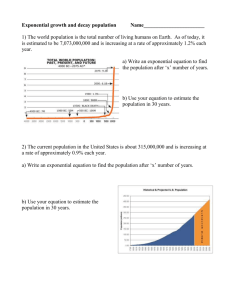
poster - Department of Statistics
advertisement

2
Letthe
F =base
(V ×X
)∪(E ×X
) be the index
set for
theideas
cothat
thealgorithm
notion of based
“overlapping
cluster”
used in the and
measure
is discrete.
However,
the
mean
field
on auxiliary
exponential
ordinates
of φto(the
If e = (a, b)
∈ E, then
work on structured mean field by Geiger et al. (2006). apply
directly
thepotentials).
general exponential
family—this
families.
it isbeunderstood
that
the detail
following
inclusion
Some v-acyclic graphs have overlapping clusters, some will
discussed in
more
in Section
3. holds on
Thedo
notion
of
vand
b-acyclic
subgraphs
is
different
the induced sigma-algebra: σ(φe,· (X)) ⊇ σ(Xa , Xb ).
not; and moreover, the computational dichotomy
2
Q ⊂ P, in which
the
log
partition
and
moments
can
We
then
the
fundamental
equation of meanF = (V
)∪(E
×X
) bewrite
the index
set for
the cothatwe
the
notion here
of “overlapping
used ofinv-the
Similarly,
if×X
v can
∈
V , σ(φ
establish
does not holdcluster”
if the notion
and Let
v,· (X)) ⊇ σ(Xa ). We lose no
ordinates
of by
φ (the
potentials).
If eof=potentials
(a, b) ∈ E,
on structured
mean
field by Geiger
(2006).
generality
requiring
existence
forthen
all
b-acyclic
subgraphs
is replaced
by thatetofal.
overlapping
be computed.work
field
approximation:
itvertices
is understood
thatsince
the following
inclusion
holdscoron
Some
v-acyclic
graphs
some
and edges,
we can always
set their
clusters.
Note
thathave
otheroverlapping
variational clusters,
approximations
induced parameter
sigma-algebra:
σ(φe,· (X))∗ ⊇ σ(Xa , Xb ).
do not;
moreover, Propagation
the computational
responding
to zero.
such and
as Expectation
also havedichotomy
a subgraph the
An intuitivelywe appealing
approach
to
making
this
seµ&⊇−σ(X
Aa ).(µ)
µ no
∈ MMF } =
V , σ(φv,· (X))
We :lose
establish
here does
notand
holdQiif 2003).
the notion
of this
v- and
interpretation
(Minka
While
sub- Similarly, if v ∈ sup{%θ,
by requiring
b-acyclic
subgraphs
ishappens
replaced
of
overlapping
graphuse
sometimes
toby
bethat
b-acyclic,
there is no generality
lection is to make
of the
graphical
representation
2.2 Convex
duality existence of potentials for all
sup{%ω,
&+
%ϑ,set
Γ(τ
)&cor− A∗ (τ ) : τ ∈ N },
(6)
specialNote
distinction
between
v- and b-acyclic
graphical vertices and edges, since we τ
can
always
their
clusters.
that other
variational
approximations
of the exponential
family and
a subset
of the
A simple parameter
but fundamental
inPropagation
the to
casechoose
of Bethe-energy
variational
responding
to zero.property of exponential
suchapproximations
as Expectation
also have
a subgraph
families where
is that theθgradient
and
Hessian
of the
log slight abuse of notation:
approximations.
why
we focus
on this
meansubfield In
interpretation
(MinkaThis
and
Qi
2003).
While
edges, E ! ⊂ E,
to represent
a istractable
subfamily.
=
(ω,
ϑ).
Note
the
partition
function
have the following forms:
approximations.
graph
sometimes happens to be b-acyclic, there is no
2.2
Convex
duality
particular, inspecial
defining
this
subfamily
we retain
only
we use A to denote the partition function of both exbetween
v- follows.
and b-acyclic
graphical
Thedistinction
paper is organized
as
We present
a ba∇A(θ) = E[φ(X
θ )]
but fundamental
property
of exponential
in the
of Bethe-energy
the potentialsapproximations
with
indices
families;
the
notation
can always be disamsic introduction
to case
structured
mean field variational
in Section 2. A simple ponential
H(A(θ))
=
Var[φ(X
)].
(3)
θ
families is that the gradient and Hessian of the log
approximations.
This
why weand
focus
on meandevelopfield
We then discuss
ourisanalysis
algorithmic
biguated
byfollowing
inspecting
partition function
have the
forms: the dimensionality of the pa! approximations.
ments
in
Section
3.
We
present
empirical
results
to
F = {fsupport
∈ F our
:f claims
= (v,in ·)Section
for 4v and
∈ Vwe or
The second identity implies
we can
Howtoconvexity,
toconstruct
constructawhich
avariational
variational
formulationforforA?A?
How
formulation
present
our
rameter
vector.
The paper is organized as follows. We present a bause
in
conjunction
with
the
Legendre-Fenchel
trans∇A(θ) = E[φ(X θ )]
conclusionsfin=
Section
5. for e ∈ E ! }.
(e, ·)
sic introduction
to structured
mean field in Section 2.
formation to establish an alternative form for A.
Key
concept:
convex
duality
convex.
• •Key
concept:
convex
duality
AA
is is
convex.
=
Var[φ(X
(3). . .). ) (6) makes it clear that
θ )]. (recall
Background
We then discuss our analysis and algorithmic developTheH(A(θ))
right-hand
side
of(recall
Equation
Inference problem:
Hence the number of nonzero entries in J (c) is equal to
the number of edges in E\E ! that have an endpoint in
V (c) and each entry is a quantity that does not depend
on τ (c) . This shows that:
Optimization of Structured Mean Field Objectives
=
X
log
c∈cc(G! )
=
X
valid for any ζ,†
∈ Ξ.
† Department
(c)
3.3
Dichotomy of tractable mean field subgraphs
We therefore have:
[g]
h
!
!
}
}
g∈F \F "
T T
!
!
!
∗
g
!(2)
[g]
h
[g]
!
f
h,f
!
}
}
"
k−1
k
k−1
k−1
k
0
0
1
k−1
k−2
1
0
k−2
k−1
"
Error
1
k−1
"
k−2
k
k−1
10
8
"
6
Error
}
}
F
F (c) (ct ) !! ∂
∼
Jf,gX(τ )(t)=!X(t −"1)
P(Y
a = s, Yb = t),
#
∂τf !(ct ) (ct )
MRF P
,ω
+ B (ct ) (X(t − 1))ϑ ,
!(1)
[g]
h
g,h
"
1
"
g
[g]
h
0
"
k−1
[g]
[g]
Optimization of v-acyclic components
2
[g]
h
[g]
An interesting property of this coordinate ascent algorithm is that it is guaranteed to converge to a local
optimum (Wainwright and Jordan 2008). This can be
seen from Equation (6) by using the fact that the tition
orig- function coincide with the quantity of interest:
inal problem in Equation (4) is convex.
X
`
´
k−2
}
y2 ∈X
θh =
yk−1 ∈X
4
Figure 3: Error
... (1) p1
ω (1) Recall that for
τ binaryp0 random variables Xs with
a function of th
pk
"
τ
"
!
pling weights (2)
θs,s and Yobservation
weights θs , the
2 to a
s (pk−1 ,pk ),(yk−1 ,s )
corresponds
b
ω (2) naive Gibbs τsampler
where h = ((v, w), (x, y)), (v, w) ∈ pg , (x, y) ∈ X 2 .
edges in G! tha
is defined as the MarkovOne
chain
can
check
this is achieved
the following SMF2inis not. Se
We can
getEquation
all thethat
derivatives
ofall
theh with
log-partition
where Y µ = (Y1 , . . . , Ym ).
