rost, 1991). This property implies that if the total score does not hold as a meaningful additive trait representation one potential consequence is the disordering of item threshold estimates (Andrich, 2005; Rost, 1991). Take the example of measuring perceived length and relating it to physical length of rods: If additivity holds, a 10-foot rod will be judged as longer than a 5-foot rod; if additivity does not hold, there will be a considerable number of persons judging the 5-foot rod as longer than the 10-foot rod. Correlates of class membership. In addition to the above hypotheses, we were also interested in identifying variables that could explain respondents’ classification into the subpopulation that does not avoid the ‘‘?’’ response. Hernandez et al. (2004) noted that ‘‘Other factors have been suggested (Cruickshank, 1984; Dubois & Burns, 1975; Worthy, 1969) . . . ’’ for respondents’ choice of ‘‘?’’ other than representing a point on the trait continuum between ‘‘Yes’’ and ‘‘No,’’ noting it is possible that respondents ‘‘ . . . (a) have a specific response style, (b) do not understand the statement, (c) do not feel competent enough or sufficiently informed to take a position, or (d) do not want to reveal their personal feelings about the question asked’’ (p. 688). Although Hypothesis 2 above addresses the question of response style influence are the reason for classification, the remaining points should also be addressed. We identified variables to explore in the available data set to address points (c) and (d): job tenure (JT) and trust in management (TIM), respectively. Unfortunately, as will be discussed later, we did not have data available to evaluate point (b), that comprehension drives the decision to use or not use the ‘‘?’’ response. JT was used as an approximation of the idea of Hernandez and colleagues (2004) that those using the ‘‘?’’ response ‘‘ . . . do not feel competent enough or sufficiently informed to take a position’’ (p. 688). Although knowledge concerning the job is variable among new employees, knowledge regarding its domains can be expected to increase during an employee’s tenure (Ostroff & Kozlowski, 1992). JT can be expected to affect the extent to which an employee feels informed regarding the five dimensions on the JDI, which map onto the four aspects of organizational 122 Downloaded from orm.sagepub.com at Hong Kong Inst of Education Library on March 20, 2012 Downloaded from orm.sagepub.com at Hong Kong Inst of Education Library on March 20, 2012 123 Using past research and organizational initiatives/concerns identify variables that may be useful for explaining class membership Conduct analyses to determine if these variables explain class membership 5/6. Evaluate the Influence of Response Sets 7. Assess Correlates of Class Membership 5/6. Check scoring assumptions PCM¼partial credit model. 4. Name the Classes 3. Assess Absolute Fit 2. Assess Relative Fit/Model Choice 1. Background/ Review Conduct a review of the measure being studied and measures using similar response scales Formulate hypotheses and expectations concerning class structure and correlates of class membership Determine the appropriate number of classes; fit first the 1-class, then 2-class model, and so on, comparing their fit May need to defer to absolute fit when relative differences are small Determine whether the model fits the data well without reference to other models, and whether there is sufficient item-level fit Name the latent classes (LCs) in a way that is behaviorally meaningful according to response behavior Determine that thresholds are ordered appropriately If not, determine if freeing discrimination parameters alleviates disordering/ Determine if categories are appropriately ordered Ensure that observed scores and trait estimates are commensurate via correlation coefficients Determine whether persons are consistently classified into similar latent groups across scales (only applicable to multiple-scale measures) Description Step Hernandez, Drasgow, & Gonzalez-Roma (2004) for 2-class case. This article for more than two classes Hernandez et al., 2004 for 2-class case This article for more than two classes Kutner, Nachtsheim, Neter, & Li (2005) for logistic regression Maij-de Meij, Kelderman, & van der Flier (2008) for covariate integration Phi correlations for 2-class case Contingency statistics, for example: Chi-square and related effect sizes Cohen’s Kappa Logistic Regression (bi- or multinomial) Covariate Integration Descriptive Statistics across classes Rost & von Davier (1994) WINRMIRA User Manual (von Davier, 2001) Eid & Zickar (2007) Rost (1991) Andrich (2005) Multilog user manual (Thissen, Chen, & Bock, 2003) Thissen & Steinberg (1986) for PCM Item-level Q index for item fit Bootstrapped Pearson’s w2 Model Parameter Values Category probability histograms Bozdogan (1987) WINRMIRA User Manual (von Davier, 2001) Key Citations (where relevant) Item Threshold Parameter Plots Option Response Function Plots Use alternate Bilog, Multilog, or Parscale parameterizations to free discrimination parameters across items Information Theory Statistics such as CAIC Bootstrapped Pearson’s w2 Typical search engines such as PsycInfo Useful Tools/Statistics Table 1. Common Steps for Conducting Mixed-Model Item Response Theory (MM-IRT) Analyses and Explaining Class Membership 124 Organizational Research Methods 14(1) characteristics that employees much learn (Work—job-related tasks, Supervision & Coworkers— group processes and work roles, Pay and Promotion—organizational attributes). TIM was used to approximate the idea of Hernandez et al. (2004) that the ‘‘?’’ response may indicate of a lack of willingness to divulge feelings. In work settings, it has long been thought that trust moderates the level of honest and accurate upward communication that takes place (see Jablin, 1979; Mellinger, 1956). Evidence of the link between trust and open communication comes from recent empirical studies. First, Detert and Burris (2007) found that employee voice, the act of openly giving feedback to superiors, was related to a feeling of safety and trust. Levin, Whitener, and Cross (2006) found that subordinates’ perceived trust in supervisors related to levels of subordinate–supervisor communication. Finally, Abrams, Cross, Lesser, and Levin (2003), in a series of employee interviews, found that trust facilitated the sharing of knowledge with others. In sum, giving honest, open feedback about perceived shortcomings of an organization is likely to be seen as risky (Rousseau, Sitkin, Burt, & Camerer, 1998). Based on this link, we expect those with low TIM to use the ‘‘?’’ response more than those with high TIM as it allows responding in a non-risky way to sensitive scale items. We also decided to examine sex and race as explanatory variables that have been suggested as important considerations in MM-IRT studies (Hernandez et al., 2004). Past research has found that sex is not a significant predictor of class membership when examining scales with the ‘‘Yes’’– ‘‘No’’–‘‘?’’ response scheme (e.g., Hernandez et al., 2004), whereas ethnic background has been found to have a significant effect on class membership in one study (see Maij-de Meij et al. 2008). Here, we consider minority status (i.e., Caucasian vs. non-Caucasian), a typical concern among researchers investigating bias in organizational contexts in the United States. No research we are aware of has examined the influence of age on class membership. These variables were investigated in an exploratory fashion; we do not postulate formal hypotheses. Illustrative Analyses Data Set The data were obtained from the JDI offices at Bowling Green State University, which included responses from 1,669 respondents to the five facet scales: Pay (9 items), the Work (18 items), Opportunities for Promotion (9 items), Supervision (18 items), and Coworkers (18 items). Sample sizes for each scale after deletion of respondents showing no response variance are included in Table 2. The sample consisted of mostly full-time workers (87.8%) and had a roughly equal number of supervisors (42.7%) and nonsupervisors. The mean age was 44, and 45.2% were female. Race demographics were 77% Caucasian/White, 17% Black/African American, 2% Hispanic/Latino, 1% Asian, and 0.5% Native American; the remaining used the ‘Other’ category. From the spring to summer of 1996, data were collected approximately uniformly from the north, midwest, west, and south of United States as part of norming efforts for the JDI (Balzer et al., 1997). JT was measured by asking respondents, ‘‘How many years have you worked on your current job?’’ Responses ranged from 0 to 50, M ¼ 9.84, SD ¼ 9.2 and were positively skewed. We transformed JT by the method of Hart and Hart (2002) to approach normality. TIM was measured with the JDI TIM scale, a 24-item item scale with a similar format to the JDI, using the same response scale, with M ¼ 35.34, SD ¼ 23.11, and a ¼ .96 in this sample. For more information on these data and the TIM measure, see Balzer et al. (1997). Results Step 2: Assessing relative fit. The process of identifying the number of latent classes involves a sequential search process. First, the single-group PCM is estimated by setting g to 1 or 100% of 124 Downloaded from orm.sagepub.com at Hong Kong Inst of Education Library on March 20, 2012 Carter et al. 125 Table 2. Mixed-Model Item Response Theory (MM-IRT) Model Fit Statistics for Job Descriptive Index (JDI) Scales by the Number of Latent Classes in the Model Number of classes in model (CAIC fit statistic) JDI Scale N 1 2 3 4 5 Work Coworker Supervisor Promotions Pay 1,563 1,529 1,562 1,586 1,564 34,549.18 41,415.55 42,472.62 20,406.90 22,081.51 33,927.93 39,326.18 41,020.70 19,532.70 20,133.49 33,529.71 39,104.40 40,745.23 19,026.70 19,556.70 33,505.90 39,102.27 40,770.56 18,868.63 19,687.08 33,621.13 39,112.48 18,968.41 CAIC ¼ Consistent Aikake’s Information Criteria. Italicized CAIC statistics denote the most appropriate latent class solution. respondents; this model represents the case where it is assumed that all items and persons can be represented by one set of parameters and reduces the model in Equation 5 to Equation 3. The number of classes is then specified as one greater, until a decrease in fit is observed. The most appropriate model is chosen with reference to one of several relative fit statistics. Here, we use the Consistent Aikake’s Information Criteria (CAIC; Bozdogan, 1987). CAIC is considered useful because it penalizes less parsimonious models based on the number of person and item parameters estimated CAIC ¼ 2 lnðLÞ þ 2p½lnðN Þ þ 1; ð6Þ where 2 ln(L) is 2 times the log-likelihood function (common to conventional IRT model fit assessment) taken from the maximization step of the EM procedure. This statistic is increased by correcting for the number of parameters estimated, p, and ln(N) þ 1, the log-linear sample size with an additive constant of 1. The related statistic, Aikiake’s Information Criteria (Akaike, 1973) does not correct for either of these, and the Bayesian Information Criteria (Schwarz, 1978) only corrects for p. CAIC is used because it promotes parsimony more than the alternatives. According to CAIC, all JDI subscales fit a 3-class model well relative to other models estimated (see Table 2). Initially, the 4- and 5-class models for the Promotions scale would not converge within 9,999 iterations to meet the accuracy criterion of .0005 (the default of the WINMIRA program). We solved this problem by attempting to use several different starting values to avoid local maxima. Nonconvergence is not uncommon and is often due to low sample size, as this can lead to nearzero within-class response frequencies; such a finding should spur the researcher to consider the bootstrapped fit statistics in addition to model choice statistics (M. von Davier, personal communication, October 23, 2009). For the Work, Coworker, and Promotions scales, the 4-class model showed slightly better fit than the 3-class model. As noted earlier, in MM-IRT analyses model choice can become difficult due to small incremental increases in fit, as is the case here (see Table 2). It is important to understand that the probability of choosing an overparameterized model increases sharply as the difference between information criteria and sample size become smaller and that model choice should be largely motivated by parsimony (Bozdogan, 1987). In fact, Smit et al. (2003) constrained their number of groups to 2, underscoring the importance of this issue. However, it has been suggested more recently that this approach is likely too restrictive (Maij-de Meij et al., 2008). Following the strategy of Hernandez et al. (2004), we analyzed both solutions further to determine which was more appropriate by examining the absolute (as opposed to relative) fit of the competing models via item-fit, bootstrapped-fit statistics and checking for unreasonable parameter estimates. As noted previously, we attempted to proceed cautiously in our use of the Rasch-based PCM. Therefore, we were concerned with the extent to which there would be misfit due to the fact that 125 Downloaded from orm.sagepub.com at Hong Kong Inst of Education Library on March 20, 2012 126 Organizational Research Methods 14(1) Table 3. Mixed-Model Item Response Theory (MM-IRT) Item Fit and Latent Class Size Estimate, p, by Class Type (i.e., ‘‘Y,’’ ‘‘N,’’ and ‘‘?’’) Latent class size estimate, p JDI Scale Work Coworker Supervisor Promotions Pay Misfit item rate AC DC MLQC 5/54 3/54 8/54 2/27 0/27 .52 .40 .48 .32 .34 .27 .27 .29 .57 .51 .21 .33 .22 .11 .15 AC ¼ acquiescent class; DC ¼ demurring class; JDI ¼ Job Descriptive Index; Misfit item rate ¼ number of misfit items/total number of item fit tests; MLQC ¼ most likely to use the question mark class. ‘‘Y’’ corresponds to the class most likely to respond. ‘‘Yes;’’ ‘‘N’’ corresponds to the class most likely to respond. ‘‘No;’’ ‘‘?’’ corresponds to the class most likely to respond ‘‘?’’ the PCM does not take discrimination into account. Therefore, we thought it important to investigate the relative fit of the PCM and the generalized PCM (GPCM). We estimated the equivalent parameterizations of the 1-class PCM and the GPCM (which allows for discrimination to vary across items) by Thissen and Steinberg (1986) in Multilog 7.03 (Thissen, Chen, & Bock, 2003) for the Work scale. We found that the GPCM did show somewhat better fit, CAIC ¼ 12,034, than the PCM, CAIC ¼ 12,458. However, the two models appeared to fit similarly at the absolute level. Additionally, the locations of items under the two models were correlated .93. These results suggested that although the GPCM showed somewhat better fit, the PCM fit reasonably well. Below, we proceed with our analysis using the PCM. Step 3: Assessing absolute fit. Item-level fit provides both important information on the interpretability of item parameters and is an indicator of absolute fit; up to now the focus has been on relative fit (i.e., model choice statistics). The significance test of the z-transformed Q statistic (see Rost & von Davier, 1994) was used to test for item misfit. For scales showing competitive solutions (i.e., lack of clarity in relative fit), we calculated and compared item misfit rates for the 3- and 4-class solutions. Item misfit rates for the 3-class solution of all scales are provided in Table 3. The 3-class solution for the Work scale showed 5 misfitting items, which was above 5% chance levels (i.e., .05[ig], or .05[18 3] ¼ 2.7), whereas the 4-class solution showed 2 misfitting items, below the expected value (i.e., .05[18 4] ¼ 3.6). For the Coworker scale, the 3-class solution, showed 3 items with significant misfit, approximately the number expected by chance (i.e., 2.7); for the 4-class solution, 2 items were misfitting, which was just below chance levels (i.e., 3.6). For the Promotions scale, the 3-class solution showed a smaller proportion of misfitting items (i.e., 2/27 ¼ .037) than the 4-class solution (i.e., 3/36 ¼ .056). The empirical p values of bootstrapped Pearson w2 fit statistics showed better fit for the 3-class solution than the 4-class solution in the Coworker scale (p ¼ .03 vs. p < .001), both solutions showed acceptable fit for the Promotions scale (p ¼ .08 vs. p ¼ .10), and both showed misfit for the Work scale (both p < .001), suggesting absolute fit was either similar or better for the 3-class model in each of these scales. More importantly, inspection of item threshold parameter estimates for the 4-class solution of the Work, Coworker, and Promotions scales showed 6 of the 72, 4 of the 72, and 5 of the 36 items had threshold values greater than +4, respectively, whereas for the 3-class solutions only 2 of 27 items for the Promotions scale were found to exceed this value; these are unreasonable values for item threshold parameters. These findings are indicative that the 4-class solution cannot be ‘‘trusted’’ and the more parsimonious model is more appropriate (M. von Davier, personal communication, October 26, 2009). 126 Downloaded from orm.sagepub.com at Hong Kong Inst of Education Library on March 20, 2012 Carter et al. 127 Category 0 Category 1 Category 2 Category Probabilities in Class 1 with size 0.48417 0.9 0.8 0.7 Probability 0.6 0.5 0.4 0.3 0.2 0.1 0.0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 Item Figure 1. Within-class category probability chart for the acquiescent class (AC) in the Supervisor scale Step 4: Naming the latent classes (LCs). After the most appropriate LC structure has been identified, one can qualify or find a way to refer to LCs that is behaviorally meaningful. This can be accomplished by identifying important differences in response within and between classes. Qualifying the LCs can help both researchers and readers avoid confusion in interpreting the results of MM-IRT studies (Eid & Zickar, 2007). An overall inspection and comparison of within-class item-category probability histograms showed a clear trend in category use. One class, the largest in all scales, with the exception of Pay and Promotions, was more likely than any other class to respond in the positive (i.e., satisfied) direction which we named the Acquiescent Class (AC; see Figure 1). Another class emerged that was more likely than other class to respond negatively and was the largest class in the Pay and Promotions scales; we named this LC the Demurring Class (DC; see Figure 2). Finally, for all scales, there was one class, the smallest for all but the Coworkers scale, which was more likely than other to use the ‘‘?’’ response, which we named the Most Likely to use the Question mark Class (MLQC; see Figure 3). Those belonging to the AC and DC avoided the ‘‘?’’ response, and only the MLQC used the ‘‘?’’ with any regularity, as indicated by its nonzero mode for frequency of ‘‘?’’ usage (see Table 4). These results offer support for Hypothesis 1 that the majority of respondents would avoid using this option (AC and DC). The size of the AC and DC also confirmed our expectations that most respondents would prefer extremes. Table 3 shows the size of each class labeled by the names given above. Steps 5/6: Identification of systematic responding. One possible reason for latent class membership is the manifestation of particular systematic response styles. This question can be addressed by comparing the consistency of class assignment across several scales measuring different attitudes or other latent variables. The current authors could find only one instance of this type of analysis in Hernandez et al. (2004) where it was found that classification consistency was low to moderate across scales of the 16 Personality Factors questionnaire. Conducting 10 w2 analyses based on 3 3 contingency tables for each of the possible scale by scale combinations (e.g., the concordance between the three latent classes for the Pay and Work scales), we found significant w2 statistics 127 Downloaded from orm.sagepub.com at Hong Kong Inst of Education Library on March 20, 2012 128 Organizational Research Methods 14(1) Category 0 Category 1 Category 2 Category Probabilities in Class 2 with size 0.29118 0.9 0.8 0.7 Probability 0.6 0.5 0.4 0.3 0.2 0.1 0.0 1 2 3 4 5 6 7 8 10 9 Item 11 12 13 14 15 16 17 18 Figure 2. Within-class category probability chart for the demurring class (DC) in the Supervisor scale Category 0 Category 1 Category 2 Category Probabilities in Class 3 with size 0.22466 0.9 0.8 0.7 Probability 0.6 0.5 0.4 0.3 0.2 0.1 0.0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 Item Figure 3. Within-class category probability chart for the most likely to use the question mark class (MLQC) in the Supervisor scale (p< .001) and small to medium effect sizes3 for all the 10 tests (see Table 5). These findings support for Hypothesis 2 that although class membership is not purely a function of response style, it is still a considerable factor, in agreement with Hernandez et al. (2004; see above). 128 Downloaded from orm.sagepub.com at Hong Kong Inst of Education Library on March 20, 2012 Carter et al. 129 Table 4. Central Tendency Estimates for the Number of Times ‘‘?’’ Was Used by Members of Each Class Work scale (18 items) Coworker scale (18 items) Supervision scale (18 items) Promotion scale (9 items) Pay scale (9 items) Latent Class M SD AC DC MLQC AC DC MLQC AC DC MLQC AC DC MLQC AC DC MLQC 0.41 0.95 4.43 0.63 0.92 6.10 0.70 1.15 6.09 0.34 0.49 2.99 0.26 0.46 2.71 0.70 1.13 2.11 0.88 1.26 3.11 0.98 1.35 3.10 0.72 0.85 2.15 0.55 0.74 1.18 Mode 0 0 3 0 0 5 0 0 5 0 0 3 0 0 2 AC ¼ acquiescent class; DC ¼ demurring class; MLQC ¼ most likely to use the question mark class. Steps 5/6: Checking scoring assumptions. Inspecting item parameters revealed the threshold locations of the PCM were disordered for the majority of classes, suggesting a potential violation of the property of additivity (discussed above). Across all scales of the JDI, the AC and DC showed disordering with large distances between thresholds (e.g., see Figures 4 and 5). For the MLQC, the thresholds were ordered as would be expected (e.g., see Figures 6–8), suggesting the sum score is an appropriate representation of these classes’ satisfaction levels. For the Pay and Work scales, thresholds were nearly identical (see Figures 9 and 10). When thresholds are disordered, as was the case for the AC and DC, it is possible that ordered integer scoring (e.g., 0, 1, 2 or 0, 1, 3) may not be appropriate. However, it is also possible that the model has been properly estimated in such cases (Borsboom, 2005; Rost, 1991). Thus, we looked closer at these classes to determine whether the typical ordered sum-scoring of the JDI is viable for representing the latent trait. First, we consider whether the observed score distributions are consistent with the type discussed by Rost (1991) in which a measurement model may be estimated properly. Additionally, we consider the influence of excluding a discrimination parameter in the measurement model (see Borsboom, 2005, chap. 4). The observed score distributions for the AC and DC were either highly skewed (e.g., Figure 11) or U-shaped (e.g., see Figure 12), whereas the MLQC showed a quasi-normal distribution with low kurtosis (e.g., see Figure 13). This is consistent with Rost’s (1991) guidance that disordered thresholds could be properly estimated under such distributional conditions. Although this threshold disordering may seem serious at first glance, it should be noted that this means the intersections of categories, and not the categories themselves, are disordered. Thresholds represent the point on the trait continuum at which endorsing one option becomes greater than another (e.g., the level of the trait where endorsing ‘‘Yes’’ becomes more likely than endorsing ‘‘?’’) or the intersection of the category curves. Thus, it is possible for thresholds to be disordered whereas category curves are not. Consulting response curve plots for the 1-class PCM for each of the scales (which also showed disordered thresholds), we noted that the disordering of thresholds was a result of the low probability of using the ‘‘?’’ option and not disordered categories (e.g., see Figure 14). Additionally, y estimates were highly positively correlated with the sum score across 129 Downloaded from orm.sagepub.com at Hong Kong Inst of Education Library on March 20, 2012 130 Organizational Research Methods 14(1) Table 5. w2 Statistics and Cohen’s w Below and Cohen’s Kappa Above the Diagonal by Scale Pairs w2 (Cohen’s w based on Cramér’s j) JDI Scale Work Work Coworker Supervisor Promotions Pay Coworker Supervisor .01 162.14 176.56 51.31 113.95 (.34) (.35) (.18) (.28) Promotions .03 .02 .07 .23 .03 222.84 (.38) 90 (.24) 73.37 (.22) Pay 80.38 (.22) 92.17 (.25) .01 .07 .01 .06 110.9 (.27) All tests performed on 3 (latent class membership, scale 1) 3 (class membership, scale 2) contingency tables with df ¼ 4. Negative Cohen’s Kappa suggests no agreement and can effectively be set to 0. Threshold 1 Threshold 2 Item Parameters in Class 1 with size 0.48417 3 2 Threshold 1 0 −1 −2 −3 1 2 3 4 5 6 7 8 9 10 Item 11 12 13 14 15 16 17 18 Figure 4. Within-class item threshold parameter plot for the acquiescent class (AC) in the Supervisor scale classes for the Work (r ¼ .97), Coworker (r ¼ .96), Supervisor (r ¼ .97), Pay (r ¼ .99), and Promotions (r ¼ .98) scales. As noted above, it is also important to consider the possibility that the threshold disordering is due to the Rasch-based model being too restrictive by not taking discrimination into account (M. von Davier, personal communication, October 23, 2009). We determined that this was not the case. As noted above, we estimated the equivalent parameterizations of the 1-class PCM and GPCM shown by Thissen and Steinberg (1986) for the Work scale. Although the GPCM fit the data somewhat better than the PCM, the inclusion of varying discriminations did not alleviate disordering for the large majority of items. These results suggest the disordering in the AC and DC is due to these groups’ low probability of choosing the ‘‘?’’ option, as can be seen by examining the intersections of the ORFs in Figure 14. Were the probability of using ‘‘?’’ higher in this plot, the thresholds would be ordered as expected. Furthermore, observed score distributions were consistent with those discussed by Rost (1991) and were not due to the exclusion of a discrimination parameter. Thus, the threshold disordering did not 130 Downloaded from orm.sagepub.com at Hong Kong Inst of Education Library on March 20, 2012 Carter et al. 131 Threshold 1 Threshold 2 Item Parameters in Class 2 with size 0.29118 3 2 Threshold 1 0 −1 −2 −3 1 2 3 4 5 6 7 8 9 10 Item 11 12 13 14 15 16 17 18 Figure 5. Within-class item threshold parameter plot for the demurring class (DC) in the Supervisor scale Threshold 1 Threshold 2 Item Parameters in Class 3 with size 0.22466 3 2 Threshold 1 0 −1 −2 −3 1 2 3 4 5 6 7 8 9 10 Item 11 12 13 14 15 16 17 18 Figure 6. Within-class item threshold parameter plot for the most likely to use the question mark class (MLQC) in the Supervisor scale appear because of problems with the data or the model, which appeared to have been properly specified, gave trait estimates consistent with sum scores and showed appropriate category ordering in spite of the disordered parameters. 