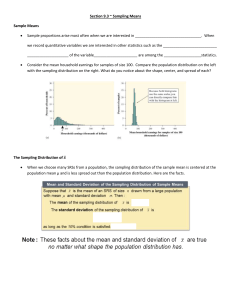
Sampling Distribution of Mean Young men's heights are roughly bell
advertisement

Sampling Distribution of Mean Young men’s heights are roughly bell-shaped with a mean of 70 inches (50 1000 ) and a standard deviation of 2.5 inches. A randomly selected man will on average be 50 1000 , but any value between 0 00 5 5 and 60 300 would not be unusual. Suppose we took a sample of 12 men, measured their heights and averaged them to get the statistic x. What would you expect to get? On average you would expect it to be 70 inches, but each sample may be a little higher or lower. How much? What values would be a typical range? What would be the shape of the histogram of X? • The basic statistic for a binary variable is the sample proportion, and the most basic statistic for a numerical variable is the sample mean, so these are the sampling distributions we will discuss. If you go further in statistics you will learn the sampling distributions of many different statistics. Sampling Distribution of Mean In general suppose X is a numerical variable with mean µX and standard deviation σX . The set of values of the sample mean X if all possible samples of size n is the sampling distribution of the mean and has three properties • It’s mean is µX = µX . • It’s standard error is σX σX = √ n . • If n is big enough its shape is roughly normal. • The mean looks like a pretty crazy thing but it is not. It says that X may be a little more or less than µX but on average it should give µX . • The formula for the standard deviation says that the more variation on X the more variation in X, which makes sense, and the bigger n is the less variation there is in X. Think of variation as all cancelling out. So you will get some tall people and some short people, but it would be really hard to have all tall people in a big sample so that the average was far from the mean. 1 The Fine Print Once again everything assumes the SRS Assumption (the sample is a simple random sample) and the formula for the standard error assumes sampling with replacement, but is a fine approximation as long as the sample and population satisfy the Large Population Assumption. The last fact relies on the Central Limit Theorem: Central Limit Theorem If X is any distribution, as n gets larger the distribution of X approaches a normal distribution. When n is small it looks like the distribution of X, but as it gets larger it becomes more unimodal, then more symmetric, then very close to normal. • The Central Limit Theorem is the basic mathematics that makes all of statistics tick, because it allows us to use the normal distribution to calculate things. • That funny formula for the normal distribution essentially comes from here, because of all possible distributions, this is the one that this process converges to. So that is why the normal distribution is the best model for symmetric unimodal distributions. • A fuzzy version of the CLT is why symmmetric unimodal distributions occur so frequently. Many random processes can be viewed as the sum (or average) of a bunch of relatively independent small effects. Such a sum is necessarily close to a normal distribution. Central Limit Theorem • As n gets bigger notice how the bumps get ironed out by the averaging process. The last thing that remains is the skew, and as n gets larger that goes away as well. 2 The 0 : 15 : 40 Rule The effect of the Central Limit Theorem means X is roughly normal if n is big enough or of X is close enough to normal, or some combination. The rule of thumb is the 0 : 15 : 40 Rule: X can be taken to be normal if one of the following conditions is met: Either... i X is known to be normal ...or... ii n ≥ 15 and X is not too skew, no major outliers ...or... iii n ≥ 40 • This is a complicated rule. I will give you a mnemonic next time to help you remember it. • Remember X refers to the population distribution and X to the sampling distribution. It is really important to keep them straight. The 0 : 15 : 40 rule uses knowledge of the pop. dist. to get information about the sampling dist. • In practice you will meet the first condition if the problem tells you X is normal, or bellshaped. You will meet the second condition if you have access to a histogram so you can see it is not too skewed. You will meet the third condition if the sample is big enough, so that is the most straightforward one and the first one to check. Example Young American men’s heights are bell-shaped with a mean of 70 inches and an s.d. of 2.5 inches. You take a simple random sample of 12 young American men and compute their average height X. Find the mean and standard error of X. What is the chance that the average you get will be more than 6 feet? Less than 50 600 ? Between what two values can we be 95% sure your answer will fall? It is an SRS. We have µX = 70, σX = 2.5, n = 12. This tells us the mean of X is µX = µX = 70 in Since there are more than 20 · 12 = 240 young American men, the Independence/Large Population assumption is met, so the standard error is 2.5 σX σX = √ = √ = .722 n 12 • 3 in Example Recall µX = 70, σX = 2.5, n = 12. We found √ µX = 70 σX = 2.5/ 12 = .722 n = 12 < 15 so we cannot possibly meet condition (ii) in the 0 : 15 : 40 rule (requires n ≥ 15) or