Using
(3), we have for
=
((v, w), (x, y)),function
X(1), X(2), . . . where only coordinateWhy?
st is resampled
where B is the matrix defined as follows:
0
choice:
0
one
shot
using
sum-product
(v, w)
∈ pg , (x, y) ∈ X 2 :
(c)
8
at
time
t
with
transition
probabilities:
There
are
three
subcases
to
consider:
Figure 2: An example of the notation used in this
Bf,gthe
(X(tblock
− 1))Gibbs
=1[f =
(a, s)]×with
log τh − log τv,x + log τ(a,v),(s,x)
if v = p0
can check easily that
sampler
>
<
[g]
[g]
4 Experim
(1)
(k)
section. This #corresponds to the inference problem in
∂Z
∂A
log
τ
−
log
τ
(c)by:
blocks VForm
, . . . ,of
V J :has a transition1[|{a,
kernel
given
[g]
v,x
[g]
h
[g]
[g]
b} ∩ V | = 1]×
=
θ
=
Z
×
=
Z
×
µ
,
(c) the mean field# subgraph in
h
[g]
[g] − log τw,yh if w = pk−1
Figure 3: E
+ log τ(pk−1 ,b),(y,t)
Ya Figure 1, left column, bot! one of the ∂vertices a, b belongs to gV =
>
1. Exactly
:
edge
(a,
b)
∂θ
∂θ
:
X
(t)
X(t
−
∼
...
p1
#
p0 1) )
s
! (1)
1[X
(t
−
1)
=
s],
h
h
Γ(τ
(ct )
t
We
b
tom
row.
The
box
indicate
which
nodes
are
involved
in
log τh − log τv,x
otherwise
X (t)!X(t
1) )
∼ = (c)
(c)τ )]
aperformed
function ex
o
Jf,g
E[φ
pk
gV(Y
Suppose
a−(τ
∈
V
,
b
∈
/
.
Since
a,
b
are
[g]
$
(
20
References
&
the
auxiliary
exponential
family
P
used
to
compute
"
#
%
'
[g]
[g]
∂τ
!(c)
Y
f
where A = log Z SMF1
. This shows that one execution of
corresponds
and where
\F ! and
((a, b),
=f
g.the
(ct ) , g ∈
= vertex
18 !
NMF
2
D.
Barber
and
W.
Wiegerinck.
Tractable
variational strucMRF
P !(ctf) ,∈ω F
+ components,
B (ctF) (X(t
− 1))ϑ
, (s, t))by
σ θpath
θs! ,s
X
(t
−
1)
in different
connected
then
Jf,g fora all f . Bernoulli
The edges
τ (1)bin the
How
can
we
get,hthe
partial
derivative
with
respect
?
st +pg are in bold
s
! to
where
=
((v,
w),
(x,
y)),
(v,
w)
∈
p
,
(x,
y)
∈
X
.
t
φ((x
)i,j∈{1,...,
g
sum-product
at
the
cost
of
O(|p
|)
yields
|F
|
entries.
SMF2
in G
tures
In i,j
Advances
16
g for approximating graphical models. edges
and the edge corresponding to g is thesbold
dashed
Note that the ∂
sparsity
pattern
of Bare
follows
that
! ∈N (s
in
Neural
Information
Processing
Systems,
pages
183–
Hammersley-Clifford
theorem
they
indepen)
t
=
P(Y
= t) from line between
14
b
a = s, Yofb sampling
where B is the
matrix
defined as
Ya and τ
Yb (2)
.
189,
Cambridge,
1999.
Press. SMF2 is no
Using
Equation
(3),
have for
allJacobian
h = ((v,MA,
w),
(x,MIT
y)),
Next,
we define
thewe
following
two
matrices:
of J.
Moreover,
thefollows:
complexity
12
dent, (c)
soMRF(P
that: !(c) , ·) ∂τ
f same (up to a multiplicative conD. M. Blei and M. I. Jordan. Variational
inference
is the
with
θ!1:121–
=forT1 , w
(v, w) ∈ pg , (x, y) ∈ X 2 :
−1
Dirichlet
process
mixtures.
Bayesian
Analysis,
[g]
10
Figure
2:
An
example
of
the
notation
used
in
this
Bf,g (X(t − 1)) =1[f = (a, s)]×
!
"
!
"
where σ(x) = {1+exp(−x)} . This closely resembles
∂θ
∂Z [g]
stant) as the complexity
of computing ∇A(c) (·). Both
as used in statist
∂
10
Experiments
8
section. This corresponds to the inference problem in
(c)
I
=
; [g]
K 144,
= 2005.h
(c)
[g]
require
executing
sum-product
on
the
same
tree.
[g]
SMF2
∩ Va =
| =s)P(Y
1]× b = t)
De Freitas,
M. I. Jordan,
S.Expe
Rus- an
Jf,g (τ ) =1[|{a, b}P(Y
∂τ P. Hojen-Sorensen,
tion4and
function
h,f
thethisnaive
mean
field
coordinate
∂Z
∂θh[g] g,h∂A N. sell.
6
[g]
the mean field
subgraph
in Figure
1, see
left immediately
column,
bot-that Jupdates:
From
expansion,
we
[g] f
f,g (τ )
Variational
MCMC.
In Proceedings of the SevenSMF1
∂τ
=
Z
×
=
Z
×
µ
,
f
that Intelliabsolute
1) = s],
h on Uncertainty in so
b (t −when
[g]
[g] teenth Conference
Artificial
This parallel 1[X
breaks
one or several of the
4
tomconrow. The
which
nodes
are involved
in as in the
willbox
notindicate
have the
same
sparsity
properties
20
8
! ∂θ
!Morgan Kaufmann.
∂θ
&
%
'
gence,
San
Mateo,
CA,
2001.
where#I has
h size |F \F | × Nh and K has size N × |F |,
We
perform
SMF1
∂ ! is b-acyclic. In this case there
2
nected!(c)components
is
the auxiliary
exponential
v-acyclic
case.family P [g] used to compute
Adding
improves
the
We
used
the u
18
! ,s µs
! (t − 1)edges
NMF
µ
(t)
←
σ
θ
+
θ
.
D.
Geiger,
C.
Meek,
and
Y.
Wexler.
A
variational
inferand where fno∈corresponding
F ,g=
∈ F \Ftractable
and
b),=
(s,Gibbs
t))
=
g.
s
s
s
τa,s((a,
τb,tblock
N = g∈F \F " |pg |.
τ b,t sampler,Jf,gwhile
t the path p tare in bold
t
0
for all One
f . The
edges
in
SMF2
g
ence
procedure
allowing
internal
structure
for
overlap[g]
[g]
16
subgra
10
10
10
10
way to find these partial derivatives
is to con- quality
∂τ
ATime
= log10Z . This
shows
one
of tractable
ofwhere
the
approximation
pingthat
clusters
andexecution
deterministic constraints.
Journal of
6
s! ∈N (salgorithm.
discusspattern
in fthe following
section)
mean and
fieldthe
is edge
corresponding
to dynamic
g is the programming
bold dashed
t)
Note
that (as
the we
sparsity
of B follows
that
struct
a specialized
We
can
finally
derive
an
expression
for
J,
using
the
14
point
updates
o
Artificial
Intelligence !Research, 27:1–23,
2006.
φ((x
i,j )i,j∈
sum-product at the cost of O(|p
still tractable
at of
a computational
higher
betweenThis
Ya and
g |) yields |F | entries.
taskYis
of J. Moreover,
the=
complexity
sampling
b . non-trivial: to see why, notice that when
τalbeit
= (a, s)]from costline
b,t × 1[f
12
generalization
of
the
chain
rule
for
Jacobian
matrices:
Before
performin
A. Globerson and T. Jaakkola. Approximate
inference
usfunction estimate as a
!(c) than in the v-acyclic case.
the partial derivative is taken with respect to a coordi- Figure 4: Error in the partition
, ·) is the same (up to a multiplicative conMRF(P
Tsubgraph
T
ing10planar graph decomposition. In Advances in Neural
Using
a
b-acyclic
is
4
function
of
the
running
time
in
milliseconds
(abscissa
J
=
K
I
.
Next, we define the following two
Jacobian matrices: ically using dire
nateNow
τf corresponding
to an between
edge in the path
pg , there
(c)
Information Processing Systems, Cambridge, MA, 2006.
the parallel
block
Gibbs
and
stant) asRelation
the complexity
of computing
(·). Both
in a sampling
log scale) for three
algorithms: naive mean field
to
block
Gibbs
sampling
(c)∇A
8 Press.
MIT
thatwith
we have
der
significantly
morecarrying
expensive
2. require
Both executing
a 3.5
and Optimization
bsum-product
belong toonV
: We
claim that this are factors τf that appear both in the numerator and (NMF),
θ! =
After
matrix
we
obtain:
v-acyclic structured
mean!fieldthis
(SMF1)
and multiplication,
of
b-acyclic
components
the
same
tree.