131 Downloaded from orm.sagepub.com at Hong Kong Inst of Education Library on March 20, 2012 132 Organizational Research Methods 14(1) Threshold 1 Threshold 2 Item Parameters in Class 2 with size 0.32449 3 2 Threshold 1 0 −1 −2 −3 −4 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 Item Figure 7. Within-class item threshold parameter plot for the most likely to use the question mark class (MLQC) in the Coworker scale Threshold 1 Threshold 2 Item Parameters in Class 3 with size 0.11211 4 3 2 Threshold 1 0 −1 −2 −3 −4 1 2 3 4 5 6 7 8 9 Item Figure 8. Within-class item threshold parameter plot for the most likely to use the question mark class (MLQC) in the Promotions scale 132 Downloaded from orm.sagepub.com at Hong Kong Inst of Education Library on March 20, 2012 Carter et al. 133 Threshold 1 Threshold 2 Item Parameters in Class 3 with size 0.15026 3 Threshold 2 1 0 −1 −2 −3 1 2 3 4 5 6 7 8 9 Item Figure 9. Within-class item threshold parameter plot for the most likely to use the question mark class (MLQC) in the Pay scale Threshold 1 Threshold 2 Item Parameters in Class 3 with size 0.20947 4 3 2 Threshold 1 0 −1 −2 −3 −4 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 Item Figure 10. Within-class item threshold parameter plot for the most likely to use the question mark class (MLQC) in the Work scale 133 Downloaded from orm.sagepub.com at Hong Kong Inst of Education Library on March 20, 2012 134 Organizational Research Methods 14(1) Frequency WLE MLE Person Parameters in Class 1 with size 0.40114 4 40 2 Frequency Parameter 30 0 20 −2 10 −4 0 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 Raw score Figure 11. Observed score distribution for the Coworker scale in the acquiescent class (AC) Frequency WLE MLE Person Parameters in Class 3 with size 0.27437 4 40 2 20 Frequency Parameter 30 0 −2 10 −4 0 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 Raw score Figure 12. Observed score frequency distribution for the Coworker scale in the demurring class (DC) Step 7: Correlates of class membership. Two basic ways of investigating this question were found by the authors in the available MM-IRT literature: (a) use of regression techniques and (b) integration of covariates into measurement models. In our illustration, we focus on the former because more organizations and researchers are likely to possess the statistical and/or programming expertise to accomplish the regression-based approach. In this method, the latent class structure is used as a multinomial dependent variable, and therefore multinomial logistic regression (MLR) is an appropriate mode of analysis in determining predictors of class membership. This is an important extension of 134 Downloaded from orm.sagepub.com at Hong Kong Inst of Education Library on March 20, 2012 Carter et al. 135 Frequency WLE MLE Person Parameters in Class 2 with size 0.32449 4 40 2 0 20 Frequency Parameter 30 −2 10 −4 0 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 Raw score Figure 13. Observed score frequency distribution for the Coworker scale in the most likely to use the question mark class (MLQC) Item Characteristic Curve: 3 1.0 1 Probability 0.8 0.6 0.4 0.2 3 2 0 −3 −2 −1 0 Ability 1 2 3 Figure 14. Example Option Response Curve for an item in the Work scale under the 1-class partial credit model (PCM) Note: 1 ¼ No, 2 ¼ ?, 3 ¼ Yes. from previous research that has (appropriately for their purposes) used only binary logistic models for 2-class solutions (e.g., Hernandez et al., 2004) or complex covariate-measurement model integration when more than two classes are retained (e.g., Maij-de Meij, 2008). 135 Downloaded from orm.sagepub.com at Hong Kong Inst of Education Library on March 20, 2012 136 Organizational Research Methods 14(1) In all, we used five variables as possible predictors of class membership: (a) JT; the transformed number of years on the job; (b) the TIM, self-report measure; (c) age; (d) sex; and (e) race. We performed multinomial logistic regression to investigate these variables as correlates of latent class membership (i.e., AC, DC, and MLQC), one for each variable representing latent class membership on the JDI scales (i.e., the outcome variables). The correlations between these variables are shown in Table 6. The AC was used as the reference group in these analyses as it had a consistently large relative size compared to the DC and MLQC. First, likelihood ratio statistics were calculated to select variables explaining class membership (see Table 7). Variables that were nonsignificant were not included in the final MLR analyses. TIM was the only variable selected for all scales, and race was the only variable that did not contribute to any of the five models. JT was only included in the MLR analyses for Promotions and Pay scales; Sex was included for Work, Promotions, and Pay; and Age for Work and Promotions. Next, the final MLR analyses can be conducted using only the variables selected in the first step. Logit regression coefficients, B, can be tested by the Wald statistic, which is distributed approximately w2 with one degree of freedom. The exponentiation of the log-odds, exp(B), can be interpreted as the probability of belonging to one class over the reference class (AC here). However, for dichotomous predictor variables, two special considerations are necessary. First, B and therein, exp(B) will likely be much larger than those for continuous predictors. This is due to the fact that a one-unit change in, for example, TIM is much less than that for a one-unit change in Sex (i.e., moving from male to female). Second, the standard errors used to compute the Wald statistic are often unduly inflated and thus can lead to high Type II Errors (Menard, 2002). Thus, for dichotomous variables, the likelihood ratios above should be used for variable selection and exp(B) should be considered over the Wald statistic. The final MLR models showed that the selected variables were successful in explaining low to moderate amounts of variance in class membership (Nagelkerke R2 from .04 to .20; see model information in Table 8). For all JDI scales, TIM was found to be a significant predictor of belonging to the MLQC and DC for all scales such that having a higher TIM score decreased the chances of belonging to either group relative to the AC by between 97% and 99%, as indicated by the exp(B) coefficient.4 The only exception was for the Promotions scale, where higher TIM increased the chance of belonging to the MLQC, though by a negligible factor (i.e., 3%). JT was a significant predictor of belonging to the MLQC and DC for the Promotions and Pay scales; more JT increases the likelihood of belonging to these classes for the Promotions scale and decreases this likelihood for the Pay scale. Higher age decreased the likelihood of belonging to the DC and MLQC in the Work scale, whereas those with higher age showed increased chances of belonging to the DC and MLQC. Females had larger chances than males of being in the MLQC for the Work and Pay scales and in the DC for the Pay scale. Females showed lower chances than males of being in the DC for the Work scale and the MLQC group for the Promotions scale. Results of the logistic regression analyses for the MLQC classes are briefly summarized in Table 9. Discussion In this article, we provided a comprehensive overview of MM-IRT and past research using the method, in addition to related techniques that can be used to understand latent class structures in item response data. We have included here, a table (Table 1) outlining the major steps commonly undertaken in conducting MM-IRT analyses. Given that MM-IRT is an underutilized tool in the organizational research, this study used MM-IRT to investigate some interesting questions about a popular work-related satisfaction measure, the JDI. The data at hand afforded us a way to show some 136 Downloaded from orm.sagepub.com at Hong Kong Inst of Education Library on March 20, 2012 Downloaded from orm.sagepub.com at Hong Kong Inst of Education Library on March 20, 2012 137 2 .185** .001 –.115** .017 –.048 –.065** .297** .020 –.234** –.067** –.067** –.032 –.016 –.008 –.009 –.051* .019 –.008 6a 6b .148** .012 .083** .053* –.196** –.034 7a 7b –.159** –.108** –.466** .312** –.538** –.347** 6c 7c 8a 8b –.011 .240** –.084** –.144** .149** .071** –.176** .064** –.084** .161** –.050* .028 .101** –.091** –.572** –.054* –.172** –.023 .285** –.165** –.160** .375** –.466** –.299** –.026 .054* –.022 –.001 .089** –.547** –.074** –.489** –.244** 5 8c 9a 9b –.091** .020 .025 .045 .127* –.043 9c 10a 10b .142** –.048 –.116** .188** –.041 –.078** .189** .009 –.071** .138** –.013 –.030 .181** –.064** –.016 .162** –.086** –.124** .210** –.045 –.606** –.103** .142** –.060* –.073** .129** –.068** –.065** .215** –.143** –.064** –.229** –.511 .113** .136** .191** –.064** –.112** .123** –.002 –.096** .145** –.057* –.076** –.066** –.117** –.040 .112** –.040 –.016 .092** –.030 –.010 .116** –.069** –.632** –.004 –.041 –.113** –.050* .233** –.098** –.070** .198** –.110** –.049* .211** –.321** –.379** .014 .036 .001 .014 .013 .022 .025 .050* .010 .152** 4 –.144** .086** –.107** –.035 –.049* .165** –.271** .131** .083** –.008 –.100** .289** –.152** –.042 .060* .097** .198** .012 –.054* –.184** –.056* –.067** .009 –.033 .199** .046 –.174** –.058* –.056* –.081** .185** .082** 3 –.006 .007 –.017 .110** .432** .030 .117** .028 .171** –.057* 1 AC ¼ acquiescent class; DC ¼ demurring class; JT ¼ job tenure; MLQC ¼ most likely to use the question mark class; TIM ¼ trust in management. Dummy coding: Sex (1 ¼ Female, 0 ¼ Male); Race (1 ¼ Not Caucasian, 0 ¼ Caucasian). * p < .05, and ** p < .01. 