condition (iii) (requires n ≥ 40), but we are told X is bellshaped, so we meet condition (i), and so we meet this assumption. Therefore we can assume X is normal. What is the chance that the average you get will be more than 6 feet? √ P X > 72 = 1 − normdist(72, 70, 2.5/ 12, 1) = .279% What is the chance X will be less than 50 600 ? √ P ( X < 66 = normdist(66, 70, 2.5/ 12, 1) = 1.49 × 10−8 = .00000149% • If it meets one of the conditions of 0 : 15 : 40, you don’t have to think about the other two. I just went through them to give you more experience with it. • So if you got an average of less than 50 600 , either it was a one in a hundred million coincidence, or you are wrong about its being a random sample or about the mean and standard deviation of men’s heights. That is an idea we will come back to. If a really low probability event happens, it probably means you are wrong in one of the assumptions you used to calculate that probability. More Example Recall µX = 70, σX = 2.5, n = 12. We found √ µX = 70 σX = 2.5/ 12 = .722 and X is normal. Between what two values will 95% of samples’ sample mean fall? We could use Empirical Rule and go up and down 2 standard errors from the mean, but lets be more precise and recall we get exactly 95% in a normal dist if we go up and down 1.96σX from µX . σX 70 ± 1.96 √ = 70 ± 1.96 × .722 = 70 ± 1.41 = [68.6, 71.4] in n • That is a pretty narrow range, compared to the usual range we got for the original variable X. 4 Another Example The mean cost of a haircut for an American college student is $18 with a standard deviation of $22. What is the probability that a simple random sample of 52 college students will have an average haircut of less than $16? Between $17 and $19? Between what two values would 95% of all such samples fall? If I actually got an average of 30 in my sample, would that suggest there was something wrong with my sampling or with my presumed mean and s.d.? Asking about the average of a sample of 52 is asking about X. It says it is a simple random sample. µX = µX = 18. There are more than 20 · 52 = 1040 college students (large pop) so σX 22 σX = √ = √ = 3.05 n 52 • Another Example µX = 18, µX = 18, σX = 22, σX n = 52 22 = √ = 3.05 52 We don’t know the shape of the population distribution so we cannot use the first two conditions (i-ii) (in fact because σ is about the same size as µ and X must be positive, it is surely skewed right). but n ≥ 40 so by condition (iii) we can assume X is normal. Chance X is less than 16 : √ P X < 16 = normdist 16, 18, 22/ 52, 1 = 25.6% • If X is always positive (like haircut costs) and µ is about the same as σ, then if X were normal we would know about a sixth of the time X would be below µ − σ, which would be negative, which makes no sense. Since X stops at 0 to have that big a σ it would have to get very large occasionally, so it would have to be skewed right. 5 More Another Example µX = 18, µX = 18, σX = 22, n = 52 22 σX = √ = 3.05 52 X is approximately normal. Chance between 17 and 19 : √ P 17 < X < 19 = normdist 19, 18, 22/ 52, 1 √ − normdist 17, 18, 22/ 52, 1 = 25.7% 95% of samples give an average haircut cost (X) between 18 ± 1.96σX = 18 ± 1.96 · 3.05 = 18 ± 5.98 = [12.0, 24.0] dollars • Finish Another Example Chance of getting over 30 : √ P X > 30 = 1 − normdist 30, 18, 22/ 52, 1 = 4 × 10−5 . Since this would be a very surprising result assuming the given mean and standard deviation and other assumptions, it suggests one of our assumptions is wrong. • Example: You Try College students heights are bimodal and symmetric with a mean of 68 inches and an s.d. of 3.5. If you take a simple random sample of 18 college students and compute their average height X, find the mean and standard error of X and check all assumptions. What is the probability you will get an average height for your sample over 70 inches? It says it is a simple random sample. There are more than 20 · 18 college students, so the Large Pop. assumption is met. We see n = 18 ≥ 15 and we are 6 told X is symmetric, so the second condition of the 0 : 15 : 40 rule is met, so we can assume X is normal. µX = µX = 68 3.5 σX σX = √ = √ = 0.825. n 18 Chance that X is more than 70 is √ P X > 70 = 1 − normdist 70, 68, 3.5/ 18, 1 = 0.767%. • We were told X is bimodal, so we know it does not meet assumption one, and n = 18 < 40 so it does not meet assumption 3. Lecture 17 Key Points After watching this lecture you should be able to • say what we mean by the sampling distribution of X, and what it represents • calculate the mean and standard deviation of X. • check the Independence/ Large Population assumption and what it tells you (that the s.d. formula is correct). • check the Normality / 0 : 15 : 40 Rule and what it tells you (can use normdist) • calculate probabilities of X using normdist. • Categorical Vs. Numerical If the original variable (pop. dist.) is CATEGORICAL Variable is a yes or no question. parameter=p, statistic=P̂ , r p(1 − p) n Assumptions: Large Pop (pop ≥ 20 * sample) and Rule of 15 (np ≥ 15, n(1 − p) ≥ 15) µP̂ = p σP̂ = If the original variable (pop. dist.) is Numerical Variable is a numerical question X, with mean µ and s.d. σ. parameter=µ, statistic=X, σX σX = √ n Assumptions: Large Pop (pop ≥ 20 * sample) and 0 : 15 : 40 Rule µX = µX 7