[g]
"
!
"
v-acyclic
mean
is the
following: let
6 and Y. Wu. Sequential mean field variational analG. Hua
!
denominator:
"
#we seestructured
From this expansion,
immediately that
Jf,g (τfields
)
∂θh
∂Z [g]
b-acyclic mean field (SMF2).
2cannot, in fact, occur
as the
used
in s
ysis of structured
deformable shapes. Since
Computer
Vision
compu
(2) ! in v-acyclic components.
(2)
(2)
!
I
=
;
K
=
4
This parallel
breaks
when
one
or
several
of
the
conwill
not
have
the
same
sparsity
properties
as
in
the
X
X
∼
MRF
ω
+
B
(X
)ϑ
Proposition
6 [g]
When
G
is
b-acyclic,
the
embedding
MRF(P,
θ)
denote
the
distribution
of
X
.
Then
one
and Image Understanding,
101:87–99, 2006.
We now turn to the
of structured mean field when
t−1
θ
t !caset−1
∂τf h,f
tion functio
g,h
expensive,
we fir
” X
Suppose
the contrary:
a, bthere
belong
to thecase.
2
τ(p0 ,p1 ),(y0 ,y1 )
nected
components
b-acyclic.
Insince
this case
is
∂ n“ X
Jacobian has ∂θ
thehform:
v-acyclic
J. B. Lasserre.
Global optimization with polynomials and
there areisb-acyclic
components.
´
`
"
P
Jf,g (τ ) =
τ(a,p1 ),(s,s )
tialon
gains
accu
so
thatinabso
the0problem of moments. SIAM Journal
Optimiza0same
no
tractable
block Gibbs
sampler,
"
connected
there
is a path
be- to find these
1 ∂τfpartial
8approxima"
s" τ(p0 ,p1 ),(y0 ,s ) where using the more expensive b-acyclic
0 corresponding
1
2component,
3
4 while
10 11:796–817,
10 2000.
10
10
10
y
∈X
s
One
way
derivatives
is
to
con[g]
!
!
1
tion,
SinceXwe are
treating graphical models that have
only
µw,y| × N and K has size N ×
To in
simplify
the notation
wemean
assume
that
where
I has size |F
|F |, the following str
Time
> \F
Temperature
(as we discuss
the
following
section)
field
is there is a
0
1
X
!(c)
θ
}
µ
}
Ya
}
+ log τ(pk−1 ,b),(y,t) − log τw,y
:
τ(pk−1 ,pk ),(yk−1 ,yk )
cou- >
log×τh`−P
log
τv,x
´
}
if w = pk−1
otherwise
}
}
τ
Error
}
0
1
2
3
4
Error
Error
0
1
2
3
4
>
0.1 0.3
× 1[x =
v=
p0
#
structb)}
a specialized dynamic programmingτ(palgorithm.
tion pays off.
>
T. s]
Minka and Y.ifQi.
Tree-structured
approximations
by
τf
k−2 ,pk−1 ),(yk−2 ,yk−1 )
We used
t
tween asingle
and
b.atThis
meansthat
that
Ethe entire
∪ {(a,
<
b-acyclic
spans
graph
pairwise
wethat
drop
from now
`P
´ on the quadratic
˘ 1[y=t]
¯ propagation.
× topotentials,
· · why,
·
N
=
|p
|.
still tractable
albeit
a component
computational
cost
higher
[g]
"
This
task
is
non-trivial:
see
notice
when
expectation
In Advances in Neural Infor1
[g]
g
g∈F
\F
"
τ
1
1
µ
×
−
if
w
=
p
2
0.9
0.8
v,x the τ
We also performed timing
k−1
(τexperiments
) = Z ×to compare
s" (pk−2 ,pk−1 ),(yk−2 ,s )
tractable
su
y2 ∈X with
∈X random
Figure
4:τv,x
Error
in the
partition
function
estimate
as aapp
G.
The
derivation
is essentially
identical
when
Processing
Systems,
Cambridge,
MA,
2003.the
MIT
f mation
dependency
onyk−1
the
variable state
spaces,behavior
|X | J.f,g
has
cycle,
apartition
contradiction.
thethere
partial derivative
is20 taken
respect
to
a coordiSMF1
inathe
v-acyclic
case. function
>
Figurethan
3: Error
in
the
estimate
as
References
[g]
>
convergence
of
the
mean
field
approximations
[g]
o
B(X
)
Press.
J(τ
)
>
µ
time inthe
milliseconds
(abscissa
SMF1
τ(p1 in
µv,xfunction of the
0 edge
,p the
),(y path
,y )p , there
several connected
We can
finallywederive
forrunning
J, using
nate τft corresponding 18to an
: f an
0.4 SMF2
0.9
point
updat
graph
with t
− τexpression
a function of theare
temperature
of the components.
model.
SMF2.
As a baseline,
ran the
naive
NMF
× ` P k−1 k k−1 k g´
D.SMF1
Barberand
and W.
Wiegerinck.
Tractable variational
τfstruclog
scale)
three
algorithms:
mean
field
andfor
J.otherwise
R.
Anderson.
A mean naive
field theory
learnv,xinC.aPeterson
are
factors
τ
that
appear
both
in
the
numerator
and
"
τ
SMF2
f
"
generalization
ofThe
the
chain
foralgorithm
Jacobian
matrices:
mean
(curve
NMF graphical
on the graph).
are rule
tures field
for approximating
models.
In results
Advances
16
Before
perfo
0
1 s (pk−1 ,pk ),(yk−1 ,s )
ing
forstructured
neural
networks.
Systems,and
1: pos
ponents
0.2 components
0.6 more
3.5 Optimization
b-acyclic
corresponds
to a The
meanquantity
fieldofapproximation
(NMF),
v-acyclic
meanComplex
field (SMF1)
to compute
is:with
denominator:
in Neural in
Information
Processing
Systems,
pages
183– it
995–1019,
1987.
T
T
displayed
Figure
4.
We
can
see
that
in
this
model
!
b-acyclic
JMA,
=
K IMITmore
where
f. Press.
=time
((v,tow),
(x, y)) is
such mean
that field
(v, (SMF2).
w) ∈ pg ;
ically subusing
edges in G than SMF1: SMF1 0.5
is v-acyclic
while
189, Cambridge,
1999.
0
0 14
0
0.1
takes
one order of
magnitude
move from
L. K. Saul and M. I. Jordan. Exploiting
tractablethe
∂0.2 mean field
SMF2
appr
We
now
turn
to
the
case
of
structured
when
12
Jf,g is
equalfield,
to zero.structures in intractable networks. In Advances
M. Blei
andfield
M. I.tootherwise,
Jordan.
inference
for
The
task is thus more
than that of creatingD.naive
SMF2 is not. See text for more
n“ X
” X complex
Neu-hav
Jf,g (τdetails.
)=
P(Ya = s, Yb = t),
thatin we
mean
v-acyclicVariational
structured
mean
τ
∂
(p
,p
),(y
,y
)
0
1
0
1
After
carrying
this
matrix
we obtain:
in486–492,
Figure 1,
there are b-acyclic components. ∂τf
Dirichlet
process
Bayesian
Analysis,
1:121–
10
ral Information Processing
Systems 8, pages
` algorithm
"
P
Jf,g (τ ) = a dynamic
τ(a,p
two orders
ofmixtures.
magnitude
more time
to move
from multiplication,
programming
of the´ type used and
1 ),(s,s )
144, 2005.
∂τf
")
Cambridge,
MA,
1996.
MIT
Press.
τ
!
!
"
(p
,p
),(y
,s
"
0
1
0
subgraph.
8
s
to b-acyclicThe
structured
mean
field
approximas
total
cost
ofand
computing
J is
O(|E | × |F
\F |), b-acyclicSince
1 ∈X
the co
for sum-product.
A ychain
rule
would need to be used,N.v-acyclic
To simplifywhere
the notation
that on
there
a
where
using the more
expensive
approxima!
De Freitas,
M.the
I. Jordan,
S.results
Rusthis timewe
theassume
probability
the is
right-hand
side
M.
J. Wainwright
and M.
I. Jordan. Variational
inference in
X
X
tions.