1. JT 2. TIM 3. Age 4. Race 5. Sex Dummy variables Work 6a. AC 6b. DC 6c. MLQC Coworker 7a. AC 7b. DC 7c. MLQC Supervisor 8a. AC 8b. DC 8c. MLQC Pay 9a. AC 9b. DC 9c. MLQC Promotions 10a. AC 10b. DC 10c. MLQC Predictor Variables Table 6. Predictor Variables and Dummy Variables by Scale 138 Organizational Research Methods 14(1) Table 7. Likelihood Ratio Statistics for Model Predictors by Scale Likelihood ratio statistics for variable selection JDI Scale Work Coworker Supervisor Promotions Pay TIM JT Age Sex Race 68.09a 0.58 13.96a 15.01a 3.85 51.91a 2.59 6.29 4.56 0.75 143.63a 1.53 7.32 5.75 1.28 193.01a 15.03a 39.21a 14.83a 3.64 88.49a 20.31a 2.96 31.12a 7.22 Dummy coding: Sex (1 ¼ Female, 0 ¼ Male); Race (1 ¼ Not Caucasian, 0 ¼ Caucasian). JDI ¼ Job Descriptive Index; JT ¼ job tenure; TIM ¼ trust in management. a Indicates that the predictor significantly improved the model and was selected to remain in the model. *p< or essentially equivelent to .01 (i.e. .05 corrected for the number of JDI scales analyzed, or .05/5). Table 8. Multinomial Logistic Regression Results Using the AC as the Reference Category for All Scales Scale (Class) Variable Work (DC) TIM* Age* Sex TIM* Age* Sex TIM* TIM* TIM* TIM* TIM* JT* Age* Sex TIM* JT Age* Sex* TIM* JT* Sex* TIM* JT* Sex* Work (MLQC) Coworker (DC) Coworker (MLQC) Supervisor (DC) Supervisor (MLQC) Promotions (DC) Promotions (MLQC) Pay (DC) Pay (MLQC) B Wald Significance exp(B) 0.02 0.02 0.30 0.01 0.02 0.31 0.02 0.01 0.03 0.02 0.02 0.66 0.03 <0.01 0.03 0.25 0.02 0.55 0.02 0.59 0.71 0.01 0.68 0.55 62.97 7.59 3.89 21.37 7.75 5.16 42.08 26.08 127.52 47.33 41.35 14.40 15.03 <0.01 44.29 1.18 6.95 10.10 84.92 12.89 34.05 17.88 13.85 12.65 <.001 .012 .026 <.001 .005 .023 <.001 <.001 <.001 <.001 <.001 <.001 <.001 .998 <.001 .277 .008 .001 <.001 <.001 <.001 <.001 <.001 .001 0.98 0.98 0.74 0.99 0.98 1.37 0.98 0.99 0.97 0.98 0.98 1.93 1.03 1.00 1.03 1.28 0.98 0.58 0.98 0.60 2.04 0.99 0.51 1.74 95% CIexp(B) (Low:High) 0.97:0.98 0.97:1.00 0.57:0.96 0.98:0.99 0.97:1.00 1.04:1.79 0.98:0.98 0.98:0.99 0.96:0.97 0.97:0.98 0.98:0.99 1.37:2.70 1.01:1.04 0.77:1.30 1.02:1.04 0.82:1.99 0.96:0.99 0.41:0.81 0.97:0.98 0.45:0.79 1.60:2.59 0.98:0.99 0.35:0.72 1.28:2.35 Model information. Work: N ¼ 1,471; w2 (10) ¼ 102.96; Nagelkerke R2 ¼ .08; Coworker: N ¼ 1,506; w2 (10) ¼ 51.79; Nagelkerke R2 ¼ .04; Supervisor: N ¼ 1,510; w2 (10) ¼ 154.77; Nagelkerke R2 ¼ .11; Promotions: N ¼ 1,529; w2 (10) ¼ 282.89; Nagelkerke R2 ¼ .20; Pay: N ¼ 1,505; w2 (10) ¼ 140.94; Nagelkerke R2 ¼ .10. Dummy coding: Sex (1 ¼ Female, 0 ¼ Male). AC ¼ acquiescent class; DC ¼ demurring class; MLQC ¼ most likely to use the question mark class; TIM ¼ trust in management. potential issues that can arise and should be investigated when using mixed Rasch models as available in the WINMIRA (von Davier, 2001) software program. First, we hope to have elucidated the procedure and importance of model selection in both the relative and absolute sense, how model selection can be complicated by data and model issues, and 138 Downloaded from orm.sagepub.com at Hong Kong Inst of Education Library on March 20, 2012 Carter et al. 139 Table 9. Summary of Predictor Variable Influence and Directionality on the Odds of Belonging to the DC and MLQC Over the AC Class membership predictors DC JDI Scale TIM Work Coworker Supervisor Promotions Pay 98% 98% 97% 98% 98% JT þ93% 60% MLQC Age Female TIM 98% 74% þ3% þ100% þ103% 99% 99% 98% þ3% 99% JT þ128% 51% Age Female 98% þ134% 98% 58% þ73% þ Signifies that as the variable increases, the odds of being in the indicated class relative to the AC increase. Signifies that as the variable increases, the odds of being in the indicated class relative to the AC decrease. No value signifies the variable was excluded from the model. Values in boldface were not found to be significant by the Wald statistic. TIM ¼ trust in management; JT ¼ job tenure; AC ¼ acquiescent class; DC ¼ demurring class; MLQC ¼ most likely to use the question mark class. the courses of action that can be taken to determine whether the model is appropriate. Second, by showing how one may go about identifying and qualifying the latent class structure, we intended to show the utility of this strategy in enhancing the clarity of analyses to both the researcher and the reader. Our results showed the majority of respondents were not classified into the MLQC. This result supported our first hypothesis in agreement with past research (see Hernandez et al., 2004; Maij-de Meij et al., 2008; Smit et al., 2003). However, given the small size of this class, it is difficult to tell whether these results would generalize to future samples. Therefore, similar studies should be conducted to determine whether this finding is replicable, ideally with larger sample sizes and among several measures using similar ‘‘Yes’’–‘‘No’’–‘‘?’’ scales. Our illustration demonstrated that model selection is not always a simple, clear-cut process. In fact, it can require several indicators of absolute and relative fit to determine the number of classes necessary to appropriately explain heterogeneity in response data. Although relative fit statistics such as CAIC may be highly helpful, they should not be viewed as the only indication of the proper number of classes. As was shown here, in situations where model selection becomes unclear, it may be necessary to turn to measures of absolute fit (see Table 1, Step 3), such as item-level fit and the p values of bootstrapped fit statistics (e.g., Pearson’s w2). In this situation, however, the simpler indication was the value of parameter estimates for the 3- and 4-class solutions. We found that although the 3-class solution showed reasonable estimates for threshold locations, the 4-class solution did not. Although the two solutions were similar in relative and absolute fit measures, the 4-class solution’s threshold values were unreasonable in that they indicated that within some classes, endorsing one option over another became probable only at extreme levels of the trait, where an unreasonably small number of persons are located. One rough heuristic in these cases is to interpret this in a fashion similar to z scores, wherein values larger than +2.5 become questionable (Reise & Waller, 2003) and those larger than our relatively liberal cutoff of +4 are unacceptable. We also showed how MM-IRT results can be analyzed to identify the influence of a systematic response set by comparing classification consistency across scales. Results also supported our second hypothesis, in that effect sizes based on contingency tables indicated only a small to medium degree of consistency of class membership across scales, suggesting that respondents’ LC membership is not due solely to a particular response set, though it is a considerable influence. This result is also consistent with the study of Hernandez et al. (2004). Given that the ‘‘?’’ does not appear to be merely the result of 139 Downloaded from orm.sagepub.com at Hong Kong Inst of Education Library on March 20, 2012 140 Organizational Research Methods 14(1) a response set, these results suggest those who are using the ‘‘?’’ purposefully use it when responding to items addressing particular facets of the job (i.e., in different scales of the JDI). Additionally, we showed how scoring processes can be checked by taking advantage of the strong assumptions of Rasch-based models and checking to see whether the sum score is a sufficient estimate of the latent variable. Our results suggested that the ordered-scoring assumption of the JDI is tenable across classes. Although the disordered thresholds suggest the ‘‘?’’ response does not lie between the ‘‘Yes’’ and ‘‘No’’ options for the AC and DC, and no information is gleaned from the ‘‘?’’ response for these persons’ satisfaction levels, this is due to the fact that they simply do not use the option with any frequency. For example, in item 12 of the Supervisor scale, 1.9% of the AC and 3.1% of the DC used the ‘‘?’’ response. However, 32.1% of the MLQC chose the ‘‘?’’ option. We also found that the threshold disordering was not due to the exclusion of a discrimination parameter. Although the GPCM showed better fit to the data, it did not show ordered thresholds for the majority of items. Furthermore, the observed score distributions were similar to those Rost (1991) has said would be observed in disordered but properly estimated measurement models. Therefore, the respondents for whom the ‘‘?’’ does not fall between ‘‘Yes’’ and ‘‘No,’’ there is effectively no influence of this option on the sum score. For the respondents who actually use the ‘‘?’’ response, the option falls between the other categories, and the sum score is conceptually valid. Hernandez et al. (2004) offered four potential explanations for using the ‘‘?’’ option. We used proxy variables to test the notion that (a) the respondents may not feel sufficiently informed to make a decision (JT) as well as (b) the respondents may not feel comfortable divulging their view (TIM). Additionally, we tested age, race, and sex due to their importance in the pantheon of organizational research. MLR was used to explain class membership from these individual difference variables, which provides a unique contribution in, that other MM-IRT studies have either used binary logistic regression (e.g., Hernandez et al., 2004) or by integrating covariates into the latent trait model (e.g., Maij-de Meij et al., 2008). Results of the MLR supported the explanation of willingness of Hernandez et al. (2004; see also DuBois & Burns, 1975) to divulge information. Those with lower levels of TIM were more likely to be classified into the MLQC over the AC. This supports the view that if respondents are willing to divulge their opinions (i.e., respondents trust management), they are less likely to use the ‘‘?’’ response. In addition, TIM predicted class membership, such that for all scales of the JDI, lower TIM also increased the probability of belonging to the DC over the AC. For all scales, the strength of relationship was similar as indicated by similar exp(B) values. Not having enough information about the topic was also considered a reason to use the ‘‘?’’ option (Hernandez et al., 2004). Using JT as a proxy for this assertion, we found that the analyses supported this explanation only for the Pay scale of the JDI; more JT decreases the chances of being in the MLQC and DC. This may suggest that those who have been on their job for a number of years are less uncertain concerning their pay, and therein more likely to used the ‘‘Yes’’ or ‘‘No’’ responses. JT had the opposite influence in the Promotions scale; the longer one has been on the job, the more likely they are to be in the DC or MLQC. This may be because any lack of clarity in the promotional structure of organizations may be more apparent or salient as one approaches the level of tenure where those opportunities are realistic options for employees. Age can also be considered a proxy for information about the job; it is reasonable to assume younger workers are less likely to have contact with the work world compared to older to workers. Age, as a proxy for job information, helped explain class membership for the Work and Promotion scales of the JDI. Older workers were less likely to be classified into the ‘‘?’’ class, whereas older workers could be expected to have more solidified attitudes toward work satisfaction facets, as was noted by Adams, Carter, Wolford, Zickar, and Highhouse (2009). Sex and race as explanations were harder to evaluate, as the Wald statistic is less reliable for dichotomous variables. Although some of these variables were nonsignificant according to this 140 Downloaded from orm.sagepub.com at Hong Kong Inst of Education Library on March 20, 2012 Carter et al. 141 statistic, we considered the predictor for each model it was selected into by the LR statistic (see Table 7). However, the more clear findings were those for the Pay scale. Here, we found that females were around twice as likely to be categorized as MLQC or DC over AC. This may be a product of the well-known inequality in salary between males and females in the United States. From an organizational perspective, this would be an unsettling finding for a business as it may indicate that females do not feel as though they have been provided a clear understanding of the pay structure or the reasons for differentials in pay between themselves and their male colleagues. Note that such a finding for age could be equally problematic, especially if the variable were coded into ‘‘Over-40’’ and ‘‘Under-40’’ categories consistent with the Age Discrimination and Employment Act. The finding for race shown here would be a much more positive finding, as there appeared to be no relationship between class membership and this important group membership variable. Another trend we noticed here is the consistency of findings for the DC and MLQC. This is especially interesting in light of the conception of Smith et al. (1969) of scoring the option 0, 1, and 3. The authors concluded that this was the appropriate scoring scheme as respondents who were less satisfied tended to use the ‘‘?’’ response more than satisfied persons, as determined by a distributional split on satisfaction scores. In fact, the MLQC was found to have generally lower observed scores (see Figure 13) than those in the AC (see Figure 11) but higher than those in the DC (see Figure 12). However, for these respondents, there appears to be little difference between choosing ‘‘?’’ over ‘‘No’’ and choosing ‘‘Yes’’ over ‘‘?’’ in terms of satisfaction. Unfortunately, all the suggestions of Hernandez et al. (2004) could not be followed due to the range of variables available in the data set. The idea that respondents who use the ‘‘?’’ category do not understand the content of the item could be tested by inclusion of a cognitive or general mental ability measure. Research by Krosnick et al. (2002) suggests that if the ‘‘?’’ response is used a no-opinion response, then lower intelligence respondents are more likely to use the ‘‘?’’ category. That is, if respondents are using the ‘‘?’’ response because of misunderstanding, less intelligent respondents are expected to use the ‘‘?’’ more often. This is still open for researchers to investigate, as it has yet to be addressed empirically in the literature. However, potential alternate and/or complimenting proxy variables for testing some of these suggestions were unavailable. For example, one reviewer noted that the personality trait of neuroticism could have been used to address the idea that persons do not feel competent enough to provide a response other than ‘‘?’’ and that both neuroticism and agreeableness could be used to test whether those in the MLQC were reluctant to divulge their feelings. Furthermore, it could be that the inclusion of personality variables would aid prediction over and/or above TIM, as TIM is situational and has shown a low correlation with personality-based trust, r ¼ .16 (Dirks & Ferrin, 2002). However, personality-based measures of trust would tell us little about the work situation faced by persons, as they tell us nothing in regard to the target of trust (i.e., the manager; Clark & Payne, 1997; Dirks & Ferrin, 2002; Mayer, Davis, & Schoorman, 1995; Payne & Clark, 2003). Furthermore, TIM’s strong relationship to organizationally relevant situation-driven variables, such as managerial leadership styles and organizational justice (see Dirks & Ferrin, 2002) and the finding here that class membership is variable across scales may reflect that the use of ‘‘?’’ is situation driven. However, the inclusion of personality variables related to trust in future studies may shed light on the stability or instability of ‘‘?’’ usage. Low correlations of TIM with more stable individual difference variables such as trait anxiety, and the finding that relatively more variance in TIM is explained by situational aspects (Payne & Clark, 2003) suggest that TIM is likely not redundant with regard to personality or mental ability. As of now, the question remains; Is use of the ‘‘?’’ determined situationally or is it a manifestation of a more stable individual difference. Although Hernandez et al. (2004) found that traits such as social boldness, abstractedness, and impression management predict membership into the group likely to use the ‘‘?,’’ it is interesting to note these MM-IRT analyses were based on personality 141 Downloaded from orm.sagepub.com at Hong Kong Inst of Education Library on March 20, 2012 142 Organizational Research Methods 14(1) measures. Therefore, it may be that stable individual differences may best predict the use ‘‘?’’ for personality measures (as in Hernandez et al., 2004), whereas its use in attitudinal measures may best be determined by situational variables (as shown here). Additionally, comparisons between the use of ‘‘?’’ in different organizational conditions or stages, such as restructuring or layoff periods would also give some indication of the nature of ‘‘?’’ usage. Finally, as one reviewer noted, it could be interesting to examine the use of the ‘‘?’’ response across time. Although this was not likely an issue here, given the short time frame for data collection, we believe this would be an interesting and relevant question for future studies. Although our illustration shows the utility of the MM-IRT technique, one limitation is the sample size requirement for accurate standard errors of parameter estimates, which are larger than for typical IRT analyses (Zickar & Broadfoot, 2009), given the need to estimate class membership parameters. However, we still encourage researchers to use this tool in their research. The increased costs to obtain more respondents will likely be outweighed by the rich information that MM-IRT offers. Here, we have shown how MM-IRT can be used by organizational researchers to determine the nature of the group structure by closely examining the most appropriate multigroup solution and considering individual and group differences important to organizational researchers as explanations of class membership. We hope our illustration has provided researchers with a somewhat comprehensive reference, expanding on prior research in regard to the topics addressed (e.g., use of Rasch models, qualifying class structures, and attitudinal measures), the complementary methods of analyses used (e.g., MLR), as well as providing further insight into respondents use of the ‘‘?’’ response. Additionally, we hope that organizational researchers will harness this powerful tool to conduct further research on organizational surveys in general, as well as to further investigate the use of ‘‘Yes’’/ ‘‘No’’/ ‘‘?’’ and other types of response scales. Notes 1. Readers unfamiliar with conventional item response theory (IRT) models are referred to Zickar (2001) for a concise introduction to polytomous IRT modeling, which is beyond the scope of this manuscript; for a more comprehensive treatment, we suggest Item Response Theory for Psychologists by Embretson and Reise (2000). 2. Note that any other IRT model could be substituted in the same fashion for P(u|g). pffiffiffiffiffiffiffiffiffiffiffi 3. To estimate association, we calculated the w effect size from Cramér’s (1946) j by w ¼ j h 1, where h is the number of categories for the smallest number, r or c, of an r c contingency table (Sheskin, 2004). Using Cohen’s (1988) criteria for w, values of .1 are considered small and values between .3 and .5 are considered medium. 4. Exp(B) can be interpreted as a probability, and thus converted to percentage chance of belonging to a group over the reference group (see Kutner, Nachtsheim, Neter, & Li, 2005). Acknowledgments The authors would like to thank Dr. Matthias von Davier of Educational Testing Service for his kindness in answering their questions and for providing them with his personal communications and Dr. Jennifer Z. Gillespie of Bowling Green State University and the JDI Office for her willingness to share these data and her personal communications. Declaration of Conflicting Interests The authors declared no potential conflicts of interests with respect to the authorship and/or publication of this article. 142 Downloaded from orm.sagepub.com at Hong Kong Inst of Education Library on March 20, 2012 Carter et al. 143 Funding The authors received no financial support for the research and/or authorship of this article. References Abrams, L. C., Cross, R., Lesser, E., & Levin, D. Z. (2003). Nurturing interpersonal trust in knowledge-sharing networks. Academy of Management Executive, 17, 64-71. Adams, J. E., Carter, N. T., Wolford, K., Zickar, M. J., & Highhouse, S. (2009). The job descriptive index: A reliability generalization study. Presented at the 24th Annual Meeting of the Society for Industrial and Organizational Psychology, New Orleans, LA. Akaike, H. (1973). Information theory and the extension of the maximum likelihood principle. In V. N. Petrov & F. Scáki (Eds.), Second international symposium of information theory (pp. 267-281). Budapest: Akadémiai Kiadó. Andrich, D. (2005). The Rasch model explained. In S. Alagumalai, D. D. Durtis & N. Hungi (Eds.), Applied Rasch measurement: A book of exemplars. New York: Springer. Balzer, W. K., Kihm, J. A., Smith, P. C., Irwin, J. L., Bachiochi, P. D., Robie, C., et al. (1997). User’s manual for the Job Descriptive Index (JDI; 1997 Revision) and the Job in General (JIG) scales. OH: Bowling Green State University. Bock, R. D. (1972). Estimating item parameters and latent ability when the responses are scored in two or more nominal categories. Psychometrika, 37, 29-51. Bock, R., & Jones, L. V. (1968). The measurement and prediction of judgment and choice. San Francisco: Holden Day. Borsboom, D. (2005). Measuring the mind: Conceptual issues in contemporary psychometrics. New York: Cambridge University Press. Bowling, N. A., Hendricks, E. A., & Wagner, S. H. (2008). Positive and negative affectivity and facet satisfaction: A meta-analysis. Journal of Business and Psychology, 23, 115-125. Bozdogan, H. (1987). Model selection and Akaike’s Information Criteria: The general theory and its analytic extensions. Psychometrika, 52, 345-370. Chan, K.-Y., Drasgow, F., & Sawin, L. L. (1999). What is the shelf life of a test? The effect of time on the psychometrics of a cognitive ability test battery. Journal of Applied Psychology, 84, 610-619. Chernyshenko, O. S., Stark, S., Chan, K.-Y., Drasgow, F., & Williams, B. (2001). Fitting item response theory models to two personality inventories: Issues and insights. Multivariate Behavioral Research, 36, 523-562. Clark, M. C., & Payne, R. L. (1997). The nature and structure of workers’ trust in management. Journal of Organizational Behavior, 18, 205-224. Cohen, J. (1988). Statistical power analysis for the behavioral sciences (2nd ed.). Hillsdale, NJ: Lawrence Erlbaum. Collins, W. C., Raju, N. S., & Edwards, J. E. (2000). Assessing differential functioning in a satisfaction scale. Journal of Applied Psychology, 85, 451-461. Connolly, J. J., & Viswesvaran, C. (2000). The role of affectivity in job satisfaction: A meta-analysis. Personality and Individual Differences, 29, 265-281. Cooper-Hakim, A., & Viswesvaran, C. (2005). The construct of work commitment: Testing an integrative framework. Psychological Bulletin, 131, 241-259. Cramér, H. (1946). Mathematical methods of statistics. Uppsala, Sweden: Almqvist & Wiksells. Cruickshank, P. J. (1984). A stress arousal mood scale for low vocabulary subjects: A reworking of Mackay et al. (1978). British Journal of Psychology, 75, 89-94. Detert, J. R., & Burris, E. R. (2007). Leadership behavior and employee voice: Is the door really open? Academy of Management Journal, 50, 869-884. Dirks, K. T., & Ferrin, D. L. (2002). Trust in leadership: Meta-analytic findings and implications for research and practice. Journal of Applied Psychology, 87, 611-628. 143 Downloaded from orm.sagepub.com at Hong Kong Inst of Education Library on March 20, 2012 144 Organizational Research Methods 14(1) Donovan, M. A., Drasgow, F., & Probst, T. M. (2000). Does computerizing paper-and-pencil job attitude scales make a difference? New IRT analyses offer insight. Journal of Applied Psychology, 85, 305-313. Dubois, B., & Burns, J. A. (1975). An analysis of the meaning of the question mark response category in attitude scales. Educational and Psychological Measurement, 35, 869-884. Eid, M., & Rauber, M. (2000). Detecting measurement invariance in organizational surveys. European Journal of Psychological Assessment, 16, 20-30. Eid, M., & Zickar, M. J. (2007). Detecting response styles and faking in personality and organizational assessments by mixed Rasch models. In M. Von Davier & C. H. Carstensen (Eds.), Multivariate and mixture distribution Rasch models: Extensions and applications. New York: Springer. Embretson, S. E., & Reise, S. P. (2000). Item response theory for psychologists. Mahwah, NJ: Lawrence Erlbaum. Goldberg, G. (1971). Response format in attitude scales. Unpublished manuscript, Northwestern University. Hanisch, K. A. (1992). The job descriptive index revisited: Questions about the question mark. Journal of Applied Psychology, 77, 377-382. Hart, R., & Hart, M. (2002). Statistical process control for health care. Pacific Grove, CA: Duxbury. Hernandez, A., Drasgow, F., & Gonzalez-Roma, V. (2004). Investigating the functioning of a middle category by means of a mixed-measurement model. Journal of Applied Psychology, 89, 687-699. Jablin, F. M. (1979). Superior-subordinate communication: The state of the art. Psychological Bulletin, 86, 