ThisP.isHojen-Sorensen,
consistent with
theoretical
Proposition
6
When
G
is
b-acyclic,
the
embedding
τ
6
(pk−2 ,pk−1 ),(yk−2 ,yk−1 )
which
is larger ofthan
the cost derived
in theThe
v-acyclic
sell. Variational MCMC.
In Proceedings
the Sevenchanging
f, g. The developed
4 Experiments
pays off.models:
view from the marginal
polytope.
expensive,
w
single b-acyclic
component
that spans
entire graph
` Pof the recursion for each
´
×
· · · the form
cannot
be decoupled
into athe
product
of marginals. Let
in Section
3.
Moreover,
the
bound
on the tiongraphical
Jacobian
has
the
form:
teenth
Conference
on
Uncertainty
in
Artificial
Intelli4
In
Forty-first
Annual
Allerton Conference
on
Communi"
τ
" (pk−2
,p
),(y
,s
)
case,
but
smaller
than
the
naive
dynamic
programming
In
Figure
3
we
s
complexity
of
this
naive
approach
can
be
shown
to
be
s
k−1
k−2
y
∈X
y
∈X
G. The derivation is essentially identical when there
log
partition
function
gets tighter
more edges are We cation,
2
k−1
gains
gence,
San Mateo,
CA, 2001.
Morgan as
Kaufmann.
also performed
timing
experiments
compare
the in
Control, and
Computing,
2003. to tial
2!
!
!
!
o
8
to C.
theMeek,
tractable
subgraph.
We performed
experiments
on
O(|Eτ|(p×|
F | ×| F \F |), which is considerable.
algorithm
at the convergence
beginning
of this
subsecdifferent
temper
pg = {acomponents.
= pthe
. .9, pIsing
: ∀i, (pi , pi+1 ) ∈ E }
[g] inferare several
connected
behavior
mean field
approximations
0 , p19, .×
k = bmodel:
D.added
Geiger,
and
Y.
Wexler. mentioned
A variational
k−1 ,pk ),(yk−1 ,yk )
M. J. Wainwright
and of
M.the
I. Jordan.
Log-determinant
reError
}
[g]
+ J (c) (τ )ϑ.
"
the definition of Γ:
Note that
Â(θ)
≤ A(θ),
which
ispurpose,
a)
very
only increase the quality of the global optimum. This
Γ(τ
ϑ
! useful property
!
tation;
for
this
we
introduce
the
following
∂Z
As awhen
consequence,
edges
in
Gin=the
(V,
E ) can
Consequence:
if∂A
a, b belong
The paper
organized
as inner
follows.
We present
ba∗vector no# ∇A(θ)
It willa∂G
be
useful to represent
this
update
in
=
Z
×
= Z to
×µ ,
mean-fieldadding
inference
is isused
loop
=
E[φ(X
)]
∂Γ
∂A
θ
g
does not imply that the local optimum found Dby only
the
Γ
(τ
)
=
E[φ
(Y
)]
different
cliques,
∂θ
∂θ
) = ωpurpose,
ϑg introduce
(τ ) − the (τ
)
introduction
to structured
mean
2.(τthis
g Moreover,
τSectionfor
the quality
of the
global
optimum.
Thisfield
f +
tation;
we
following
ofincrease
EM definition.
(Wainwright
and
Jordan
2008).
ifg in
µ sic
θ
H(A(θ))
=
Var[φ(X
)].
(3)
∂τ
∂τ
∂τ
θ
f
f
i
We
then
discuss
our
analysis
and
algorithmic
developY a ⊥⊥
Y
g∈F
\F
!!
!
does
not
imply
that
the
local
optimum
found
by
the
τ
ω
optimization procedure will always be superior, dbutE ⊆ E , with associated
mean field approximation definition.
where A = log Z . This
shows bthat one execution of
ments
inalways
Section be
3. superior,
We presentbut
empirical results to
optimization
procedure
will
we can
at the cost of O(|p |) yields |F | entries.
! The second identity implies convexity, whichsum-product
Ă(θ),
then
Ă(θ)
≤
Â(θ)
≤
A(θ).
Complexity
where four
∈
F the
.
support2our
claimsembedding
in Section 4 andJacobian
we present
we
show
in
the
experimental
section
that
empirically
Definition
The
is
(transChain
for Jacobian
matrices
we show in the experimental section that
empirically
conjunction
with
theA(θ)
Legendre-Fenchel
transDefinition 2 use
Thein embedding
is isthe
(trans-Next,
of computing
we
definerule
the following
two Jacobian
matrices:
Var !Jacobian
0 =⇒
convex
! 5.
!
conclusions
in Section
3
As
a
consequence,
adding
edges
in
G
=
(V,
E
)
can
formation
to
establish
an
alternative
form
for
A.
O(n)
It
will
be
useful
to
represent
this
update
in
vector
nogradient
O(n) an improvement
there
is
indeed
an
improvement
when
edges
are
added
there is indeed
when
edges
are
added
O(n )
Necessary optimality
condition:
posed)
Jacobian
matrix
of Γ:This posed) Jacobian matrix of Γ:
! ∂Z "
! ∂θ "
only
increase
the
quality
of
the
global
optimum.
tation;
for
this
purpose,
we
introduce
the
following
to
the
approximation.
%
$1 ∂Γ
;
K=
tointhe
2 ∗0the
Background
For
real-valued
function f ,I = ∂θ
not )ϑ
imply
that
by the
0 = ω does
+ J(τ
− ∇A
(τ
)local optimum found
∂τ
g an extended
First result: dichotomy
termsapproximation.
of a graph property, v-acyclic and
% definition. Definition
$ ∂Γ
∗
−1
J
=
∇A
=
∇A
g
the
Legendre-Fenchel
transformation
is
defined
as:
We optimization
also let!N denote
the set
realizable
moments but
of
procedure
willof always
be superior,
∂τf f,g
b-acyclic subgraphs
"
J
=
where#I has size |F \F | × N and
In
this
section,
we
review
the
principles
of
mean
field
T KThas size N × |F |,
when
theJacobian
family is regular
and
minimal
show
in this
theJ(τ
experimental
section
thatfrom
empirically
We also let N denote the set of realizable moments
ofwe
Note
that
set
is
formally
distinct
M
Definition
2
The
embedding
is
the
(transMF
=⇒
J
=
K
I
τQ.=
∇A
ω
+
)ϑ
∗
∂τ
f,g
0
N=
|p |.
f
!
! (x) = sup{"x, y# − f (y) : y ∈ dom(f )}.
f
approximation
and
set
the
notation.
Our
exposition
f ∈ Jacobian
F , g ∈ F matrix
\F . of Γ:
there is indeed
an improvement
when edges
are added for
particular,
its elements
have different
dimensionalposed)
Second result: improved
in the b-acyclic
subgraph
case
Q. algorithm
Note that
this set
is formally
distinct from M(in
follows the general treatment of variational methods
MFto the approximation.
We can finally derive an expression for J, using the
ity). Easy
? presented
$ ∂Γ %
!
!
in
Wainwright
and
Jordan
(2003)
where
the
of the chain rule for Jacobian matrices:
f ∈ F , g ∈ F \F .
g and
When f we
is convex
semi-continuous,
f = f ∗∗ ,
With this definition,
obtain
thelower
concise
expression:generalization
(in particular, its elements have different dimensional-We alsofor
J
=
J =K I .
Legendre-Fenchel
plays
let N itdenote
set of realizable
moments
of a central role.
we can use convexity
By construction,
will
bethe
possible
totransformation
perform
the op∂τf f,gof A to obtain:
∗
ity).
Q. Noteover
thatvariables
this set is
distinct
∇G = ω + Jϑ − ∇A .
MF
After carrying this matrix multiplication, we obtain:
timization
in formally
Rd , where
d! =from
|F ! |.MTo
[g]
(c)
does not depend on τ (c) . It is hence possible to optimize exactly in time O(|F !(c) |) the block of coordinates
τ (c) while keeping the values of the other blocks fixed.1
1
ω∈Ξ⊆R
[g]
0
k−1
rameter vector.
for a sufficient statistics φ : X → R , base measure
problem
can
be relaxed.
Mean
fieldof
methods
can
Stepν 2: be
Relax
thethat
optimization
problem
using
a
subset
of
the
initial
! entropy
shown
to
be
equal
to
the
negative
the
f=
·) for
∈ Ewhere
In particular, the function Γ on the right-hand side
P(X
∈ A) =
exp{"φ(x),
(1) ω ∈beΞseen
and as
itsa moments
by
τ .(e,
wee let
Y}.denote
a
andθ parameters
θ
∈ Ω∗= {θ θ#
∈ R−d A(θ)}ν(
: A(θ) <dx),
∞}. exponential
particular
type
ofAlso
relaxation
the
family
(defined
by
a
subgraph)
−H
(X
)
(Wainwright
and
Jordan
2008)
cannot
be
The
right-hand the
side ofoptiEquation (6) makes it clear that
perform
ν
µ Note that Equation (6) allows us to
Â(θ) = sup{%θ, µ&A−! A (µ) : µ ∈ MMF }. generic
(5)
of
Equation
(6)
is
generally
non-convex. The precise
random
variable
that
has
a
distribution
in
Q.
!
!
sup
is
taken
over
a
proper
subset
of
M
.
In
particuThe subgraph
G for
= arbitrary
(V, E ) isµ.generally
taken
to be d! the mean field optimization
efficiently
Hence, the
objecOverview
problem
is different
than
We will also use the notation Xµ where µ ∈ Rd to computed
Example
of a b-acyclic
graph
form
of
Γ
will
be
established
shortly.
mization
in
the
smaller
space
R
;
this
is
a
key
algolar,
the
sup
is
taken
over
a
subset
of
M
for
which
the
⊆
M
The
subfamily
induces
a
tractable
subset
M
A(θ)
=
log
exp{"φ(x),
θ#}ν(
dx)
(2)
MF
acyclic
so that
inference
in the efficiently.
induced subfamily
function
cannot
be evaluated
On the Q
denote a random variable with distribution in P such tive
performing inference in Q, the latter being:
d
objective
function
and
its
gradient
can
be
evaluated
of
moments
in
M
:
∗
isYindeed
tractable.consequence
hand,
(4) is a constrained of
optimization
µ.
that this is
defined other
E[φ(Xµ,)]A
the mean-field
approximation.
The left-hand
side of Equation (6) gives another perω rithmic
Indeed,
for dynamic
all µthat
∈programming
M
(µ)
amounts
towell
computing
Easy
special case:
beNote
! Equation
"
MF =can
efficiently.
d
sup{%ω, τ & − A∗ (τ ) : τ ∈ N }.
φ is sufficient
for asince
sufficient
statisticsforφθ.: X → R , base measure ν Tractable
problem
that
can
be
relaxed.
Mean
field
methods
can
spective on the mean-field optimization problem: heretition function coincide with the quantity of interest:
r.v.
Tractable
parameters
M
=
µ
∈
M
:
∃ω
∈
Ξ
s.t.
E[φ(Y
)]
=
µ
,
used
when
the
graph
is
acyclic
We
denote
the
parameters
indexing
this
subfamily
by
MF
ω
the entropy of
forest-shaped
X
andaparameters
θ ∈ Ω = {θgraphical
∈ Rd : A(θ) <model:
∞}.
be seen as a particular
typegain
of relaxation
where
the a new
focus on
the case inbut
which
theoptimization
interactions areisZpairwise
of this
in accuracy,
we present
structure
[g] ` [g] ´
we
have
a
convex
objective,
the
exp{!φ(x), θ [g] "}
θ
=
We are interested in the case in which the distribuIn
particular,
the
function
Γ
on
the
right-hand
side
Subgraph
ω∈Ξ
and its moments
by τrelaxations
. Also we let Y denote a
2.3
Graphical
mean-field
sup isintaken
over
aGeneric
proper
subset
of M . based
In
particuand the base
measure is and
discrete. However,
mean
field
algorithm
on auxiliary
exponential
!
k−1
d
2.4
fixed
point
updates
#
which
turn
induces
a tractable
relaxation:
over
a non-convex
(Wainwright
2008).the ideas “x∈X
X use
factors
toµ an
undirected
will
also
the according
notation
X
where
µ ∈ Rgraphto "
of Equation
(6) is set
generally
non-convex. Jordan
The precise
generic
random
variable
that
has
a
distribution
in
Q.
” X
Problem: ignores 36 ofWe
thetion
128of
components
of the#
X
τ(p ,p ),(y ,y )
apply directly to the general exponential family—this=
families.
lar,
the
sup
is
taken
over
a
subset
of
M
for
which
the
`P 0 1 0 1 ´
"
τ(a,p1 ),(s,s )
order
to define
this relaxation,
thesubset
user needs
to
ical
vertices
=H
(V,νE),
i.e.
X =) . In
Hν (Yand) sufficient
= denote
Hinν on
(Y
)+
(Y
|Y
amodel
random
variable
with G
distribution
in
Ppa(j)
such
form
of
Γ
will
be
established
shortly.
⊆
M
The
subfamily
induces
a
tractable
M
imexample
j
∗
parameters
statistics
the
"
will be (6)
discussed
more
in Section
3.
s" τ(p0 ,p1 ),(y0 ,s )
Note
that Equation
allowsinus
to detail
perform
the optiand
gradient
evaluated
m
Â(θ)afunction
=
sup{%θ,
µ&itsprincipal
−notion
A (µ)
:v-can
µand
∈ be
M
}.MF subgraphs
(5)
y1 ∈X
s"
MF
provide
subset
of
the
exponential
family,
), Xµ.= X
. For
simplicity
of notation
we objective
The
of
b-acyclic
is
different
1 , . . . ,µX
m=
!
)]
Note
that
this
is
well
defined
that(X
E[φ(X
∗
of moments
in
M : ) = %ω, τ &+%ϑ, Γ(τ )&−A (τ ). We take partial
X
X
d
τ(pk−2 ,pk−1 ),(yk−2 ,yk−1 )
Let
G(τ
j:j$=i∼j
2
efficiently.
i∈cc(G! )
The
left-hand
side
of
Equation
(6)
gives
another
permization
in
the
smaller
space
R
;
this
is
a
key
algo´
`
P
·
·
·
×
Let
F
=
(V
×X
)∪(E
×X
)
be
the
index
set
for
the
cothat
the
notion
of
“overlapping
cluster”
used
in
the
!
"
since φ is sufficient for θ.
")
τ
"
(p
,p
),(y
,s
s
k−2 k−1
k−2
∗ ∈structured
yk−1 ∈X
y2 ∈X
spective
on the
mean-field
problem:
here
rithmic
consequence
ofofthe
mean-field
approximation.
ordinates
φoptimization
(the
potentials).
If e = (a,
b) ∈ E, then
work
on
mean
field
et
al. (2006).
Mfor
= µ µ∈ ∈MM
:,∃ω
Ξobtain
s.t. E[φ(Y
)] =by
µ Geiger
,
Indeed,
all
Ato
(µ)
amounts
to
computing
MFderivatives
ω
MF
stationary
point
conditions.
By
τ
Wesubgraph,
are interested
in takes
the case in which the distribu- the
we have
objective, that
but the
thefollowing
optimization
is holds on × ` P (pk−1 ,pk ),(yk−1 ,yk ) ´
it is understood
inclusion
Some v-acyclic
graphsmodel:
have overlapping clusters,
somea convex
2.3entropy
Graphical
mean-field
relaxations
Structured mean field harnesses an acyclic
but also
of a forest-shaped
graphical
"
the
definition
of#
Γ:
s" τ(pk−1 ,pk ),(yk−1 ,s )
tion≤
of A(θ),
X factors
according
an undirected
the
induced
sigma-algebra:
⊇ σ(Xa , Xb ).
and
moreover,
the computational
dichotomy
which in
turn
induces
a tractable
over
aGeneric
non-convex
set point
(Wainwright
and σ(φ
Jordan
2008).
e,· (X))
! do not;
"
Note that Â(θ)
which
is ato very
usefulgraphproperty
into account all components
∗relaxation:
2.4
fixed
updates
#
µ
∈establish
MMF ,here
Athe
(µ)
isnottractable
InConsequence:
order
to defineon
this
relaxation,
user
needs
ical model on m vertices G = (V, E), i.e. X =
Similarly, if v ∈ V , σ(φv,· (X)) ⊇ σ(Xa ). WeOne
losecan
no check that this is achieved with the following
we(Y
does
hold if
of v- and
H
(Y
)
=
H
)
+
H
(Y
)tothe
.(5)notionNote
∗
ν
ν µ&
i − A (µ) : µν ∈ M
j |Ypa(j)
∗
#
m
that
Equation
(6)
allows
us
to
perform
the
optiÂ(θ)
=
sup{%θ,
}.