1201-1222. Judge, T. A., Heller, D., & Mount, M. K. (2002). Five-factor model of personality and job satisfaction: A metaanalysis. Journal of Applied Psychology, 87, 530-541. Kaplan, K. J. (1972). On the ambivalence-indifference problem in attitude theory: A suggested modification of the semantic differential technique. Psychological Bulletin, 77, 361-372. Krosnick, J. A., Holbrook, A .L., Berent, M. K., Carson, R. T., Hanemann, W. M., Kopp, R. J., et al. (2002). The impact of ‘‘no opinion’’ response options on data quality: Non-attitude reduction or an invitation to satisfice? Public Opinion Quarterly, 66, 371-403. Kutner, M. H., Nachtsheim, C. J., Neter, J., & Li, W. (2005). Applied linear statistical models (5th ed.). Boston: McGraw-Hill. Lazarsfeld, P. E., & Henry, N. W. (1968). Latent structure analysis. Boston: Houghton Mifflin. Levin, D. Z., Whitener, E. M., & Cross, R. (2006). Perceived trustworthiness of knowledge sources: The moderating impact of relationship length. Journal of Applied Psychology, 91, 1163-1171. Maij-de Meij, A. M., Kelderman, H., & van der Flier, H. (2008). Fitting a mixture item response theory model to personality questionnaire data: Characterizing latent classes and investigating possibilities for improving prediction. Applied Psychological Measurement, 32, 611-631. Masters, G. N. (1982). A Rasch model for partial credit scoring. Psychometrika, 47, 149-174. Maurer, T. J., Raju, N. S., & Collins, W. C. (1998). Peer and subordinate performance appraisal measurement equivalence. Journal of Applied Psychology, 83, 693-702. Mayer, R. C., Davis, J. H., & Schoorman, F. D. (1995). An integrative model of organizational trust. Academy of Management Review, 20, 709-734. Mellinger, G. D. (1956). Interpersonal trust as a factor in communication. Journal of Abnormal Social Psychology, 52, 304-309. Menard, S. (2002). Applied logistic regression analysis (2nd ed.). Thousand Oaks, CA: Sage. Mislevy, R., & Huang, C. -W. (2007). Measurement models as narrative structures. In M. Von Davier & C. H. Carstensen (Eds.), Multivariate and mixture distribution Rasch models: Extensions and applications. New York: Springer. Ostroff, C., & Kozlowski, S. (1992). Organizational socialization as a learning process: The role of information acquisition. Personnel Psychology, 45, 849-874. Payne, R., & Clark, M. (2003). Dispositional and situational determinants of trust in two types of managers. International Journal of Human Resource Management, 14, 128-138. 144 Downloaded from orm.sagepub.com at Hong Kong Inst of Education Library on March 20, 2012 Carter et al. 145 Personnel Decisions International. (1997). Selection systems test scale manual. Unpublished document. Minneapolis, MN: Author. Reise, S. P., & Gomel, J. N. (1995). Modeling qualitative variation within latent trait dimensions: Application of mixed-measurement to personality assessment. Multivariate Behavioral Research, 30, 341-358. Reise, S. P., & Waller, N. G. (2003). How many IRT parameter does it take to model personality items? Psychological Methods, 8, 164-184. Rost, J. (1991). A logistic mixture distribution for polychotomous item responses. British. Journal of Mathematical and Statistical Psychology, 44, 75-92. Rost, J. (1997). Logistic mixture models. In W. J. van der Linden & R. K. Hambleton (Eds.), Handbook of modern item response theory (pp. 449-463). New York: Springer. Rost, J., & von Davier, M. (1994). A conditional item-fit index for Rasch models. Applied Psychological Measurement, 18, 171-182. Rousseau, D. M., Sitkin, S. B., Burt, R. S., & Camerer, C. (1998). Not so different after all: A cross-discipline view of trust. Academy of Management Review, 23, 393-404. Ryan, A. M., Horvath, M., Ployhart, R. E., Schmitt, N., & Slade, L. (2000). Hypothesizing differential item functioning in global employee opinion surveys. Personnel Psychology, 53, 531-562. Schwarz, G. E. (1978). Estimating the dimension of a model. Annals of Statistics, 6, 461-464. Sheskin, D. J. (2004). Handbook of parametric and non-parametric statistical procedures (3rd ed.). Boca Raton, FL: Chapman & Hall/CRC. Smit, A., Kelderman, H., & van der Flier, H. (2003). Latent trait latent class analysis of an Eysenck personality questionnaire. Methods of Psychological Research Online, 8, 23-50. Smith, P. C., Kendall, L. M., & Hulin, C. L. (1969). The measurement of satisfaction in work and retirement: A strategy for the study of attitudes. Skokie, IL: Rand-McNally. Tay, L., Drasgow, F., Rounds, J., & Williams, B. A. (2009). Fitting measurement models to vocational interest data: Are dominance models ideal? Journal of Applied Psychology, 94, 1287-1304. Thissen, D., Chen, W.-H, & Bock, R. D. (2003). Multilog (version 7) [Computer software]. Lincolnwood, IL: Scientific Software International. Thissen, D. & Steinberg, L. (1986). A taxonomy of item response models. Psychometrika, 51, 567-577. Vermunt, J. K., & Magidson, J. (2005). LatentGOLD (v4.5). Belmont, MA: Statistical Innovations, Inc. von Davier, M. (2001). WINMIRA 2001: Windows mixed Rasch model analysis [Computer software and User manual]. Kiel, the Netherlands: Institute for Science Education. von Davier, M., Rost, J., & Carstensen, C. H. (2007). Introduction: Extending the Rasch model. In M. von Davier & C. H. Carstensen (Eds.), Multivariate and mixture distribution Rasch models: Extensions and applications. New York: Springer. Wang, M., & Russell, S. S. (2005). Measurement equivalence of the Job Descriptive Index across Chinese and American workers: Results from confirmatory factor analysis and item response theory. Educational and Psychological Measurement, 65, 709-732. White, L. A., Nord, R. D., Mael, F. A., & Young, M. C. (1993). The Assessment of Background and Life Experiences (ABLE). In T. Trent & J. H. Laurence (Eds.), Adaptability screening for the armed forces (pp. 101-162). Washington, DC: Office of Assistant secretary of Defense (Force Management and Personnel). Wilde, G. (1970). Neurotische labiliteit gemeten volgens de vragenlijstmethode [Neurotic ability measured by the questionnaire method]. Amsterdam: Van Rossen. Worthy, M. (1969). Note on scoring midpoint responses in extreme response style scores. Psychological Reports, 24, 189-190. Zickar, M. J. (2001). Conquering the next frontier: Modeling personality data with item response theory. In B. Roberts & R. Hogan (Eds.), Applied personality psychology: The intersection of personality and I/O psychology (pp. 141-158). Washington, DC: American Psychological Association. 145 Downloaded from orm.sagepub.com at Hong Kong Inst of Education Library on March 20, 2012 146 Organizational Research Methods 14(1) Zickar, M. J., & Broadfoot, A. A. (2009). The partial revival of a dead horse? Comparing classical test theory and item response theory. In C. E. Lance & R. J. Vandenberg (Eds.), Statistical and methodological myths and urban legends: Doctrine, verity, and fable in the organizational and social sciences (pp. 37-60). New York: Routledge. Zickar, M. J., Gibby, R. E., & Robie, C. (2004). Uncovering faking samples in applicant, incumbent, and experimental data sets: An application of mixed-model item response theory. Organizational Research Methods, 7, 168-190. Zickar, M. J., & Robie, C. (1999). Modeling faking good on personality items: An item-level analysis. Journal of Applied Psychology, 84, 551-563. Bios Nathan T. Carter is currently a doctoral student in Industrial-Organizational Psychology at Bowling Green State University. His research concerns the application of psychometric techniques in organizational and educational settings. He is also interested in individual differences and the history of applied psychology. Dev K. Dalal is currently a doctoral student in the Industrial-Organizational Psychology program at Bowling Green State University. His research interests include methodological issues as applied to behavioral and applied research, application of psychometric theories to measurement issues, and investigating how individuals respond to items. Christopher J. Lake is a graduate student currently working toward his PhD in Industrial-Organizational Psychology at Bowling Green State University. His research focuses on testing, measurement, and methodological issues in the social sciences. Bing C. Lin is a doctoral student in the Industrial-Organizational Psychology area in the Portland State University Applied Psychology program. His research interests include various occupational health psychology topics such as interruptions and recovery at work. In addition, he is interested in the application of psychometric techniques to organizational issues. Michael J. Zickar is an associate professor of Psychology at Bowling Green State University where he is also department chair. He has published widely in the area of psychological measurement as well as the history of applied psychology. 146 Downloaded from orm.sagepub.com at Hong Kong Inst of Education Library on March 20, 2012