when mean-field
inference
is
used
in
the
inner
loop
MF
∂G
∂ΓofgLet
choice:
for all
b-acyclic
subgraphs
is replaced
by that
overlapping∂Agenerality by requiring
provide a subset
of
the
principal
exponential
family,
(X1 , . . . , Xm ), X = X . For simplicity of notation we
∗ existence of potentials
G(τ
)
=
%ω,
τ
&+%ϑ,
Γ(τ
)&−A
j:j$=i∼j
i∈cc(G! )
d! (τ ). We take partial
Question: how to choose the acyclic subgraph?
mization
in
the
smaller
space
R
;
this
is
a
key
algo8
(τ ) =Note
ωfthat
+ other variational
ϑg approximations
(τ ) −
(τ ) and edges, since we can always set their corvertices
clusters.
log τh − log τv,x + log τ(a,v),(s,x)
if v = p0
of EM (Wainwright and Jordan 2008). Moreover, ifIndeed, for all µ∂τ
>
derivatives
to
obtain
stationary
point
conditions.
By
<
∗
∂τ
∂τ
rithmic
consequence
of
the
mean-field
approximation.
responding
parameter
to
zero.
such
as
Expectation
Propagation
also
have
a
subgraph
f
f
i
log τh − log τv,x
∈M
to computing
[g]
MF , A (µ) amounts
!
Step 3: Solve the simplified
optimization
problem
θh =
g∈F
\F
!!
!
the
definition
of
Γ:
+ log τ(pk−1 ,b),(y,t) − log τw,y if w = pk−1
Bag
of
tricks
>
interpretation
(Minka
and
Qi 2003). While this subNotethe
that
Â(θ) of
≤ aA(θ),
which is agraphical
very
useful
property
E , with
:
entropy
forest-shaped
model:
• Adding an edge E
in the⊆
subgraph
can onlyassociated
increase qualitymean field approximation
log
τ
−
log τv,x
otherwise
h
∗
∗
# duality
graph
sometimes
happens
toτ be
b-acyclic,
there∂G
isGeneric
no
!
"
when
mean-field
inference
is
used
in
the
inner
loop
2.2
Convex
∂Γ
∂A
2.4
fixed
point
updates
Â(θ)
=
sup{!ω,
τ
"
+
!ϑ,
Γ(τ
)"
−
A
(τ
)
:
∈
N
}
#
#
g
0
!distinction between
Ă(θ), then Ă(θ) ≤ Â(θ) ≤ A(θ).
(τ
)
=
ω
+
ϑ
(τ ) −
(τ )
special
vand
b-acyclic
graphical
f
g
where
f
∈
F
.
H
(Y
)
=
H
(Y
)
+
H
(Y
|Y
)
.
where h = ((v, w), (x, y)), (v, w) ∈ pg , (x, y) ∈ X 2 .
ν
ν
i
ν
j
pa(j) if
of EM (Wainwright and Jordan 2008). Moreover,
∂τ
∂τ
∂τ
• But what is the impact on computational complexity?
f
f
i
∗
A τsimple
but
fundamental
property
of exponential
case of Bethe-energy Let
variational
! ) approximations
g∈F
\F !)&−A
!!
!
moments
in the
subgraph
G(τ ) = %ω,
&+%ϑ,
Γ(τ
(τ ). We
take partial
j:j$field
=in
i∼jthe
, withi∈cc(G
associated
mean
approximation
Using Equation (3), we have for all h = ((v, w), (x, y)),
!
! E ⊆ Erealizable
is
that the gradient
and Hessian
of the log
approximations. This is why we focus on derivatives
mean field to families
As a consequence, adding edges in G = (V, E ) can
obtain
stationary
point
conditions.
By
pg , (x, y) ∈ X 2 :
will
beapproximations.
useful
no- have the following
Ă(θ), thenIt
Ă(θ)
≤ Â(θ)
≤ A(θ). to represent this update
Theorem
of A(θ) forms: (v, w) ∈ Hammersley-Clifford
where f ∈in
F ! .vector
partition functionProperties
}
!
"
τ (c) = ∇A(c) ω (c) + J (c) (τ (1) , · · · , τ (k) )ϑ
10
Suppose now that connected component G!(c) is vacyclic. We show how entries in the embedding Jaexp{!φ(x), θ [g] "}
Z [g] θ [g] =
(c)
8
Technique:x∈Xauxiliary exponential families
v-acyclic
subgraphs
cobian J (τ ) can be computed
in constant
time in
” X
“X
τ(p ,p ),(y ,y )
3.4 Relation to Gibbs sampling
this case.
`P
´
τ(a,p ),(s,s )
=
τ
(p
,p
),(y
,s
)
s
For fixed g, construct ansexponentialy families
such that its partition6
Connected component decomposition:
∈X
Recall that we have:
X
X
τ(p ,p ),(y ,y )
Before' moving
to the b-acyclic case, we
draw satisfies:
atition
paral
function
function
coincide
with
the
quantity of interest:
´
`
&
(1)
P
·
·
·
×
(1)
(1)
(1)
τ
(p
,p
),(y
,s
)
4
∂ τ
∇A0 ω + J lel
(τ between
)ϑ
block Gibbs sampling and structured mean
(c)
X y ∈X y ∈X [g] s
` [g] ´
[g]
Jf,g (τ ) τ== E[φg (Y
)],
τ
τ(p ,p ),(yθ ,y
=
exp{!φ(x),
"} )
Z θ
=
field approximations
in the case in which all connected
∂τf
´
× `P
&
'
(2)
x∈X k−1
τ(p ,p ),(y ,s )
(2)
(2)
!(c)
2
s
τ (2)
∇A0 ω + J components
(τ )ϑ
G
are v-acyclic. This connection gen- “ X
” X
τ
!(c)
!
(p0 ,p1 ),(y0 ,y1 )
where f ∈ F , g ∈ F \F .
`P
´
= checkτthat
(a,p1 ),(s,s
One can
this "is) achieved
withτ the following
eralizes the classical relationship between naive Gibbs
" (p0 ,p1 ),(y0 ,s" )
"
s
y1 ∈X
s
0
choice:
0
sampling steps and naive mean field coordinate ascent
Since g ∈ F \F ! , we must have g = (e, (s, t)) for some
X
X
τ
(pk−2 ,pk−1 ),(yk−2 ,yk−1 )
8
can check
easily
that
the
block
Gibbs
sampler
with
´
`P
log×τh − log· τ· v,x
if v = p0
· + log τ(a,v),(s,x)
! (1)
>
ϑ updates. Γ(τ )
<
e = (a, b) ∈ E\E
∈ has
X 2 a. transition
Therefore:
"
blocks Vand
, . .s,
. , Vt (k)
kernel given by:
log τh − log τv,x
[g]
s" τ(pk−2 ,pk−1 ),(yk−2 ,s )
The
θ∈Θ⊆R
A
: Rin
→
computed.
field approximation:
In
this section,
we review
the principlessubfamily
of mean field beQ
acyclic so that
inference
theRinduced
conclusions
in Section
5.
performing inference in Q, the latter
being:
∗ to establish an alternative form for A.
formation
f
(x)
=
sup{"x,
y#
−
f
(y)
:
y
∈
dom(f
)}.
approximation
and
set
the
notation.
Our
exposition
Parameters
Log-partition
• ∈v-acyclic,
if for all e ∈ E, E′ ∪{e} is still acyclic
∗
is indeed tractable.
sesup{%θ,
µ&
−
A
(µ)
:
µ
M
}
=
MF
follows the general treatment of variational methods An intuitively appealing approach to making this
∗
2 presented
Background
Definition
1
For
an
extended
real-valued
function
f , ) : τ ∈ N }.
lection
is
to
make
use
of
the
graphical
representation
!
" Jordan (2003) where
sup{%ω,
τ
&
−
A
(τ
in Wainwright
and
the
D
Theorem:When
If f isfconvex
and
lower
sup{%ω, τ & + %ϑ, Γ(τ )& − A∗ (τ ) : τ ∈ N },
(6)
is convex
and
lower semi-continuous, f = f ∗∗ ,
φ:X →R
µ
=
E
φ(X
)
•
b-acyclic,
otherwise
the
Legendre-Fenchel
transformation
is
defined
as:
θ
of
the
exponential
family
and
to
choose
a
subset
of
the
We denote the parameters
indexing
this
subfamily
by
Legendre-Fenchel transformation plays a central role.
we can! use
of A to obtain:
semi-continuous,
f =convexity
f **
In this section, we review the principles of mean field
edges,
E
⊂
E,
to
represent
a tractable subfamily. In
where θ = (ω, ϑ). Note the slight abuse of notation:
Sufficient statistics Graphical
Moments
∗ In particular, the function Γ on the right-hand side
ω ∈ Ξmodel
and itsapproximation
moments
by
τ
.
Also
we
let
Y
denote
a
f
(x)
=
sup{"x,
y#
−
f
(y)
:
y
∈
dom(f
)}.
∗
and set families
the notation. Our exposition particular,
Q ⊂ P,
which
thethis
partition
and
moments
can we
Weuse
canAthen
write the
equationofofboth
meanA(θ)
=
sup{"θ,
µ#log
−subfamily
A
(µ) : µ ∈
M },
inin defining
we
retain(4)
only
2.1 Exponential
to denote
thefundamental
partition function
exfollows
the
general
treatment
of
variational
methods
of
Equation
(6)
is
generally
non-convex.
The
precise
generic random variable that has a distribution in the
Q.be
computed.
field approximation:
potentials
with indices
ponential
families; the Examples
notation can
always be
disamof v-acyclic
graphs
∗∗
presented
in Wainwright
and Jordan
(2003)
We assume
that the random
variable
underwhere
study,the
Xθ , When
wheref M
=
∇A(Θ)
is
the
set
of
realizable
moments.
isinference
convex of
and
semi-continuous,
f = problem
f , shortly.
by µ&
inspecting
of the paStep
Express
as Γ
alower
constrained
optimization
will
be
established
⊆1:M
The subfamily
induces
a transformation
tractable
Mfamily
!form appealing
An intuitively
approach
to
making
this se- biguated
MF
sup{%θ,
− A∗ (µ) the
: µ ∈dimensionality
MMF } =
!
has a distribution
in a regularsubset
exponential
Legendre-Fenchel
plays
a central
role.P
F
=
{f
∈
F
:f
=
(v,
·)
for
v
∈
V
or
we
can
use
convexity
of
A
to
obtain:
Formulation
is nouse
more
tractable
than representation
the definirameter vector.
using convex
duality:
intractable
lection
is to(4)
make
of the
graphical
in canonical
!
P(X θ ∈ B) =
exp{"φ(x),
θ# − A(θ)}ν(in
dx)
∗
sup{%ω, τ & + %ϑ, Γ(τ )& − A∗ (τ ) : τ ∈ N },
(6)
of moments
M
: Oftenform:
f
=
(e,
·)
for
e
∈
E
}.
tion
of
A
in
Equation
(2):
the
term
A
(µ),
which
can
!
∗side
of
the
exponential
family
and
to
choose
a
subset
of
the
The
left-hand
of
Equation
(6)
gives
another
per(e.g.
NP-complete
B
A(θ)
= sup{"θ, µ# − Anegative
(µ) : µ ∈
(4)
The right-hand side of Equation (6) makes it clear that
! 2.1 Exponential families
" be shown
of M
the},entropy
!
!to be! equal to the
!
edges,
E
⊂
E,
to
represent
a
tractable
subfamily.
In
P(X θ for
∈ A)
=
exp{"φ(x),
θ#
−
A(θ)}ν(
dx),
(1)
where
θ =field
(ω, optimization
ϑ). Note the problem
slight abuse
of notation:
non-planar
The−H
subgraph
G = (V,
E
) Jordan
is generally
taken
to
be
the
mean
is
different
than
spective
on
the
mean-field
optimization
problem:
here
(X
)
(Wainwright
and
2008)
cannot
be
ν
µ
MMF θ"}ν(
= µ
M :that
∃ω
∈
AΞ s.t. E[φ(Y ω )] = µ ,
D
A(θ) = log
exp{!φ(x),
dx)
particular,
in
defining
this
subfamily
we
retain
only
we
use
A
to
denote
the
partition
function
of
both
ex!
We∈
assume
the
random
variable
under
study,
X
,
where
M that
=efficiently
∇A(Θ)
of s.t.
realizable
moments.
Ising models)
θ
M
=
{µinference
∈ R isfor
:the
∃θ
∈the
Θ
E[φ(X
= µ} Q
acyclic
so
inset
induced
subfamily
θ )] objecperforming
inference
in
Q,
the
latter
being:
computed
arbitrary
µ.
Hence,
the
X
we cannot
have
aevaluated
convexefficiently.
objective,
but the
optimization
is can always be disamthe potentials
with indices
ponential
families; the notation
has a distribution
exponential
family P(2) is indeed
A(θ) =inloga regular
exp{"φ(x),
θ#}ν( dx)
tractable.
tive function
the
Formulation
(4) is no be
more
tractable than theOn
definiin induces
canonical form:
biguated
bysup{%ω,
inspecting
dimensionality
τ & −the
A∗ (τ
)Naive
: τ ∈MF
N }. of the pa-Factorial
!Equation
∗ optimization
a !tractable relaxation:
other
hand,
(4):fisthe
a constrained
over
a
non-convex
set
(Wainwright
and
Jordan
2008).
Maximum
D=#
vertexwhich
X #{0,1}in+ #turn
edges
X #{00,01,10,11}
tion
of
A
in
Equation
(2):
term
A
(µ),
which
can
F
=
{f
∈
F
=
(v,
·)
for
v
∈
V
or
We denote the parameters indexing this subfamily by
d
}} }}
Proposition 5 The right hand side of the equation
1
∇A1 (ζ 1 )
B
C
..
∇A(ζ) = @
A
.
∇Ak (ζ k ).
2 !inBackground
Definition 1 For
an
extended
real-valued
function
f,
Two
equivalent
ways
specify
convex
functions
ments
3. ! We
empirical taken
results toto be
• •Two
equivalent
ways
to to
specify
convex
functions
subgraph
G
=Section
(V, E
) ispresent
generally
The
second
identity
implies
convexity,
which
we
can
the
mean
field
optimization
problem
is then
different
⊂
in whichtransformation
the transformation
log partition and
moments
We can
write thethan
fundamental equation of meantheP,
Legendre-Fenchel
is defined
as: can
support our claims D
in Section 4 and we present Tool:
our Q
Legendre-Fenchel
Definition: an acyclic subgraph with edges E' ⊆ E is ...
use in conjunction with the Legendre-Fenchel trans-
}
exp!ζ (c) , φ(c) (x)"ν( dx)
A(c) (ζ (c) ),
* Computer Science Division
of Statistics
University of California at Berkeley Now plug in ζ = ω
Preview:
Z
c∈cc(G! )
Alexandre Bouchard-Côté* Michael I. Jordan*
D
+ !ζ (k) , φ(k) (x)"}ν( dx)
b-acyclic subgraphs
the followin
µw,y
´
0
>
ence procedure allowing
internal structure
for overlap>
×
1[x
=
s]
if
v
=
p
SMF1
and
SMF2.
As
a
baseline,
we
ran
the
laxation
for
approximate
inference
in
discrete
Markov
0
10
10 "
10
10
10
tion.
regime,
innaive
this c
τ
>
τ
,s )
f
k−1 ,pk ),(y
k−1
< Journal
We now (ppresent
an
alternative
Time approach that is both ping clusters and deterministic constraints.
of˘
¯
random
fields.
IEEE
Transactions
on
Signal
Processing,
mean field (curve NMF on the graph). The results are
[g]
1[y=t]
× `P
Form
: n is: path in G! from
9J X
o a to b (see FigThe quantity
toof
compute
X
denote
the8 shortest
1
[g]
Intelligence
Research,
54:2099–2109,
2006.
− τv,x
if4.wWe=can
pk−1
φ((xi,j )i,j∈{1,...,9}ure
x
x
+
x
x
,
Jf,g (τ
) = Z27:1–23,
× 2006.µv,x ×
2) =
simpler to implement and asymptotically faster. The 5Artificial
i,j
i+1,j
j,i
j,i+1
in Figure
see that in this
model itthe
τdisplayed
Conclusion
f
2).
SMF1
>
A.
Globerson
and
T.
Jaakkola.
Approximate
inference
us∂
[g]
M.
J.
Wainwright
and
M.
I.
Jordan.
Graphical
models,
Figure
4:
Error
in
the
partition
function
estimate
as
a
>
j=1 i=1
[g]
idea
is
to
construct
an
auxiliary
exponential
family
takes
one
order
of
magnitude
more
time
to
move
from
>
µ
The
task
is
thus
more
complex
than
that
of
creating
can check Jeasily
that
block
Gibbs
sampler
with
(τ )let
=y the
P(Y
s,
Ywe
t),
:
f Neuralµv,x
ing planar graph decomposition. In Advances
in
f,gwe
a =
b =
exponential
families,
and
variational
inference.
Foundafunction
of
the
running
time
in
milliseconds
(abscissa
If
=
s,
y
=
t,
have:
graph
w
−
otherwise
0 f
k
naive
mean
field
to
v-acyclic
structured
mean
field,
(1)
(k) ∂τ
model
and
to
use
an
elementary
property
of
Jacobian
τf 2006.τv,x
Information
Processing Systems,
Cambridge,
a dynamic programming
algorithm
ofalgorithms:
the typenaive
used
tions and Trends in Machine Learning, 1:1–305, 2008.
blocks1V , . . . , V
has a transition kernel given by:
We
have characterized
a dichotomy
in the MA,
complexity
in
a
log
scale)
for
three
mean
field
and two orders of magnitude more time to moveponent
from
MIT Press.
with θ! = T , where T is the
temperature parameter
matrices
to reduce
computation
to
a standard
W. Wiegerinck. Variational approximations between mean
Ya needmean
for sum-product.
A... chain
rule the
would
to be
used,
∂ X on X
! time the probability
(NMF),
v-acyclic
structured
field
(SMF1)
and ap- of optimizing structure mean field approximations of v-acyclic
where
this
the
right-hand
side
p
to
b-acyclic
structured
mean
field
approximap
·
·
·
P(Y
=
y
,
∀i
∈
{1,
.
.
.
k})
J
(τ
)
=
G. Hua and Y.
Wu. Sequential
field variational
anal! f,g physics. In this model, thepiparti1
0
i
field theory
and(v,
the w)
junction
algorithm. In Proas used in
statistical
t)
exponential
models.
class
plication
sum-product
the auxiliary
wherefamily
fmean
=
((v,The
w),first
(x,
y)) is
such
∈ tree
pthe
mean
field
(SMF2).
g forineach
X (c
(t)!decoupled
X(t − 1) ∼into
changing the
formb-acyclic
of of
the
recursion
f, g. The exponential graphical,
∂τf ya∈X
g ; theoretical
ysis of structured deformable shapes. Computer Vision
tions.
Thisthat
isthe
consistent
with
results
ceedings
of
Sixteenth
Conference
on Uncertainty
in
cannot
be
product
yk−1of
∈X marginals. Let
p
1
k
allows
efficient
block updates
while the
second is comSMF2
the
f
tion function and moments
can be computed exactly#
family.
"
and Image
Understanding,
101:87–99,
2006.
Artificial
Intelligence,
pages
626–633,
San
Mateo,
CA,
complexity
of
this
naive
approach
can
be
shown
to
be
otherwise,
J
is
equal
to
zero.
developed
in
Section
3.
Moreover,
the
bound
on
the
Y
f,g most tractable
X
X
b
putationally
more
challenging.
While
!(c∂
(ct )
(c
t)
t)
2000.
Morgan
Kaufmann.
!
!
so that absolute
errors
can
! , = y )O(|E !·|·×|
ωestablished.
+ ∀i,
B (p(X(t
− 1))ϑ
J. B. Lasserre. Global optimization with polynomials and
in Figu
· F There
| ×| F is
\Fone
|), auxiliary
which is considerable.
p1) =
0
pg = {a MRF
=
p0 , pP
, . .∂τ
.be
, ,pP(Y
pi+1
∈ yE1 |Y
}p0
1=
k =a b=: s)
i ,P(Y
studied
in the existing
literature
have fallen log partition function gets tighter as more edges are
exponential family P [g] for each subgraphs
the problem
of moments.
SIAM Journal
on Optimizaf
J.
S.
Yedidia,
W.
T.
Freeman,
and
Y.
Weiss.
Generaladded
to
the
tractable
subgraph.
!
!
!
y1 ∈X
y2 ∈X
the11:796–817,
first category,
wetotal
have presented
theoretical
and
((a, b),
(s,alternative
t))using
= gthe∈more
F \Fexpensive
. It that
is b-acyclic
defined
on the chain intion,
2000.
where
approximaThe
cost of
computing
Jizedisbelief
O(|E
| × |FIn\F
|), in Neural subgrap
propagation.
Advances
InforWe used
the
updates
of defined
Proposition
5 when the
We
now
present
an
approach
is
both
! follows:
X
X
where
B
is
the
matrix
as
empirical
reasons
to
expand
the
scope
of
the
structured
denote the shortest path
to0 ,yb 1(see
Figτ(p0 ,pa1 ),(y
∂ in G from
mation
Processing
Systems,
pages
689–695,
Cambridge,
)
tion
pays
off.
p
,
p
,
.
.
.
,
p
where
p
is
as
above.
We
pick
its
paT.
Minka
and
Y.
Qi.
Tree-structured
approximations
by
1 2
k−1
g
tractable subgraph was =v-acyclic
which
is
larger
than
the
cost derived
in the
τa,s and used the fixed · · ·
simpler to implement
and
asymptotically
faster. The
MA, 2001. MIT
Press.v-acyclic
mean
field method
to consider
the in
second
expectation
propagation.
In Advances
Neuralcategory.
Infor[g]
ure 2). (c)
∂τf
τ
p0 ,y0
so
that
the
partial
derivatives
of
its
parrameters
θ
We
also
performed
timing
experiments
to
compare
the
y1the
∈X
y2 ∈X
point updatesBf,g
of (X(t
Proposition
6 in=
b-acyclic cases.
Figure
2:
An
example
of
the
notation
used
in
this
− 1)) =1[f
(a, s)]×
mation
Processing
Systems,
Cambridge,
MA,
2003.
MIT
We
also
presented
a
novel
algorithm
for
computing
idea is to construct an auxiliary exponential family
case, but smaller than the naive
programming
In Figure 3
5 dynamic
Conclusion
convergence behavior of the mean field approximations
Press.
we let y0 =the
s, ykexperiments,
= t, we have:we verified
the
gradient and bound on the log-partition function
section.
Thistocorresponds
to the inference
problem
in
BeforeIfperforming
empir(c)
model
and
use
an
elementary
property
of
Jacobian
algorithm
mentioned at the beginning of this subsecdifferent tem
SMF1 and SMF2. As a baseline, we ran the naive
1[|{a, b} ∩ V | = 1]×
C.inPeterson
and J. R.
Anderson. A mean field theory learnthe b-acyclic
case.
the
mean
field
subgraph
in
Figure
1,
left
column,
botically using directional
derivatives
that
the
updates
X
X
matrices
to
reduce
the
computation
to
a
standard
apmean field (curve NMF on the graph). The results are
∂
ing algorithm for
neural networks. Complex Systems, 1:
We have characterized a dichotomy in theregime,
complexity
tion.
in t
1[XP(Y
1) = s],
···
Jf,ghave
(τ ) =derived are
b (t p−
tom
row. The
box indicate
which
i = yi , ∀i ∈ {1, . . . k})
995–1019, 1987.
displayed in
4. Weare
can involved
see
that inin
this model it
that we
plication
of sum-product
inFigure
the nodes
auxiliary
exponential
of optimizing structure mean field approximations of
∂τf y ∈X error-free.
[g]
yk−1 ∈X
1
takes onefamily
order of
more
time to move from
the
auxiliary exponential
Pmagnitude
used to
compute
L. K. Saul and M. I. Jordan. Exploiting tractable subgraphical, exponential family models. The first class
family.
s"
0
1
2
3
4